En este instructivo, se muestra cómo comenzar a usar la ciencia de datos a gran escala con R en Google Cloud. Esto está dirigido a aquellos usuarios que tengan experiencia con R y con notebooks de Jupyter, que se sientan cómodos con SQL.
En este instructivo, nos enfocamos en realizar análisis de datos exploratorios mediante notebooks administrados por el usuario de Vertex AI Workbench y BigQuery. Puedes encontrar el código para este instructivo en un notebook de Jupyter en GitHub.
Descripción general
R es uno de los lenguajes de programación que más se usan para el modelado estadístico. Tiene una gran comunidad activa de científicos de datos y profesionales del aprendizaje automático (AA). Con más de 15,000 paquetes en el repositorio de código abierto de la Red integral de archivos R (CRAN), R tiene herramientas para todas las aplicaciones de análisis de datos estadísticos, AA y visualización. R experimentó un crecimiento continuo en las últimas dos décadas debido a la expresividad de su sintaxis y a través de la amplitud de sus datos y las bibliotecas del AA.
Como científico de datos, es posible que desees saber cómo puedes usar tu conjunto de habilidades mediante R y cómo también puedes aprovechar las ventajas de los servicios de nube completamente administrados y escalables para el AA.
Arquitectura
En este instructivo, usarás notebooks administrados por el usuario como el entorno de ciencia de datos para realizar análisis de datos exploratorio (EDA). Usa R en los datos que extraigas como parte de este instructivo desde BigQuery, el almacén de datos en la nube sin servidores, altamente escalable y rentable de Google. Después de analizar y procesar los datos, los datos transformados se almacenan en Cloud Storage para otras tareas del AA. Este flujo se muestra en el siguiente diagrama:

Datos para el instructivo
El conjunto de datos que se usa en este instructivo es el conjunto de datos de natalidad de BigQuery. Este conjunto de datos públicos incluye información sobre más de 137 millones de nacimientos registradas en los Estados Unidos de 1969 a 2008.
En este instructivo, nos enfocaremos en el EDA y en la visualización mediante R y BigQuery. En este instructivo, te preparas para un objetivo de aprendizaje automático a fin de predecir el peso de un bebé según una cantidad de factores sobre el embarazo y la madre del bebé, aunque esa tarea no se explica en este instructivo.
Notebooks administrados por el usuario
Los notebooks administrados por el usuario de Vertex AI Workbench son un servicio que ofrece un entorno integrado de JupyterLab, con las siguientes características:
- Implementación con un solo clic Puedes usar un solo clic para iniciar una instancia de JupyterLab preconfigurada con los últimos frameworks de aprendizaje automático y ciencia de datos.
- Escala según la demanda Puedes comenzar con una configuración de máquina pequeña (por ejemplo, 4 CPU virtuales y 15 GB de RAM, como en este instructivo) y, cuando tus datos se vuelven demasiado grandes para una máquina, puedes escalarlos si agregas CPU, RAM y GPU.
- Integración en Google Cloud. Las instancias de notebooks administrados por el usuario de Vertex AI Workbench están integradas con los servicios de Google Cloud, como BigQuery. Esta integración facilita el paso de la transferencia de datos al preprocesamiento y la exploración.
- Precios de pago por uso No hay tarifas mínimas ni compromisos anticipados. Consulta los precios de los notebooks administrados por el usuario de Vertex AI Workbench. También pagas por los recursos de Google Cloud que usas con la instancia de notebooks administrados por el usuario.
Los notebooks administrados por el usuario se ejecutan en Deep Learning VM Image. Estas imágenes están optimizadas para admitir los frameworks del AA, como PyTorch y TensorFlow. En este instructivo, se admite la creación de una instancia de notebooks administrados por el usuario con R 3.6.
Trabaja con BigQuery mediante R
BigQuery no requiere administración de infraestructura, por lo que puedes enfocarte en descubrir estadísticas significativas. BigQuery te permite usar SQL familiar para trabajar con tus datos, por lo que no necesitas un administrador de base de datos. Puedes usar BigQuery con el fin de analizar grandes cantidades de datos a gran escala y preparar conjuntos de datos para el AA con las capacidades analíticas enriquecidas del SQL de BigQuery.
Para consultar datos de BigQuery con R, puedes usar bigrquery, una biblioteca R de código abierto. El paquete de bigrquery proporciona los siguientes niveles de abstracción, además de BigQuery:
La API de bajo nivel proporciona wrappers delgados a través de la API de REST de BigQuery subyacente.
La interfaz de ADB une la API de bajo nivel y hace que trabajar con BigQuery sea similar a trabajar con cualquier otro sistema de base de datos. Esta es la capa más conveniente si deseas ejecutar consultas de SQL en BigQuery o subir menos de 100 MB.
La interfaz de dbplry te permite tratar las tablas de BigQuery, como los marcos de datos en la memoria. Esta es la capa más conveniente si no quieres escribir SQL, sino que prefieres que dbplyr lo haga por ti.
En este instructivo, se usa la API de bajo nivel de bigrquery, sin necesidad de DBI o dbplyr.
Objetivos
- Crear una instancia de notebook administrados por el usuario que sea compatible con R.
- Consultar y analizar datos de BigQuery con la biblioteca R de bigrquery
- Preparar y almacenar datos para el AA en Cloud Storage.
Costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
- BigQuery
- Instancia de notebooks administrados por el usuario de Vertex AI Workbench. También se te cobra por los recursos utilizados en los notebooks, incluidos los recursos de procesamiento, BigQuery y las solicitudes a la API.
- Cloud Storage
Para generar una estimación de costos en función del uso previsto, usa la calculadora de precios.
Antes de comenzar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Crea una instancia de notebooks administrados por el usuario con R
El primer paso es crear una instancia de notebooks administrados por el usuario que puedas usar para este instructivo.
En la consola de Google Cloud, ve a la página Notebooks.
En la pestaña Notebooks administrados por el usuario, haz clic en Nuevo notebook .
Selecciona R 3.6.

Para este instructivo, deja todos los valores predeterminados y haz clic en Crear:
La instancia de notebooks administrados por el usuario puede tardar hasta 90 segundos en iniciarse. Cuando esté listo, la verás en el panel Instancias de notebook con el vínculo Abrir JupyterLab junto al nombre de la instancia:
Abre JupyterLab
Para seguir el instructivo en el notebook, debes abrir el entorno de JupyterLab, clonar el repositorio de GitHub ml-on-gcp y, luego, abrir el notebook.
En la lista de instancias, haz clic en Abrir Jupyterlab. Esto abrirá el entorno de JupyterLab en el navegador.

Para iniciar una pestaña de la terminal, haz clic en Terminal en el Selector.
En la terminal, clona el repositorio de GitHub
ml-on-gcp:git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.gitCuando el comando finalice, verás la carpeta
ml-on-gcpen el navegador de archivos.En el navegador de archivos, abre
ml-on-gcp; luego,tutorialsy, luego,R..El resultado de la clonación se ve de la siguiente manera:

Abre el notebook y configura R
Las bibliotecas R que necesitas para este instructivo, incluida bigquery, se instalan de forma predeterminada en los notebooks de R. Como parte de este procedimiento, debes importarlos para que estén disponibles en el notebook.
En el navegador de archivos, abre el notebook
01-EDA-with-R-and-BigQuery.ipynb.En este notebook, se abarca el instructivo de análisis de datos exploratorios con R y BigQuery. Desde este punto del instructivo, trabajas en el notebook y ejecutas el código que ves dentro del notebook de Jupyter.
Importa las bibliotecas R que necesitas para este instructivo:
library(bigrquery) # used for querying BigQuery library(ggplot2) # used for visualization library(dplyr) # used for data wranglingAutentica
bigrquerymediante la autenticación fuera de banda:bq_auth(use_oob = True)Configura una variable para el nombre del proyecto que usas en este instructivo:
# Set the project ID PROJECT_ID <- "gcp-data-science-demo"Configura una variable para el nombre del bucket de Cloud Storage:
BUCKET_NAME <- "bucket-name"
Reemplaza bucket-name por un nombre que sea único de forma global.
Usa el bucket más adelante para almacenar los datos de salida.
Consulta datos desde BigQuery
En esta sección del instructivo, leerás los resultados de la ejecución de una instrucción de SQL de BigQuery en R y una vista preliminar de los datos.
Crea una instrucción de SQL de BigQuery que extraiga algunos posibles predicciones y la variable de predicción de destino para una muestra de nacimientos desde el 2000:
sql_query <- " SELECT ROUND(weight_pounds, 2) AS weight_pounds, is_male, mother_age, plurality, gestation_weeks, cigarette_use, alcohol_use, CAST(ABS(FARM_FINGERPRINT(CONCAT( CAST(YEAR AS STRING), CAST(month AS STRING), CAST(weight_pounds AS STRING))) ) AS STRING) AS key FROM publicdata.samples.natality WHERE year > 2000 AND weight_pounds > 0 AND mother_age > 0 AND plurality > 0 AND gestation_weeks > 0 AND month > 0 LIMIT %s "La columna
keyes un identificador de fila generado que se basa en los valores concatenados de las columnasyear,monthyweight_pounds.Ejecuta la consulta y recupera los datos como un objeto de
data frameen la memoria:sample_size <- 10000 sql_query <- sprintf(sql_query, sample_size) natality_data <- bq_table_download( bq_project_query( PROJECT_ID, query=sql_query ) )Visualiza los resultados recuperados:
head(natality_data)La salida es similar a esta:

Observa la cantidad de filas y tipos de datos de cada columna:
str(natality_data)La salida es similar a esta:
Classes ‘tbl_df’, ‘tbl’ and 'data.frame': 10000 obs. of 8 variables: $ weight_pounds : num 7.75 7.4 6.88 9.38 6.98 7.87 6.69 8.05 5.69 9.22 ... $ is_male : logi FALSE TRUE TRUE TRUE FALSE TRUE ... $ mother_age : int 47 44 42 43 42 43 42 43 45 44 ... $ plurality : int 1 1 1 1 1 1 1 1 1 1 ... $ gestation_weeks: int 41 39 38 39 38 40 35 40 38 39 ... $ cigarette_use : logi NA NA NA NA NA NA ... $ alcohol_use : logi FALSE FALSE FALSE FALSE FALSE FALSE ... $ key : chr "3579741977144949713" "8004866792019451772" "7407363968024554640" "3354974946785669169" ...
Visualiza un resumen de los datos recuperados:
summary(natality_data)La salida es similar a esta:
weight_pounds is_male mother_age plurality Min. : 0.620 Mode :logical Min. :13.0 Min. :1.000 1st Qu.: 6.620 FALSE:4825 1st Qu.:22.0 1st Qu.:1.000 Median : 7.370 TRUE :5175 Median :27.0 Median :1.000 Mean : 7.274 Mean :27.3 Mean :1.038 3rd Qu.: 8.110 3rd Qu.:32.0 3rd Qu.:1.000 Max. :11.440 Max. :51.0 Max. :4.000 gestation_weeks cigarette_use alcohol_use key Min. :18.00 Mode :logical Mode :logical Length:10000 1st Qu.:38.00 FALSE:580 FALSE:8284 Class :character Median :39.00 TRUE :83 TRUE :144 Mode :character Mean :38.68 NA's :9337 NA's :1572 3rd Qu.:40.00 Max. :47.00
Visualiza datos con ggplot2
En esta sección, usarás la biblioteca ggplot2 en R para estudiar algunas de las variables del conjunto de datos de natalidad.
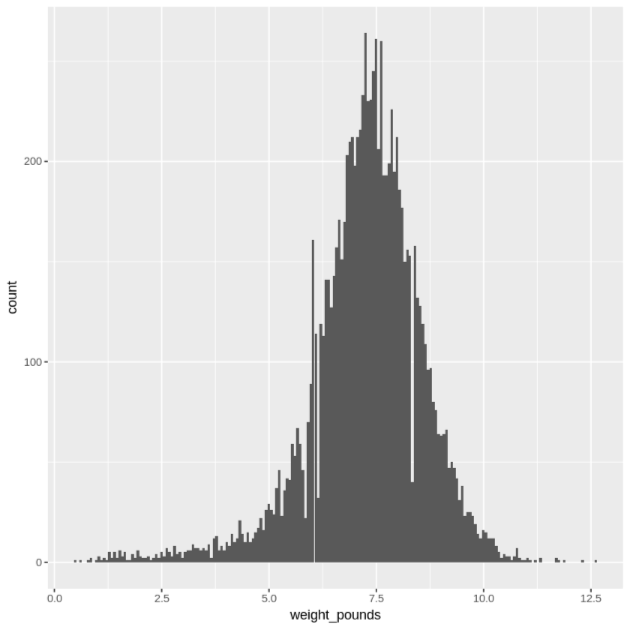
Muestra la distribución de los valores de
weight_poundsmediante un histograma:ggplot( data = natality_data, aes(x = weight_pounds) ) + geom_histogram(bins = 200)El trazado resultante es similar al siguiente:
Muestra la relación entre
gestation_weeksyweight_poundsmediante un gráfico de dispersión:ggplot( data = natality_data, aes(x = gestation_weeks, y = weight_pounds) ) + geom_point() + geom_smooth(method = "lm")El trazado resultante es similar al siguiente:

Procesa datos en BigQuery desde R
Cuando trabajas con grandes conjuntos de datos, te recomendamos que realices la mayor cantidad de análisis posible (agregación, filtrado, unión, columnas de procesamiento, etc.) en BigQuery y, luego, recuperes los resultados. Es menos eficiente realizar estas tareas en R. Usar BigQuery para el análisis aprovecha la escalabilidad y el rendimiento de BigQuery, y se asegura de que los resultados que se muestren puedan ajustarse a la memoria en R.
Crea una función que encuentre la cantidad de registros y el peso promedio para cada valor de la columna seleccionada:
get_distinct_values <- function(column_name) { query <- paste0( 'SELECT ', column_name, ', COUNT(1) AS num_babies, AVG(weight_pounds) AS avg_wt FROM publicdata.samples.natality WHERE year > 2000 GROUP BY ', column_name) bq_table_download( bq_project_query( PROJECT_ID, query = query ) ) }Invoca esta función con la columna
mother_agey, luego, observa la cantidad de bebés y el peso promedio por edad de la madre:df <- get_distinct_values('mother_age') ggplot(data = df, aes(x = mother_age, y = num_babies)) + geom_line() ggplot(data = df, aes(x = mother_age, y = avg_wt)) + geom_line()El resultado del primer comando
ggplotes el siguiente, que muestra la cantidad de bebés nacidos según la edad de la madre.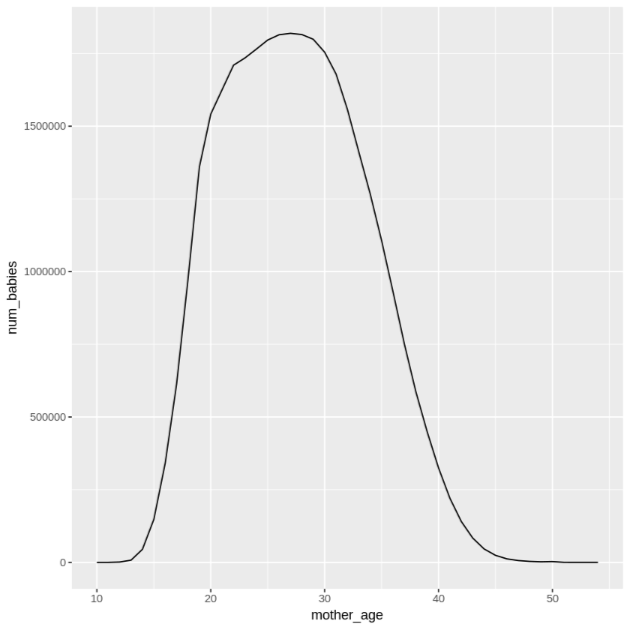
El resultado del segundo comando
ggplotes el siguiente, que muestra el peso promedio de los bebés según la edad de la madre.
Si deseas ver más ejemplos de visualización, consulta el notebook.
Guarda datos como archivos CSV
La siguiente tarea es guardar los datos extraídos de BigQuery como archivos CSV en Cloud Storage para que puedas usarlos en más tareas del AA.
Carga los datos de entrenamiento y de evaluación de BigQuery en R:
# Prepare training and evaluation data from BigQuery sample_size <- 10000 sql_query <- sprintf(sql_query, sample_size) train_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) <= 75') eval_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) > 75') # Load training data to data frame train_data <- bq_table_download( bq_project_query( PROJECT_ID, query = train_query ) ) # Load evaluation data to data frame eval_data <- bq_table_download( bq_project_query( PROJECT_ID, query = eval_query ) )Escribe los datos en un archivo CSV local:
# Write data frames to local CSV files, without headers or row names dir.create(file.path('data'), showWarnings = FALSE) write.table(train_data, "data/train_data.csv", row.names = FALSE, col.names = FALSE, sep = ",") write.table(eval_data, "data/eval_data.csv", row.names = FALSE, col.names = FALSE, sep = ",")Sube los archivos CSV a Cloud Storage mediante la unión de los comandos
gsutilque se pasan al sistema:# Upload CSV data to Cloud Storage by passing gsutil commands to system gcs_url <- paste0("gs://", BUCKET_NAME, "/") command <- paste("gsutil mb", gcs_url) system(command) gcs_data_dir <- paste0("gs://", BUCKET_NAME, "/data") command <- paste("gsutil cp data/*_data.csv", gcs_data_dir) system(command) command <- paste("gsutil ls -l", gcs_data_dir) system(command, intern = TRUE)Otra opción para este paso es usar la biblioteca googleCloudStorageR a fin de hacerlo con la API de JSON de Cloud Storage.
Limpia
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en este instructivo, debes quitarlos.
Borra el proyecto
La manera más fácil de eliminar la facturación es borrar el proyecto que creaste para el instructivo.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
¿Qué sigue?
- Obtén más información para usar los datos de BigQuery en tus notebooks de R en la documentación de bigrquery.
- Obtén información sobre las prácticas recomendadas para la ingeniería de AA en las Reglas de AA..
- Explora arquitecturas de referencia, diagramas y prácticas recomendadas sobre Google Cloud. Consulta nuestro Cloud Architecture Center.