Extensiones del analizador
En este documento, se explica cómo crear extensiones de analizador para extraer campos de datos de registro sin procesar y asignarlos a campos de UDM (modelo de datos unificado) de destino dentro de la plataforma de Google Security Operations.
En el documento, se describe el proceso de creación de la extensión del analizador:
- Crea extensiones de analizador.
- Requisitos previos y limitaciones
- Identifica los campos de origen en los datos de registro sin procesar.
- Selecciona los campos de UDM de destino adecuados.
Elige el enfoque de definición de extensión del analizador adecuado:
La definición de una extensión de analizador incluye el diseño de la lógica de análisis para filtrar los datos de registro sin procesar, transformar los datos y asignarlos a los campos del UDM de destino. Google SecOps proporciona dos enfoques para crear extensiones de analizador:
- Crea extensiones de analizador con el enfoque sin código (Asignar campos de datos).
- Crea extensiones de analizador con el enfoque de fragmento de código.
Ejemplos ilustrativos de creación de extensiones de analizador para diversos formatos y situaciones de registros Por ejemplo, ejemplos sin código con JSON y fragmentos de código para lógica compleja o formatos que no son JSON (CSV, XML, Syslog).
Crea extensiones de analizador
Las extensiones del analizador proporcionan una forma flexible de extender las capacidades de los analizadores predeterminados (y personalizados) existentes. Las extensiones del analizador proporcionan una forma flexible de ampliar las capacidades de los analizadores predeterminados (o personalizados) existentes sin reemplazarlos. Las extensiones te permiten personalizar la canalización del analizador agregando nueva lógica de análisis, extrayendo y transformando campos, y actualizando o quitando asignaciones de campos del UDM.
Una extensión de análisis no es lo mismo que un analizador personalizado. Puedes crear un analizador personalizado para un tipo de registro que no tenga un analizador predeterminado o inhabilitar las actualizaciones del analizador.
Proceso de extracción y normalización del analizador
Google SecOps recibe los datos de registro originales como registros sin procesar. Los analizadores predeterminados (y personalizados) extraen y normalizan los campos de registro principales en campos de UDM estructurados en los registros de UDM. Esto representa solo un subconjunto de los datos de registro sin procesar originales. Puedes definir extensiones de analizador para extraer valores de registro que no controlan los analizadores predeterminados. Una vez activadas, las extensiones del analizador se convierten en parte del proceso de extracción y normalización de datos de Google SecOps.
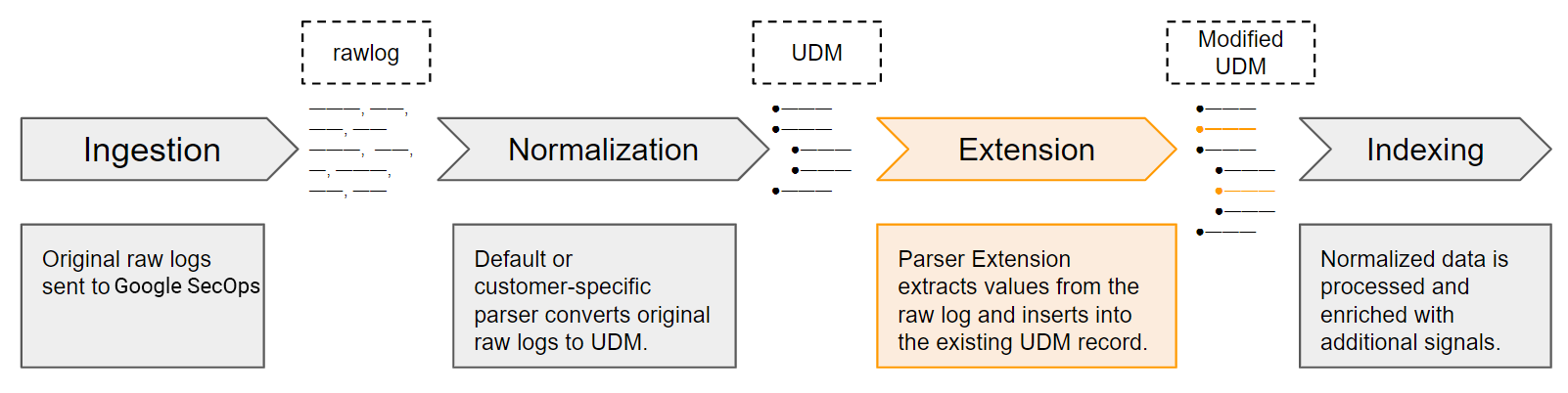
Cómo definir nuevas extensiones del analizador
Los analizadores predeterminados contienen conjuntos predefinidos de instrucciones de asignación que especifican cómo extraer, transformar y normalizar los valores de seguridad principales. Puedes crear nuevas extensiones de analizador sintáctico definiendo instrucciones de asignación con el enfoque sin código (Map data fields) o el enfoque de fragmentos de código:
Enfoque sin código
El enfoque sin código es más adecuado para extracciones simples de registros sin procesar en formato JSON, XML o CSV nativo. Te permite especificar campos de fuente de registro sin procesar y asignar los campos de UDM de destino correspondientes.
Por ejemplo, para extraer datos de registro JSON con hasta 10 campos, usando comparaciones de igualdad simples.
Enfoque de fragmento de código
El enfoque de fragmentos de código te permite definir instrucciones para extraer y transformar valores del registro sin procesar, y asignarlos a campos del UDM. Los fragmentos de código usan la misma sintaxis similar a Logstash que el analizador predeterminado (o personalizado).
Este enfoque se aplica a todos los formatos de registro admitidos. Es ideal para las siguientes situaciones:
- Extracciones de datos o lógica complejas
- Datos no estructurados que requieren analizadores basados en Grok
- Formatos que no son JSON, como CSV y XML
Los fragmentos de código usan funciones para extraer datos específicos de los datos de registro sin procesar. Por ejemplo, Grok, JSON, KV y XML.
En la mayoría de los casos, es mejor usar el enfoque de asignación de datos que se usó en el analizador predeterminado (o personalizado).
Combinar los valores extraídos recientemente en los campos de UDM
Una vez activadas, las extensiones del analizador combinan los valores recién extraídos en los campos del UDM designados en el registro del UDM correspondiente según los principios de combinación predefinidos. Por ejemplo:
Reemplazar valores existentes: Los valores extraídos reemplazan los valores existentes en los campos de UDM de destino.
La única excepción son los campos repetidos, en los que puedes configurar la extensión del analizador para agregar valores nuevos cuando se escriben datos en un campo repetido en el registro del UDM.
La extensión del analizador tiene prioridad: Las instrucciones de asignación de datos en una extensión del analizador tienen prioridad sobre las del analizador predeterminado (o personalizado) para ese tipo de registro. Si hay un conflicto en las instrucciones de asignación, la extensión del analizador reemplazará el valor establecido de forma predeterminada.
Por ejemplo, si el analizador predeterminado asigna un campo de registro sin procesar al campo
event.metadata.descriptiondel UDM y la extensión del analizador asigna un campo de registro sin procesar diferente a ese mismo campo del UDM, la extensión del analizador anula el valor establecido por el analizador predeterminado.
Limitaciones
- Una extensión de analizador por tipo de registro: Solo puedes crear una extensión de analizador por tipo de registro.
- Solo un enfoque de instrucciones de asignación de datos: Puedes crear una extensión de analizador con el enfoque sin código o con el de fragmento de código, pero no con ambos enfoques juntos.
- Muestras de registros para la validación: Se requieren muestras de registros de los últimos 30 días para validar una extensión del analizador de UDM. Para obtener más información, consulta Asegúrate de que haya un analizador activo para el tipo de registro.
- Errores del analizador base: Los errores del analizador base no se pueden identificar ni corregir dentro de las extensiones del analizador.
- Campos repetidos en fragmentos de código: Ten cuidado cuando reemplaces objetos repetidos completos en fragmentos de código para evitar la pérdida de datos no deseada. Para obtener más detalles, consulta Más información sobre el selector de campos repetidos.
- Eventos desambiguados: Las extensiones del analizador no pueden controlar registros con varios eventos únicos en un solo registro, por ejemplo, un array de Google Drive.
XML y sin código: El modo sin código no es compatible con XML. En su lugar, usa el método de fragmento de código.
Sin datos retroactivos: No puedes analizar los datos de registro sin procesar de forma retroactiva.
Palabras clave reservadas con el enfoque sin código: Si los registros contienen alguna de las siguientes palabras clave reservadas, usa el enfoque de fragmento de código en lugar del enfoque sin código:
collectionTimestampcreateTimestampenableCbnForLoopeventfilenamemessagenamespaceoutputonErrorCounttimestamptimezone
Quita las asignaciones existentes: Puedes quitar las asignaciones de campos del UDM existentes solo con el enfoque de fragmentos de código.
Quita las asignaciones para los campos de IP repetidos: No puedes quitar las asignaciones de campos del UDM para los campos de IP repetidos.
Conceptos del analizador
En los siguientes documentos, se explican conceptos importantes del analizador:
- Descripción general del modelo de datos unificado
- Descripción general del análisis de registros
- Referencia de la sintaxis del analizador
Requisitos previos
Requisitos previos para la creación de extensiones de analizador:
- Debe haber un analizador predeterminado (o personalizado) activo para el tipo de registro.
- Google SecOps debe poder transferir y normalizar los registros sin procesar con un analizador predeterminado (o personalizado).
- Asegúrate de que el analizador activo predeterminado (o personalizado) para el tipo de registro objetivo haya transferido datos de registro sin procesar en los últimos 30 días. Estos datos deben contener una muestra de los campos que deseas extraer o usar para filtrar los registros del registro. Se usará para validar tus nuevas instrucciones de asignación de datos.
Comenzar
Antes de crear una extensión de analizador, haz lo siguiente:
Verifica los requisitos previos:
Asegúrate de que haya un analizador activo para el tipo de registro. Si aún no tiene un analizador, crea uno personalizado.
Identifica los campos que se extraerán de los registros sin procesar:
Identifica los campos que deseas extraer de los registros sin procesar.
Selecciona los campos de UDM adecuados:
Selecciona los campos de UDM correspondientes adecuados para asignar los campos de registro sin procesar extraídos.
Elige un enfoque de definición de la extensión del analizador:
Elige uno de los dos enfoques de extensión (enfoques de asignación de datos) para crear la extensión del analizador.
Verifica los requisitos previos
Asegúrate de que haya un analizador activo para el tipo de registro que deseas extender, como se describe en las siguientes secciones:
Asegúrate de que haya un analizador activo para el tipo de registro
Asegúrate de que haya un analizador predeterminado (o personalizado) activo para el tipo de registro que deseas extender.
Busca tu tipo de registro en estas listas:
Tipos de registros admitidos con un analizador predeterminado.
- Si hay un analizador predeterminado para el tipo de registro, asegúrate de que el analizador esté activo.
- Si no hay un analizador predeterminado para el tipo de registro, asegúrate de que haya un analizador personalizado para el tipo de registro.
Tipos de registros admitidos sin un analizador predeterminado.
- Si no hay un analizador predeterminado para el tipo de registro, asegúrate de que haya un analizador personalizado para el tipo de registro.
Asegúrate de que haya un analizador personalizado para el tipo de registro.
Para asegurarte de que haya un analizador personalizado para un tipo de registro, haz lo siguiente:
- En la barra de navegación, selecciona Configuración del SIEM > Analizadores.
Busca el tipo de registro que deseas extender en la tabla Parsers.
- Si ese tipo de registro aún no tiene un analizador predeterminado o personalizado, haz clic en CREAR ANALIZADOR y sigue los pasos que se indican en Cómo crear un analizador personalizado según las instrucciones de asignación.
- Si ese tipo de registro ya tiene un analizador personalizado, asegúrate de que el analizador esté activo.
Asegúrate de que el analizador esté activo para el tipo de registro.
Para verificar si un analizador está activo para un tipo de registro, sigue estos pasos:
- En la barra de navegación, selecciona Configuración del SIEM > Analizadores.
Busca el tipo de registro que deseas extender en la tabla Parsers.
Si el analizador del tipo de registro no está activo, actívalo:
- Para obtener información sobre los analizadores predeterminados, consulta Administra actualizaciones de analizadores prediseñados.
- Para obtener información sobre los analizadores personalizados, consulta Administra actualizaciones de analizadores personalizados.
Identifica los campos que se extraerán de los registros sin procesar
Analiza el registro sin procesar del que deseas extraer datos para identificar los campos que no extrae el analizador predeterminado (o personalizado). Presta atención a cómo el analizador predeterminado (o personalizado) extrae los campos de registro sin procesar y los asigna a sus campos de UDM correspondientes.
Para identificar los campos específicos que deseas extraer de los registros sin procesar, puedes usar las herramientas de búsqueda:
Para acceder a la herramienta de búsqueda, ve a Investigación > Búsqueda en el SIEM. Escribe raw= antes de tu búsqueda. Para obtener más información, consulta Cómo realizar una búsqueda de registros sin procesar.
Para acceder a la herramienta de búsqueda heredada, haz clic en Ir a la búsqueda heredada en la parte superior de la página Búsqueda de SIEM. Para obtener más información, consulta Cómo buscar registros sin procesar con el análisis de registros sin procesar.
Para obtener detalles sobre la búsqueda en los registros sin procesar, consulta lo siguiente:
Selecciona los campos del UDM adecuados
Ahora que identificaste los campos de destino específicos que se extraerán, puedes correlacionarlos con los campos de UDM de destino correspondientes. Establece una asignación clara entre los campos de la fuente de registro sin procesar y sus campos de UDM de destino. Puedes asignar datos a cualquier campo del UDM que admita los tipos de datos estándar o los campos repetidos.
Elige el campo de UDM correcto
Los siguientes recursos pueden ayudarte a simplificar el proceso:
- Familiarízate con los principales conceptos del UDM
- Comprende la asignación de datos que usa el analizador existente
- Usa la herramienta de búsqueda de UDM para encontrar posibles campos de UDM que coincidan con tus campos de origen.
- La guía Campos importantes del UDM para la asignación de datos del analizador incluye un resumen y una explicación de los campos más utilizados del esquema del UDM.
- La lista de campos del modelo de datos unificado contiene una lista de todos los campos del UDM y sus descripciones. Los campos repetidos se identifican con la etiqueta "repeated" en las listas.
- Consideraciones importantes sobre el UDM para evitar errores
Familiarízate con los principales conceptos del UDM
Objetos lógicos: Evento y Entidad
El esquema del UDM describe todos los atributos disponibles que almacenan datos. Cada registro del UDM describe un evento o una entidad. Los datos se almacenan en diferentes campos según si el registro describe un evento o una entidad.
- Un objeto UDM Event almacena datos sobre la acción que ocurrió en el entorno. El registro de eventos original describe la acción tal como la registró el dispositivo, como el firewall o el proxy web.
- Los objetos UDM Entity almacenan datos sobre los participantes o las entidades involucradas en el evento del UDM, como los recursos, los usuarios o los recursos de tu entorno.
Sustantivos de UDM: Un sustantivo representa a un participante o una entidad en un evento de UDM. Por ejemplo, un sustantivo podría ser el dispositivo o el usuario que realiza la actividad descrita en el evento. Un sustantivo también podría ser el dispositivo o el usuario que es el objetivo de la actividad descrita en el evento.
Sustantivo de UDM Descripción principalEs la entidad responsable de iniciar la acción que se describe en el evento. targetEs la entidad que es el destinatario o el objeto de la acción. En una conexión de firewall, la máquina que recibe la conexión sería el destino. srcEs una entidad de origen sobre la que actúa el principal. Por ejemplo, si un usuario copia un archivo de una máquina a otra, el archivo y la máquina de la que se originó se representarían como src. intermediaryEs cualquier entidad que actúa como intermediaria en el evento, como un servidor proxy. Pueden influir en la acción, como bloquear o alterar una solicitud. observerEs una entidad que supervisa el evento y genera informes sobre él, pero no interactúa directamente con el tráfico. Algunos ejemplos incluyen los sistemas de detección de intrusiones en la red o los sistemas de administración de información y eventos de seguridad. aboutCualquier otra entidad involucrada en el evento que no se ajuste a las categorías anteriores. Por ejemplo, archivos adjuntos de correos electrónicos o DLL cargadas durante el inicio de un proceso. En la práctica, los objetos Noun principales y de destino son los que se utilizan con mayor frecuencia. También es importante tener en cuenta que las descripciones anteriores constituyen el uso recomendado de los sustantivos. El uso real puede variar según la implementación de un analizador base predeterminado o personalizado.
Comprende la asignación de datos que usa el analizador existente
Se recomienda comprender la asignación de datos existente que utiliza el analizador predeterminado (o personalizado) entre los campos de origen de registro sin procesar y sus campos de UDM de destino.
Para ver la asignación de datos entre los campos de origen del registro sin procesar y los campos de UDM de destino que se usan en el analizador predeterminado (o personalizado) existente, haz lo siguiente:
- En la barra de navegación, selecciona Configuración del SIEM > Analizadores.
- Busca el tipo de registro que deseas extender en la tabla Parsers.
Navega a esa fila y, luego, haz clic en Menú > Ver.
En la pestaña Código del analizador, se muestra la asignación de datos entre los campos de origen del registro sin procesar y los campos de UDM de destino que se usan en el analizador predeterminado (o personalizado) existente.
Usa la herramienta de búsqueda de UDM
Usa la herramienta de búsqueda de UDM para identificar los campos de UDM que coinciden con los campos de la fuente de registro sin procesar.
Google SecOps proporciona la herramienta de búsqueda de UDM para ayudarte a encontrar rápidamente los campos de UDM de destino. Para acceder a la herramienta de búsqueda de UDM, ve a Investigación > Búsqueda en SIEM.
Consulta estos temas para obtener detalles sobre cómo usar la herramienta UDM Lookup:
- Cómo encontrar un campo de UDM
- Cómo ingresar una búsqueda de UDM
- Establece un filtro de tiempo en la búsqueda
- Ejemplos de búsquedas de UDM
- Genera búsquedas de UDM con Gemini
Ejemplo de la herramienta de búsqueda de UDM
Por ejemplo, si tienes un campo de origen en el registro sin procesar llamado "packets", usa la herramienta de búsqueda de UDM para encontrar posibles campos de UDM de destino con "packets" en su nombre:
Ve a Investigación > Búsqueda en el SIEM.
En la página SIEM Search, ingresa "packets" en el campo Look up UDM fields by value y, luego, haz clic en UDM Lookup.
Se abrirá el diálogo UDM Lookup. La herramienta de búsqueda hace coincidir los campos de UDM por nombre de campo o valor de campo:
- Búsqueda por nombre del campo: Coincide con la cadena de texto que ingresas en los nombres de los campos que contienen ese texto.
- Búsqueda por valor de campo: Coincide el valor que ingresas con los campos que contienen ese valor en sus datos de registro almacenados.
En el diálogo UDM Lookup, selecciona UDM Fields.
La función de búsqueda mostrará una lista de posibles campos de UDM que contengan el texto "packets" en sus nombres de campos de UDM.
Haz clic en cada fila una por una para ver la descripción de cada campo de UDM.
Consideraciones importantes sobre el UDM para evitar errores
- Campos de aspecto similar: La estructura jerárquica del UDM puede generar campos con nombres similares. Consulta los analizadores predeterminados para obtener orientación. Para obtener más información, consulta Información sobre la asignación de datos que usa el analizador existente.
- Asignación de campos arbitrarios: Usa el objeto
additionalpara los datos que no se asignan directamente a un campo de UDM. Para obtener más detalles, consulta Asignación de campos arbitrarios en el UDM. - Campos repetidos: Ten cuidado cuando trabajes con campos repetidos en fragmentos de código. Reemplazar un objeto completo podría sobrescribir los datos originales. El uso del enfoque sin código ofrece más control sobre los campos repetidos. Para obtener más detalles, consulta Más información sobre el selector de campos repetidos.
- Campos obligatorios de UDM para los tipos de eventos de UDM: Cuando se asigna un campo de
metadata.event_typede UDM a un registro de UDM, cadaevent_typerequiere un conjunto diferente de campos relacionados que deben estar presentes en el registro de UDM. Para obtener más detalles, consulta Más información sobre la asignación de campos de UDMmetadata.event_type. - Problemas del analizador base: Las extensiones del analizador no pueden corregir errores del analizador base. El analizador base es el analizador predeterminado (o personalizado) que creó el registro de UDM. Considera opciones como mejorar la extensión del analizador, modificar el analizador base o filtrar previamente los registros.
Asignación de campos arbitrarios en UDM
Cuando no encuentres un campo UDM estándar adecuado para almacenar tus datos, usa el objeto additional para almacenarlos como un par clave-valor personalizado. Esto te permite almacenar información valiosa en el registro del UDM, incluso si no tiene un campo coincidente del UDM.
Elige un enfoque para definir la extensión del analizador
Antes de elegir un enfoque para la definición de la extensión del analizador, debes haber trabajado en estas secciones:
Los siguientes pasos son abrir la página Extensiones del analizador y seleccionar el enfoque de extensión que se usará para definir la extensión del analizador:
Abre la página Extensiones del analizador
La página Extensiones del analizador te permite definir la nueva extensión del analizador.
Puedes abrir la página Extensiones del analizador de las siguientes maneras, desde el menú Configuración, desde una Búsqueda de registros sin procesar o desde una Búsqueda de registros sin procesar heredada:
Abrir desde el menú Configuración
Para abrir la página Extensiones del analizador desde el menú Configuración, haz lo siguiente:
En la barra de navegación, selecciona Configuración del SIEM > Analizadores.
En la tabla Analizadores, se muestra una lista de analizadores predeterminados por tipo de registro.
Busca el tipo de registro que deseas extender, haz clic en el Menú > Crear extensión.
Se abrirá la página Extensiones del analizador.
Abrir desde una búsqueda de registros sin procesar
Para abrir la página Extensiones del analizador desde una Búsqueda de registros sin procesar, haz lo siguiente:
- Ve a Investigación > Búsqueda en el SIEM.
- En el campo de búsqueda, agrega el prefijo
raw =a tu argumento de búsqueda y encierra el término de búsqueda entre comillas. Por ejemplo,raw = "example.com" - Haz clic en Ejecutar búsqueda. Los resultados se muestran en el panel Registros sin procesar.
- Haz clic en un registro (fila) en el panel Registros sin procesar. Se mostrará el panel Event View.
- Haz clic en la pestaña Raw Log en el panel Event View. Se muestra el registro sin procesar.
Haz clic en Administrar el analizador > Crear extensión > Siguiente.
Se abrirá la página Extensiones del analizador.
Abrir desde una búsqueda de registros sin procesar heredada
Para abrir la página Extensiones del analizador desde una Búsqueda de registros sin procesar heredada, haz lo siguiente:
- Usa la Búsqueda de registros sin procesar heredada para buscar registros similares a los que se analizarán.
- Selecciona un evento en el panel Eventos > Cronograma.
- Expande el panel Datos del evento.
Haz clic en Administrar el analizador > Crear extensión > Siguiente.
Se abrirá la página Extensiones del analizador.
Página de extensiones del analizador
En la página, se muestran los paneles Registro sin procesar y Definición de extensión:
Panel Registro sin procesar:
Aquí se muestran datos de registro sin procesar de muestra para el tipo de registro seleccionado. Si abriste la página desde la Búsqueda de registros sin procesar, los datos de muestra son el resultado de tu búsqueda. Puedes darle formato a la muestra con el menú Ver como (RAW, JSON, CSV, XML, etc.) y la casilla de verificación Ajustar texto.
Verifica que la muestra de datos de registro sin procesar que se muestra sea representativa de los registros que procesará la extensión del analizador.
Haz clic en Preview UDM Output para ver el resultado del UDM para los datos de registro sin procesar de muestra.
Panel Definición de la extensión:
Esto te permite definir una extensión del analizador con uno de los dos enfoques de instrucciones de asignación: Asignar campos de datos (sin código) o Escribir fragmento de código. No puedes usar ambos enfoques en la misma extensión del analizador.
Según el enfoque que elijas, puedes especificar los campos de datos de registro de origen para extraerlos de los registros sin procesar entrantes y asignarlos a los campos correspondientes del UDM, o bien puedes escribir un fragmento de código para realizar estas tareas y muchas más.
Selecciona el enfoque de extensión
En el panel Definición de extensión de la página Extensiones del analizador, en el campo Método de extensión, selecciona uno de los siguientes enfoques para crear la extensión del analizador:
Enfoque de asignación de campos de datos (sin código):
Este enfoque te permite especificar los campos en el registro sin procesar y asignarlos a los campos de UDM de destino.
Este enfoque funciona con los siguientes formatos de registros sin procesar:
- JSON nativo, XML nativo o CSV
- Encabezado de Syslog más JSON nativo, XML nativo o CSV. Puedes crear instrucciones de asignación de tipos de campos de datos para los registros sin procesar en los siguientes formatos:
JSON,XML,CSV,SYSLOG + JSON,SYSLOG + XMLySYSLOG + CSV.
Consulta los próximos pasos, Instrucciones para crear mapas sin código (campos de datos del mapa).
Enfoque de escribir fragmento de código:
Este enfoque te permite usar una sintaxis similar a la de Logstash para especificar instrucciones para extraer y transformar valores del registro sin procesar, y asignarlos a los campos del UDM en el registro del UDM.
Los fragmentos de código usan la misma sintaxis y secciones que los analizadores predeterminados (o personalizados). Para obtener más información, consulta Sintaxis del analizador.
Este enfoque funciona con todos los formatos de datos compatibles para ese tipo de registro.
Consulta los próximos pasos en Instrucciones para crear fragmentos de código.
Crea instrucciones sin código (campos de datos del mapa)
El enfoque sin código (también llamado método Map data fields) te permite especificar las rutas de los campos de registro sin procesar y asignarlos a los campos de UDM de destino correspondientes.
Antes de crear una extensión del analizador con el enfoque sin código, debes haber trabajado en estas secciones:
- Crea extensiones de analizador
- Comenzar
- Selecciona el enfoque de extensión y, luego, la opción Asignar campos de datos.
Los siguientes pasos para definir la extensión del analizador son los siguientes:
- Cómo configurar el selector de campos repetidos
- Define una instrucción de asignación de datos para cada campo
- Envía y activa la extensión del analizador
Configura el selector de campos repetidos
En el panel Definición de extensión, en el campo Campos repetidos, configura cómo la extensión del analizador debe guardar un valor en los campos repetidos (campos que admiten un array de valores, por ejemplo, principal.ip):
- Append Values: El valor recién extraído se agrega al conjunto existente de valores almacenados en el campo de array del UDM.
- Reemplazar valores: El valor recién extraído reemplaza el conjunto existente de valores en el campo de array del UDM, que el analizador predeterminado almacenó anteriormente.
La configuración del selector Campos repetidos no afecta a los campos no repetidos.
Para obtener más detalles, consulta Más información sobre el selector de campos repetidos.
Define una instrucción de asignación de datos para cada campo
Define una instrucción de asignación de datos para cada campo que desees extraer del registro sin procesar. La instrucción debe especificar la ruta de acceso del campo de origen en el registro sin procesar y asignarlo al campo de UDM de destino.
Si la muestra de registro sin procesar que se muestra en el panel Registro sin procesar contiene un encabezado de Syslog, se mostrarán los campos Syslog y Destino. (Algunos formatos de registro no contienen un encabezado de Syslog, por ejemplo, JSON nativo, XML nativo o CSV).
Google SecOps necesitará los campos Syslog y Target para preprocesar el encabezado de Syslog y extraer la parte estructurada del registro.
Define estos campos:
Syslog: Es un patrón definido por el usuario que preprocesa y separa un encabezado de Syslog de la parte estructurada de un registro sin procesar.
Especifica el patrón de extracción con Grok y expresiones regulares que identifiquen el encabezado de Syslog y el mensaje de registro sin procesar. Para obtener más detalles, consulta Cómo definir los campos del extractor de Syslog.
Target: Nombre de la variable en el campo Syslog que almacena la parte estructurada del registro.
Especifica el nombre de la variable en el patrón de extracción que almacena la parte estructurada del registro.
Este es un ejemplo de un patrón de extracción y un nombre de variable para los campos Syslog y Target, respectivamente.

Después de ingresar valores en los campos Syslog y Target, haz clic en el botón Validate.
El proceso de validación verifica si hay errores de sintaxis y de análisis, y, luego, devuelve uno de los siguientes resultados:
- Listo: Aparecerán los campos de asignación de datos. Define el resto de la extensión del analizador.
- Falla: Aparece un mensaje de error. Corrige la condición de error antes de continuar.
De manera opcional, define una instrucción previa a la condición.
Una instrucción de condición previa identifica un subconjunto de los registros sin procesar que la extensión del analizador procesa haciendo coincidir un valor estático con un campo del registro sin procesar. Si un registro sin procesar entrante cumple con los criterios de la condición previa, la extensión del analizador aplica la instrucción de asignación. Si los valores no coinciden, la extensión del analizador no aplica la instrucción de asignación.
Completa los siguientes campos:
- Campo de condición previa: Es el identificador del campo en el registro sin procesar que contiene el valor que se comparará. Ingresa la ruta de acceso completa al campo si el formato de los datos de registro es JSON o XML, o la posición de la columna si el formato de datos es CSV.
- Operador de condición previa: Selecciona
EQUALSoNOT EQUALS. - Valor de la condición previa: Es el valor estático que se comparará con el Campo de la condición previa en el registro sin procesar.
Para ver otro ejemplo de una instrucción de condición previa, consulta Sin código: Extrae campos con un valor de condición previa.
Asigna el campo de datos de registro sin procesar al campo de UDM de destino:
Campo de datos sin procesar: Ingresa la ruta de acceso completa al campo si el formato de los datos de registro es JSON (por ejemplo,
jsonPayload.connection.dest_ip) o XML (por ejemplo,/Event/Reason-Code), o la posición de la columna si el formato de los datos es CSV (nota: Las posiciones del índice comienzan en 1).Campo de destino: Ingresa el nombre del campo del UDM completamente calificado en el que se almacenará el valor, por ejemplo,
udm.metadata.collected_timestamp.seconds.
Para seguir agregando más campos, haz clic en Agregar y, luego, ingresa todos los detalles de las instrucciones de asignación para el siguiente campo.
Para ver otro ejemplo de cómo asignar los campos, consulta Sin código: Extrae campos.
Envía y activa la extensión del analizador
Una vez que hayas definido las instrucciones de asignación de datos para todos los campos que deseas extraer del registro sin procesar, envía y activa la extensión del analizador.
Haz clic en Enviar para guardar y validar la instrucción de asignación.
Google SecOps valida las instrucciones de asignación:
- Si el proceso de validación se completa correctamente, el estado cambia a Activo y las instrucciones de asignación comienzan a procesar los datos de registro entrantes.
Si el proceso de validación falla, el estado cambia a Con errores y se muestra un error en el campo Registro sin procesar.
Este es un ejemplo de un error de validación:
ERROR: generic::unknown: pipeline.ParseLogEntry failed: LOG_PARSING_CBN_ERROR: "generic::invalid_argument: pipeline failed: filter mutate (7) failed: copy failure: copy source field \"jsonPayload.dest_instance.region\" must not be empty (try using replace to provide the value before calling copy) "LOG: {"insertId":"14suym9fw9f63r","jsonPayload":{"bytes_sent":"492", "connection":{"dest_ip":"10.12.12.33","dest_port":32768,"protocol":6, "src_ip":"10.142.0.238","src_port":22},"end_time":"2023-02-13T22:38:30.490546349Z", "packets_sent":"15","reporter":"SRC","src_instance":{"project_id":"example-labs", "region":"us-east1","vm_name":"example-us-east1","zone":"us-east1-b"}, "src_vpc":{"project_id":"example-labs","subnetwork_name":"default", "vpc_name":"default"},"start_time":"2023-02-13T22:38:29.024032655Z"}, "logName":"projects/example-labs/logs/compute.googleapis.com%2Fvpc_flows", "receiveTimestamp":"2023-02-13T22:38:37.443315735Z","resource":{"labels": {"location":"us-east1-b","project_id":"example-labs", "subnetwork_id":"00000000000000000000","subnetwork_name":"default"}, "type":"gce_subnetwork"},"timestamp":"2023-02-13T22:38:37.443315735Z"}Estados del ciclo de vida de una extensión del analizador
Las extensiones del analizador tienen los siguientes estados de ciclo de vida:
DRAFT: Es una extensión del analizador recién creada que aún no se envió.VALIDATING: Google SecOps valida las instrucciones de asignación en los registros sin procesar existentes para garantizar que los campos se analicen sin errores.LIVE: La extensión del analizador pasó la validación y ahora está en producción. Extrae y transforma los datos de los registros sin procesar entrantes en registros de UDM.FAILED: La extensión del analizador no pasó la validación.
Más información sobre el selector de campos repetidos
Algunos campos del UDM almacenan un array de valores, como el campo principal.ip. El selector de campos repetidos te permite controlar cómo tu extensión del analizador almacenará los datos recién extraídos en un campo repetido:
Valores agregados:
La extensión del analizador agregará el valor recién extraído al array de valores existentes en el campo del UDM.
Reemplazar valores:
La extensión del analizador reemplazará el array de valores existentes en el campo del UDM por el valor recién extraído.
Una extensión del analizador solo puede asignar datos a un campo repetido cuando este se encuentra en el nivel más bajo de la jerarquía. Por ejemplo:
- Se admite la asignación de valores a
udm.principal.ipporque el campoiprepetido se encuentra en el nivel más bajo de la jerarquía yprincipalno es un campo repetido. - No se admite la asignación de valores a
udm.intermediary.hostnameporqueintermediaryes un campo repetido y no se encuentra en el nivel más bajo de la jerarquía.
En la siguiente tabla, se proporcionan ejemplos de cómo la configuración del selector de Campos repetidos afecta el registro de UDM generado.
| Selección de Campos repetidos | Ejemplo de registro | Configuración de la extensión del analizador | Resultado generado |
|---|---|---|---|
| Valores agregados | {"protoPayload":{"@type":"type.AuditLog","authenticationInfo":{"principalEmail":"admin@cmmar.co"},"requestMetadata":{"callerIp":"1.1.1.1, 2.2.2.2"}}} |
Campo de condición previa: protoPayload.requestMetadata.callerIp
Valor de condición previa: " "
Operador de condición previa: NOT_EQUALS
Campo de datos sin procesar: protoPayload.requestMetadata.callerIp
Campo de destino: event.idm.read_only_udm.principal.ip
|
metadata:{event_timestamp:{}.....}principal:{Ip:"1.1.1.1, 2.2.2.2"}
}
} |
| Valores agregados | {"protoPayload":{"@type":"type.AuditLog","authenticationInfo":{"principalEmail":"admin@cmmar.co"},"requestMetadata":{"callerIp":"2.2.2.2, 3.3.3.3", "name":"Akamai Ltd"}}} |
Condición previa 1:
Campo de condición previa: protoPayload.requestMetadata.callerIp
Valor de condición previa: " "
Operador de condición previa: NOT_EQUALS
Campo de datos sin procesar: protoPayload.requestMetadata.callerIp
Campo de destino: event.idm.read_only_udm.principal.ip
Condición previa 2:
|
Son los eventos que genera el analizador sintáctico prediseñado antes de aplicar la extensión.
metadata:{event_timestamp:{} ... principal:{ip:"1.1.1.1"}}}
Es el resultado después de aplicar la extensión.
|
| Reemplazar valores | {"protoPayload":{"@type":"type..AuditLog","authenticationInfo":{"principalEmail":"admin@cmmar.co"},"requestMetadata":{"callerIp":"2.2.2.2"}}} |
Campo de condición previa: protoPayload.authenticationInfo.principalEmail
Valor de condición previa: " "
Operador de condición previa: NOT_EQUALS
Campo de datos sin procesar: protoPayload.authenticationInfo.principalEmail
Campo de destino: event.idm.read_only_udm.principal.ip
|
Son los eventos del UDM que genera el analizador sintáctico prediseñado antes de aplicar la extensión.timestamp:{} idm:{read_only_udm:{metadata:{event_timestamp:{} ... principal:{ip:"1.1.1.1"}}}
Salida del UDM después de aplicar la extensión
|
Más información sobre los campos del extractor de Syslog
Los campos del extractor de Syslog te permiten separar el encabezado de Syslog de un registro estructurado definiendo Grok, una expresión regular y un token con nombre en el patrón de expresión regular para almacenar el resultado.
Define los campos del extractor de Syslog
Los valores de los campos Syslog y Target funcionan en conjunto para definir cómo la extensión del analizador separa el encabezado de Syslog de la parte estructurada de un registro sin procesar. En el campo Syslog, define una expresión con una combinación de Grok y sintaxis de expresiones regulares. La expresión incluye un nombre de variable que identifica la parte estructurada del registro sin procesar. En el campo Target, especifica ese nombre de variable.
En el siguiente ejemplo, se ilustra cómo funcionan estos campos en conjunto.
Este es un ejemplo de un registro sin procesar:
<13>1 2022-09-14T15:03:04+00:00 fieldname fieldname - - - {"timestamp": "2021-03-14T14:54:40.842152+0000","flow_id": 1885148860701096, "src_ip": "10.11.22.1","src_port": 51972,"dest_ip": "1.2.3.4","dest_port": 55291,"proto": "TCP"}
El registro sin procesar contiene las siguientes secciones:
Encabezado de Syslog:
<13> 2022-09-14T15:03:04+00:00 fieldname fieldname - - -Evento con formato JSON:
{"timestamp": "2021-03-14T14:54:40.842152+0000","flow_id": 1885148860701096, "src_ip": "10.11.22.1","src_port": 51972,"dest_ip": "1.2.3.4","dest_port": 55291,"proto": "TCP"}
Para separar el encabezado de Syslog de la parte JSON del registro sin procesar, usa la siguiente expresión de ejemplo en el campo Syslog:
%{TIMESTAMP_ISO8601} %{WORD} %{WORD} ([- ]+)?%{GREEDYDATA:msg}
- Esta parte de la expresión identifica el encabezado de Syslog:
%{TIMESTAMP\_ISO8601} %{WORD} %{WORD} ([- ]+)? - Esta parte de la expresión captura el segmento JSON del registro sin procesar:
%{GREEDYDATA:msg}
En este ejemplo, se incluye el nombre de la variable msg. Tú eliges el nombre de la variable.
La extensión del analizador extrae el segmento JSON del registro sin procesar y lo asigna a la variable msg.
En el campo Target, ingresa el nombre de la variable msg. El valor almacenado en la variable msg se ingresa en las instrucciones de asignación de campos de datos que creas en la extensión del analizador.
Con el ejemplo de registro sin procesar, el siguiente segmento se ingresa en la instrucción de asignación de datos:
{"timestamp": "2021-03-14T14:54:40.842152+0000","flow_id": 1885148860701096, "src_ip": "10.11.22.1","src_port": 51972,"dest_ip": "1.2.3.4","dest_port": 55291,"proto": "TCP"}
A continuación, se muestran los campos Syslog y Target completados:
En la siguiente tabla, se proporcionan más ejemplos con registros de muestra, el patrón de extracción de Syslog, el nombre de la variable Target y el resultado.
| Ejemplo de registro sin procesar | Campo Syslog | Campo objetivo | Resultado |
|---|---|---|---|
<13>1 2022-07-14T15:03:04+00:00 suricata suricata - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"}" |
%{TIMESTAMP_ISO8601} %{WORD} %{WORD} ([- ]+)?%{GREEDYDATA:msg} |
msg | field_mappings {
field: "msg"
value: "{\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"}"
}
|
<13>1 2022-07-14T15:03:04+00:00 suricata suricata - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\"} - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"} |
%{TIMESTAMP_ISO8601} %{WORD} %{WORD} ([- ]+)?%{GREEDYDATA:msg1} ([- ]+)?%{GREEDYDATA:msg2} |
msg2 | field_mappings {
field: "msg2"
value: "{\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"}"
} |
"<13>1 2022-07-14T15:03:04+00:00 suricata suricata - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\"} - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"}" |
%{TIMESTAMP_ISO8601} %{WORD} %{WORD} ([- ]+)?%{GREEDYDATA:message} ([- ]+)?%{GREEDYDATA:msg2} |
msg2 | Error - message already exists in state and not overwritable. |
Más información sobre la asignación de campos de UDM metadata.event_type
Cuando se asigna un campo metadata.event_type de UDM a un registro de UDM, se valida para garantizar que los campos relacionados obligatorios estén presentes en el registro de UDM. Cada objeto metadata.event_type del UDM requiere un conjunto diferente de campos relacionados. Por ejemplo, un evento USER_LOGIN sin un user no es útil.
Si falta un campo relacionado obligatorio, la validación del UDM muestra un error:
"error": {
"code": 400,
"message": "Request contains an invalid argument.",
"status": "INVALID_ARGUMENT"
}
Un analizador de Grok devuelve un error más detallado:
generic::unknown:
invalid event 0: LOG_PARSING_GENERATED_INVALID_EVENT:
"generic::invalid_argument: udm validation failed: target field is not set"
Para encontrar los campos obligatorios de un event_type de UDM que deseas asignar, usa los siguientes recursos:
Documentación de Google SecOps: Guía de uso del UDM: Campos obligatorios y opcionales del UDM para cada tipo de evento
Recursos no oficiales de terceros: Validación de eventos del UDM
En los casos en que la Guía de uso del UDM no proporciona detalles suficientes, este documento complementa la documentación oficial con los campos obligatorios mínimos del UDM necesarios para completar un
metadata.event_typedeterminado del UDM.Por ejemplo, abre el documento y busca el tipo de evento
GROUP_CREATION.Deberías ver los siguientes campos mínimos de UDM, presentados como un objeto de UDM:
{ "metadata": { "event_timestamp": "2023-07-03T13:01:10.957803Z", "event_type": "GROUP_CREATION" }, "principal": { "user": { "userid": "pinguino" } }, "target": { "group": { "group_display_name": "foobar_users" } } }
Crea instrucciones de fragmentos de código
El enfoque de fragmentos de código te permite usar una sintaxis similar a la de Logstash para definir cómo extraer y transformar valores del registro sin procesar, y asignarlos a campos del UDM en el registro del UDM.
Antes de crear una extensión del analizador con el enfoque de fragmento de código, debes haber completado estas secciones:
- Crea extensiones de analizador
- Comenzar
- Selecciona el enfoque de extensión y, luego, la opción Escribir fragmento de código.
Los siguientes pasos para definir la extensión del analizador son los siguientes:
- Si quieres obtener sugerencias y conocer las prácticas recomendadas, consulta Sugerencias y prácticas recomendadas para escribir instrucciones de fragmentos de código.
- Crea una instrucción de fragmento de código
- Envía una instrucción de fragmento de código
Sugerencias y prácticas recomendadas para escribir instrucciones de fragmentos de código
Las instrucciones de fragmentos de código pueden fallar debido a problemas como patrones de Grok incorrectos, errores en las operaciones de cambio de nombre o reemplazo, o errores de sintaxis. Consulta lo siguiente para obtener sugerencias y prácticas recomendadas:
Crea una instrucción de fragmento de código
Las instrucciones de los fragmentos de código usan la misma sintaxis y secciones que el analizador predeterminado (o personalizado):
- Sección 1: Extrae datos del registro sin procesar.
- Sección 2: Transforma los datos extraídos.
- Sección 3: Asigna uno o más valores a un campo del UDM.
- Sección 4: Vincula los campos de eventos de UDM a la clave
@output.
Para crear una extensión del analizador con el enfoque de fragmento de código, haz lo siguiente:
- En el panel Fragmento de CBN de la página Extensiones de analizadores, ingresa un fragmento de código para crear la extensión del analizador.
- Haz clic en Validate para validar las instrucciones de asignación.
Ejemplos de instrucciones de fragmentos de código
En el siguiente ejemplo, se ilustra un fragmento de código.
Este es un ejemplo del registro sin procesar:
{
"insertId": "00000000",
"jsonPayload": {
...section omitted for brevity...
"packets_sent": "4",
...section omitted for brevity...
},
"timestamp": "2022-05-03T01:45:00.150614953Z"
}
Este es un ejemplo de un fragmento de código que asigna el valor de jsonPayload.packets_sent al campo network.sent_bytes del UDM:
filter {
mutate {
replace => {
"jsonPayload.packets_sent" => ""
}
}
# Section 1. extract data from the raw JSON log
json {
source => "message"
array_function => "split_columns"
on_error => "_not_json"
}
if [_not_json] {
drop {
tag => "TAG_UNSUPPORTED"
}
} else {
# Section 2. transform the extracted data
if [jsonPayload][packets_sent] not in ["", 0] {
mutate {
convert => {
"jsonPayload.packets_sent" => "uinteger"
}
on_error => "_exception1"
}
# Section 3. assign the value to a UDM field
mutate {
Replace => {
"event.idm.read_only_udm.network.sent_bytes" => "jsonPayload.packets_sent"
}
on_error => "_exception2"
}
if ![_exception1] and![_exception2] {
# Section 4. Bind the UDM fields to the @output key
mutate {
merge => {
"@output" => "event"
}
}
}
}
}
}
Envía una instrucción de fragmento de código
Haz clic en Enviar para guardar las instrucciones de asignación.
Google SecOps valida las instrucciones de asignación.
- Si el proceso de validación se completa correctamente, el estado cambia a Activo y las instrucciones de asignación comienzan a procesar los datos de registro entrantes.
- Si el proceso de validación falla, el estado cambia a Con errores y se muestra un error en el campo Registro sin procesar.
Administra las extensiones de analizador existentes
Puedes ver, editar, borrar y controlar el acceso a las extensiones del analizador existentes.
Cómo ver una extensión del analizador existente
- En la barra de navegación, selecciona Configuración del SIEM > Analizadores.
- En la lista de analizadores, busca el analizador (tipo de registro) que deseas ver.
Los analizadores con una extensión de analizador se indican con el texto
EXTENSIONjunto a su nombre. Ve a esa fila y, luego, haz clic en Menú > Ver extensión.
Aparecerá la pestaña Extension de View Custom/Prebuilt Parser, en la que se muestran detalles sobre la extensión del analizador. De forma predeterminada, el panel de resumen muestra la extensión del analizador
LIVE.
Cómo editar una extensión del analizador
Abre View Custom/Prebuilt Parser > Pestaña Extension, como se describe en Cómo ver una extensión de analizador existente.
Haz clic en el botón Editar extensión.
Aparecerá la página Extensiones del analizador.
Edita la extensión del analizador.
Para cancelar la edición y descartar los cambios, haz clic en Descartar borrador.
Para borrar la extensión del analizador en cualquier momento, haz clic en Borrar extensión fallida.
Cuando termines de editar la extensión del analizador, haz clic en Enviar.
Se ejecutará el proceso de validación para validar la configuración nueva.
Cómo borrar una extensión del analizador
Abre la pestaña Extensión en Ver el analizador personalizado o prediseñado, como se describe en Cómo ver una extensión de analizador existente.
Haz clic en el botón Borrar extensión.
Controla el acceso a las extensiones del analizador
De forma predeterminada, los usuarios con el rol de administrador pueden acceder a las extensiones del analizador. Puedes controlar quién puede ver y administrar las extensiones del analizador. Para obtener más información sobre cómo administrar usuarios y grupos, o asignar roles, consulta Control de acceso basado en roles.
En la siguiente tabla, se resumen los nuevos roles de Google SecOps.
| Función | Acción | Descripción |
|---|---|---|
| Analizador | Borrar | Borra las extensiones del analizador. |
| Analizador | Editar | Crear y editar extensiones de analizador |
| Analizador | Ver | Ver las extensiones del analizador |
Cómo quitar asignaciones de campos de UDM con extensiones del analizador
Puedes usar extensiones del analizador para quitar una asignación de campos del UDM existente.
- Haz clic en SIEM Settings > Parsers.
- Usa cualquiera de los siguientes métodos para ver la página de la extensión Parser:
- En el caso de una extensión existente, haz clic en Menú > Extender el analizador > Ver extensión.
- En el caso de las extensiones de analizador nuevas, haz clic en Menú > Extender el analizador > Crear extensión.
Selecciona Escribir fragmento de código como el método de extensión para agregar un fragmento de código personalizado que quite valores para campos de UDM específicos.
En el caso de una extensión existente, en el panel Extensión del analizador, haz clic en Editar y, luego, agrega el fragmento de código.
Consulta Fragmento de código: Quita las asignaciones existentes para ver ejemplos de fragmentos.
Sigue los pasos que se indican en Envía una instrucción de fragmento de código para enviar la extensión.
¿Necesitas más ayuda? Obtén respuestas de miembros de la comunidad y profesionales de Google SecOps.