O BigQuery oferece suporte a registros aninhados em tabelas. Os registros aninhados podem ser um único registro ou conter valores repetidos. Esta página oferece uma visão geral sobre como trabalhar com dados aninhados do BigQuery no Looker.
As vantagens dos registros aninhados
Há algumas vantagens em usar registros aninhados ao verificar um conjunto de dados distribuído:
- Registros aninhados não exigem mesclas. Isso significa que as computações podem ser mais rápidas e verificar muito menos dados do que se você precisasse juntar os dados extras toda vez que consultasse.
- Estruturas aninhadas são basicamente tabelas pré-mescladas. Não há custo extra para a consulta se você não fizer referência à coluna aninhada, porque os dados do BigQuery são armazenados em colunas. Se você fizer referência à coluna aninhada, a lógica será idêntica a uma mesclagem colocalizada.
- As estruturas aninhadas evitam a repetição de dados que teriam que ser repetidos em uma tabela ampla e desnormalizada. Em outras palavras, para uma pessoa que morou em cinco cidades, uma tabela denormalizada ampla conteria todas as informações dela em cinco linhas (uma para cada cidade em que ela morou). Em uma estrutura aninhada, as informações repetidas ocupam apenas uma linha, já que a matriz de cinco cidades pode ser contida em uma única linha e desaninhada quando necessário.
Como trabalhar com registros aninhados no LookML
A tabela persons_living do BigQuery a seguir mostra um esquema típico que armazena dados de exemplo do usuário, incluindo fullName, age, phoneNumber e citiesLived, além do tipo de dados e do modo de cada coluna. O esquema mostra que os valores na coluna citiesLived são repetidos, indicando que alguns usuários podem ter vivido em várias cidades:
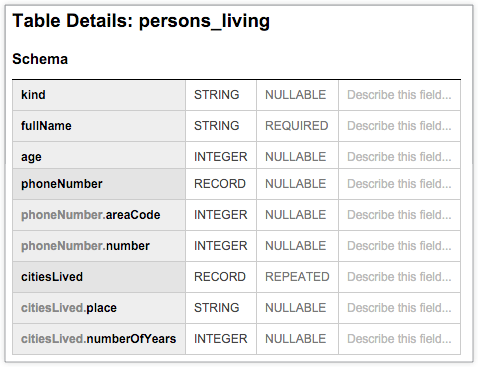
O exemplo a seguir é o LookML para as análises detalhadas e visualizações que você pode criar com base no esquema anterior mostrado. Há três visualizações: persons, persons_cities_lived e persons_phone_number. O recurso "Análise" aparece idêntico a um que é escrito com tabelas não aninhadas.
Observação:embora todos os componentes (visualizações e Análises) sejam escritos em um bloco de código no exemplo abaixo, é recomendável colocar as visualizações em arquivos de visualização individuais e colocar as Análises e a especificação connection: no arquivo de modelo.
-- model file
connection: "bigquery_publicdata_standard_sql"
explore: persons {
# Repeated nested object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived ;;
relationship: one_to_many
}
# Non repeated nested object
join: persons_phone_number {
view_label: "Persons: Phone:"
sql: LEFT JOIN UNNEST([${persons.phoneNumber}]) as persons_phone_number ;;
relationship: one_to_one
}
}
-- view files
view: persons {
sql_table_name: bigquery-samples.nested.persons_living ;;
dimension: id {
primary_key: yes
sql: ${TABLE}.fullName ;;
}
dimension: fullName {label: "Full Name"}
dimension: kind {}
dimension: age {type:number}
dimension: citiesLived {hidden:yes}
dimension: phoneNumber {hidden:yes}
measure: average_age {
type: average
sql: ${age} ;;
drill_fields: [fullName,age]
}
measure: count {
type: count
drill_fields: [fullName, cities_lived.place_count, age]
}
}
view: persons_phone_number {
dimension: areaCode {label: "Area Code"}
dimension: number {}
}
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${place} AS STRING)) ;;
}
dimension: place {}
dimension: numberOfYears {
label: "Number Of Years"
type: number
}
measure: place_count {
type: count
drill_fields: [place, persons.count]
}
measure: total_years {
type: sum
sql: ${numberOfYears} ;;
drill_fields: [persons.fullName, persons.age, place, numberOfYears]
}
}
Cada componente para trabalhar com dados aninhados no LookML é discutido em mais detalhes nas seções a seguir:
Visualizações
Cada registro aninhado é gravado como uma visualização. Por exemplo, a visualização phoneNumber declara as dimensões que aparecem no registro:
view: persons_phone_number {
dimension: areaCode {label: "Area Code"}
dimension: number {}
}
A visualização persons_cities_lived é mais complexa. Como mostrado no exemplo do LookML, você define as dimensões que aparecem no registro (numberOfYears e place), mas também pode definir algumas medições. As medidas e o drill_fields são definidos normalmente, como se estivessem na própria tabela. A única diferença real é que você declara id como um primary_key para que os agregados sejam calculados corretamente.
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${place} AS STRING)) ;;
}
dimension: place {}
dimension: numberOfYears {
label: "Number Of Years"
type: number
}
measure: place_count {
type: count
drill_fields: [place, persons.count]
}
measure: total_years {
type: sum
sql: ${numberOfYears} ;;
drill_fields: [persons.fullName, persons.age, place, numberOfYears]
}
}
Declarações de registro
Na visualização que contém os subregistros (neste caso, persons), é necessário declarar os registros. Elas serão usadas quando você criar as juntas. É possível ocultar esses campos do LookML com o parâmetro hidden, porque você não vai precisar deles ao analisar os dados.
view: persons {
...
dimension: citiesLived {
hidden:yes
}
dimension: phoneNumber {
hidden:yes
}
...
}
Mesclagens
Os registros aninhados no BigQuery são matrizes de elementos STRUCT. Em vez de fazer a mesclagem com um parâmetro sql_on, a relação de mesclagem é integrada à tabela. Nesse caso, use o parâmetro de mesclagem sql: para usar o operador UNNEST. Além dessa diferença, desaninhar uma matriz de elementos STRUCT é exatamente como mesclar uma tabela.
No caso de registros não repetidos, basta usar STRUCT. Você pode transformar isso em uma matriz de elementos STRUCT colocando-a entre colchetes. Embora isso pareça estranho, não há penalidade de desempenho. Isso mantém as coisas limpas e simples.
explore: persons {
# Repeated nested object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived ;;
relationship: one_to_many
}
# Non repeated nested object
join: persons_phone_number {
view_label: "Persons: Phone:"
sql: LEFT JOIN UNNEST([${persons.phoneNumber}]) as persons_phone_number ;;
relationship: one_to_one
}
}
Junções para matrizes sem chaves exclusivas para cada linha
Embora seja melhor ter chaves naturais identificáveis nos dados ou chaves substitutas criadas no processo de ETL, nem sempre isso é possível. Por exemplo, você pode encontrar uma situação em que algumas matrizes não têm uma chave exclusiva relativa para a linha. É aí que o WITH OFFSET pode ser útil na sintaxe de mesclagem.
Por exemplo, uma coluna que representa uma pessoa pode ser carregada várias vezes se ela tiver vivido em várias cidades, como Chicago, Denver, São Francisco etc. Pode ser difícil criar uma chave primária na linha não aninhada se uma data ou outra chave natural identificável não for fornecida para distinguir a permanência da pessoa em cada cidade. É aqui que WITH OFFSET pode fornecer um número de linha relativo (0,1,2,3) para cada linha não aninhada. Essa abordagem garante uma chave exclusiva na linha não aninhada:
explore: persons {
# Repeated nested Object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived WITH OFFSET as person_cities_lived_offset;;
relationship: one_to_many
}
}
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${offset} AS STRING)) ;;
}
dimension: offset {
type: number
sql: person_cities_lived_offset;;
}
}
Valores simples repetidos
Os dados aninhados no BigQuery também podem ser valores simples, como números inteiros ou strings. Para desagrupar matrizes de valores repetidos simples, use uma abordagem semelhante à mostrada anteriormente, usando o operador UNNEST em uma mesclagem.
O exemplo a seguir desaninha uma determinada matriz de números inteiros, "unresolved_skus":
explore: impressions {
join: impressions_unresolved_sku {
sql: LEFT JOIN UNNEST(unresolved_skus) AS impressions_unresolved_sku ;;
relationship: one_to_many
}
}
view: impressions_unresolved_sku {
dimension: sku {
type: string
sql: ${TABLE} ;;
}
}
O parâmetro sql para a matriz de números inteiros, unresolved_skus, é representado como ${TABLE}. Isso faz referência direta à tabela de valores, que é desaninhada no explore.