BigQuery supports nested records in tables. Nested records can be a single record or contain repeated values. This page provides an overview of working with BigQuery nested data in Looker.
The advantages of nested records
There are a few advantages to using nested records when you're scanning a distributed dataset:
- Nested records do not require joins. This means that computations can be faster and scan much less data than if you had to rejoin the extra data each time you query it.
- Nested structures are essentially pre-joined tables. There is no added expense for the query if you do not reference the nested column, because BigQuery data is stored in columns. If you do reference the nested column, the logic is identical to a colocated join.
- Nested structures avoid repeating data that would have to be repeated in a wide denormalized table. In other words, for a person who has lived in five cities, a wide denormalized table would contain all their information in five rows (one for each of the cities they have lived in). In a nested structure, the repeated information only takes one row since the array of five cities can be contained in a single row and unnested when needed.
Working with nested records in LookML
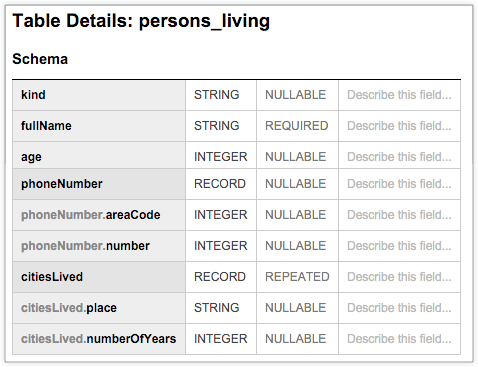
The following BigQuery table, persons_living, displays a typical schema that stores example user data, including fullName, age, phoneNumber, and citiesLived along with the datatype and mode of each column. The schema shows that the values in the citiesLived column are repeated, indicating that some users may have lived in multiple cities:
The following example is the LookML for the Explores and views you can create from the previous schema shown. There are three views: persons, persons_cities_lived, and persons_phone_number. The Explore appears identical to an Explore that is written with non-nested tables.
Note: While all the components (views and Explore) are written in one code block in the following example, it is best practice to place views in individual view files and to place Explores and connection: specification in the model file.
-- model file
connection: "bigquery_publicdata_standard_sql"
explore: persons {
# Repeated nested object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived ;;
relationship: one_to_many
}
# Non repeated nested object
join: persons_phone_number {
view_label: "Persons: Phone:"
sql: LEFT JOIN UNNEST([${persons.phoneNumber}]) as persons_phone_number ;;
relationship: one_to_one
}
}
-- view files
view: persons {
sql_table_name: bigquery-samples.nested.persons_living ;;
dimension: id {
primary_key: yes
sql: ${TABLE}.fullName ;;
}
dimension: fullName {label: "Full Name"}
dimension: kind {}
dimension: age {type:number}
dimension: citiesLived {hidden:yes}
dimension: phoneNumber {hidden:yes}
measure: average_age {
type: average
sql: ${age} ;;
drill_fields: [fullName,age]
}
measure: count {
type: count
drill_fields: [fullName, cities_lived.place_count, age]
}
}
view: persons_phone_number {
dimension: areaCode {label: "Area Code"}
dimension: number {}
}
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${place} AS STRING)) ;;
}
dimension: place {}
dimension: numberOfYears {
label: "Number Of Years"
type: number
}
measure: place_count {
type: count
drill_fields: [place, persons.count]
}
measure: total_years {
type: sum
sql: ${numberOfYears} ;;
drill_fields: [persons.fullName, persons.age, place, numberOfYears]
}
}
Each component for working with nested data in LookML is discussed in greater detail in the following sections:
Views
Each nested record is written as a view. For example, the phoneNumber view simply declares the dimensions that appear in the record:
view: persons_phone_number {
dimension: areaCode {label: "Area Code"}
dimension: number {}
}
The persons_cities_lived view is more complex. As shown in the LookML example, you define the dimensions that appear in the record (numberOfYears and place), but you can also define some measures. The measures and drill_fields are defined as usual, as if this data were in its own table. The only real difference is that you declare id as a primary_key so that aggregates are properly calculated.
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${place} AS STRING)) ;;
}
dimension: place {}
dimension: numberOfYears {
label: "Number Of Years"
type: number
}
measure: place_count {
type: count
drill_fields: [place, persons.count]
}
measure: total_years {
type: sum
sql: ${numberOfYears} ;;
drill_fields: [persons.fullName, persons.age, place, numberOfYears]
}
}
Record declarations
In the view that contains the subrecords (in this case persons), you need to declare the records. These will be used when you create the joins. You can hide these LookML fields with the hidden parameter because you won't need them when exploring the data.
view: persons {
...
dimension: citiesLived {
hidden:yes
}
dimension: phoneNumber {
hidden:yes
}
...
}
Joins
Nested records in BigQuery are arrays of STRUCT elements. Instead of joining with a sql_on parameter, the join relationship is built into the table. In this case, you can use the sql: join parameter so that you can use the UNNEST operator. Other than that difference, unnesting an array of STRUCT elements is exactly like joining a table.
In the case of non-repeated records, you can simply use STRUCT; you can turn that into an array of STRUCT elements by placing it in square brackets. While this may appear strange, there seems be be no performance penalty — and this keeps things clean and simple.
explore: persons {
# Repeated nested object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived ;;
relationship: one_to_many
}
# Non repeated nested object
join: persons_phone_number {
view_label: "Persons: Phone:"
sql: LEFT JOIN UNNEST([${persons.phoneNumber}]) as persons_phone_number ;;
relationship: one_to_one
}
}
Joins for arrays without unique keys for each row
While it is best to have identifiable natural keys in the data, or surrogate keys created in the ETL process, this is not always possible. For example, you could encounter a situation where some arrays don't have a relative unique key for the row. This is where WITH OFFSET can come in handy in join syntax.
For example, a column representing a person might load multiple times if the person has lived in multiple cities — Chicago, Denver, San Francisco, etc. It can be difficult to create a primary key on the unnested row if a date or other identifiable natural key is not provided to distinguish the person's tenure in each city. This is where WITH OFFSET can provide a relative row number (0,1,2,3) for each unnested row. This approach guarantees a unique key on the unnested row:
explore: persons {
# Repeated nested Object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived WITH OFFSET as person_cities_lived_offset;;
relationship: one_to_many
}
}
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${offset} AS STRING)) ;;
}
dimension: offset {
type: number
sql: person_cities_lived_offset;;
}
}
Simple repeated values
Nested data in BigQuery can also be simple values, such as integers or strings. To unnest arrays of simple repeated values, you can use a similar approach as shown previously, using the UNNEST operator in a join.
The following example unnests a given array of integers, `unresolved_skus`:
explore: impressions {
join: impressions_unresolved_sku {
sql: LEFT JOIN UNNEST(unresolved_skus) AS impressions_unresolved_sku ;;
relationship: one_to_many
}
}
view: impressions_unresolved_sku {
dimension: sku {
type: string
sql: ${TABLE} ;;
}
}
The sql parameter for the array of integers, unresolved_skus, is represented as ${TABLE}. This directly references the table of values itself, which is then unnested in the explore.