派生テーブルは、高度な分析の可能性を広げますが、アプローチ、実装、トラブルシューティングが困難な場合があります。このクックブックには、Looker における派生テーブルの最も一般的なユースケースが含まれています。
このページには、次の例を記載しています。
- 毎日午前 3 時にテーブルをビルドする
- 新しいデータを大きなテーブルに追加する
- SQLウィンドウ関数の使用
- 計算値の派生列の作成
- 最適化戦略
- PDT を使用して最適化をテストする
- 2 つのテーブルを
UNIONで結合する - 合計の合計を取得する(measure のディメンション化)
- 集計認識付きロールアップ テーブル
派生テーブル リソース
このクックブックは、LookML と派生テーブルについて基本的な知識があることを前提としています。ビューの作成とモデルファイルの編集には慣れている必要があります。こうしたトピックを復習する場合は、次のリソースをご覧ください。
毎日午前 3 時にテーブルをビルドする
この例では、毎日午前 2 時にデータが送られてきます。このデータに対するクエリは、午前 3 時に実行しても午後 9 時に実行しても、同じ結果になります。したがって、テーブルを 1 日に 1 回作成し、ユーザーがキャッシュから結果を引き出せるようにすることは理にかなっています。
モデルファイルにデータグループを含めると、複数のテーブルや Explore で再利用できます。このデータグループには、派生テーブルをトリガーして再構築するタイミングをデータグループに指示する sql_trigger_value パラメータが含まれています。
トリガー式のその他の例については、sql_trigger_value のドキュメントをご覧ください。
## in the model file
datagroup: standard_data_load {
sql_trigger_value: SELECT FLOOR(((TIMESTAMP_DIFF(CURRENT_TIMESTAMP(),'1970-01-01 00:00:00',SECOND)) - 60*60*3)/(60*60*24)) ;;
max_cache_age: "24 hours"
}
explore: orders {
…
ビューファイルの derived_table 定義に datagroup_trigger パラメータを追加し、使用するデータグループの名前を指定します。この例では、データグループは standard_data_load です。
view: orders {
derived_table: {
indexes: ["id"]
datagroup_trigger: standard_data_load
sql:
SELECT
user_id,
id,
created_at,
status
FROM
demo_db.orders
GROUP BY
user_id ;;
}
…
}
新しいデータを大きなテーブルに追加する
増分 PDT は永続的な派生テーブルです。Looker はテーブル全体を再構築するのではなく、テーブルに新しいデータを追加して構築します。
次の例では、orders テーブルの例を基に、テーブルが段階的に構築される様子を示します。increment_key パラメータと increment_offset パラメータを追加すると、新しい注文データは毎日入ってきて、既存のテーブルに追加できます。
view: orders {
derived_table: {
indexes: ["id"]
increment_key: "created_at"
increment_offset: 3
datagroup_trigger: standard_data_load
distribution_style: all
sql:
SELECT
user_id,
id,
created_at,
status
FROM
demo_db.orders
GROUP BY
user_id ;;
}
dimension: id {
primary_key: yes
type: number
sql: ${TABLE}.id ;; }
…
}
この例では、increment_key 値には created_at が設定され、新しいデータをクエリして PDT に追加する時間増分になります。
increment_offset 値には 3 が設定さて、遅れて到着したデータを考慮して再構築する、以前の期間(インクリメント キーの粒度)の数を指定します。
SQLウィンドウ関数の使用
一部のデータベース言語はウィンドウ関数をサポートしており、特にシーケンス番号、主キー、実行中の累積合計、その他の便利な複数行の計算を行うことができます。プライマリクエリが実行された後、derived_column 宣言が個別に実行されます。
データベース言語がウィンドウ関数に対応している場合は、ネイティブ派生テーブルでその関数を使用できます。ウィンドウ関数を含む sql パラメータで derived_column パラメータを作成します。値を参照する際には、ネイティブ派生テーブルで定義された列名を使用する必要があります。
次の例では、user_id、order_id、created_time の各列を含むネイティブ派生テーブルを作成する方法を示します。その後、SQL ROW_NUMBER() ウィンドウ関数で派生列を使用して、お客様の注文のシーケンス番号を含む列を計算します。
view: user_order_sequences {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: order_id {
field: order_items.order_id
}
column: created_time {
field: order_items.created_time
}
derived_column: user_sequence {
sql: ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY created_time) ;;
}
}
}
dimension: order_id {
hidden: yes
}
dimension: user_sequence {
type: number
}
}
計算値の派生列の作成
derived_column パラメータを追加すると、explore_source パラメータの Explore に存在しない列を指定できます。各 derived_column パラメータには、値の作成方法を指定する sql パラメータがあります。
sql 計算では、column パラメータで指定した任意の列を使用できます。派生列に集計関数を含めることはできませんが、テーブルの単一行に対して実行される計算を含めることができます。
この例では、ネイティブ派生テーブルの lifetime_customer_value 列と lifetime_number_of_orders 列から計算される average_customer_order 列を作成します。
view: user_order_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: users.id
}
column: lifetime_number_of_orders {
field: order_items.count
}
column: lifetime_customer_value {
field: order_items.total_profit
}
derived_column: average_customer_order {
sql: lifetime_customer_value / lifetime_number_of_orders ;;
}
}
}
dimension: user_id {
hidden: yes
}
dimension: lifetime_number_of_orders {
type: number
}
dimension: lifetime_customer_value {
type: number
}
dimension: average_customer_order {
type: number
}
}
最適化戦略
PDT はデータベースに保存されるため、お使いの言語でサポートされているとおり、以下の戦略を使用して PDT を最適化する必要があります。
たとえば、永続性を追加するには、次のように、データグループ orders_datagroup がトリガーされたときに PDT を再構築するように設定し、インデックスを customer_id と first_order の両方に追加できます。
view: customer_order_summary {
derived_table: {
explore_source: orders {
...
}
datagroup_trigger: orders_datagroup
indexes: ["customer_id", "first_order"]
}
}
インデックス(またはご使用のダイアレクトでそれに相当するもの)を追加しない場合、クエリのパフォーマンス改善のため追加するよう Looker から警告が表示されます。
PDT を使用して最適化をテストする
PDT を使用すると、DBA や ETL デベロッパーから多くのサポートがなくても、さまざまなインデックス、分散、その他の最適化オプションをテストできます。
テーブルが 1 つあり、さまざまなインデックスをテストする必要があるとします。ビューの最初の LookML は、次のようになります。
view: customer {
sql_table_name: warehouse.customer ;;
}
最適化戦略をテストするには、indexes パラメータを使用して、次のように LookML にインデックスを追加します。
view: customer {
# sql_table_name: warehouse.customer
derived_table: {
sql: SELECT * FROM warehouse.customer ;;
persist_for: "8 hours"
indexes: [customer_id, customer_name, salesperson_id]
}
}
ビューに対して 1 回クエリを実行して PDT を生成します。次に、テストクエリを実行して結果を比較します。結果に問題がなければ、DBA または ETL チームにインデックスを元のテーブルに追加するように依頼できます。
2 つのテーブルを UNION で結合する
SQL 言語がサポートしている場合は、両方の派生テーブルで SQL の UNION 演算子または UNION ALL 演算子を実行できます。UNION 演算子と UNION ALL 演算子は、2 つのクエリの結果セットを結合します。
次の例では、UNION を使用した SQL ベースの派生テーブルがどのように見えるかを示します。
view: first_and_second_quarter_sales {
derived_table: {
sql:
SELECT * AS sales_records
FROM sales_records_first_quarter
UNION
SELECT * AS sales_records
FROM sales_records_second_quarter ;;
}
}
sql パラメータの UNION ステートメントは、両方のクエリの結果を組み合わせた派生テーブルを生成します。
UNION と UNION ALL の違いは、UNION ALL では重複する行が削除されないことです。UNION と UNION ALL を使用する場合は、データベース サーバーが重複する行を削除することから追加作業を行う必要があるため、パフォーマンスについて考慮すべき点があります。
合計の合計を取得する(measure のディメンション化)
SQL の一般的なルールとして、また Looker への拡張として、集計関数の結果(Looker では measure)によってクエリをグループ化することはできません。グループ化は、集計されていないフィールド(Looker ではディメンション)でのみ行えます。
集計でグループ化する(たとえば、合計の合計を取得する)には、measure を「ディメンション化」する必要があります。これを行う方法の 1 つは、派生テーブルを使用することです。これにより、集計のサブクエリが実質的に作成されます。
Exploreで開始すると、Lookerは大半の派生テーブルのLookMLを生成できます。 Explore を作成し、派生テーブルに含めるすべてのフィールドを選択するだけです。その後、ネイティブ(または SQL ベースの)派生テーブル LookML を生成するには、次の手順に沿って操作します。
Explore の歯車アイコンをクリックし、[LookML を取得] を選択します。

Explore のネイティブ派生テーブルを作成するための LookML を表示するには、[派生テーブル] タブをクリックします。
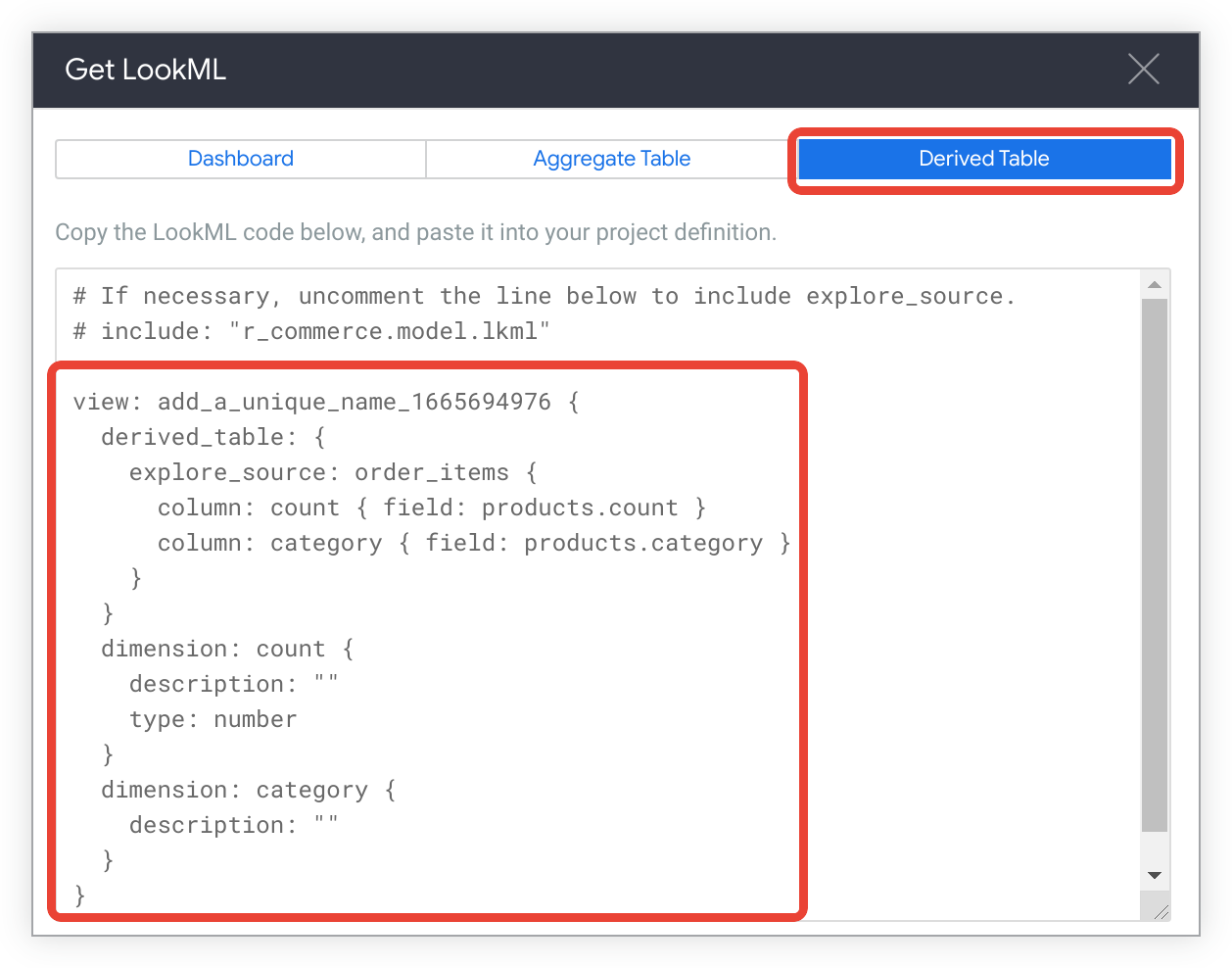
そのLookMLをコピーします。
生成された LookML をコピーしたら、次の手順でビューファイルに貼り付けます。
Development Mode で、プロジェクト ファイルに移動します。
Looker IDE のプロジェクト ファイル リストの上部にある [+] をクリックし、[ビューを作成] を選択します。または、フォルダ内にファイルを作成するには、フォルダのメニューをクリックして [ビューを作成] を選択します。
内容がわかりやすいビュー名を設定します。
必要に応じて、列名の変更、派生列の指定、フィルタの追加を行います。
集計認識付きロールアップ テーブル
Looker では、非常に大きなデータセットやテーブルが発生し、パフォーマンスを改善するために、集約テーブルやロールアップが必要になることがあります。
Looker の集計認識により、さまざまな粒度、ディメンション、集計レベルの集約テーブルを事前構築できます。また、Looker には、既存の Explore 内での使用方法を知らせることができます。その後、クエリは、Looker が適切と判断するこうしたロールアップ テーブルを、ユーザーからの入力なしで使用します。これにより、クエリのサイズが削減され、待ち時間が短縮されて、ユーザー エクスペリエンスが向上します。
以下に、Looker モデルでの非常に単純な実装で、集約テーブルの自動認識がいかに軽量になるかを示します。FAA を通じて記録されたすべてのフライトの行がある、データベース内の仮想的なフライト テーブルを考えると、独自のビューと Explore を使用して Looker でこのテーブルをモデル化できます。Explore 用に定義できる集計テーブルの LookML は次のとおりです。
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
この集約テーブルを使用して、ユーザーが flights Explore に対してクエリを実行すると、Looker は自動的に集約テーブルを使用してクエリに回答します。集計認識の詳細なチュートリアルについては、集計認識のチュートリアルをご覧ください。