Auf dieser Seite wird beschrieben, wie Sie Ihre NoSQL-Datenbank von Cassandra zu Spanner migrieren.
Cassandra und Spanner sind beide verteilte Datenbanken im großen Maßstab, die für Anwendungen entwickelt wurden, die hohe Skalierbarkeit und niedrige Latenz erfordern. Beide Datenbanken können anspruchsvolle NoSQL-Arbeitslasten unterstützen. Spanner bietet jedoch erweiterte Funktionen für die Datenmodellierung, Abfrage und Transaktionsvorgänge. Spanner unterstützt die Cassandra Query Language (CQL).
Weitere Informationen dazu, wie Spanner die Kriterien für NoSQL-Datenbanken erfüllt, finden Sie unter Spanner für nicht relationale Arbeitslasten.
Migrationseinschränkungen
Damit die Migration von Cassandra zum Cassandra-Endpunkt in Spanner erfolgreich ist, sollten Sie sich Spanner für Cassandra-Nutzer ansehen, um zu erfahren, wie sich die Spanner-Architektur, das Datenmodell und die Datentypen von Cassandra unterscheiden. Sehen Sie sich die funktionalen Unterschiede zwischen Spanner und Cassandra genau an, bevor Sie mit der Migration beginnen.
Migrationsprozess
Der Migrationsprozess ist in die folgenden Schritte unterteilt:
- Schema und Datenmodell migrieren
- Dual-Write für eingehende Daten einrichten
- Bulk-Export Ihrer Verlaufsdaten aus Cassandra nach Spanner
- Daten validieren, um die Datenintegrität während des gesamten Migrationsprozesses sicherzustellen.
- Anwendung auf Spanner statt auf Cassandra verweisen:
- Optional. Umgekehrte Replikation von Spanner zu Cassandra durchführen
Schema und Datenmodell konvertieren
Der erste Schritt bei der Migration Ihrer Daten von Cassandra zu Spanner besteht darin, das Cassandra-Datenschema an das Spanner-Schema anzupassen und dabei Unterschiede bei Datentypen und Modellierung zu berücksichtigen.
Die Syntax für die Tabellendeklaration ist in Cassandra und Spanner ziemlich ähnlich. Sie geben den Tabellennamen, die Spaltennamen und -typen sowie den Primärschlüssel an, der eine Zeile eindeutig identifiziert. Der Hauptunterschied besteht darin, dass Cassandra hash-partitioniert ist und zwischen den beiden Teilen des Primärschlüssels unterscheidet: dem gehashten Partitionsschlüssel und den sortierten Clustering-Spalten. Spanner ist dagegen bereichspartitioniert. Der Primärschlüssel von Spanner enthält nur Clustering-Spalten. Partitionen werden automatisch im Hintergrund verwaltet. Wie Cassandra unterstützt auch Spanner zusammengesetzte Primärschlüssel.
Wir empfehlen die folgenden Schritte, um Ihr Cassandra-Datenschema in Spanner zu konvertieren:
- Lesen Sie die Cassandra-Übersicht, um die Gemeinsamkeiten und Unterschiede zwischen Cassandra- und Spanner-Datenschemas zu verstehen und zu erfahren, wie Sie verschiedene Datentypen zuordnen.
- Verwenden Sie das Tool zum Migrieren von Cassandra- zu Spanner-Schemas, um Ihr Cassandra-Datenschema zu extrahieren und in Spanner zu konvertieren.
- Bevor Sie mit der Datenmigration beginnen, müssen Sie dafür sorgen, dass Ihre Spanner-Tabellen mit den entsprechenden Datenschemas erstellt wurden.
Live-Migration für eingehende Daten einrichten
Wenn Sie eine Migration ohne Ausfallzeit von Cassandra zu Spanner durchführen möchten, richten Sie die Live-Migration für eingehende Daten ein. Bei der Live-Migration geht es darum, Ausfallzeiten zu minimieren und die kontinuierliche Anwendungsverfügbarkeit durch Echtzeitreplikation zu gewährleisten.
Beginnen Sie mit der Live-Migration, bevor Sie die Bulk-Migration durchführen. Das folgende Diagramm zeigt die Architektur einer Live-Migration.
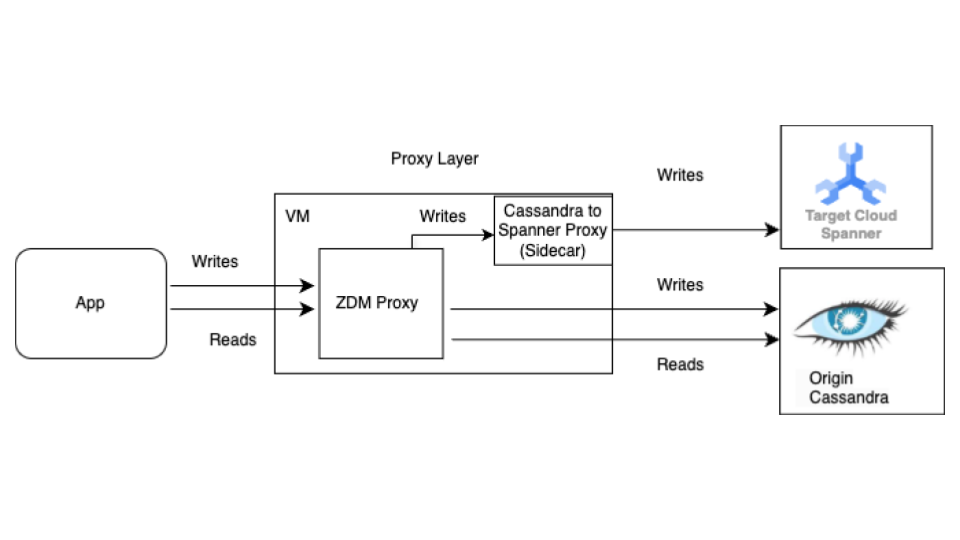
Die Live-Migrationsarchitektur hat die folgenden Hauptkomponenten:
- Quelle:Ihre Cassandra-Quelldatenbank.
- Ziel:Die Spanner-Zieldatenbank, zu der Sie migrieren. Es wird davon ausgegangen, dass Sie Ihre Spanner-Instanz und -Datenbank bereits mit einem Schema bereitgestellt haben, das mit Ihrem Cassandra-Schema kompatibel ist (mit den erforderlichen Anpassungen für das Datenmodell und die Funktionen von Spanner).
Datastax ZDM-Proxy:Der ZDM-Proxy ist ein von DataStax entwickelter Dual-Write-Proxy für Cassandra-zu-Cassandra-Migrationen. Der Proxy imitiert einen Cassandra-Cluster, sodass eine Anwendung den Proxy ohne Anwendungsänderungen verwenden kann. Dieses Tool ist die Schnittstelle, über die Ihre Anwendung kommuniziert und die intern verwendet wird, um Dual-Writes in die Quell- und Zieldatenbanken auszuführen. Normalerweise wird es mit Cassandra-Clustern als Quelle und Ziel verwendet. In unserer Einrichtung wird es jedoch so konfiguriert, dass der Cassandra-Spanner-Proxy (der als Sidecar ausgeführt wird) als Ziel verwendet wird. So wird sichergestellt, dass jeder eingehende Lesevorgang nur an den Ursprung weitergeleitet wird und die Antwort des Ursprungs an die Anwendung zurückgegeben wird. Außerdem wird jeder eingehende Schreibvorgang sowohl an die Quelle als auch an das Ziel weitergeleitet.
- Wenn Schreibvorgänge sowohl für das Quell- als auch für das Ziel-Dataset erfolgreich sind, erhält die Anwendung eine Erfolgsmeldung.
- Wenn Schreibvorgänge in die Quelle fehlschlagen und Schreibvorgänge in das Ziel erfolgreich sind, erhält die Anwendung die Fehlermeldung der Quelle.
- Wenn Schreibvorgänge in das Ziel fehlschlagen und Schreibvorgänge in die Quelle erfolgreich sind, erhält die Anwendung die Fehlermeldung des Ziels.
- Wenn Schreibvorgänge sowohl für den Ursprung als auch für das Ziel fehlschlagen, erhält die Anwendung die Fehlermeldung des Ursprungs.
Cassandra-Spanner-Proxy:Eine Sidecar-Anwendung, die den für Cassandra bestimmten Cassandra Query Language-Traffic (CQL) abfängt und in Spanner API-Aufrufe übersetzt. Damit können Anwendungen und Tools über den Cassandra-Client mit Spanner interagieren.
Clientanwendung:Die Anwendung, die Daten in den Cassandra-Quellcluster liest und schreibt.
Proxy-Einrichtung
Der erste Schritt für die Live-Migration ist das Bereitstellen und Konfigurieren der Proxys. Der Cassandra-Spanner-Proxy wird als Sidecar für den ZDM-Proxy ausgeführt. Der Sidecar-Proxy fungiert als Ziel für die ZDM-Proxy-Schreibvorgänge in Spanner.
Einzelinstanztests mit Docker
Sie können eine einzelne Instanz des Proxys lokal oder auf einer VM für erste Tests mit Docker ausführen.
Vorbereitung
- Prüfen Sie, ob die VM, auf der der Proxy ausgeführt wird, eine Netzwerkverbindung zur Anwendung, zur Cassandra-Quelldatenbank und zur Spanner-Datenbank hat.
- Installieren Sie Docker.
- Prüfen Sie, ob eine Dienstkontoschlüsseldatei mit den erforderlichen Berechtigungen zum Schreiben in Ihre Spanner-Instanz und -Datenbank vorhanden ist.
- Spanner-Instanz, -Datenbank und -Schema einrichten
- Der Name der Spanner-Datenbank muss mit dem Namen des Cassandra-Schlüsselbereichs des Ursprungs übereinstimmen.
- Klonen Sie das Repository für das Spanner-Migrationstool.
ZDM-Proxy herunterladen und konfigurieren
- Wechseln Sie zum Verzeichnis
sources/cassandra. - Achten Sie darauf, dass sich die Dateien
entrypoint.shundDockerfileim selben Verzeichnis wie das Dockerfile befinden. Führen Sie den folgenden Befehl aus, um ein lokales Image zu erstellen:
docker build -t zdm-proxy:latest .
ZDM-Proxy ausführen
- Prüfen Sie, ob
zdm-config.yamlundkeyfileslokal vorhanden sind, wenn der folgende Befehl ausgeführt wird. - Öffnen Sie die Beispielkonfigurationsdatei zdm-config.yaml.
- Sehen Sie sich die ausführliche Liste der Flags an, die von ZDM akzeptiert werden.
Verwenden Sie den folgenden Befehl, um den Container auszuführen:
sudo docker run --restart always -d -p 14002:14002 \ -v zdm-config-file-path:/zdm-config.yaml \ -v local_keyfile:/var/run/secret/keys.json \ -e SPANNER_PROJECT=SPANNER_PROJECT_ID \ -e SPANNER_INSTANCE=SPANNER_INSTANCE_ID \ -e SPANNER_DATABASE=SPANNER_DATABASE_ID \ -e GOOGLE_APPLICATION_CREDENTIALS="/var/run/secret/keys.json" \ -e ZDM_CONFIG=/zdm-config.yaml \ zdm-proxy:latest
Proxy-Einrichtung überprüfen
Prüfen Sie mit dem Befehl
docker logsdie Proxy-Logs auf Fehler beim Start:docker logs container-idFühren Sie den Befehl
cqlshaus, um zu prüfen, ob der Proxy richtig eingerichtet ist:cqlsh VM-IP 14002Ersetzen Sie VM-IP durch die IP-Adresse Ihrer VM.
Produktionseinrichtung mit Terraform:
Für eine Produktionsumgebung empfehlen wir, die bereitgestellten Terraform-Vorlagen zu verwenden, um die Bereitstellung des Cassandra-Spanner-Proxys zu orchestrieren.
Vorbereitung
- Terraform installieren.
- Prüfen Sie, ob die Anwendung Standardanmeldedaten mit den entsprechenden Berechtigungen zum Erstellen von Ressourcen hat.
- Prüfen Sie, ob die Dienstschlüsseldatei die entsprechenden Berechtigungen zum Schreiben in Spanner hat. Diese Datei wird vom Proxy verwendet.
- Spanner-Instanz, -Datenbank und -Schema einrichten
- Prüfen Sie, ob sich das Dockerfile,
entrypoint.shund die Dienstschlüsseldatei im selben Verzeichnis wie die Dateimain.tfbefinden.
Terraform-Variablen konfigurieren
- Sie benötigen die Terraform-Vorlage für die Proxy-Bereitstellung.
- Aktualisieren Sie die Datei
terraform.tfvarsmit den Variablen für Ihre Einrichtung.
Vorlagenbereitstellung mit Terraform
Das Terraform-Skript tut Folgendes:
- Erstellt containeroptimierte VMs basierend auf einer angegebenen Anzahl.
- Erstellt
zdm-config.yaml-Dateien für jede VM und weist ihr einen Topologieindex zu. Für ZDM Proxy sind mehrere VMs erforderlich, um die Topologie mit den FeldernPROXY_TOPOLOGY_ADDRESSESundPROXY_TOPOLOGY_INDEXin der Konfigurationsdateiyamlzu konfigurieren. - Überträgt die relevanten Dateien auf jede VM, führt Docker Build remote aus und startet die Container.
So stellen Sie die Vorlage bereit:
Verwenden Sie den Befehl
terraform init, um Terraform zu initialisieren:terraform initFühren Sie den Befehl
terraform planaus, um zu sehen, welche Änderungen Terraform an Ihrer Infrastruktur vornehmen möchte:terraform plan -var-file="terraform.tfvars"Wenn die Ressourcen in Ordnung sind, führen Sie den Befehl
terraform applyaus:terraform apply -var-file="terraform.tfvars"Führen Sie nach dem Beenden des Terraform-Skripts den Befehl
cqlshaus, um sicherzustellen, dass die VMs zugänglich sind.cqlsh VM-IP 14002Ersetzen Sie VM-IP durch die IP-Adresse Ihrer VM.
Clientanwendungen auf den ZDM-Proxy verweisen
Ändern Sie die Konfiguration Ihrer Clientanwendung und legen Sie die Kontaktpunkte als die VMs fest, auf denen die Proxys ausgeführt werden, anstatt als Ihr Cassandra-Quellcluster.
Testen Sie Ihre Anwendung gründlich. Prüfen Sie, ob Schreibvorgänge sowohl auf den ursprünglichen Cassandra-Cluster als auch auf die Spanner-Datenbank angewendet werden. Lesevorgänge werden von der ursprünglichen Cassandra-Instanz ausgeführt.
Bulk-Export von Daten nach Spanner
Bei der Bulk-Datenmigration werden große Datenmengen zwischen Datenbanken übertragen. Dies erfordert häufig eine sorgfältige Planung und Ausführung, um Ausfallzeiten zu minimieren und die Datenintegrität zu gewährleisten. Zu den Techniken gehören ETL-Prozesse (Extrahieren, Transformieren, Laden), die direkte Datenbankreplikation und spezielle Migrationstools. Alle zielen darauf ab, Daten effizient zu übertragen und gleichzeitig ihre Struktur und Genauigkeit beizubehalten.
Wir empfehlen, die Dataflow-Vorlage SourceDB To Spanner (SourceDB zu Spanner) von Spanner zu verwenden, um Ihre Daten aus Cassandra in Spanner zu migrieren. Dataflow ist der verteilte ETL-Dienst (Extract, Transform, Load) Google Cloud , der eine Plattform zum Ausführen von Datenpipelines bietet, um große Datenmengen parallel auf mehreren Maschinen zu lesen und zu verarbeiten. Die Dataflow-Vorlage „SourceDB To Spanner“ ist für hochgradig parallelisierte Lesevorgänge aus Cassandra konzipiert. Sie transformiert die Quelldaten nach Bedarf und schreibt sie in Spanner als Zieldatenbank.
Führen Sie die Schritte in der Anleitung Bulk-Migration von Cassandra zu Spanner mit der Cassandra-Konfigurationsdatei aus.
Daten validieren, um die Integrität zu gewährleisten
Die Datenvalidierung während der Datenbankmigration ist entscheidend, um die Richtigkeit und Integrität der Daten sicherzustellen. Dabei werden Daten zwischen Ihrer Cassandra-Quelldatenbank und Ihrer Spanner-Zieldatenbank verglichen, um Abweichungen wie fehlende, beschädigte oder nicht übereinstimmende Daten zu erkennen. Zu den allgemeinen Techniken zur Datenvalidierung gehören Prüfsummen, Zeilenanzahlen und detaillierte Datenvergleiche. Sie alle zielen darauf ab, sicherzustellen, dass die migrierten Daten eine genaue Darstellung der Originaldaten sind.
Nach Abschluss der Massendatenmigration und während Dual Writes noch aktiv sind, müssen Sie die Datenkonsistenz prüfen und Abweichungen beheben. Während der Dual-Write-Phase können aus verschiedenen Gründen Unterschiede zwischen Cassandra und Spanner auftreten, z. B.:
- Fehler beim zweifachen Export Ein Schreibvorgang kann in einer Datenbank erfolgreich sein, in der anderen jedoch aufgrund von vorübergehenden Netzwerkproblemen oder anderen Fehlern fehlschlagen.
- Leichte Transaktionen (Lightweight Transactions, LWT): Wenn Ihre Anwendung LWT-Vorgänge (Compare and Set) verwendet, können diese in einer Datenbank erfolgreich sein, in der anderen jedoch aufgrund von Unterschieden in den Datasets fehlschlagen.
- Hohe Anzahl von Abfragen pro Sekunde (QPS) für einen einzelnen Primärschlüssel: Bei sehr hoher Schreiblast für denselben Partitionsschlüssel kann sich die Reihenfolge der Ereignisse zwischen Quelle und Ziel aufgrund unterschiedlicher Netzwerk-Roundtrip-Zeiten unterscheiden, was möglicherweise zu Inkonsistenzen führt.
Parallele Ausführung von Bulk-Jobs und Dual-Writes:Wenn die Bulk-Migration parallel zu Dual-Writes ausgeführt wird, kann es aufgrund verschiedener Race-Bedingungen zu Abweichungen kommen, z. B.:
- Zusätzliche Zeilen in Spanner:Wenn die Bulk-Migration ausgeführt wird, während Dual-Writes aktiv sind, löscht die Anwendung möglicherweise eine Zeile, die bereits vom Bulk-Migrationsjob gelesen und in das Ziel geschrieben wurde.
- Race-Bedingungen zwischen Bulk- und Dual-Writes:Es kann andere verschiedene Race-Bedingungen geben, bei denen der Bulk-Job eine Zeile aus Cassandra liest und die Daten aus der Zeile veraltet sind, wenn eingehende Schreibvorgänge die Zeile in Spanner aktualisieren, nachdem die Dual-Writes abgeschlossen sind.
- Teilweise Spaltenaktualisierungen:Wenn Sie eine Teilmenge von Spalten in einer vorhandenen Zeile aktualisieren, wird in Spanner ein Eintrag mit anderen Spalten als „null“ erstellt. Da bei Bulk-Updates vorhandene Zeilen nicht überschrieben werden, weichen die Zeilen zwischen Cassandra und Spanner voneinander ab.
In diesem Schritt werden die Daten zwischen der Quell- und der Zieldatenbank validiert und abgeglichen. Bei der Validierung werden Quelle und Ziel verglichen, um Inkonsistenzen zu erkennen. Bei der Abstimmung geht es darum, diese Inkonsistenzen zu beheben, um Datenkonsistenz zu erreichen.
Daten zwischen Cassandra und Spanner vergleichen
Wir empfehlen, sowohl die Anzahl der Zeilen als auch den tatsächlichen Inhalt der Zeilen zu validieren.
Die Entscheidung, wie Daten verglichen werden sollen (sowohl Anzahl als auch Zeilenabgleich), hängt von der Toleranz Ihrer Anwendung für Datenabweichungen und Ihren Anforderungen an eine genaue Validierung ab.
Es gibt zwei Möglichkeiten, Daten zu validieren:
Die aktive Validierung wird durchgeführt, während Dual Writes aktiv sind. In diesem Fall werden die Daten in Ihren Datenbanken weiterhin aktualisiert. Es ist möglicherweise nicht möglich, eine genaue Übereinstimmung bei der Anzahl der Zeilen oder dem Zeileninhalt zwischen Cassandra und Spanner zu erreichen. Ziel ist es, dass alle Unterschiede nur auf die aktive Last der Datenbanken zurückzuführen sind und nicht auf andere Fehler. Wenn die Abweichungen innerhalb dieser Grenzwerte liegen, können Sie mit der Umstellung fortfahren.
Für die Validierung des Static-Feeds ist eine Ausfallzeit erforderlich. Wenn Ihre Anforderungen eine starke, statische Validierung mit einer Garantie für genaue Datenkonsistenz erfordern, müssen Sie möglicherweise alle Schreibvorgänge in beide Datenbanken vorübergehend beenden. Anschließend können Sie Daten validieren und Unterschiede in Ihrer Spanner-Datenbank abgleichen.
Wählen Sie den Zeitpunkt der Validierung und die geeigneten Tools basierend auf Ihren spezifischen Anforderungen an die Datenkonsistenz und die akzeptable Ausfallzeit aus.
Anzahl der Zeilen in Cassandra und Spanner vergleichen
Eine Methode zur Datenvalidierung besteht darin, die Anzahl der Zeilen in Tabellen in der Quell- und Zieldatenbank zu vergleichen. Es gibt verschiedene Möglichkeiten, die Anzahl zu validieren:
Wenn Sie kleine Datasets migrieren (weniger als 10 Millionen Zeilen pro Tabelle), können Sie dieses Script für den Abgleich der Anzahl verwenden, um Zeilen in Cassandra und Spanner zu zählen. Mit diesem Ansatz werden genaue Anzahlwerte in kurzer Zeit zurückgegeben. Das Standardzeitlimit in Cassandra beträgt 10 Sekunden. Erhöhen Sie das Zeitlimit für Treiberanfragen und das serverseitige Zeitlimit, wenn das Script vor Abschluss der Zählung eine Zeitüberschreitung verursacht.
Bei der Migration großer Datasets (mehr als 10 Millionen Zeilen pro Tabelle) sollten Sie bedenken, dass Spanner-Zählabfragen gut skalieren, Cassandra-Abfragen jedoch häufig ein Zeitlimit überschreiten. In solchen Fällen empfehlen wir, das DataStax Bulk Loader-Tool zu verwenden, um die Anzahl der Zeilen aus Cassandra-Tabellen abzurufen. Für Spanner-Zählungen reicht die SQL-Funktion
count(*)für die meisten großen Lasten aus. Wir empfehlen, den Bulk Loader für jede Cassandra-Tabelle auszuführen, die Anzahl der Spanner-Tabelle abzurufen und die beiden Werte zu vergleichen. Das kann entweder manuell oder mithilfe eines Skripts erfolgen.
Auf Zeilenabweichungen prüfen
Wir empfehlen, Zeilen aus der Quell- und Zieldatenbank zu vergleichen, um Abweichungen zwischen Zeilen zu erkennen. Es gibt zwei Möglichkeiten, Zeilen zu validieren. Welche Sie verwenden, hängt von den Anforderungen Ihrer Anwendung ab:
- Eine zufällige Gruppe von Zeilen validieren.
- Validieren Sie das gesamte Dataset.
Zufällige Stichprobe von Zeilen validieren
Die Validierung eines gesamten Datasets ist bei großen Arbeitslasten teuer und zeitaufwendig. In diesen Fällen können Sie Stichproben verwenden, um eine zufällige Teilmenge der Daten zu validieren und nach Zeilenabweichungen zu suchen. Eine Möglichkeit besteht darin, zufällige Zeilen in Cassandra auszuwählen, die entsprechenden Zeilen in Spanner abzurufen und dann die Werte (oder den Zeilen-Hash) zu vergleichen.
Der Vorteil dieser Methode besteht darin, dass Sie schneller fertig sind als bei der Überprüfung eines gesamten Datasets und die Ausführung unkompliziert ist. Der Nachteil ist, dass es sich um eine Teilmenge der Daten handelt und es daher bei Grenzfall-Szenarien weiterhin zu Unterschieden kommen kann.
So wählen Sie zufällige Zeilen aus Cassandra aus:
- Generiert Zufallszahlen im Tokenbereich [
-2^63,2^63 - 1]. - Zeilen abrufen
WHERE token(PARTITION_KEY) > GENERATED_NUMBER
Das validation.go-Beispielskript ruft Zeilen nach dem Zufallsprinzip ab und validiert sie mit Zeilen in der Spanner-Datenbank.
Gesamtes Dataset validieren
Wenn Sie ein ganzes Dataset validieren möchten, rufen Sie alle Zeilen in der ursprünglichen Cassandra-Datenbank ab. Mit den Primärschlüsseln alle entsprechenden Spanner-Datenbankzeilen abrufen Anschließend können Sie die Zeilen auf Unterschiede vergleichen. Bei großen Datasets können Sie ein MapReduce-basiertes Framework wie Apache Spark oder Apache Beam verwenden, um das gesamte Dataset zuverlässig und effizient zu validieren.
Der Vorteil besteht darin, dass die vollständige Validierung eine höhere Zuverlässigkeit der Datenkonsistenz bietet. Die Nachteile sind, dass die Leselast für Cassandra erhöht wird und dass die Entwicklung komplexer Tools für große Datasets eine Investition erfordert. Bei einem großen Dataset kann die Validierung auch viel länger dauern.
Eine Möglichkeit hierfür besteht darin, die Tokenbereiche zu partitionieren und den Cassandra-Ring parallel abzufragen. Für jede Cassandra-Zeile wird die entsprechende Spanner-Zeile mit dem Partitionierungsschlüssel abgerufen. Diese beiden Zeilen werden dann auf Abweichungen verglichen. Hinweise zum Erstellen von Validierungsjobs finden Sie unter Tipps zum Validieren von Cassandra mit Zeilenabgleich.
Daten- oder Zeilenanzahldiskrepanzen abstimmen
Je nach den Anforderungen an die Datenkonsistenz können Sie Zeilen aus Cassandra in Spanner kopieren, um Abweichungen zu beheben, die während der Validierungsphase festgestellt wurden. Eine Möglichkeit zur Abstimmung besteht darin, das Tool zu erweitern, das für die Validierung des vollständigen Datasets verwendet wird, und die richtige Zeile aus Cassandra in die Ziel-Spanner-Datenbank zu kopieren, wenn eine Abweichung gefunden wird. Weitere Informationen finden Sie unter Überlegungen zur Implementierung.
Anwendung auf Spanner statt auf Cassandra verweisen
Nachdem Sie die Richtigkeit und Integrität Ihrer Daten nach der Migration überprüft haben, wählen Sie einen Zeitpunkt für die Migration Ihrer Anwendung aus, sodass sie auf Spanner anstatt auf Cassandra (oder auf den Proxy-Adapter, der für die Live-Datenmigration verwendet wird) verweist. Das wird als Umstellung bezeichnet.
So führen Sie die Umstellung durch:
Erstellen Sie eine Konfigurationsänderung für Ihre Clientanwendung, damit sie mit einer der folgenden Methoden direkt eine Verbindung zu Ihrer Spanner-Instanz herstellen kann:
- Verbinden Sie Cassandra mit dem Cassandra-Adapter, der als Sidecar ausgeführt wird.
- Ersetzen Sie die Treiber-JAR-Datei durch den Endpunktclient.
Wenden Sie die Änderung an, die Sie im vorherigen Schritt vorbereitet haben, um Ihre Anwendung auf Spanner zu verweisen.
Richten Sie das Monitoring für Ihre Anwendung ein, um Fehler oder Leistungsprobleme zu erkennen. Spanner-Messwerte mit Cloud Monitoring überwachen Weitere Informationen finden Sie unter Instanzen mit Cloud Monitoring überwachen.
Nach einer erfolgreichen Umstellung und einem stabilen Betrieb können Sie die ZDM-Proxy- und die Cassandra-Spanner-Proxy-Instanzen außer Betrieb nehmen.
Reverse-Replikation von Spanner zu Cassandra durchführen
Sie können die umgekehrte Replikation mit der Dataflow-Vorlage Spanner to
SourceDB durchführen.
Die umgekehrte Replikation ist nützlich, wenn unerwartete Probleme mit Spanner auftreten und Sie mit minimalen Unterbrechungen des Dienstes auf die ursprüngliche Cassandra-Datenbank zurückgreifen müssen.
Tipps zum Validieren von Cassandra mit Zeilenabgleich
Es ist langsam und ineffizient, vollständige Tabellenscans in Cassandra (oder einer anderen Datenbank) mit SELECT * durchzuführen. Um dieses Problem zu beheben, teilen Sie das Cassandra-Dataset in überschaubare Partitionen auf und verarbeiten Sie die Partitionen gleichzeitig. Gehen Sie dazu so vor:
- Datensatz in Tokenbereiche aufteilen
- Partitionen parallel abfragen
- Daten in jeder Partition lesen
- Entsprechende Zeilen aus Spanner abrufen
- Tools zur Designvalidierung für Erweiterbarkeit
- Nichtübereinstimmungen melden und protokollieren
Dataset in Tokenbereiche aufteilen
Cassandra verteilt Daten auf Knoten basierend auf Partitionierungsschlüssel-Tokens.
Der Tokenbereich für einen Cassandra-Cluster reicht von -2^63 bis 2^63 -
1. Sie können eine feste Anzahl von Tokenbereichen gleicher Größe definieren, um den gesamten Keyspace in kleinere Partitionen aufzuteilen. Wir empfehlen, den Tokenbereich mit einem konfigurierbaren partition_size-Parameter aufzuteilen, den Sie so abstimmen können, dass der gesamte Bereich schnell verarbeitet wird.
Partitionen parallel abfragen
Nachdem Sie die Tokenbereiche definiert haben, können Sie mehrere parallele Prozesse oder Threads starten, die jeweils für die Validierung von Daten in einem bestimmten Bereich zuständig sind. Für jeden Bereich können Sie CQL-Abfragen mit der token()-Funktion für Ihren Partitionsschlüssel (pk) erstellen.
Eine Beispielabfrage für einen bestimmten Tokenbereich würde so aussehen:
SELECT *
FROM your_keyspace.your_table
WHERE token(pk) >= partition_min_token AND token(pk) <= partition_max_token;
Indem Sie die definierten Tokenbereiche durchlaufen und diese Abfragen parallel für Ihren ursprünglichen Cassandra-Cluster (oder über den ZDM-Proxy, der für das Lesen aus Cassandra konfiguriert ist) ausführen, lesen Sie Daten effizient und verteilt.
Daten in jeder Partition lesen
Jeder parallele Prozess führt die bereichsbasierte Abfrage aus und ruft eine Teilmenge der Daten aus Cassandra ab. Prüfen Sie die Menge der abgerufenen Daten pro Partition, um ein Gleichgewicht zwischen Parallelität und Arbeitsspeichernutzung zu gewährleisten.
Entsprechende Zeilen aus Spanner abrufen
Rufen Sie für jede aus Cassandra abgerufene Zeile die entsprechende Zeile aus Ihrer Ziel-Spanner-Datenbank mit dem Quellzeilenschlüssel ab.
Zeilen vergleichen, um Abweichungen zu erkennen
Nachdem Sie sowohl die Cassandra-Zeile als auch die entsprechende Spanner-Zeile (falls vorhanden) haben, müssen Sie die Felder vergleichen, um etwaige Abweichungen zu ermitteln. Bei diesem Vergleich sollten potenzielle Unterschiede beim Datentyp und alle Transformationen berücksichtigt werden, die während der Migration angewendet wurden. Wir empfehlen Ihnen, anhand der Anforderungen Ihrer Anwendung klare Kriterien dafür zu definieren, was eine Nichtübereinstimmung darstellt.
Validierungstools für Erweiterbarkeit entwickeln
Entwerfen Sie Ihr Validierungstool so, dass es für die Abstimmung erweitert werden kann. Sie können beispielsweise Funktionen hinzufügen, um die richtigen Daten aus Cassandra in Spanner zu schreiben, wenn Abweichungen festgestellt werden.
Abweichungen melden und protokollieren
Wir empfehlen, alle erkannten Abweichungen mit ausreichend Kontext zu protokollieren, damit sie untersucht und abgeglichen werden können. Dazu gehören möglicherweise die Primärschlüssel, die spezifischen Felder, die sich unterscheiden, und die Werte aus Cassandra und Spanner. Möglicherweise möchten Sie auch Statistiken zur Anzahl und zu den Arten der gefundenen Abweichungen zusammenfassen.
TTL für Cassandra-Daten aktivieren und deaktivieren
In diesem Abschnitt wird beschrieben, wie Sie die Gültigkeitsdauer (Time to Live, TTL) für Cassandra-Daten in Spanner-Tabellen aktivieren und deaktivieren. Eine Übersicht finden Sie unter Gültigkeitsdauer (TTL).
TTL für Cassandra-Daten aktivieren
Bei den Beispielen in diesem Abschnitt wird davon ausgegangen, dass Sie eine Tabelle mit dem folgenden Schema haben:
CREATE TABLE Singers (
SingerId INT64 OPTIONS (cassandra_type = 'bigint'),
AlbumId INT64 OPTIONS (cassandra_type = 'int'),
) PRIMARY KEY (SingerId);
So aktivieren Sie die TTL auf Zeilenebene für eine vorhandene Tabelle:
Fügen Sie die Zeitstempelspalte hinzu, um den Ablaufzeitstempel für jede Zeile zu speichern. In diesem Beispiel heißt die Spalte
ExpiredAt, Sie können aber einen beliebigen Namen verwenden.ALTER TABLE Singers ADD COLUMN ExpiredAt TIMESTAMP;Fügen Sie die Richtlinie zum Löschen von Zeilen hinzu, um Zeilen, die älter als die Ablaufzeit sind, automatisch zu löschen.
INTERVAL 0 DAYbedeutet, dass Zeilen sofort nach Ablauf der Aufbewahrungsdauer gelöscht werden.ALTER TABLE Singers ADD ROW DELETION POLICY (OLDER_THAN(ExpiredAt, INTERVAL 0 DAY));Setzen Sie
cassandra_ttl_modeaufrow, um den TTL auf Zeilenebene zu aktivieren.ALTER TABLE Singers SET OPTIONS (cassandra_ttl_mode = 'row');Legen Sie optional
cassandra_default_ttlfest, um den Standard-TTL-Wert zu konfigurieren. Der Wert wird in Sekunden angegeben.ALTER TABLE Singers SET OPTIONS (cassandra_default_ttl = 10000);
TTL für Cassandra-Daten deaktivieren
Bei den Beispielen in diesem Abschnitt wird davon ausgegangen, dass Sie eine Tabelle mit dem folgenden Schema haben:
CREATE TABLE Singers (
SingerId INT64 OPTIONS ( cassandra_type = 'bigint' ),
AlbumId INT64 OPTIONS ( cassandra_type = 'int' ),
ExpiredAt TIMESTAMP,
) PRIMARY KEY (SingerId),
ROW DELETION POLICY (OLDER_THAN(ExpiredAt, INTERVAL 0 DAY)), OPTIONS (cassandra_ttl_mode = 'row');
So deaktivieren Sie die TTL auf Zeilenebene für eine vorhandene Tabelle:
Optional können Sie
cassandra_default_ttlauf null setzen, um den Standard-TTL-Wert zu entfernen.ALTER TABLE Singers SET OPTIONS (cassandra_default_ttl = 0);Setzen Sie
cassandra_ttl_modeaufnone, um die TTL auf Zeilenebene zu deaktivieren.ALTER TABLE Singers SET OPTIONS (cassandra_ttl_mode = 'none');Entfernen Sie die Richtlinie für das Löschen von Zeilen.
ALTER TABLE Singers DROP ROW DELETION POLICY;Entfernen Sie die Spalte mit dem Ablaufzeitstempel.
ALTER TABLE Singers DROP COLUMN ExpiredAt;
Hinweise zur Implementierung
- Frameworks und Bibliotheken:Für die skalierbare benutzerdefinierte Validierung verwenden Sie MapReduce-basierte Frameworks wie Apache Spark oder Dataflow (Beam). Wählen Sie eine unterstützte Sprache (Python, Scala, Java) aus und verwenden Sie Connectors für Cassandra und Spanner, z. B. über einen Proxy. Diese Frameworks ermöglichen die effiziente parallele Verarbeitung großer Datasets für eine umfassende Validierung.
- Fehlerbehandlung und Wiederholungsversuche:Implementieren Sie eine robuste Fehlerbehandlung, um potenzielle Probleme wie Netzwerkverbindungsprobleme oder die vorübergehende Nichtverfügbarkeit einer der beiden Datenbanken zu beheben. Erwägen Sie die Implementierung von Wiederholungsmechanismen für vorübergehende Fehler.
- Konfiguration:Die Tokenbereiche, Verbindungsdetails für beide Datenbanken und die Vergleichslogik müssen konfigurierbar sein.
- Leistungsoptimierung:Experimentieren Sie mit der Anzahl der parallelen Prozesse und der Größe der Tokenbereiche, um den Validierungsprozess für Ihre spezifische Umgebung und Ihr Datenvolumen zu optimieren. Beobachten Sie während der Validierung die Last auf Ihren Cassandra- und Spanner-Clustern.
Weitere Informationen
- Einen Vergleich zwischen Spanner und Cassandra finden Sie in der Cassandra-Übersicht.
- Verbindung zu Cloud Spanner mit dem Cassandra-Adapter herstellen