En este documento, se describe cómo configurar una canalización de integración continua/implementación continua (CI/CD) para procesar datos mediante la aplicación de métodos de CI/CD con productos administrados en Google Cloud. Los científicos y los analistas de datos pueden adaptar las metodologías de las prácticas de CI/CD para garantizar la alta calidad, el mantenimiento y la adaptabilidad de los procesos de datos y los flujos de trabajo. A continuación, se incluyen los métodos que puedes aplicar:
- Control de versión del código fuente
- Compilación, prueba e implementación automática de apps
- Aislamiento del entorno y separación de la producción
- Procedimientos replicables para la configuración del entorno
Este documento está dirigido a científicos y analistas de datos que compilan trabajos de procesamiento de datos en ejecución recurrentes para ayudar a estructurar la investigación y el desarrollo (I+D) a fin de mantener las cargas de trabajo de procesamiento de datos de forma sistemática y automática.
Arquitectura
En el siguiente diagrama, se muestra una vista detallada de los pasos de la canalización de CI/CD.

Las implementaciones en los entornos de prueba y producción se separan en dos canalizaciones de Cloud Build diferentes: una de prueba y una de producción.
En el diagrama anterior, la canalización de prueba consta de los siguientes pasos:
- Un desarrollador confirma los cambios de código en Cloud Source Repositories.
- Los cambios de código activan una compilación de prueba en Cloud Build.
- Cloud Build compila el archivo JAR de ejecución automática y lo implementa en el bucket de JAR de prueba en Cloud Storage.
- Cloud Build implementa los archivos de prueba en los buckets de archivos de prueba en Cloud Storage.
- Cloud Build establece la variable en Cloud Composer para hacer referencia al archivo JAR recién implementado.
- Cloud Build prueba el grafo acíclico dirigido (DAG) del flujo de trabajo de procesamiento de datos y lo implementa en el bucket de Cloud Composer en Cloud Storage.
- El archivo DAG de flujo de trabajo se implementa en Cloud Composer.
- Cloud Build activa el flujo de trabajo de procesamiento de datos recién implementado para su ejecución.
- Cuando se haya pasado la prueba de integración del flujo de trabajo de procesamiento de datos, se publicará un mensaje en Pub/Sub que contendrá una referencia al último JAR de ejecución automática (obtenido de las variables de Airflow) en el campo de datos del mensaje.
En el diagrama anterior, la canalización de producción consta de los siguientes pasos:
- La canalización de implementación de producción se activa cuando se publica un mensaje en un tema de Pub/Sub.
- Un desarrollador aprueba de forma manual la canalización de implementación de producción y se ejecuta la compilación.
- Cloud Build copia el último archivo JAR de ejecución automática del bucket de JAR de prueba en el bucket de JAR de producción en Cloud Storage.
- Cloud Build prueba el DAG del flujo de trabajo de procesamiento de datos de producción y lo implementa en el bucket de Cloud Composer en Cloud Storage.
- El archivo de DAG del flujo de trabajo de producción se implementa en Cloud Composer.
En este documento de arquitectura de referencia, el flujo de trabajo de procesamiento de datos de producción se implementa en el mismo entorno de Cloud Composer que el flujo de trabajo de prueba para brindar una vista unificada de todos los flujos de trabajo de procesamiento de datos. Para los fines de esta arquitectura de referencia, los entornos están separados mediante el uso de diferentes buckets de Cloud Storage para contener los datos de entrada y salida.
Para separar por completo los entornos, necesita varios entornos de Cloud Composer creados en proyectos diferentes, que están separados de forma predeterminada. Esta separación ayuda a proteger el entorno de producción. Este método no se analiza en este instructivo. Para obtener más información sobre cómo acceder a los recursos en varios proyectos de Google Cloud, consulta Configura los permisos de la cuenta de servicio.
El flujo de trabajo de procesamiento de datos
Las instrucciones que indican cómo Cloud Composer ejecuta el flujo de trabajo de procesamiento de datos se definen en un DAG escrito en Python. En el DAG, todos los pasos del flujo de trabajo de procesamiento de datos se definen junto con las dependencias entre ellos.
La canalización de CI/CD implementa de forma automática la definición de DAG de Cloud Source Repositories en Cloud Composer en cada compilación. Este proceso garantiza que Cloud Composer siempre esté actualizado con la última definición del flujo de trabajo sin necesidad de intervención humana.
En la definición de DAG para el entorno de prueba, se define un paso de prueba de extremo a extremo, además del flujo de trabajo de procesamiento de datos. El paso de prueba ayuda a garantizar que el flujo de trabajo de procesamiento de datos se ejecute de forma correcta.
El flujo de trabajo de procesamiento de datos se ilustra en el siguiente diagrama.
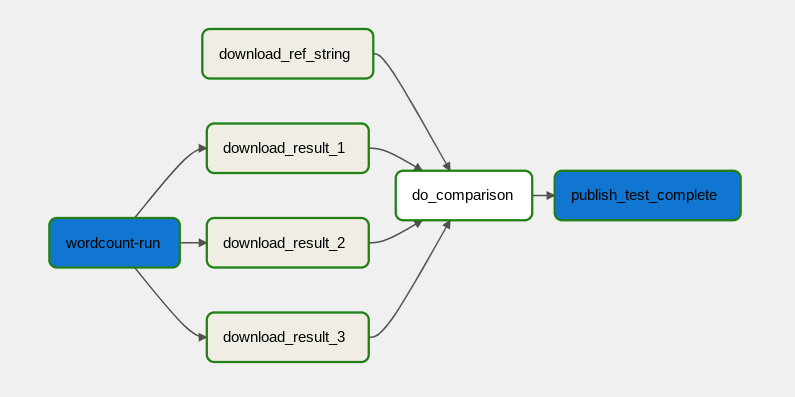
El flujo de trabajo de procesamiento de datos consta de los pasos siguientes:
- Ejecuta el proceso de datos de WordCount en Dataflow.
Descarga los archivos de salida del proceso WordCount. El proceso WordCount genera tres archivos:
download_result_1download_result_2download_result_3
Descarga el archivo de referencia, llamado
download_ref_string.Verifica el resultado con el archivo de referencia. Esta prueba de integración agrupa los tres resultados y compara todos los resultados con el archivo de referencia.
Publica un mensaje en Pub/Sub después de que finalice la prueba de integración.
El uso de un framework de organización de tareas como Cloud Composer para administrar el flujo de trabajo de procesamiento de datos ayuda a disminuir la complejidad del código del flujo de trabajo.
Optimización de costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
¿Qué sigue?
- Obtén más información sobre la entrega continua tipo GitOps con Cloud Build.
- Obtén más información sobre los Patrones comunes de casos prácticos de Dataflow.
- Obtenga más información sobre la Ingeniería de lanzamientos.
- Para obtener más información sobre las arquitecturas de referencia, los diagramas y las prácticas recomendadas, explora Cloud Architecture Center.