As tabelas derivadas abrem um mundo de possibilidades analíticas avançadas, mas podem ser difíceis de abordar, implementar e resolver problemas. Este livro de receitas contém os casos de uso mais comuns de tabelas derivadas no Looker.
Esta página contém os seguintes exemplos:
- Como criar uma tabela às 3h todos os dias
- Como anexar novos dados a uma tabela grande
- Usar funções de janela SQL
- Criar colunas derivadas para valores calculados
- Estratégias de otimização
- Usar TDPs para testar otimizações
UNIONduas tabelas- Fazer uma soma de uma soma (dimensionalizar uma medida)
- Tabelas de resumo com reconhecimento agregado
Recursos de tabela derivada
Esses livros de receitas pressupõem que você tenha uma compreensão introdutória da LookML e das tabelas derivadas. Você precisa saber criar visualizações e editar o arquivo de modelo. Se você quiser relembrar algum desses tópicos, confira os seguintes recursos:
- Tabelas derivadas
- Termos e conceitos do LookML
- Como criar tabelas derivadas nativas
- Referência do parâmetro
derived_table - Armazenamento de consultas em cache e recriação de PDTs com grupos de dados
Criar uma tabela às 3h da manhã todos os dias
Os dados neste exemplo chegam às 2h todos os dias. Os resultados de uma consulta nesses dados serão os mesmos, seja às 3h ou às 21h. Portanto, faz sentido criar a tabela uma vez por dia e permitir que os usuários extraiam resultados de um cache.
Incluir seu grupo de dados no arquivo de modelo permite reutilizá-lo com várias tabelas e análises detalhadas. Esse grupo de dados contém um parâmetro sql_trigger_value que informa ao grupo de dados quando acionar e recriar a tabela derivada.
Para mais exemplos de expressões de acionamento, consulte a documentação sql_trigger_value.
## in the model file
datagroup: standard_data_load {
sql_trigger_value: SELECT FLOOR(((TIMESTAMP_DIFF(CURRENT_TIMESTAMP(),'1970-01-01 00:00:00',SECOND)) - 60*60*3)/(60*60*24)) ;;
max_cache_age: "24 hours"
}
explore: orders {
…
Adicione o parâmetro datagroup_trigger à definição derived_table no arquivo de visualização e especifique o nome do grupo de dados que você quer usar. Neste exemplo, o grupo de dados é standard_data_load.
view: orders {
derived_table: {
indexes: ["id"]
datagroup_trigger: standard_data_load
sql:
SELECT
user_id,
id,
created_at,
status
FROM
demo_db.orders
GROUP BY
user_id ;;
}
…
}
Como anexar novos dados a uma tabela grande
Uma PDT incremental é uma tabela derivada persistente que o Looker cria anexando dados novos à tabela, em vez de recriá-la por completo.
O exemplo a seguir se baseia no exemplo da tabela orders para mostrar como a tabela é criada de forma incremental. Novos dados de pedidos chegam todos os dias e podem ser anexados à tabela atual quando você adiciona um parâmetro increment_key e um parâmetro increment_offset.
view: orders {
derived_table: {
indexes: ["id"]
increment_key: "created_at"
increment_offset: 3
datagroup_trigger: standard_data_load
distribution_style: all
sql:
SELECT
user_id,
id,
created_at,
status
FROM
demo_db.orders
GROUP BY
user_id ;;
}
dimension: id {
primary_key: yes
type: number
sql: ${TABLE}.id ;; }
…
}
O valor increment_key é definido como created_at, que é o incremento de tempo para o qual os dados atualizados precisam ser consultados e anexados à PDT neste exemplo.
O valor increment_offset é definido como 3 para especificar o número de períodos anteriores (na granularidade da chave de incremento) que são recriados para considerar os dados que chegam atrasados.
Como usar funções de janela SQL
Alguns dialetos de banco de dados oferecem suporte a funções de janela, especialmente para criar números de sequência, chaves primárias, totais contínuos e cumulativos e outros cálculos úteis de várias linhas. Depois que a consulta principal é executada, todas as declarações derived_column são executadas em uma transmissão separada.
Se o dialeto do seu banco de dados oferecer suporte a funções de janela, use-as na tabela derivada nativa. Crie um parâmetro derived_column com um parâmetro sql que contenha sua função de janela. Ao se referir a valores, use o nome da coluna conforme definido na tabela derivada nativa.
O exemplo a seguir mostra como criar uma tabela derivada nativa que inclui as colunas user_id, order_id e created_time. Em seguida, use uma coluna derivada com uma função de janela SQL ROW_NUMBER() para calcular uma coluna que contenha o número de sequência do pedido de um cliente.
view: user_order_sequences {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: order_id {
field: order_items.order_id
}
column: created_time {
field: order_items.created_time
}
derived_column: user_sequence {
sql: ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY created_time) ;;
}
}
}
dimension: order_id {
hidden: yes
}
dimension: user_sequence {
type: number
}
}
Como criar colunas derivadas para valores calculados
É possível adicionar parâmetros derived_column para especificar colunas que não existem na análise detalhada do parâmetro explore_source. Cada parâmetro derived_column tem um parâmetro sql que especifica como construir o valor.
O cálculo de sql pode usar qualquer coluna especificada com parâmetros column. As colunas derivadas não podem incluir funções de agregação, mas podem incluir cálculos que podem ser realizados em uma única linha da tabela.
Este exemplo cria uma coluna average_customer_order, que é calculada com base nas colunas lifetime_customer_value e lifetime_number_of_orders na tabela derivada nativa.
view: user_order_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: users.id
}
column: lifetime_number_of_orders {
field: order_items.count
}
column: lifetime_customer_value {
field: order_items.total_profit
}
derived_column: average_customer_order {
sql: lifetime_customer_value / lifetime_number_of_orders ;;
}
}
}
dimension: user_id {
hidden: yes
}
dimension: lifetime_number_of_orders {
type: number
}
dimension: lifetime_customer_value {
type: number
}
dimension: average_customer_order {
type: number
}
}
Estratégias de otimização
Como as TDPs são armazenadas no banco de dados, é necessário otimizá-las usando as seguintes estratégias, conforme compatibilidade com seu dialeto:
Por exemplo, para adicionar persistência, você pode definir a PDT para ser recriada quando o grupo de dados orders_datagroup for acionado e adicionar índices em customer_id e first_order, conforme mostrado a seguir:
view: customer_order_summary {
derived_table: {
explore_source: orders {
...
}
datagroup_trigger: orders_datagroup
indexes: ["customer_id", "first_order"]
}
}
Se você não adicionar um índice (ou um equivalente para seu dialeto), o Looker vai avisar que é preciso fazer isso para melhorar o desempenho da consulta.
Como usar PDTs para testar otimizações
Você pode usar PDTs para testar diferentes opções de indexação, distribuições e outras opções de otimização sem precisar de muito suporte do DBA ou dos desenvolvedores de ETL.
Considere um caso em que você tem uma tabela, mas quer testar diferentes índices. Sua LookML inicial para a visualização pode ser semelhante a esta:
view: customer {
sql_table_name: warehouse.customer ;;
}
Para testar estratégias de otimização, use o parâmetro indexes para adicionar índices à LookML, conforme mostrado a seguir:
view: customer {
# sql_table_name: warehouse.customer
derived_table: {
sql: SELECT * FROM warehouse.customer ;;
persist_for: "8 hours"
indexes: [customer_id, customer_name, salesperson_id]
}
}
Consulte a visualização uma vez para gerar a TDP. Em seguida, execute as consultas de teste e compare os resultados. Se os resultados forem favoráveis, peça ao DBA ou à equipe de ETL para adicionar os índices à tabela original.
UNION duas tabelas
É possível executar um operador SQL UNION ou UNION ALL nas duas tabelas derivadas se o dialeto SQL for compatível. Os operadores UNION e UNION ALL combinam os conjuntos de resultados de duas consultas.
Este exemplo mostra como uma tabela derivada baseada em SQL aparece com um UNION:
view: first_and_second_quarter_sales {
derived_table: {
sql:
SELECT * AS sales_records
FROM sales_records_first_quarter
UNION
SELECT * AS sales_records
FROM sales_records_second_quarter ;;
}
}
A instrução UNION no parâmetro sql produz uma tabela derivada que combina os resultados das duas consultas.
A diferença entre UNION e UNION ALL é que UNION ALL não remove linhas duplicadas. Há considerações de desempenho a serem lembradas ao usar UNION em vez de UNION ALL, já que o servidor de banco de dados precisa fazer um trabalho extra para remover as linhas duplicadas.
Fazer uma soma de uma soma (dimensionalizar uma medida)
Como regra geral em SQL e, por extensão, no Looker, não é possível agrupar uma consulta pelos resultados de uma função de agregação (representada no Looker como medidas). Só é possível agrupar por campos não agregados (representados no Looker como dimensões).
Para agrupar por um agregado (por exemplo, para fazer a soma de uma soma), é necessário "dimensionalizar" uma métrica. Uma maneira de fazer isso é usar uma tabela derivada, que cria uma subconsulta do agregado.
Começando com uma análise detalhada, o Looker pode gerar LookML para toda ou a maior parte da sua tabela derivada. Basta criar uma análise detalhada e selecionar todos os campos que você quer incluir na tabela derivada. Em seguida, para gerar a LookML de tabela derivada nativa (ou baseada em SQL), siga estas etapas:
Clique no menu de engrenagem da Análise e selecione Receber LookML.
Para conferir o LookML de criação de uma tabela derivada nativa para a análise, clique na guia Tabela derivada.
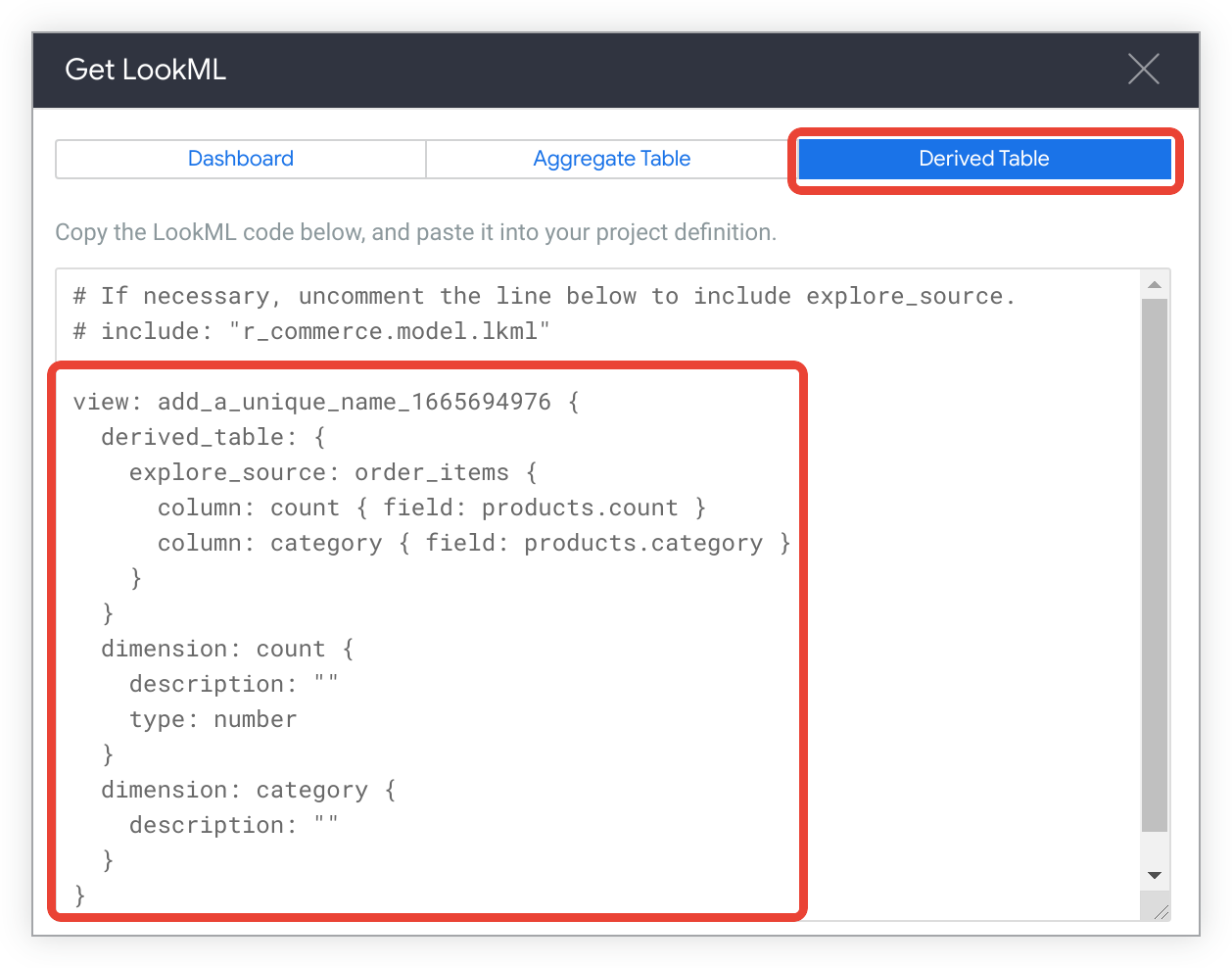
Copie o LookML.
Agora que você copiou o LookML gerado, cole-o em um arquivo de visualização seguindo estas etapas:
No modo de desenvolvimento, navegue até os arquivos do projeto.
Clique no + na parte de cima da lista de arquivos do projeto no ambiente de desenvolvimento integrado do Looker e selecione Criar visualização. Como alternativa, para criar o arquivo dentro da pasta, clique no menu de uma pasta e selecione Criar visualização.
Defina um nome significativo para a visualização.
Se quiser, mude os nomes das colunas, especifique colunas derivadas e adicione filtros.
Tabelas de resumo com reconhecimento agregado
No Looker, é comum encontrar conjuntos de dados ou tabelas muito grandes que, para ter um bom desempenho, exigem tabelas de agregação ou resumos.
Com o reconhecimento de agregação do Looker, é possível pré-construir tabelas agregadas em vários níveis de granularidade, dimensionalidade e agregação, além de informar ao Looker como usá-las nas análises detalhadas atuais. As consultas vão usar essas tabelas de resumo quando o Looker achar adequado, sem nenhuma entrada do usuário. Isso vai reduzir o tamanho da consulta, diminuir os tempos de espera e melhorar a experiência do usuário.
Confira a seguir uma implementação muito simples em um modelo do Looker para demonstrar como a agregação leve pode ser. Supondo que você tenha uma tabela hipotética de voos no banco de dados com uma linha para cada voo registrado pela FAA, é possível modelar essa tabela no Looker com uma visualização e uma análise detalhada próprias. Confira abaixo o LookML de uma tabela de agregação que pode ser definida para a Análise:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
Com essa tabela agregada, um usuário pode consultar a análise detalhada flights, e o Looker vai usar automaticamente a tabela agregada para responder às consultas. Para um tutorial mais detalhado sobre a percepção agregada, acesse Tutorial sobre a percepção agregada.