In un'applicazione aziendale tradizionale, le richieste dei client vengono eseguite all'interno di una transazione di database. In genere, tutti i dati necessari per completare una richiesta vengono archiviati in un singolo database che ha proprietà ACID (il termine ACID sta per atomicità, coerenza, isolamento e durabilità). Pertanto, puoi garantire coerenza usando le funzionalità transazionali del sistema di database relazionali. Quando si verifica un problema durante la transazione, il sistema di database può eseguire automaticamente il rollback e riprovare la transazione. Questo documento descrive come progettare flussi di lavoro transazionali utilizzando Cloud Run, Pub/Sub, Flussi di lavoro e Firestore in modalità Datastore (Datastore). È destinata agli sviluppatori di applicazioni che vogliono progettare flussi di lavoro transazionali in un'applicazione basata su microservizi.
Il documento fa parte di una serie composta dalle seguenti parti:
- Flussi di lavoro transazionali nell'architettura di microservizi su Google Cloud (questo documento).
- Deployment di un'applicazione di esempio di flussi di lavoro transazionali nell'architettura di microservizi: un tutorial che mostra come eseguire il deployment e utilizzare un'applicazione di esempio che utilizza l'architettura descritta in questo documento.
Transazioni end-to-end nei microservizi
Nelle architetture di microservizi, una transazione end-to-end potrebbe riguardare più servizi. Ogni servizio può fornire una funzionalità specifica e avere un proprio database indipendente, come mostrato nel diagramma seguente.

Come mostrato nell'immagine precedente, un client accede a più microservizi attraverso un gateway. A causa di questo accordo di accesso client, non puoi fare affidamento sulle funzionalità transazionali di un singolo database per consentire al tuo sistema di database di recuperare gli errori e garantire coerenza. Ti consigliamo invece di implementare un flusso di lavoro transazionale nell'architettura dei microservizi.
Questo documento descrive due pattern che puoi utilizzare per implementare un flusso di lavoro transazionale in un'architettura di microservizi. Gli schemi sono i seguenti:
- Saga basata sulla coreografia
- Orchestrazione sincrona
Applicazione di esempio
Per dimostrare il flusso di lavoro, questo documento utilizza una semplice applicazione di esempio in grado di gestire le transazioni relative agli ordini per un sito web di shopping. L'applicazione gestisce clienti e ordini. I clienti dispongono di un massimale di credito e la richiesta deve confermare che un nuovo ordine non superi il massimale di credito del cliente. Come mostrato nel diagramma seguente, il flusso di lavoro transazionale viene eseguito sui seguenti microservizi: Order e Customer.

Il flusso di lavoro è il seguente:
- Un cliente invia una richiesta di ordine in cui sono specificati un ID cliente e una serie di articoli.
- Il servizio
Orderassegna un ID ordine e archivia le informazioni sull'ordine nel database. Lo stato dell'ordine è contrassegnato comepending. - Il servizio
Customeraumenta l'utilizzo del credito del cliente archiviato nel database in base al numero di articoli ordinati. Ad esempio, un aumento di 100 crediti per un singolo elemento. - Se l'utilizzo totale del credito è inferiore o uguale al limite predefinito, l'ordine viene accettato e il servizio
Orderne modifica lo stato nel database inaccepted. - Se l'utilizzo totale del credito è superiore al limite predefinito, il servizio
Ordermodifica lo stato dell'ordine inrejected. In questo caso, l'utilizzo del credito non viene aumentato.
Il servizio Ordina
Il servizio Order gestisce lo stato di un ordine. Genera e archivia un record di ordine nel database Order per ogni richiesta del client. Il record è costituito dalle seguenti colonne:
Order_id: l'ID dell'ordine. Questo ID è generato dal servizioOrder.Customer_id: l'ID cliente.Number: la quantità di articoli inclusi nell'ordine.Status: lo stato di un ordine.
L'assistenza clienti
Il servizio Customer gestisce i crediti dei clienti. Genera e archivia un record del cliente nel database Customer per ogni richiesta del client. Il record è costituito dalle seguenti colonne:
Customer_id: l'ID del cliente, generato dal servizioCustomer.Credit: il numero di crediti utilizzati dal cliente. Aumenta quando il cliente ordina gli articoli.Limit: massimale di credito individuale del cliente. Un ordine viene rifiutato quando il credito del cliente supera il limite impostato.
Saga basata sulla coreografia
Questa sezione descrive come implementare un pattern di microservizi saga basato su coreografie in un flusso di lavoro transazionale.
Panoramica dell'architettura
In un pattern di microservizi basato su coreografia, i microservizi funzionano come sistema distribuito in modo autonomo. Quando un servizio cambia lo stato della propria entità, pubblica un evento per notificare gli aggiornamenti agli altri servizi. L'evento di notifica attiva l'azione di altri servizi. In questo modo, più servizi collaborano per completare un processo transazionale. La comunicazione tra i microservizi è asincrona. Quando un servizio pubblica un evento, non vengono inviate informazioni al servizio di pubblicazione per confermare i servizi che lo ricevono o quando lo ricevono.
L'immagine seguente mostra un esempio di pattern di microservizi saga basati su coreografie.

L'architettura di esempio mostrata nell'immagine precedente è la seguente:
- Cloud Run funge da runtime dei microservizi.
- Pub/Sub funge da servizio di messaggistica per distribuire eventi tra microservizi.
- Datastore fornisce un database per ogni servizio.
Puoi utilizzare Datastore per archiviare gli eventi prima di pubblicarli. Come spiegato nel processo di pubblicazione degli eventi, i microservizi archiviano gli eventi anziché pubblicarli immediatamente.
Inizialmente, i servizi Order e Customer archiviano gli eventi nel database degli eventi.
Successivamente, gli eventi archiviati vengono pubblicati periodicamente utilizzando Cloud Scheduler.
Cloud Scheduler richiama il servizio event-publisher, che pubblica gli eventi. Questo flusso di eventi è mostrato nell'immagine seguente:

Flusso di lavoro transazionale
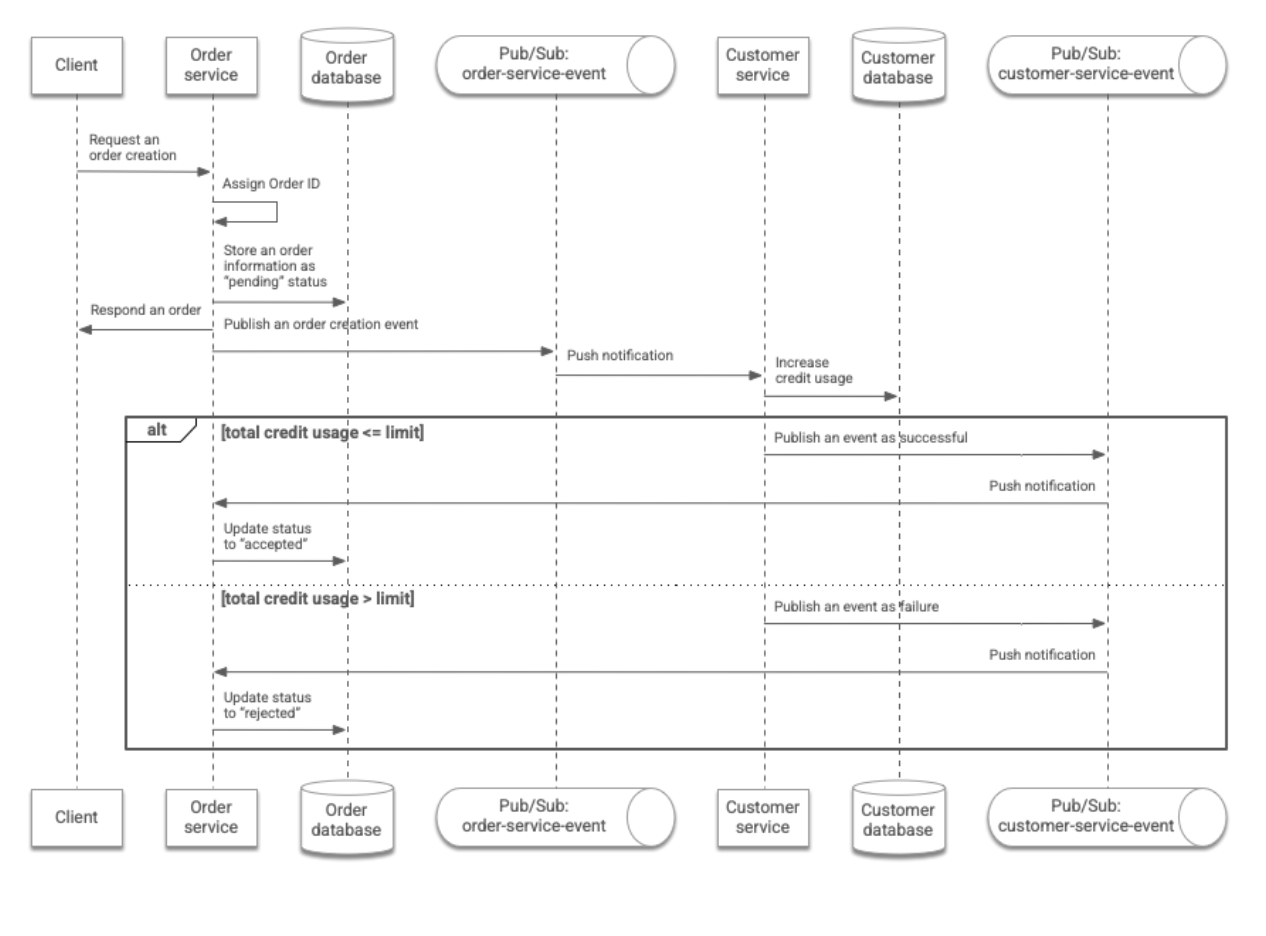
In un flusso di lavoro transazionale, due servizi comunicano tra loro tramite eventi. In questa architettura, l'ordine del cliente viene elaborato come segue:
- Il cliente invia una richiesta di ordine in cui sono specificati l'ID del cliente e il numero di articoli ordinati. La richiesta viene inviata al servizio
Ordertramite un'API REST. - Il servizio
Orderassegna un ID all'ordine e archivia le informazioni nell'ordine nel databaseOrder. Lo stato dell'ordine è contrassegnato comepending. Il servizioOrderrestituisce al client le informazioni sull'ordine e pubblica un evento che include le informazioni sull'ordine nel seguente argomento Pub/Sub:order-service-event. - Il servizio
Customerriceve l'evento tramite una notifica push. Aumenta l'utilizzo del credito da parte del cliente, che viene archiviato nel database diCustomerin base al numero di articoli ordinati. - Se l'utilizzo totale del credito è inferiore o uguale al limite predefinito, il servizio
Customerpubblica un evento in cui si afferma che l'aumento del credito è riuscito. In alternativa, pubblica un evento che indica che l'aumento del merito non è andato a buon fine. In questo caso, l'utilizzo del credito non viene aumentato. - Il servizio
Orderriceve l'evento tramite una notifica push. Lo stato dell'ordine viene modificato di conseguenza inacceptedorejected. Il cliente può monitorare lo stato dell'ordine utilizzando l'ID ordine restituito dal servizioOrder.
Il seguente diagramma riassume questo flusso di lavoro:
La procedura di pubblicazione dell'evento
Quando un microservizio modifica i propri dati nel database e pubblica un evento per notificare il database, queste due operazioni devono essere condotte in modo atomico. Ad esempio, se il microservizio non funziona dopo aver modificato i dati senza pubblicare un evento, il processo transazionale si interrompe. In questo caso, i dati potrebbero essere potenzialmente in uno stato incoerente tra i vari microservizi coinvolti nella transazione. Per evitare questo problema, nell'applicazione di esempio utilizzata in questo documento i microservizi scrivono i dati degli eventi nel database di backend anziché pubblicare direttamente gli eventi in Pub/Sub.
I dati vengono modificati e i dati degli eventi associati sono scritti in modo atomico, utilizzando la funzionalità transazionale del database di backend. Questo pattern, mostrato nell'immagine seguente, è comunemente chiamato eventi applicazione o "Posta in uscita transazionale".

Come mostrato nell'immagine precedente, inizialmente la colonna published nei dati sugli eventi è contrassegnata come False. Quindi, il servizio event-publisher analizza periodicamente il database e pubblica gli eventi in cui la colonna published è False.
Dopo aver pubblicato un evento, il servizio event-publisher modifica
la colonna published in True.
Come mostrato nell'immagine seguente, sia il database Order sia il database Event nello stesso spazio dei nomi possono essere aggiornati a livello atomico mediante le transazioni del Datastore.

Se il servizio event-publisher non riesce dopo la pubblicazione di un evento senza modificare la colonna published, il servizio pubblica di nuovo lo stesso evento dopo il recupero. Poiché la ripubblicazione dell'evento causa un evento duplicato, i microservizi che ricevono l'evento devono verificare la potenziale duplicazione e gestirlo di conseguenza. Questo approccio aiuta a garantire l'idempotenza della gestione degli eventi.
L'immagine seguente mostra come un'applicazione di esempio gestisce la duplicazione di eventi.
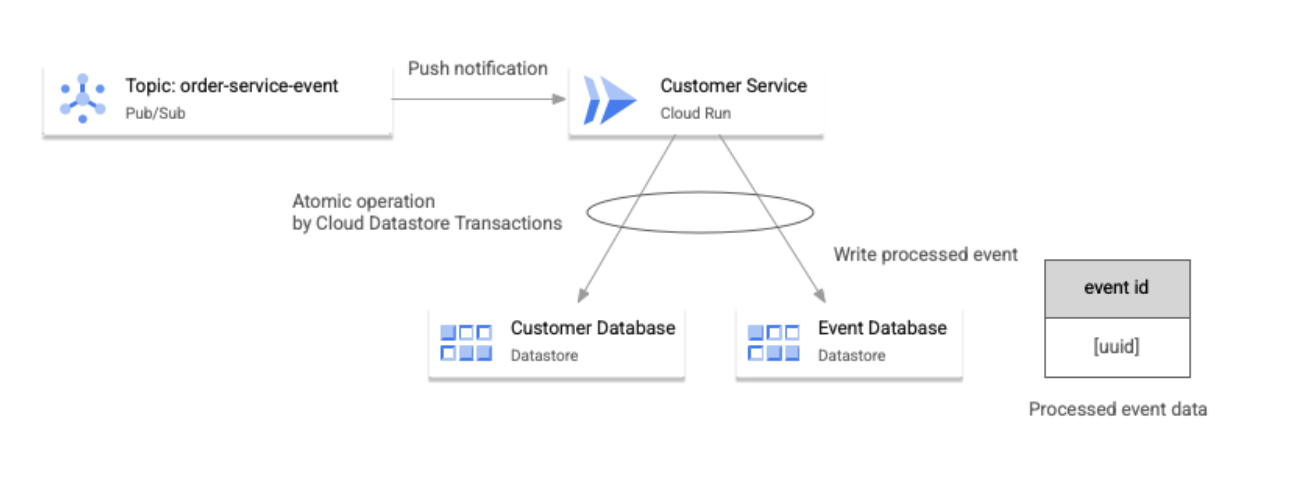
Come mostrato nel diagramma precedente, l'applicazione gestisce gli eventi duplicati con il seguente flusso di lavoro:
- Ogni microservizio aggiorna il rispettivo database di backend in base alla logica di business attivata da un evento e scrive l'ID evento nel database.
- Queste due operazioni di scrittura vengono eseguite in modo atomico utilizzando la funzionalità transazionale utilizzata dai database di backend.
- Se i servizi ricevono un evento duplicato, questo viene rilevato quando i servizi cercano l'ID evento nei propri database.
La gestione degli eventi duplicati è una pratica comune quando si ricevono eventi da Pub/Sub, perché esiste una piccola probabilità che Pub/Sub possa causare la consegna di messaggi duplicati.
Espandi l'architettura
Nell'applicazione di esempio, prima di elaborare un messaggio, puoi utilizzare
Datastore per verificare se è duplicato. Questo approccio significa che il servizio che consuma i messaggi (il servizio Customer, in questo caso) è idempotente. Questo approccio viene comunemente chiamato pattern "consumatore idempotente". Alcuni framework implementano questo pattern come funzionalità integrata, ad esempio Eventuate.
Tuttavia, l'accesso al database ogni volta che elabora un messaggio può causare problemi di prestazioni. Una soluzione è l'utilizzo di un database con buone prestazioni e scalabilità, ad esempio Redis.
Orchestrazione sincrona
Questa sezione descrive come implementare un pattern di microservizi di orchestrazione sincrona in un flusso di lavoro transazionale.
Panoramica dell'architettura
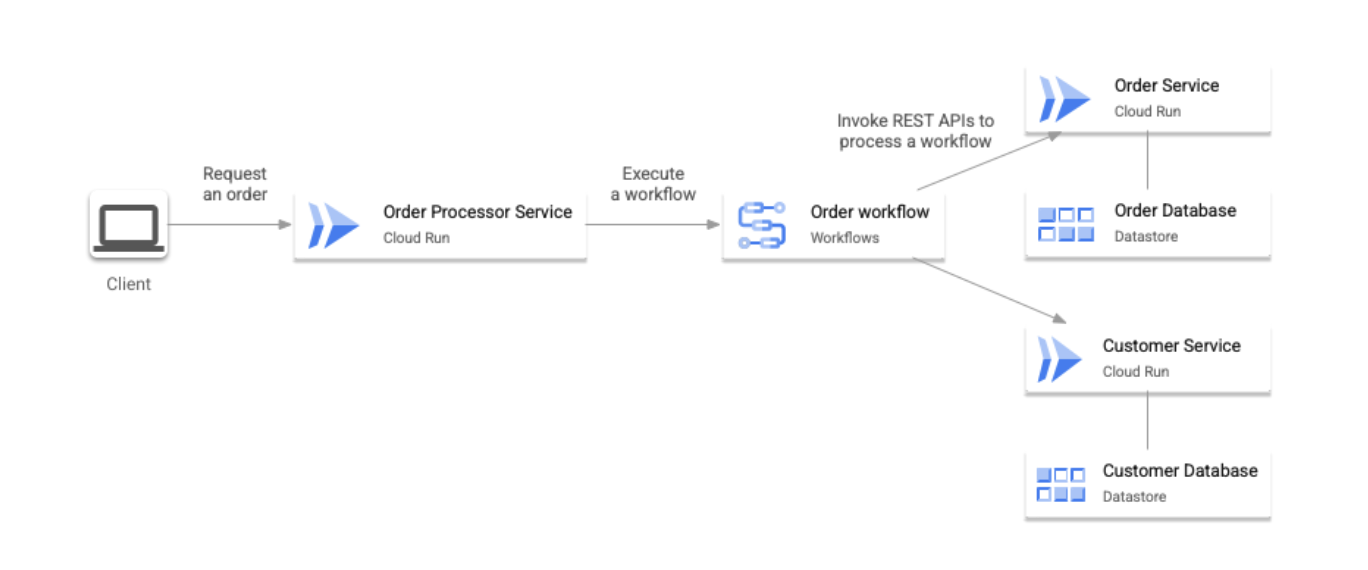
In questo pattern, un singolo agente di orchestrazione controlla il flusso di esecuzione di una transazione. La comunicazione tra microservizi e l'agente di orchestrazione viene eseguita in modo sincrono tramite le API REST.
Nell'architettura di esempio descritta in questo documento, Cloud Run viene utilizzato come runtime di microservizi e Datastore come database di backend per ogni servizio. Inoltre, Flussi di lavoro viene utilizzato come agente di orchestrazione. Questo pattern è mostrato nell'immagine seguente:
Flusso di lavoro transazionale
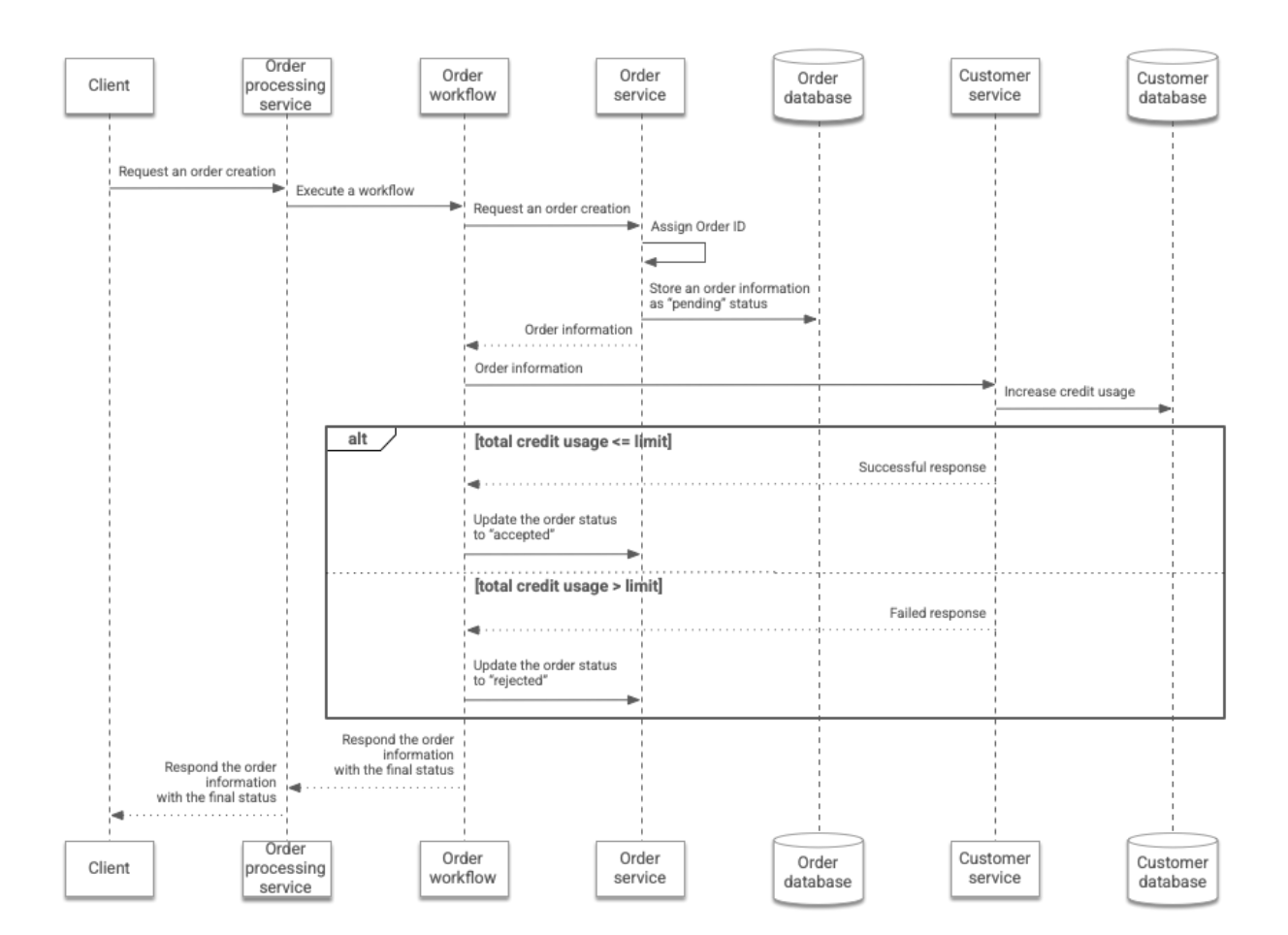
Nell'architettura di un flusso di lavoro sincrono, l'ordine di un cliente viene elaborato come segue:
- Il cliente invia una richiesta di ordine in cui sono specificati l'ID di un cliente e il numero di articoli ordinati. La richiesta viene inviata al servizio
Order processortramite l'API REST. - Il servizio
Order processoresegue un flusso di lavoro in cui l'ID cliente e il numero di articoli vengono passati a Workflows. - Il flusso di lavoro chiama l'API REST del servizio
Ordere trasmette l'ID cliente e il numero di articoli ordinati dal cliente. Successivamente, il servizioOrderassegna un ID ordine all'ordine del cliente e memorizza le informazioni dell'ordine nel databaseOrder. Lo stato dell'ordine è contrassegnato comepending. Il servizioOrderrestituisce le informazioni dell'ordine al flusso di lavoro. - Il flusso di lavoro chiama l'API REST del servizio
Customere trasmette l'ID cliente e il numero di articoli ordinati dal cliente. Successivamente, il servizioCustomeraumenta l'utilizzo del credito del cliente archiviato nel databaseCustomerin base al numero di articoli ordinati. - Se l'utilizzo totale del credito è inferiore o uguale al limite predefinito, il servizio
Customerrestituisce i dati che indicano che l'aumento del credito è riuscito. In alternativa, restituisce i dati che spiegano che l'aumento del merito non è andato a buon fine. In questo caso, l'utilizzo del credito non viene aumentato. - Il flusso di lavoro chiama l'API REST del servizio
Orderper modificare lo stato dell'ordine inacceptedorejected, a seconda dei casi. Infine, restituisce al servizioOrder processorle informazioni sull'ordine nell'aggiornamento finale dello stato. Quindi, il servizioOrder processorrestituisce queste informazioni al client.
Questo flusso di lavoro è riassunto nel seguente diagramma:
Vantaggi e svantaggi
Quando valuti se implementare una saga basata sulla coreografia o un'orchestrazione sincrona, la scelta migliore per la tua organizzazione è sempre il pattern più adatto alle sue esigenze. Tuttavia, in generale, a causa della semplicità del suo design, l'orchestrazione sincrona è spesso la prima scelta per molte aziende.
La seguente tabella riassume i vantaggi e gli svantaggi della saga basata sulla coreografia e dei pattern di orchestrazione sincrona descritti in questo documento.
Vantaggi |
Svantaggi |
|
|---|---|---|
Saga basata sulla coreografia |
Accoppiamento basso: ogni servizio pubblica gli eventi nel datastore in caso di modifica dei propri dati. Nessuna informazione viene inviata ad altri servizi. Questo approccio rende ogni servizio più indipendente e si riduce la possibilità di dover modificare i servizi quando introduci nuovi servizi nel flusso di lavoro. |
Dipendenza complessa: l'implementazione dell'intero flusso di lavoro è distribuita tra i servizi. Di conseguenza, può essere complesso comprendere il flusso di lavoro. Questo approccio potrebbe introdurre involontariamente complessità nelle future modifiche alla progettazione e nella risoluzione dei problemi. |
Orchestrazione sincrona |
Dipendenza semplice: un singolo agente di orchestrazione controlla l'intero flusso di esecuzione di una transazione. Di conseguenza, è più semplice capire come funziona il flusso delle transazioni. Questo pattern semplifica la modifica del flusso di lavoro e la risoluzione dei problemi. |
Rischio di accoppiamento stretto: l'agente di orchestrazione centrale dipende da tutti i servizi che costituiscono il flusso di lavoro transazionale. Di conseguenza, quando modifichi uno di questi servizi o aggiungi nuovi servizi al flusso di lavoro, potresti dover modificare l'agente di orchestrazione di conseguenza. Lo sforzo aggiuntivo necessario può superare il vantaggio di poter modificare e aggiungere servizi in modo più indipendente all'architettura di microservizi rispetto ai sistemi monolitici. |
Passaggi successivi
- Scopri di più sulle architetture di microservizi
- Esplora le architetture di riferimento, i diagrammi e le best practice su Google Cloud. Dai un'occhiata al nostro Cloud Architecture Center.