Questa pagina esplora i pattern di architettura più comuni per un deployment ospitato dal cliente e descrive le best practice per implementarli. Per utilizzare questa pagina in modo efficace, devi avere familiarità con i concetti e le pratiche di architettura di sistema.
Strategia del workflow
Dopo aver identificato l'hosting autonomo come opzione valida per l'implementazione di Looker, il passaggio successivo consiste nell'elaborare la strategia da utilizzare per il deployment.
- Esegui una valutazione. Identifica un elenco di candidati di workflow pianificati ed esistenti.
- Elenca i pattern di architettura applicabili. A partire dai workflow candidati identificati, identifica i pattern architetturali applicabili.
- Dai la priorità e seleziona il pattern di architettura ottimale. Allinea il pattern di architettura alle attività e ai risultati più importanti.
- Configura i componenti dell'architettura ed esegui il deployment dell'applicazione Looker. Implementa l'host, le dipendenze di terze parti e la topologia di rete necessari per stabilire connessioni client sicure.
Opzioni di architettura
Macchina virtuale dedicata
Un'opzione è eseguire Looker come singola istanza in una macchina virtuale (VM) dedicata. Una singola istanza può gestire workload impegnativi scalando verticalmente l'host e aumentando i pool di thread predefiniti. Tuttavia, l'overhead di elaborazione della gestione di un heap Java di grandi dimensioni sottopone lo scaling verticale alla legge dei rendimenti decrescenti. È generalmente accettabile per carichi di lavoro di piccole e medie dimensioni. Il seguente diagramma mostra le configurazioni predefinite e facoltative tra un'istanza di Looker in esecuzione in una VM dedicata, i repository locali e remoti, i server SMTP e le origini dati evidenziate nelle sezioni Vantaggi e Best practice per questa opzione.
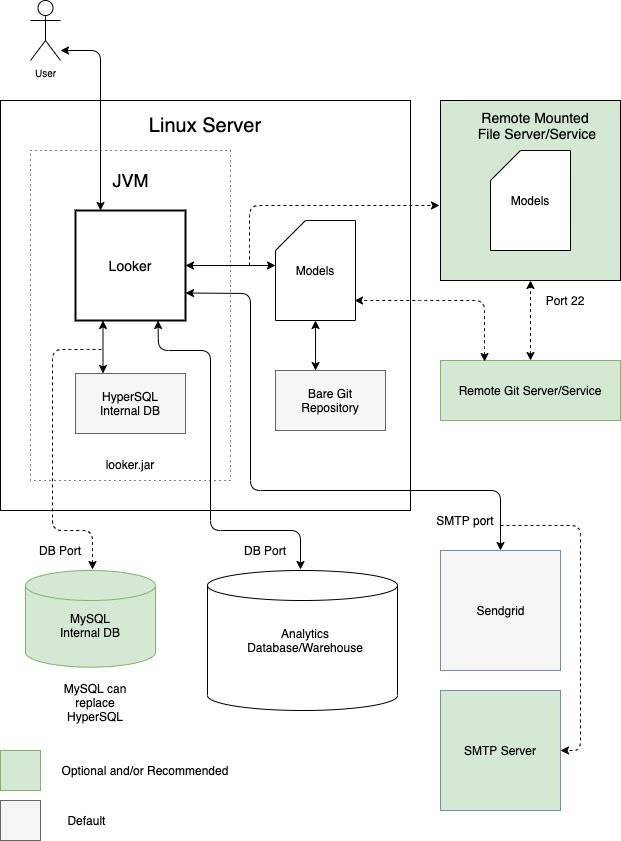
Vantaggi
- Una VM dedicata è facile da implementare e gestire.
- Il database interno è ospitato all'interno dell'applicazione Looker.
- I componenti dei modelli Looker, del repository Git, del server SMTP e del database di backend possono essere configurati localmente o da remoto.
- Puoi sostituire il server SMTP predefinito di Looker con il tuo per le notifiche email e le attività pianificate.
Best practice
- Per impostazione predefinita, Looker può generare repository Git vuoti per un progetto. Ti consigliamo di configurare un repository Git remoto per la ridondanza.
-
Per impostazione predefinita, Looker viene avviato con un database HyperSQL in memoria. Questo database è pratico e leggero, ma può riscontrare problemi di prestazioni in caso di utilizzo intenso. Per le implementazioni più grandi, consigliamo l'utilizzo di un database MySQL. Consigliamo la migrazione a un database MySQL remoto una volta che il file
~/looker/.db/looker.scriptraggiunge i 600 MB. - Il deployment di Looker dovrà essere convalidato rispetto al servizio di gestione delle licenze di Looker; è necessario il traffico in uscita sulla porta 443.
- Un deployment di VM dedicato può essere scalato verticalmente aumentando le risorse disponibili e i pool di thread di Looker. Tuttavia, l'aumento della RAM è soggetto alla legge dei rendimenti decrescenti una volta raggiunti i 64 GB, poiché gli eventi di Garbage Collection sono a thread singolo e interrompono tutti gli altri thread per l'esecuzione. I nodi con 16 CPU e 64 GB di RAM offrono un buon equilibrio tra prezzo e prestazioni.
- Ti consigliamo di utilizzare un deployment con spazio di archiviazione con 2 operazioni al secondo (IOPS) per GB.
Cluster di VM
L'esecuzione di Looker come cluster di istanze su più VM è un pattern flessibile che beneficia del failover e della ridondanza del servizio. La scalabilità orizzontale consente di aumentare il throughput senza incorrere in un aumento eccessivo dell'heap e in costi eccessivi di garbage collection. I nodi hanno la possibilità di dedicare il carico di lavoro, il che consente di adattare più opzioni di deployment a diversi requisiti aziendali. I deployment dei cluster richiedono almeno un amministratore di sistema che abbia familiarità con i sistemi Linux e sia in grado di gestire le parti componenti.
Cluster Standard
Per la maggior parte dei deployment standard, è sufficiente un cluster di nodi di servizio identici. Tutti i nodi del cluster sono configurati allo stesso modo e si trovano tutti nello stesso pool del bilanciatore del carico. Nessuno dei nodi in questa configurazione avrebbe più o meno probabilità di gestire richieste degli utenti Looker, un'attività di rendering, un'attività pianificata, una richiesta API e così via.
Questo tipo di configurazione è adatto quando la maggior parte delle richieste proviene direttamente da un utente Looker che esegue query e interagisce con Looker. Inizia a interrompersi quando un numero elevato di richieste proviene da uno scheduler, un renderer o un'altra origine. In questo caso, è utile designare determinati nodi di servizio per gestire attività come pianificazioni e rendering.
Ad esempio, gli utenti pianificano spesso l'esecuzione delle consegne di dati il lunedì mattina. Un utente che tenta di eseguire query Looker lunedì mattina potrebbe riscontrare problemi di prestazioni mentre Looker elabora il backlog di richieste pianificate. Aumentando il numero di nodi di servizio, il cluster fornisce un aumento proporzionale del throughput in tutte le funzionalità di Looker.
Il seguente diagramma mostra come le richieste a Looker effettuate da utenti, app e script vengono bilanciate in un'istanza di Looker in cluster.
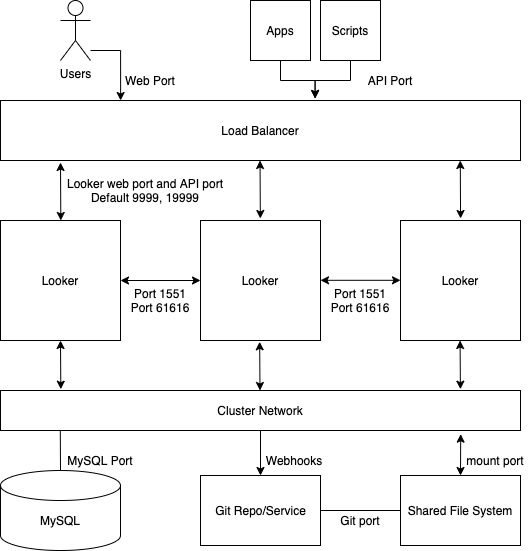
Vantaggi
- Un cluster standard massimizza il throughput generale con una configurazione minima della topologia del cluster.
- La VM Java subisce un degrado delle prestazioni alla soglia di memoria allocata di 64 GB, motivo per cui lo scaling orizzontale ha rendimenti maggiori rispetto allo scaling verticale.
- Una configurazione del cluster garantisce la ridondanza e il failover del servizio.
Best practice
- Ogni nodo Looker deve essere ospitato nella propria VM dedicata.
- Il bilanciatore del carico, che è il punto di ingresso del cluster, deve essere un bilanciatore del carico di livello 4. Deve avere un timeout lungo (3600 secondi), essere dotato di un certificato SSL firmato e configurato per l'inoltro delle porte da 443 (https) a 9999 (porta su cui è in ascolto il server Looker).
- Ti consigliamo di utilizzare un deployment con spazio di archiviazione con 2 IOPS per GB.
Sviluppo/Staging/Produzione
Per i casi d'uso che danno la priorità al massimo tempo di attività dei contenuti per gli utenti finali, consigliamo ambienti Looker separati per compartimentare il lavoro di sviluppo e quello analitico. Limitando le modifiche all'ambiente di produzione dietro ambienti di sviluppo e test isolati, questa architettura mantiene un ambiente di produzione il più stabile possibile.
Questi vantaggi richiedono la configurazione degli ambienti interconnessi e l'adozione di un ciclo di rilascio solido. Un deployment Dev/Staging/Prod richiede anche un team di sviluppatori che conoscono l'API Looker e Git per l'amministrazione del flusso di lavoro.
Il seguente diagramma mostra il flusso di contenuti tra gli sviluppatori LookML che sviluppano contenuti nell'istanza di sviluppo, i tester del controllo qualità che testano i contenuti nell'istanza QA e gli utenti, le app e gli script che utilizzano i contenuti nell'istanza di produzione.
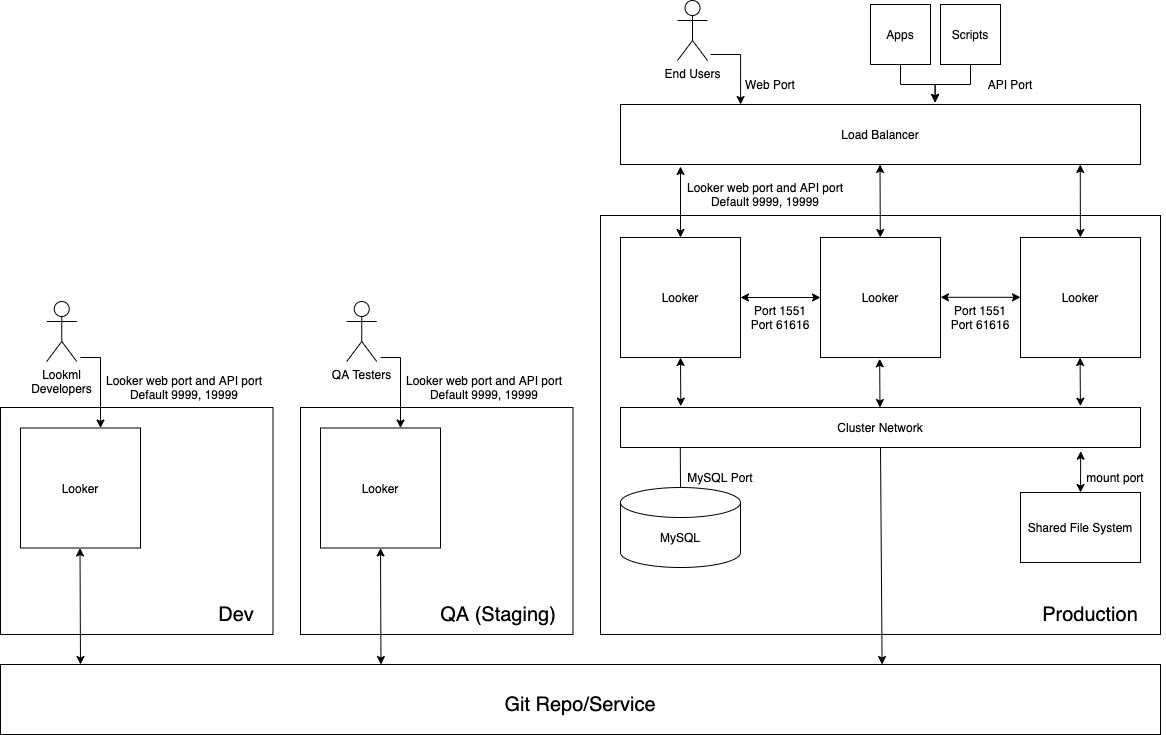
Vantaggi
- La convalida di LookML e dei contenuti avviene in un ambiente non di produzione, garantendo che qualsiasi modifica alla logica del modello possa essere esaminata a fondo prima di raggiungere gli utenti di produzione.
- Le funzionalità a livello di istanza, come le funzionalità di Labs o i protocolli di autenticazione, possono essere testate in isolamento prima di essere attivate nell'ambiente di produzione.
- I gruppi di dati e i criteri di memorizzazione nella cache possono essere testati in un ambiente non di produzione.
- Il test della modalità di produzione di Looker è separato dagli ambienti di produzione responsabili della gestione degli utenti finali.
- Le release di Looker possono essere testate in un ambiente non di produzione, il che offre tutto il tempo necessario per testare nuove funzionalità, modifiche del flusso di lavoro e problemi prima di aggiornare l'ambiente di produzione.
Best practice
- Isola le varie attività che si verificano contemporaneamente in almeno tre istanze separate:
- Istanza di sviluppo: gli sviluppatori utilizzano l'ambiente di sviluppo per eseguire il commit del codice, condurre esperimenti, correggere bug e commettere errori in sicurezza.
- Istanza QA: nota anche come ambiente di test o di gestione temporanea, è l'ambiente in cui gli sviluppatori eseguono test manuali e automatizzati. L'ambiente QA è complesso e può consumare molte risorse.
- Istanza di produzione: è qui che viene creato valore per i clienti e/o l'attività. La produzione è un ambiente molto visibile e deve essere privo di errori.
- Mantieni un workflow del ciclo di rilascio documentato e ripetibile.
- Se è necessario servire volumi elevati di sviluppatori e tester QA, le istanze di sviluppo e/o QA possono essere raggruppate. Che vengano lasciate come VM autonome o come cluster di VM, le istanze di sviluppo e controllo qualità sono soggette alle stesse considerazioni architetturali mostrate in precedenza nelle rispettive sezioni.
Throughput di pianificazione elevato
Per i casi d'uso che richiedono un'elevata velocità effettiva di distribuzione dei dati pianificata e consegne tempestive e affidabili, consigliamo che la configurazione includa un cluster con un pool di nodi dedicati esclusivamente alla pianificazione. Questa configurazione contribuirà a mantenere il web e le applicazioni incorporate veloci e reattivi. Questi vantaggi richiedono la configurazione di nodi con opzioni di avvio personalizzate e regole di bilanciamento del carico appropriate, come illustrato nel seguente diagramma e descritto nelle sezioni Vantaggi e Best practice per questa opzione.
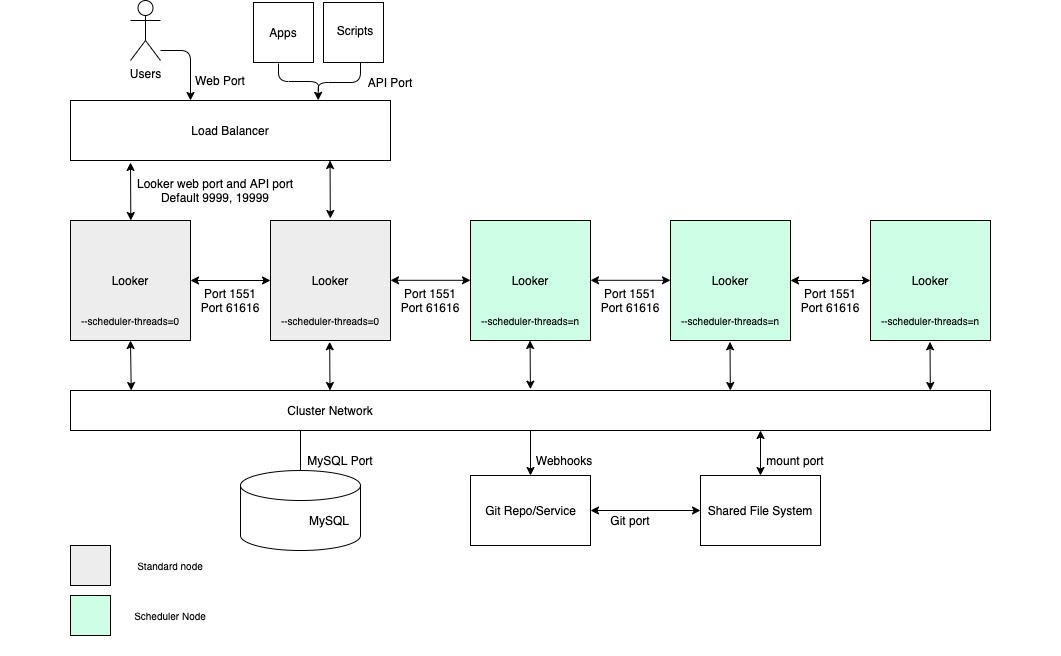
Vantaggi
- L'assegnazione di nodi a una funzione specifica suddivide le risorse per la pianificazione dalle funzioni di sviluppo e di analisi ad hoc.
- Gli utenti possono sviluppare LookML ed esplorare i contenuti senza utilizzare cicli dai nodi responsabili della gestione delle consegne programmate dei dati.
- Il traffico elevato degli utenti incanalato verso i nodi regolari non ostacola i workload pianificati gestiti dai nodi di pianificazione.
Best practice
- Ogni nodo Looker deve essere ospitato nella propria VM dedicata.
- Il bilanciatore del carico, che è il punto di ingresso del cluster, deve essere un bilanciatore del carico di livello 4. Deve avere un timeout lungo (3600 secondi), essere dotato di un certificato SSL firmato e configurato per l'inoltro delle porte da 443 (https) a 9999 (porta su cui è in ascolto il server Looker).
- Ometti i nodi dello scheduler dalle regole di bilanciamento del carico in modo che non gestiscano il traffico degli utenti finali e le richieste API interne.
- Ti consigliamo di utilizzare un deployment con spazio di archiviazione con 2 IOPS per GB.
Throughput di rendering elevato
Per i casi d'uso che richiedono un'elevata velocità effettiva di rendering dei report, ti consigliamo di configurare un cluster con un pool di nodi dedicati esclusivamente al rendering. Il rendering di un file PDF o di un'immagine PNG/JPEG è un'operazione relativamente costosa in termini di risorse in Looker. Il rendering può richiedere molta memoria e CPU e, quando Linux è sotto pressione della memoria, potrebbe interrompere un processo in esecuzione. Poiché l'utilizzo della memoria di un job di rendering non può essere determinato in anticipo, l'avvio di un job di rendering potrebbe comportare l'interruzione del processo Looker. La configurazione di nodi di rendering dedicati consente di ottimizzare la messa a punto dei job di rendering, preservando al contempo la reattività dell'applicazione interattiva e incorporata.
Questi vantaggi richiedono la configurazione di nodi con opzioni di avvio personalizzate e regole di bilanciamento del carico appropriate, come illustrato nel seguente diagramma e spiegato nelle sezioni Vantaggi e Best practice per questa opzione. Inoltre, i nodi di rendering potrebbero richiedere più risorse host rispetto ai nodi standard, poiché il servizio di rendering di Looker dipende da processi Chromium di terze parti che condividono tempo CPU e memoria.
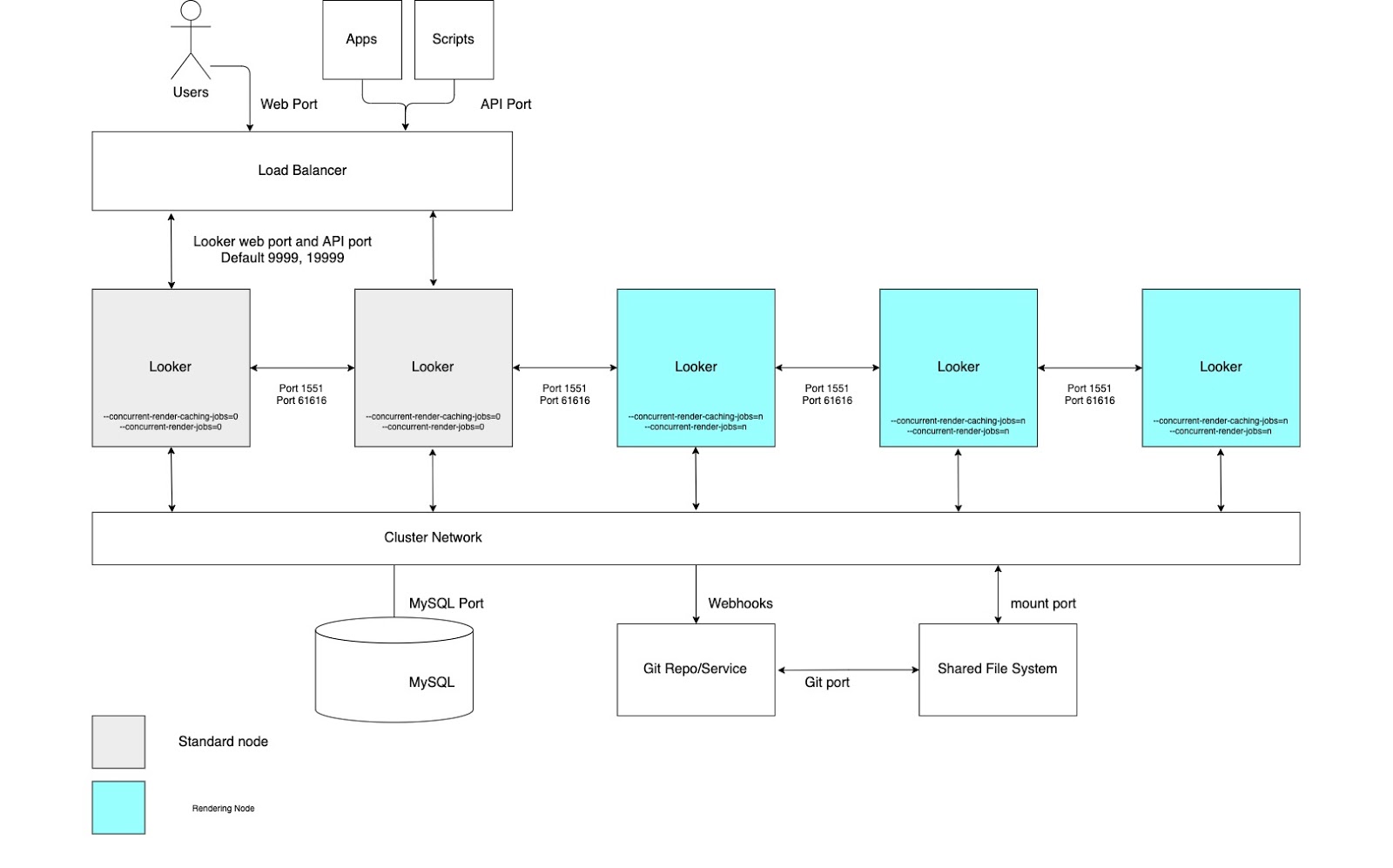
Vantaggi
- L'assegnazione di nodi a una funzione specifica suddivide le risorse per il rendering dalle funzioni di sviluppo e di analisi ad hoc.
- Gli utenti possono sviluppare LookML ed esplorare i contenuti senza utilizzare cicli dai nodi responsabili del rendering di PNG e PDF.
- L'elevato traffico degli utenti incanalato verso i nodi regolari non ostacola i carichi di lavoro di rendering gestiti dai nodi di rendering.
Best practice
- Ogni nodo Looker deve essere ospitato nella propria VM dedicata.
- Il bilanciatore del carico, che è il punto di ingresso del cluster, deve essere un bilanciatore del carico di livello 4. Deve avere un timeout lungo (3600 secondi), essere dotato di un certificato SSL firmato e configurato per l'inoltro delle porte da 443 (https) a 9999 (porta su cui è in ascolto il server Looker).
- Ometti i nodi di rendering dalle regole di bilanciamento del carico, in modo che non gestiscano il traffico degli utenti finali e le richieste API interne.
- Assegna una quantità di memoria relativamente inferiore a Java nei nodi di rendering per fornire ai processi di Chromium un buffer di memoria più grande. Invece di allocare il 60% della memoria a Java, alloca il 40-50%.
- Il rischio di pressione sulla memoria è stato ridotto sui nodi non di rendering, quindi la quantità di memoria dedicata a Looker può essere aumentata. Anziché il 60% predefinito, valuta la possibilità di utilizzare un numero più alto, ad esempio 80%.
- Ti consigliamo di utilizzare un deployment con spazio di archiviazione con 2 IOPS per GB.