Cuando tienes permiso para crear campos personalizados, puedes crear grupos personalizados ad hoc para las dimensiones sin usar funciones lógicas en expresiones de Looker ni desarrollar lógicaCASE WHENen parámetrossqlo campostype: case.
También puedes crear intervalos personalizados ad hoc para dimensiones de tipo numérico sin necesidad de usar funciones lógicas en expresiones de Looker ni de desarrollar campos de LookML type: tier cuando tienes permiso para crear campos personalizados.
El agrupamiento puede ser muy útil para crear dimensiones de agrupación personalizadas en Looker.
Existen tres maneras de crear buckets en Looker:
- Cómo usar el tipo
dimensiontier - Usa el parámetro
case - Usa una sentencia
CASE WHENde SQL en el parámetroSQLde un campo de LookML
Usa tier para el agrupamiento
Para crear buckets de números enteros, simplemente podemos definir el tipo dimension como tier:
dimension: users_lifetime_orders_tier {
type: tier
tiers: [0,1,2,5,10]
sql: ${users_lifetime_orders} ;;
}
Puedes usar el parámetro style para personalizar cómo aparecen tus niveles durante la exploración. Estas son las cuatro opciones para style:
Por ejemplo:
dimension: age_tier {
type: tier
tiers: [0,10,20,30,40,50,60,70,80]
style: integer
sql: ${age} ;;
}
El parámetro style classic es el predeterminado y tiene el formato Tx[x,x], con Tx que indica el número de nivel y [x,x] que indica el rango. La siguiente imagen es una tabla de datos de Explorar con Cantidad de usuarios agrupados por Edad de los usuarios:
![El nivel superior disponible de Edad de los usuarios en la tabla de datos es T02[10,20], que indica un registro de 808 usuarios de entre 10 y 20 años.](https://cloud.google.com/static/looker/docs/images/bucketing-in-looker-1-2210.png?hl=es-419)
En la siguiente imagen, se muestran ejemplos de las otras opciones de parámetros style:
-
interval: Con el formato[x,x], que indica el valor más bajo y el más alto de un nivel -
integer: Con el formatox to x, que indica el valor más bajo y el más alto de un nivel -
relational: Con el formato>= x and <x, que indica que un valor es mayor o igual que el valor del nivel más bajo y menor que el valor del nivel más alto
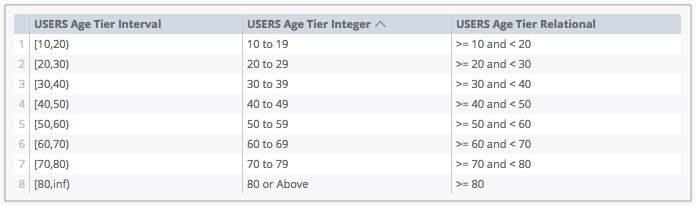
Aspectos que debes tener en cuenta
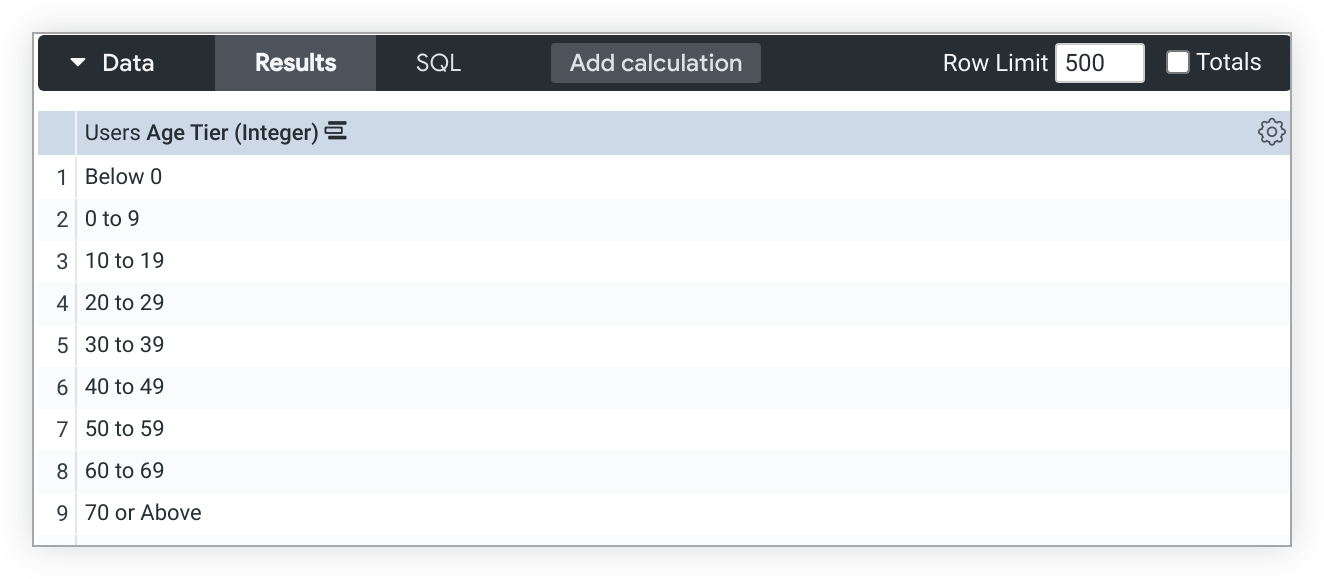
El uso de tier junto con el relleno de dimensiones puede generar buckets de niveles inesperados.
Por ejemplo, una dimensión type: tier, Nivel de edad, mostrará buckets de nivel para Menos de 0 y De 0 a 9 cuando se habilite el relleno de dimensiones, aunque los datos no incluyan valores de edad para esos buckets:
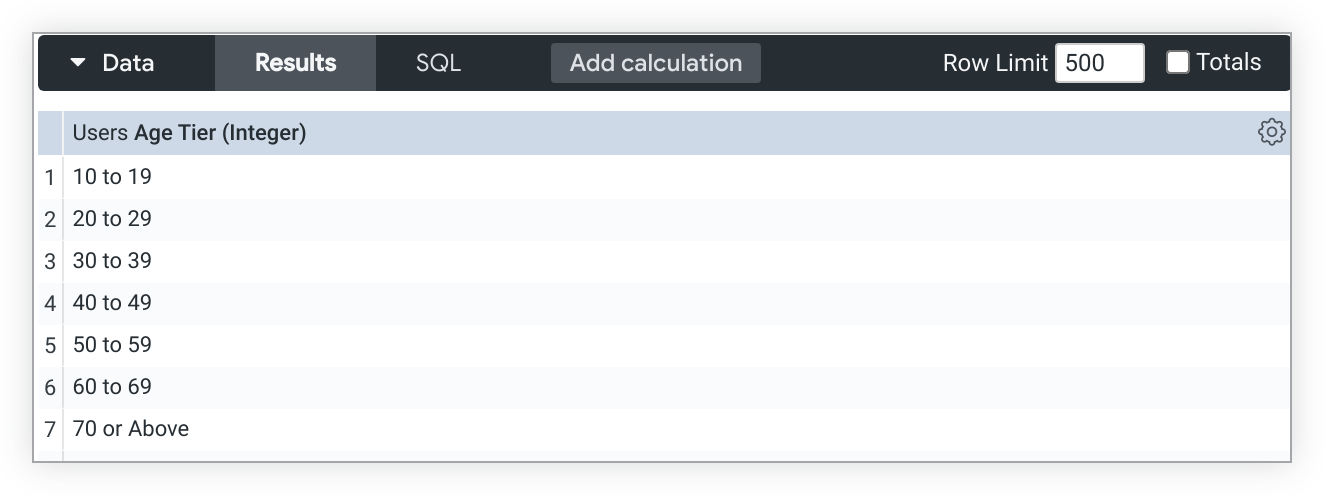
Cuando se inhabilita el relleno de dimensiones para Nivel de edad, los intervalos reflejan con mayor precisión los valores de edad disponibles en los datos, comenzando con el intervalo De 10 a 19:
Para habilitar o inhabilitar el relleno de dimensiones, coloca el cursor sobre el nombre de la dimensión en Explorar, haz clic en el ícono de ajustes a nivel del campo y selecciona Quitar valores de nivel completados para inhabilitar la opción o Completar valores de nivel faltantes para habilitarla.
Obtén más información sobre tiers de Looker en la página de documentación Dimensiones, filtros y tipos de parámetros.
Usa case para el agrupamiento
Puedes usar el parámetro case para crear buckets con nombres personalizados y ordenamiento personalizado. Se recomienda el parámetro case para un conjunto fijo de buckets, ya que puede ayudar a controlar la forma en que se presentan, ordenan y usan los valores en los filtros y las visualizaciones de la IU. Por ejemplo, con case, un usuario podrá seleccionar solo los valores de bucket definidos en un filtro.
Para crear buckets con case, puedes definir una dimensión, como un bucket para los importes de los pedidos:
dimension: order_amount_bucket {
case: {
when: {
sql: ${order_amount} <= 50;;
label: "Small"
}
when: {
sql: ${order_amount} > 50 AND ${order_amount} <= 150;;
label: "Medium"
}
when: {
sql: ${order_amount} > 150;;
label: "Large"
}
else:"Unknown"
}
}
Por lo general, el parámetro case ordenará los valores en el orden en que se enumeran los buckets. Para la dimensión order_amount_bucket, el orden de los buckets es Pequeño, Mediano y Grande:

Si deseas ordenar de forma alfanumérica, agrega el parámetro alpha_sort a la dimensión de la siguiente manera:
dimension: order_amount_bucket {
alpha_sort: yes
case: {
when: {
sql: ${order_amount} <= 50;;
label: "Small"
}
when: {
sql: ${order_amount} > 50 AND ${order_amount} <= 150;;
label: "Medium"
}
when: {
sql: ${order_amount} > 150;;
label: "Large"
}
else:"Unknown"
}
}
Para las dimensiones en las que se desean muchos valores distintos en el resultado (esto requeriría que definas cada resultado con una sentencia WHEN o ELSE), o cuando quieras implementar una sentencia ELSE más compleja, te recomendamos que uses una CASE WHEN de SQL, que se analiza en la siguiente sección.
Obtén más información sobre el parámetro case en la página de documentación Parámetros de campo.
Usa SQL CASE WHEN para el agrupamiento
Se recomienda una sentencia CASE WHEN de SQL para un agrupamiento más complejo o para la implementación de una sentencia ELSE más matizada.
Por ejemplo, es posible que desees usar diferentes métodos de agrupación, según el destino de un pedido. Se puede usar una sentencia CASE WHEN de SQL para crear una dimensión de bucket compuesto, en la que la sentencia THEN muestra dimensiones en lugar de cadenas:
dimension: compound_buckets {
sql:
CASE
WHEN ${orders.destination} = 'US' THEN ${us_buckets}
WHEN ${orders.destination} = 'CA' THEN ${canada_buckets}
ELSE ${intl_buckets}
END ;;
}