BigLake tables for Apache Iceberg in BigQuery
BigLake tables for Apache Iceberg in BigQuery, (hereafter, BigLake Iceberg tables in BigQuery) provide the foundation for building open-format lakehouses on Google Cloud. BigLake Iceberg tables in BigQuery offer the same fully managed experience as standard BigQuery tables, but store data in customer-owned storage buckets. BigLake Iceberg tables in BigQuery support the open Iceberg table format for better interoperability with open-source and third-party compute engines on a single copy of data.
BigLake tables for Apache Iceberg in BigQuery are distinct from Apache Iceberg external tables. BigLake tables for Apache Iceberg in BigQuery are fully managed tables that are modifiable directly in BigQuery, while Apache Iceberg external tables are customer-managed and offer read-only access from BigQuery.
BigLake Iceberg tables in BigQuery support the following features:
- Table mutations using GoogleSQL data manipulation language (DML).
- Unified batch and high throughput streaming using the Storage Write API through BigLake connectors like Spark, Dataflow, and other engines.
- Iceberg V2 snapshot export and automatic refresh on each table mutation for direct query access with open-source and third-party query engines.
- Schema evolution, which lets you add, drop, and rename columns to suit your needs. This feature also lets you change an existing column's data type and column mode. For more information, see type conversion rules.
- Automatic storage optimization, including adaptive file sizing, automatic clustering, garbage collection, and metadata optimization.
- Time travel for historical data access in BigQuery.
- Column-level security and data masking.
- Multi-statement transactions (in Preview).
Architecture
BigLake Iceberg tables in BigQuery bring the convenience of BigQuery resource management to tables that reside in your own cloud buckets. You can use BigQuery and open-source compute engines on these tables without moving the data out of the buckets that you control. You must configure a Cloud Storage bucket before you start using BigLake Iceberg tables in BigQuery.
BigLake Iceberg tables in BigQuery utilize BigLake metastore as the unified runtime metastore for all Iceberg data. BigLake metastore provides a single source of truth for managing metadata from multiple engines and allows for engine interoperability.
The following diagram shows the managed table architecture at a high level:
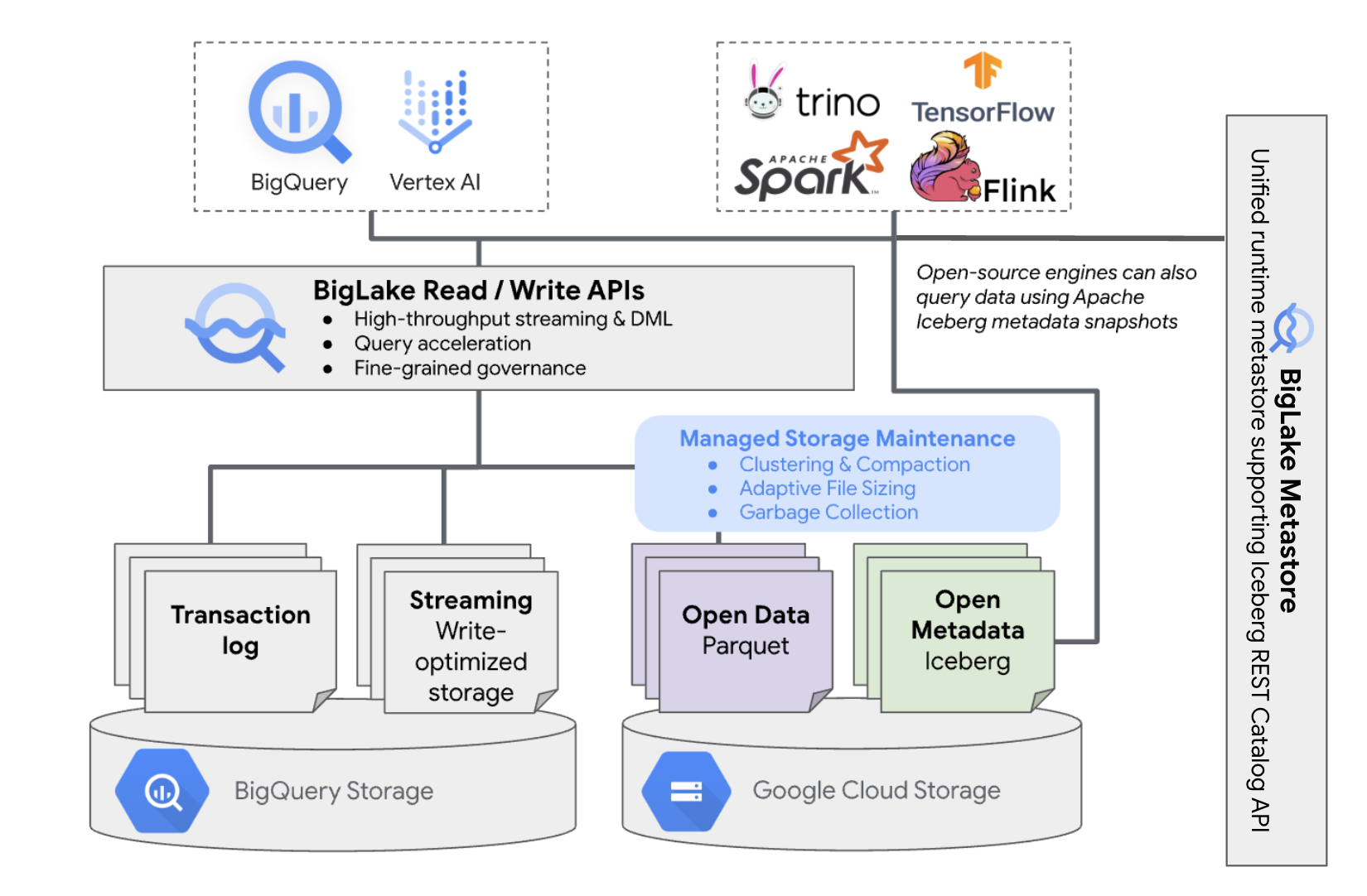
This table management has the following implications on your bucket:
- BigQuery creates new data files in the bucket in response to write requests and background storage optimizations, such as DML statements and streaming.
- When you delete a managed table in BigQuery, BigQuery garbage collects the associated data files in Cloud Storage after the expiration of the time travel period.
Creating a BigLake Iceberg table in BigQuery is similar to creating BigQuery tables. Because it stores data in open formats on Cloud Storage, you must do the following:
- Specify the
Cloud resource connection
with
WITH CONNECTIONto configure the connection credentials for BigLake to access Cloud Storage. - Specify the file format of data storage as
PARQUETwith thefile_format = PARQUETstatement. - Specify the open-source metadata table format as
ICEBERGwith thetable_format = ICEBERGstatement.
Best practices
Directly changing or adding files to the bucket outside of BigQuery can lead to data loss or unrecoverable errors. The following table describes possible scenarios:
| Operation | Consequences | Prevention |
|---|---|---|
| Add new files to the bucket outside BigQuery. | Data loss: New files or objects added outside of BigQuery are not tracked by BigQuery. Untracked files are deleted by background garbage collection processes. | Add data exclusively through BigQuery. This lets
BigQuery track the files and prevent them from being
garbage collected. To prevent accidental additions and data loss, we also recommend restricting external tool write permissions on buckets containing BigLake Iceberg tables in BigQuery. |
| Create a new BigLake Iceberg table in BigQuery in a non-empty prefix. | Data loss: Extant data isn't tracked by BigQuery, so these files are considered untracked, and deleted by background garbage collection processes. | Only create new BigLake Iceberg tables in BigQuery in empty prefixes. |
| Modify or replace BigLake Iceberg table in BigQuery data files. | Data loss: On external modification or replacement,
the table fails a consistency check and becomes unreadable. Queries
against the table fail. There is no self-serve way to recover from this point. Contact support for data recovery assistance. |
Modify data exclusively through BigQuery. This lets
BigQuery track the files and prevent them from being
garbage collected. To prevent accidental additions and data loss, we also recommend restricting external tool write permissions on buckets containing BigLake Iceberg tables in BigQuery. |
| Create two BigLake Iceberg tables in BigQuery on the same or overlapping URIs. | Data loss: BigQuery doesn't bridge identical URI instances of BigLake Iceberg tables in BigQuery. Background garbage collection processes for each table will consider the opposite table's files as untracked, and delete them, causing data loss. | Use unique URIs for each BigLake Iceberg table in BigQuery. |
Cloud Storage bucket configuration best practices
The configuration of your Cloud Storage bucket and its connection with BigLake have a direct impact on the performance, cost, data integrity, security, and governance of your BigLake Iceberg tables in BigQuery. The following are best practices to help with this configuration:
Select a name that clearly indicates that the bucket is only meant for BigLake Iceberg tables in BigQuery.
Choose single-region Cloud Storage buckets that are co-located in the same region as your BigQuery dataset. This coordination improves performance and lowers costs by avoiding data transfer charges.
By default, Cloud Storage stores data in the Standard storage class, which provides sufficient performance. To optimize data storage costs, you can enable Autoclass to automatically manage storage class transitions. Autoclass starts with the Standard storage class and moves objects that aren't accessed to progressively colder classes in order to reduce storage costs. When the object is read again, it's moved back to the Standard class.
Enable uniform bucket-level access and public access prevention.
Verify that the required roles are assigned to the correct users and service accounts.
To prevent accidental Iceberg data deletion or corruption in your Cloud Storage bucket, restrict write and delete permissions for most users in your organization. You can do this by setting a bucket permission policy with conditions that deny
PUTandDELETErequests for all users, except those that you specify.Apply google-managed or customer-managed encryption keys for extra protection of sensitive data.
Enable audit logging for operational transparency, troubleshooting, and monitoring data access.
Keep the default soft delete policy (7 day retention) to protect against accidental deletions. However, if you find that Iceberg data has been deleted, engage with support rather than restoring objects manually, as objects that are added or modified outside of BigQuery aren't tracked by BigQuery metadata.
Adaptive file sizing, automatic clustering, and garbage collection are enabled automatically and help with optimizing file performance and cost.
Avoid the following Cloud Storage features, as they are unsupported for BigLake Iceberg tables in BigQuery:
- Hierarchical namespaces
- Dual regions and multi-regions
- Object access control lists (ACLs)
- Customer-supplied encryption keys
- Object versioning
- Object lock
- Bucket lock
- Restoring soft-deleted objects with the BigQuery API or bq command-line tool
You can implement these best practices by creating your bucket with the following command:
gcloud storage buckets create gs://BUCKET_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --enable-autoclass \ --public-access-prevention \ --uniform-bucket-level-access
Replace the following:
BUCKET_NAME: the name for your new bucketPROJECT_ID: the ID of your projectLOCATION: the location for your new bucket
BigLake Iceberg table in BigQuery workflows
The following sections describe how to create, load, manage, and query managed tables.
Before you begin
Before creating and using BigLake Iceberg tables in BigQuery, ensure that you have set up a Cloud resource connection to a storage bucket. Your connection needs write permissions on the storage bucket, as specified in the following Required roles section. For more information about required roles and permissions for connections, see Manage connections.
Required roles
To get the permissions that you need to let BigQuery manage tables in your project, ask your administrator to grant you the following IAM roles:
-
To create BigLake Iceberg tables in BigQuery:
-
BigQuery Data Owner (
roles/bigquery.dataOwner) on your project -
BigQuery Connection Admin (
roles/bigquery.connectionAdmin) on your project
-
BigQuery Data Owner (
-
To query BigLake Iceberg tables in BigQuery:
-
BigQuery Data Viewer (
roles/bigquery.dataViewer) on your project -
BigQuery User (
roles/bigquery.user) on your project
-
BigQuery Data Viewer (
-
Grant the connection service account the following roles so it can read and write data in Cloud Storage:
-
Storage Object User (
roles/storage.objectUser) on the bucket -
Storage Legacy Bucket Reader (
roles/storage.legacyBucketReader) on the bucket
-
Storage Object User (
For more information about granting roles, see Manage access to projects, folders, and organizations.
These predefined roles contain the permissions required to let BigQuery manage tables in your project. To see the exact permissions that are required, expand the Required permissions section:
Required permissions
The following permissions are required to let BigQuery manage tables in your project:
-
bigquery.connections.delegateon your project -
bigquery.jobs.createon your project -
bigquery.readsessions.createon your project -
bigquery.tables.createon your project -
bigquery.tables.geton your project -
bigquery.tables.getDataon your project -
storage.buckets.geton your bucket -
storage.objects.createon your bucket -
storage.objects.deleteon your bucket -
storage.objects.geton your bucket -
storage.objects.liston your bucket
You might also be able to get these permissions with custom roles or other predefined roles.
Create BigLake Iceberg tables in BigQuery
To create a BigLake Iceberg table in BigQuery, select one of the following methods:
SQL
CREATE TABLE [PROJECT_ID.]DATASET_ID.TABLE_NAME ( COLUMN DATA_TYPE[, ...] ) CLUSTER BY CLUSTER_COLUMN_LIST WITH CONNECTION {CONNECTION_NAME | DEFAULT} OPTIONS ( file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'STORAGE_URI');
Replace the following:
- PROJECT_ID: the project containing the dataset. If undefined, the command assumes the default project.
- DATASET_ID: an existing dataset.
- TABLE_NAME: the name of the table you're creating.
- DATA_TYPE: the data type of the information that is contained in the column.
- CLUSTER_COLUMN_LIST (optional): a comma-separated list containing up to four columns. They must be top-level, non-repeated columns.
CONNECTION_NAME: the name of the connection. For example,
myproject.us.myconnection.To use a default connection, specify
DEFAULTinstead of the connection string containing PROJECT_ID.REGION.CONNECTION_ID.STORAGE_URI: a fully qualified Cloud Storage URI. For example,
gs://mybucket/table.
bq
bq --project_id=PROJECT_ID mk \ --table \ --file_format=PARQUET \ --table_format=ICEBERG \ --connection_id=CONNECTION_NAME \ --storage_uri=STORAGE_URI \ --schema=COLUMN_NAME:DATA_TYPE[, ...] \ --clustering_fields=CLUSTER_COLUMN_LIST \ DATASET_ID.MANAGED_TABLE_NAME
Replace the following:
- PROJECT_ID: the project containing the dataset. If undefined, the command assumes the default project.
- CONNECTION_NAME: the name of the connection. For
example,
myproject.us.myconnection. - STORAGE_URI: a fully qualified
Cloud Storage URI.
For example,
gs://mybucket/table. - COLUMN_NAME: the column name.
- DATA_TYPE: the data type of the information contained in the column.
- CLUSTER_COLUMN_LIST (optional): a comma-separated list containing up to four columns. They must be top-level, non-repeated columns.
- DATASET_ID: the ID of an existing dataset.
- MANAGED_TABLE_NAME: the name of the table you're creating.
API
Call the
tables.insert'
method with a defined
table resource, similar to the
following:
{ "tableReference": { "tableId": "TABLE_NAME" }, "biglakeConfiguration": { "connectionId": "CONNECTION_NAME", "fileFormat": "PARQUET", "tableFormat": "ICEBERG", "storageUri": "STORAGE_URI" }, "schema": { "fields": [ { "name": "COLUMN_NAME", "type": "DATA_TYPE" } [, ...] ] } }
Replace the following:
- TABLE_NAME: the name of the table that you're creating.
- CONNECTION_NAME: the name of the connection. For
example,
myproject.us.myconnection. - STORAGE_URI: a fully qualified
Cloud Storage URI.
Wildcards
are also supported. For example,
gs://mybucket/table. - COLUMN_NAME: the column name.
- DATA_TYPE: the data type of the information contained in the column.
Import data into BigLake Iceberg tables in BigQuery
The following sections describe how to import data from various table formats into BigLake Iceberg tables in BigQuery.
Standard load data from flat files
BigLake Iceberg tables in BigQuery use BigQuery load jobs to
load external files
into BigLake Iceberg tables in BigQuery. If you have an existing
BigLake Iceberg table in BigQuery, follow
the bq load CLI guide
or the
LOAD SQL guide
to load external data. After loading the data, new Parquet files are written
into the STORAGE_URI/data folder.
If the prior instructions are used without an existing BigLake Iceberg table in BigQuery, a BigQuery table is created instead.
See the following for tool-specific examples of batch loads into managed tables:
SQL
LOAD DATA INTO MANAGED_TABLE_NAME FROM FILES ( uris=['STORAGE_URI'], format='FILE_FORMAT');
Replace the following:
- MANAGED_TABLE_NAME: the name of an existing BigLake Iceberg table in BigQuery.
- STORAGE_URI: a fully qualified
Cloud Storage URI
or a comma-separated list of URIs.
Wildcards
are also supported. For example,
gs://mybucket/table. - FILE_FORMAT: the source table format. For supported formats,
see the
formatrow ofload_option_list.
bq
bq load \ --source_format=FILE_FORMAT \ MANAGED_TABLE \ STORAGE_URI
Replace the following:
- FILE_FORMAT: the source table format. For supported formats,
see the
formatrow ofload_option_list. - MANAGED_TABLE_NAME: the name of an existing BigLake Iceberg table in BigQuery.
- STORAGE_URI: a fully qualified
Cloud Storage URI
or a comma-separated list of URIs.
Wildcards
are also supported. For example,
gs://mybucket/table.
Standard load from Hive-partitioned files
You can load Hive-partitioned files into BigLake Iceberg tables in BigQuery using standard BigQuery load jobs. For more information, see Loading externally partitioned data.
Load streaming data from Pub/Sub
You can load streaming data into BigLake Iceberg tables in BigQuery by using a Pub/Sub BigQuery subscription.
Export data from BigLake Iceberg tables in BigQuery
The following sections describe how to export data from BigLake Iceberg tables in BigQuery into various table formats.
Export data into flat formats
To export a BigLake Iceberg table in BigQuery into a flat format, use the
EXPORT DATA statement
and select a destination format. For more information, see
Exporting data.
Create BigLake Iceberg table in BigQuery metadata snapshots
To create a BigLake Iceberg table in BigQuery metadata snapshot, follow these steps:
Export the metadata into the Iceberg V2 format with the
EXPORT TABLE METADATASQL statement.Optional: Schedule Iceberg metadata snapshot refresh. To refresh an Iceberg metadata snapshot based on a set time interval, use a scheduled query.
Optional: Enable metadata auto-refresh for your project to automatically update your Iceberg table metadata snapshot on each table mutation. To enable metadata auto-refresh, contact bigquery-tables-for-apache-iceberg-help@google.com.
EXPORT METADATAcosts are applied on each refresh operation.
The following example creates a scheduled query named My Scheduled Snapshot Refresh Query
using the DDL statement EXPORT TABLE METADATA FROM mydataset.test. The DDL
statement runs every 24 hours.
bq query \ --use_legacy_sql=false \ --display_name='My Scheduled Snapshot Refresh Query' \ --schedule='every 24 hours' \ 'EXPORT TABLE METADATA FROM mydataset.test'
View BigLake Iceberg table in BigQuery metadata snapshot
After you refresh the BigLake Iceberg table in BigQuery metadata snapshot you can
find the snapshot in the Cloud Storage URI
that the BigLake Iceberg table in BigQuery was originally created in. The /data
folder contains the Parquet file data shards, and the /metadata folder contains
the BigLake Iceberg table in BigQuery metadata snapshot.
SELECT table_name, REGEXP_EXTRACT(ddl, r"storage_uri\s*=\s*\"([^\"]+)\"") AS storage_uri FROM `mydataset`.INFORMATION_SCHEMA.TABLES;
Note that mydataset and table_name are placeholders for your actual dataset and table.
Read BigLake Iceberg tables in BigQuery with Apache Spark
The following sample sets up your environment to use Spark SQL with Apache Iceberg, and then executes a query to fetch data from a specified BigLake Iceberg table in BigQuery.
spark-sql \ --packages org.apache.iceberg:iceberg-spark-runtime-ICEBERG_VERSION_NUMBER \ --conf spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog \ --conf spark.sql.catalog.CATALOG_NAME.type=hadoop \ --conf spark.sql.catalog.CATALOG_NAME.warehouse='BUCKET_PATH' \ # Query the table SELECT * FROM CATALOG_NAME.FOLDER_NAME;
Replace the following:
- ICEBERG_VERSION_NUMBER: the current version of Apache Spark Iceberg runtime. Download the latest version from Spark Releases.
- CATALOG_NAME: the catalog to reference your BigLake Iceberg table in BigQuery.
- BUCKET_PATH: the path to the bucket containing the
table files. For example,
gs://mybucket/. - FOLDER_NAME: the folder containing the table files.
For example,
myfolder.
Modify BigLake Iceberg tables in BigQuery
To modify a BigLake Iceberg table in BigQuery, follow the steps shown in Modifying table schemas.
Use multi-statement transactions
To gain access to multi-statement transactions for BigLake Iceberg tables in BigQuery, fill out the sign-up form.
Pricing
BigLake Iceberg table in BigQuery pricing consists of storage, storage optimization, and queries and jobs.
Storage
BigLake Iceberg tables in BigQuery store all data in Cloud Storage. You are charged for all data stored, including historical table data. Cloud Storage data processing and transfer charges might also apply. Some Cloud Storage operation fees might be waived for operations that are processed through BigQuery or the BigQuery Storage API. There are no BigQuery-specific storage fees. For more information, see Cloud Storage Pricing.
Storage optimization
BigLake Iceberg tables in BigQuery perform automatic table management, including compaction, clustering, garbage collection, and BigQuery metadata generation/refresh to optimize query performance and reduce storage costs. Compute resource usage for BigLake table management is billed in Data Compute Units (DCUs) over time, in per second increments. For more details, see BigLake Iceberg table in BigQuery pricing.
Data export operations taking place while streaming through the BigQuery Storage Write API are included in Storage Write API pricing and are not charged as background maintenance. For more information, see Data ingestion pricing.
Storage optimization and EXPORT TABLE METADATA usage are visible in the INFORMATION_SCHEMA.JOBS view.
Queries and jobs
Similar to BigQuery tables, you are charged for queries and bytes read (per TiB) if you are using BigQuery on-demand pricing, or slot consumption (per slot hour) if you are using BigQuery capacity compute pricing.
BigQuery pricing also applies to the BigQuery Storage Read API and the BigQuery Storage Write API.
Load and export operations (such as EXPORT METADATA) use
Enterprise edition pay as you go slots.
This differs from BigQuery tables, which are not charged for
these operations. If PIPELINE reservations with Enterprise or
Enterprise Plus slots are available, load and export operations
preferentially use these reservation slots instead.
Limitations
BigLake Iceberg tables in BigQuery have the following limitations:
- BigLake Iceberg tables in BigQuery don't support
renaming operations or
ALTER TABLE RENAME TOstatements. - BigLake Iceberg tables in BigQuery don't support
table copies or
CREATE TABLE COPYstatements. - BigLake Iceberg tables in BigQuery don't support
table clones or
CREATE TABLE CLONEstatements. - BigLake Iceberg tables in BigQuery don't support
table snapshots or
CREATE SNAPSHOT TABLEstatements. - BigLake Iceberg tables in BigQuery don't support the following table schema:
- Empty schema
- Schema with
BIGNUMERIC,INTERVAL,JSON,RANGE, orGEOGRAPHYdata types. - Schema with field collations.
- Schema with default value expressions.
- BigLake Iceberg tables in BigQuery don't support the following schema
evolution cases:
NUMERICtoFLOATtype coercionsINTtoFLOATtype coercions- Adding new nested fields to an existing
RECORDcolumns using SQL DDL statements
- BigLake Iceberg tables in BigQuery display a 0-byte storage size when queried by the console or APIs.
- BigLake Iceberg tables in BigQuery don't support materialized views.
- BigLake Iceberg tables in BigQuery don't support authorized views, but column-level access control is supported.
- BigLake Iceberg tables in BigQuery don't support change data capture (CDC) updates.
- BigLake Iceberg tables in BigQuery don't support managed disaster recovery
- BigLake Iceberg tables in BigQuery don't support partitioning. Consider clustering as an alternative.
- BigLake Iceberg tables in BigQuery don't support row-level security.
- BigLake Iceberg tables in BigQuery don't support fail-safe windows.
- BigLake Iceberg tables in BigQuery don't support extract jobs.
- The
INFORMATION_SCHEMA.TABLE_STORAGEview doesn't include BigLake Iceberg tables in BigQuery. - BigLake Iceberg tables in BigQuery aren't supported as query result
destinations. You can instead use the
CREATE TABLEstatement with theAS query_statementargument to create a table as the query result destination. CREATE OR REPLACEdoesn't support replacing standard tables with BigLake Iceberg tables in BigQuery, or BigLake Iceberg tables in BigQuery with standard tables.- Batch loading and
LOAD DATAstatements only support appending data to existing BigLake Iceberg tables in BigQuery. - Batch loading and
LOAD DATAstatements don't support schema updates. TRUNCATE TABLEdoesn't support BigLake Iceberg tables in BigQuery. There are two alternatives:CREATE OR REPLACE TABLE, using the same table creation options.DELETE FROMtableWHEREtrue
- The
APPENDStable-valued function (TVF) doesn't support BigLake Iceberg tables in BigQuery. - Iceberg metadata might not contain data that was streamed to BigQuery by the Storage Write API within the last 90 minutes.
- Record-based paginated access using
tabledata.listdoesn't support BigLake Iceberg tables in BigQuery. - BigLake Iceberg tables in BigQuery don't support linked datasets.
- Only one concurrent mutating DML statement (
UPDATE,DELETE, andMERGE) runs for each BigLake Iceberg table in BigQuery. Additional mutating DML statements are queued.