Managed disaster recovery
This document provides an overview of BigQuery managed disaster recovery and how to implement it for your data and workloads.
Overview
BigQuery supports disaster recovery scenarios in the case of a total region outage. BigQuery disaster recovery relies on cross-region dataset replication to manage storage failover. After creating a dataset replica in a secondary region, you can control failover behavior for compute and storage to maintain business continuity during an outage. After a failover, you can access compute capacity (slots) and replicated datasets in the promoted region. Disaster recovery is only supported with the Enterprise Plus edition.
Managed disaster recovery offers two failover options: hard failover and
soft failover. A hard failover immediately promotes the secondary region's
reservation and dataset replicas to become the primary. This action proceeds
even if the current primary region is offline and does not wait for the
replication of any unreplicated data. Because of this, data loss can occur
during hard failover.
Any jobs that committed data in the source region before the replica's value of
replication_time
may need to be rerun in the destination region after failover.
In contrast to a hard failover, a soft failover waits until all reservation
and dataset changes committed in the primary region are replicated to the
secondary region before completing the failover process. A soft failover
requires both the primary and secondary region to be available.
Initiating a soft failover sets the softFailoverStartTime
for the reservation. The softFailoverStartTime
is cleared on soft failover completion.
To enable disaster recovery, you are required to create an Enterprise Plus edition reservation in the primary region, which is the region the dataset is in before failover. Standby compute capacity in the paired region is included in the Enterprise Plus reservation. You then attach a dataset to this reservation to enable failover for that dataset. You can only attach a dataset to a reservation if the dataset is backfilled and has the same paired primary and secondary locations as the reservation. After a dataset is attached to a failover reservation, only Enterprise Plus reservations can write to those datasets and you can't perform a cross-region replication promotion on the dataset. You can read from datasets attached to a failover reservation with any capacity model. For more information about reservations, see Introduction to workload management.
The compute capacity of your primary region is available in the secondary region promptly after a failover. This availability applies to your reservation baseline, whether it is used or not.
You must actively choose to fail over as part of testing or in response to a real disaster. You shouldn't fail over more than once in a 10-minute window. In data replication scenarios, backfill refers to the process of populating a replica of a dataset with historical data that existed before the replica was created or became active. Datasets must complete their backfill before you can fail over to the dataset.
The following diagram shows the architecture of managed disaster recovery:
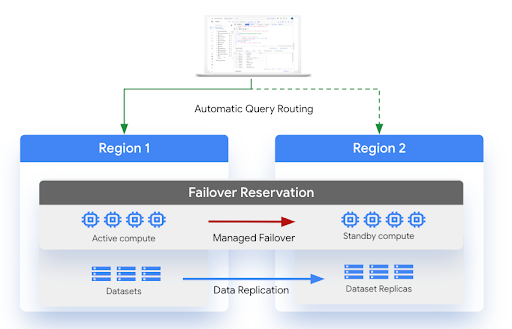
Limitations
The following limitations apply to BigQuery disaster recovery:
BigQuery disaster recovery is subject to the same limitations as cross-region dataset replication.
Autoscaling after a failover depends on compute capacity availability in the secondary region. Only the reservation baseline is available in the secondary region.
The
INFORMATION_SCHEMA.RESERVATIONSview doesn't have failover details.If you have multiple failover reservations with the same administration project but whose attached datasets use different secondary locations, don't use one failover reservation with the datasets attached to a different failover reservation.
If you want to convert an existing reservation to a failover reservation, the existing reservation can't have more than 1,000 reservation assignments.
A failover reservation can't have more than 1,000 datasets attached to it.
Soft failover can only be triggered if both the source and destination regions are available.
Soft failover cannot be triggered if there are any errors transient or otherwise during reservation replication. For example, if there is insufficient slots quota in the secondary region for the reservation update.
The reservation and attached datasets cannot be updated during an active soft failover but they can still be read from.
Jobs running on a failover reservation during an active soft failover may not run on the reservation due to transient changes in the dataset and reservation routing during the failover operation. However these jobs will use the reservation slots before any soft failover is initiated and after it completes.
Locations
The following regions are available when creating a failover reservation:
| Location code | Region Name | Region Description |
|---|---|---|
ASIA |
||
ASIA-EAST1 |
Taiwan | |
ASIA-SOUTHEAST1 |
Singapore | |
AU |
||
AUSTRALIA-SOUTHEAST1 |
Sydney | |
AUSTRALIA-SOUTHEAST2 |
Melbourne | |
CA |
||
NORTHAMERICA-NORTHEAST1 |
Montréal | |
NORTHAMERICA-NORTHEAST2 |
Toronto | |
DE |
||
EUROPE-WEST3 |
Frankfurt | |
EUROPE-WEST10 |
Berlin | |
EU |
||
EU |
EU multi-region | |
EUROPE-CENTRAL2 |
Warsaw | |
EUROPE-NORTH1 |
Finland | |
EUROPE-SOUTHWEST1 |
Madrid | |
EUROPE-WEST1 |
Belgium | |
EUROPE-WEST3 |
Frankfurt | |
EUROPE-WEST4 |
Netherlands | |
EUROPE-WEST8 |
Milan | |
EUROPE-WEST9 |
Paris | |
IN |
||
ASIA-SOUTH1 |
Mumbai | |
ASIA-SOUTH2 |
Delhi | |
US |
||
US |
US multi-region | |
US-CENTRAL1 |
Iowa | |
US-EAST1 |
South Carolina | |
US-EAST4 |
Northern Virginia | |
US-EAST5 |
Columbus | |
US-SOUTH1 |
Dallas | |
US-WEST1 |
Oregon | |
US-WEST2 |
Los Angeles | |
US-WEST3 |
Salt Lake City | |
US-WEST4 |
Las Vegas |
Region pairs must be selected within ASIA, AU, CA, DE, EU, IN or the
US. For example, a region within the US cannot be paired with a region within EU.
If your BigQuery dataset is in a multi-region location, you can't use the following region pairs. This limitation is required to make sure that your failover reservation and data are geographically separated after replication. For more information about regions that are contained within multi-regions, see Multi-regions.
us-central1-usmulti-regionus-west1-usmulti-regioneu-west1-eumulti-regioneu-west4-eumulti-region
Before you begin
- Verify that you have the
bigquery.reservations.updateIdentity and Access Management (IAM) permission to update reservations. - Verify that you have existing datasets that are configured for replication. For more information, see Replicate a dataset.
Turbo replication
Disaster recovery uses Turbo replication for faster data replication across regions, which reduces the risk of data loss exposure, minimize service downtime, and helps support uninterrupted service following a regional outage.
Turbo replication doesn't apply to the initial backfill operation. After the initial backfill operation is completed, turbo replication aims to replicate datasets to a single failover region pair with a secondary replica within 15 minutes, as long as the bandwidth quota isn't exceeded and there are no user errors.
Recovery time objective
A recovery time objective (RTO) is the target time allowed for recovery in BigQuery in the event of a disaster. For more information on RTO, see Basics of DR planning.Managed disaster recovery has a five minute RTO after you initiate a failover. Because of the RTO, capacity is available in the secondary region within five minutes of starting the failover process.
Recovery point objective
A recovery point objective (RPO) is the most recent point in time from which data must be able to be restored. For more information on RPO, see Basics of DR planning. Managed disaster recovery has a RPO that is defined per dataset. The RPO aims to keep the secondary replica within 15 minutes of the primary. To meet this RPO, you can't exceed the bandwidth quota and there can't be any user errors.
Quota
You must have your chosen compute capacity in the secondary region before configuring a failover reservation. If there is not available quota in the secondary region, you can't configure or update the reservation. For more information, see Quotas and limits.
Turbo replication bandwidth has quota. For more information, see Quotas and limits.
Pricing
Configuring managed disaster recovery requires the following pricing plans:
Compute capacity: You must purchase the Enterprise Plus edition.
Turbo replication: Disaster recovery relies on turbo replication during replication. You are charged based on physical bytes and on a per physical GiB replicated basis. For more information, see Data replication data transfer pricing for Turbo replication.
Storage: Storage bytes in the secondary region are billed at the same price as storage bytes in the primary region. For more information, see Storage pricing.
Customers are only required to pay for compute capacity in the primary region. Secondary compute capacity (based on the reservation baseline) is available in the secondary region at no additional cost. Idle slots can't use the secondary compute capacity unless the reservation has failed over.
If you need to perform stale reads in the secondary region, you must purchase additional compute capacity.
Create or alter an Enterprise Plus reservation
Before attaching a dataset to a reservation, you must create an Enterprise Plus reservation or alter an existing reservation and configure it for disaster recovery.
Create a reservation
Select one of the following:
Console
In the Google Cloud console, go to the BigQuery page.
In the navigation menu, click Capacity management, and then click Create reservation.
In the Reservation name field, enter a name for the reservation.
In the Location list, select the location.
In the Edition list, select the Enterprise Plus edition.
In the Max reservation size selector list, select the maximum reservation size.
Optional: In the Baseline slots field, enter the number of baseline slots for the reservation.
The number of available autoscaling slots is determined by subtracting the Baseline slots value from the Max reservation size value. For example, if you create a reservation with 100 baseline slots and a max reservation size of 400, your reservation has 300 autoscaling slots. For more information about baseline slots, see Using reservations with baseline and autoscaling slots.
In the Secondary location list, select the secondary location.
To disable idle slot sharing and use only the specified slot capacity, click the Ignore idle slots toggle.
To expand the Advanced settings section, click the expander arrow.
Optional: To set the target job concurrency, click the Override automatic target job concurrency toggle to on, and then enter a value for Target Job Concurrency. The breakdown of slots is displayed in the Cost estimate table. A summary of the reservation is displayed in the Capacity summary table.
Click Save.
The new reservation is visible in the Slot reservations tab.
SQL
To create a reservation, use the
CREATE RESERVATION data definition language (DDL) statement.
In the Google Cloud console, go to the BigQuery page.
In the query editor, enter the following statement:
CREATE RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` OPTIONS ( slot_capacity = NUMBER_OF_BASELINE_SLOTS, edition = ENTERPRISE_PLUS, secondary_location = SECONDARY_LOCATION);
Replace the following:
ADMIN_PROJECT_ID: the project ID of the administration project that owns the reservation resource.LOCATION: the location of the reservation. If you select a BigQuery Omni location, your edition option is limited to the Enterprise edition.RESERVATION_NAME: the name of the reservation.The name must start and end with a lowercase letter or a number and contain only lowercase letters, numbers, and dashes.
NUMBER_OF_BASELINE_SLOTS: the number of baseline slots to allocate to the reservation. You cannot set theslot_capacityoption and theeditionoption in the same reservation.SECONDARY_LOCATION: the secondary location of the reservation. In the case of an outage, any datasets attached to this reservation will fail over to this location.
Click Run.
For more information about how to run queries, see Run an interactive query.
Alter an existing reservation
Select one of the following:
Console
In the Google Cloud console, go to the BigQuery page.
In the navigation menu, click Capacity management.
Click the Slot reservations tab.
Find the reservation that you want to update.
Click Reservations actions, and then click Edit.
In the Secondary location field, enter the secondary location.
Click Save.
SQL
To add or change a secondary location to a reservation, use the
ALTER RESERVATION SET OPTIONS DDL statement.
In the Google Cloud console, go to the BigQuery page.
In the query editor, enter the following statement:
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( secondary_location = SECONDARY_LOCATION);
Replace the following:
ADMIN_PROJECT_ID: the project ID of the administration project that owns the reservation resource.LOCATION: the location of the reservation, for exampleeurope-west9.RESERVATION_NAME: the name of the reservation. The name must start and end with a lowercase letter or a number and contain only lowercase letters, numbers, and dashes.SECONDARY_LOCATION: the secondary location of the reservation. In the case of an outage, any datasets attached to this reservation will fail over to this location.
Click Run.
For more information about how to run queries, see Run an interactive query.
Attach a dataset to a reservation
To enable disaster recovery for the previously created reservation, complete the following steps. The dataset must already be configured for replication in the same primary and secondary regions as the reservation. For more information, see Cross-region dataset replication.
Console
In the Google Cloud console, go to the BigQuery page.
In the navigation menu, click Capacity management, and then click the Slot Reservations tab.
Click the reservation that you want to attach a dataset to.
Click the Disaster recovery tab.
Click Add failover dataset.
Enter the name of the dataset you want to associate with the reservation.
Click Add.
SQL
To attach a dataset to a reservation, use the
ALTER SCHEMA SET OPTIONS DDL statement.
In the Google Cloud console, go to the BigQuery page.
In the query editor, enter the following statement:
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = ADMIN_PROJECT_ID.RESERVATION_NAME);
Replace the following:
DATASET_NAME: the name of the dataset.ADMIN_PROJECT_ID.RESERVATION_NAME: the name of the reservation you want to associate the dataset to.
Click Run.
For more information about how to run queries, see Run an interactive query.
Detach a dataset from a reservation
To stop managing the failover behavior of a dataset through a reservation, detach the dataset from the reservation. This doesn't change the current primary replica for the dataset nor does it remove any existing dataset replicas. For more information about removing dataset replicas after detaching a dataset, see Remove dataset replica.
Console
In the Google Cloud console, go to the BigQuery page.
In the navigation menu, click Capacity management, and then click the Slot Reservations tab.
Click the reservation that you want to detach a dataset from.
Click the Disaster recovery tab.
Expand the Actions option for the primary replica of the dataset.
Click Remove.
SQL
To detach a dataset from a reservation, use the
ALTER SCHEMA SET OPTIONS DDL statement.
In the Google Cloud console, go to the BigQuery page.
In the query editor, enter the following statement:
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = NULL);
Replace the following:
DATASET_NAME: the name of the dataset.
Click Run.
For more information about how to run queries, see Run an interactive query.
Initiate a failover
In the event of a regional outage, you must manually failover your reservation to the location used by the replica. Failing over the reservation also includes any associated datasets. To manually fail over a reservation, do the following:
Console
In the Google Cloud console, go to the BigQuery page.
In the navigation menu, click Disaster recovery.
Click the name of the reservation that you want to fail over to.
Select either Hard failover mode (default) or Soft failover mode.
Click Failover.
SQL
To add or change a secondary location to a reservation, use the
ALTER RESERVATION SET OPTIONS DDL statement and set is_primary to TRUE.
In the Google Cloud console, go to the BigQuery page.
In the query editor, enter the following statement:
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( is_primary = TRUE, failover_mode=FAILOVER_MODE);
Replace the following:
ADMIN_PROJECT_ID: the project ID of the administration project that owns the reservation resource.LOCATION: the new primary location of the reservation, that is the current secondary location before the failover - for example,europe-west9.RESERVATION_NAME: the name of the reservation. The name must start and end with a lowercase letter or a number and contain only lowercase letters, numbers, and dashes.PRIMARY_STATUS: a boolean status that declares whether the reservation is the primary replica.FAILOVER_MODE: an optional parameter used to describe the failover mode. This can be set to eitherHARDorSOFT. If this parameter is not specified,HARDis used by default.
Click Run.
For more information about how to run queries, see Run an interactive query.
Monitoring
To determine the state of your replicas, query the
INFORMATION_SCHEMA.SCHEMATA_REPLICAS view. For example:
SELECT schema_name, replica_name, creation_complete, replica_primary_assigned, replica_primary_assignment_complete FROM `region-LOCATION`.INFORMATION_SCHEMA.SCHEMATA_REPLICAS WHERE schema_name="my_dataset"
The following query returns the jobs from the last seven days that would fail if their datasets were failover datasets:
WITH non_epe_reservations AS ( SELECT project_id, reservation_name FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.RESERVATIONS WHERE edition != 'ENTERPRISE_PLUS' ) SELECT * FROM ( SELECT job_id FROM ( SELECT job_id, reservation_id, ARRAY_CONCAT(referenced_tables, [destination_table]) AS all_referenced_tables, query FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.JOBS WHERE creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP() ) A, UNNEST(all_referenced_tables) AS referenced_table ) jobs LEFT OUTER JOIN non_epe_reservations ON ( jobs.reservation_id = CONCAT( non_epe_reservations.project_id, ':', 'LOCATION', '.', non_epe_reservations.reservation_name)) WHERE CONCAT(jobs.project_id, ':', jobs.dataset_id) IN UNNEST( [ 'PROJECT_ID:DATASET_ID', 'PROJECT_ID:DATASET_ID']);
Replace the following:
PROJECT_ID: the project ID.DATASET_ID: the dataset ID.LOCATION: the location.
What's next
Learn more about cross-region dataset replication.
Learn more about reliability.