Introduction to vector search
This document provides an overview of vector search in BigQuery. Vector search is a technique to compare similar objects using embeddings, and it is used to power Google products, including Google Search, YouTube, and Google Play. You can use vector search to perform searches at scale. When you use vector indexes with vector search, you can take advantage of foundational technologies like inverted file indexing (IVF) and the ScaNN algorithm.
Vector search is built on embeddings. Embeddings are high-dimensional numerical vectors that represent a given entity, like a piece of text or an audio file. Machine learning (ML) models use embeddings to encode semantics about such entities to make it easier to reason about and compare them. For example, a common operation in clustering, classification, and recommendation models is to measure the distance between vectors in an embedding space to find items that are most semantically similar.
This concept of semantic similarity and distance in an embedding space is visually demonstrated when you consider how different items might be plotted. For example, terms like cat, dog, and lion, which all represent types of animals, are grouped close together in this space due to their shared semantic characteristics. Similarly, terms like car, truck, and the more generic term vehicle would form another cluster. This is shown in the following image:
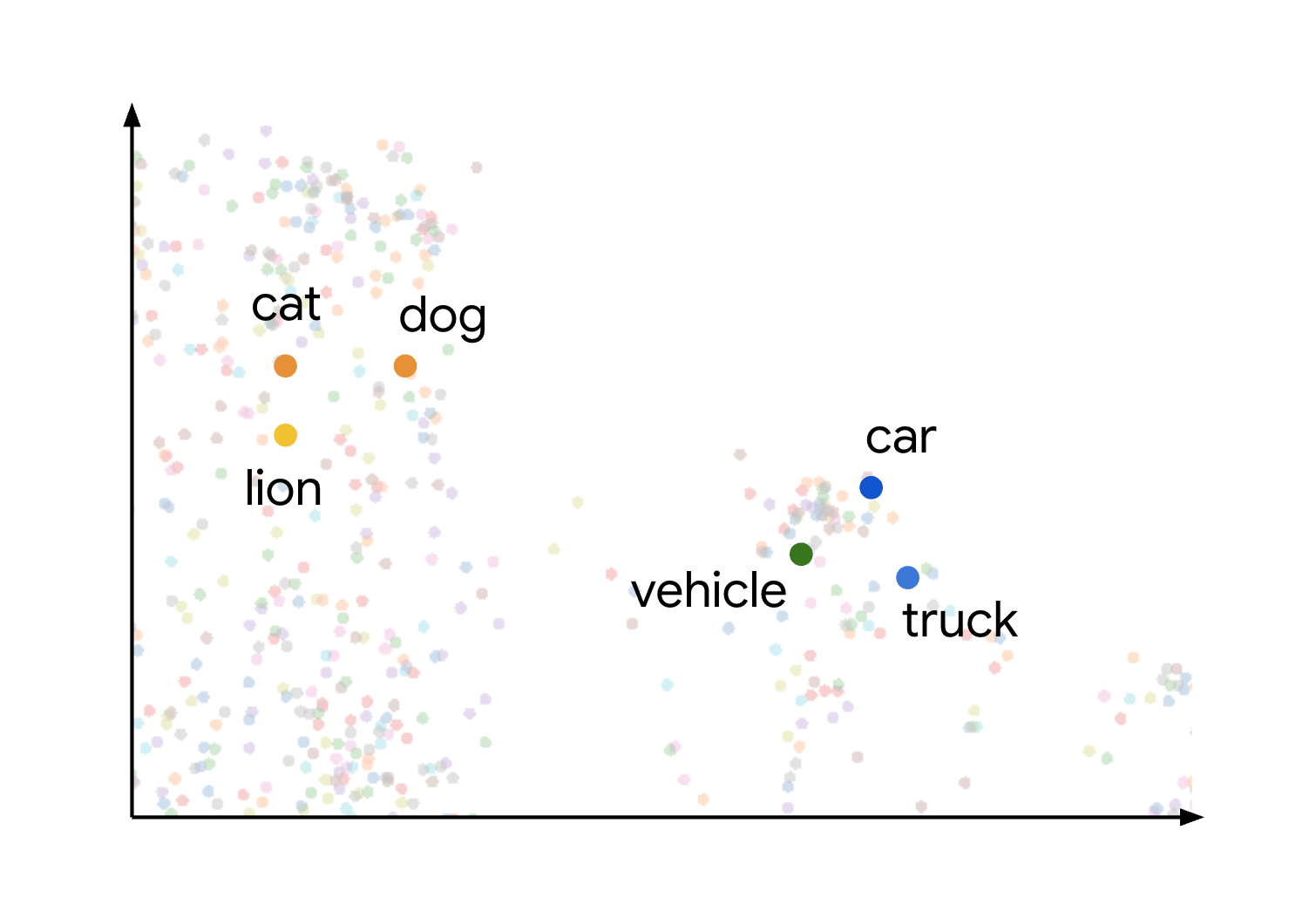
You can see that the animal and vehicle clusters are positioned far apart from each other. The separation between the groups illustrates the principle that the closer objects are in the embedding space, the more semantically similar they are, and greater distances indicate greater semantic dissimilarity.
BigQuery provides an end-to-end experience for generating embeddings, indexing content, and performing vector searches. You can complete each of these tasks independently, or in a single journey. For a tutorial that shows how to complete all of these tasks, see Perform semantic search and retrieval-augmented generation.
To perform a vector search by using SQL, you use the
VECTOR_SEARCH function.
You can optionally create a vector index by
using the
CREATE VECTOR INDEX statement.
When a vector index is used, VECTOR_SEARCH uses the
Approximate Nearest Neighbor
search technique to improve vector search performance, with the
trade-off of reducing
recall
and so returning more approximate results. Without a vector index,
VECTOR_SEARCH uses
brute force search
to measure distance for every record. You can also choose to use brute
force to get exact results even when a vector index is available.
This document focuses on the SQL approach, but you can also perform vector searches by using BigQuery DataFrames in Python. For a notebook that illustrates the Python approach, see Build a Vector Search application using BigQuery DataFrames.
Use cases
The combination of embedding generation and vector search enables many interesting use cases. Some possible use cases are as follows:
- Retrieval-augmented generation (RAG): Parse documents, perform vector search on content, and generate summarized answers to natural language questions using Gemini models, all within BigQuery. For a notebook that illustrates this scenario, see Build a Vector Search application using BigQuery DataFrames.
- Recommending product substitutes or matching products: Enhance ecommerce applications by suggesting product alternatives based on customer behavior and product similarity.
- Log analytics: Help teams proactively triage anomalies in logs and accelerate investigations. You can also use this capability to enrich context for LLMs, in order to improve threat detection, forensics, and troubleshooting workflows. For a notebook that illustrates this scenario, see Log Anomaly Detection & Investigation with Text Embeddings + BigQuery Vector Search.
- Clustering and targeting: Segment audiences with precision. For example, a hospital chain could cluster patients using natural language notes and structured data, or a marketer could target ads based on query intent. For a notebook that illustrates this scenario, see Create-Campaign-Customer-Segmentation.
- Entity resolution and deduplication: Cleanse and consolidate data. For example, an advertising company could deduplicate personally identifiable information (PII) records, or a real estate company could identify matching mailing addresses.
Pricing
The VECTOR_SEARCH function and the CREATE VECTOR INDEX statement use
BigQuery compute pricing.
VECTOR_SEARCHfunction: You are charged for similarity search, using on-demand or editions pricing.- On-demand: You are charged for the amount of bytes scanned in the base table, the index, and the search query.
Editions pricing: You are charged for the slots required to complete the job within your reservation edition. Larger, more complex similarity calculations incur more charges.
CREATE VECTOR INDEXstatement: There is no charge for the processing required to build and refresh your vector indexes as long as the total size of the indexed table data is below your per-organization limit. To support indexing beyond this limit, you must provide your own reservation for handling the index management jobs.
Storage is also a consideration for embeddings and indexes. The amount of bytes stored as embeddings and indexes are subject to active storage costs.
- Vector indexes incur storage costs when they are active.
- You can find the index storage size by using the
INFORMATION_SCHEMA.VECTOR_INDEXESview. If the vector index is not yet at 100% coverage, you are still charged for whatever has been indexed. You can check index coverage by using theINFORMATION_SCHEMA.VECTOR_INDEXESview.
Quotas and limits
For more information, see Vector index limits.
Limitations
Queries that contain the VECTOR_SEARCH function aren't accelerated by
BigQuery BI Engine.
What's next
- Learn more about creating a vector index.
- Learn how to perform a vector search using the
VECTOR_SEARCHfunction. - Try the Search embeddings with vector search tutorial to learn how to create a vector index, and then do a vector search for embeddings both with and without the index.
Try the Perform semantic search and retrieval-augmented generation tutorial to learn how to do the following tasks:
- Generate text embeddings.
- Create a vector index on the embeddings.
- Perform a vector search with the embeddings to search for similar text.
- Perform retrieval-augmented generation (RAG) by using vector search results to augment the prompt input and improve results.
Try the Parse PDFs in a retrieval-augmented generation pipeline tutorial to learn how to create a RAG pipeline based on parsed PDF content.