Introduction to BigQuery data preparation
This document describes AI-augmented data preparation in BigQuery. Data preparations are BigQuery resources, which use Gemini in BigQuery to analyze your data and provide intelligent suggestions for cleaning, transforming, and enriching it. You can significantly reduce the time and effort required for manual data preparation tasks. Scheduling of data preparations is powered by Dataform.
Benefits
- You can reduce the time spent on data pipeline development with context-aware, Gemini-generated transformation suggestions.
- You can validate the generated results in a preview and receive data quality cleanup and enrichment suggestions with automated schema mapping.
- Dataform lets you use a continuous integration, continuous development (CI/CD) process, supporting cross-team collaboration for code reviews and source control.
Data preparation entry points
You can create and manage data preparations in the BigQuery Studio page (see Open the data preparation editor in BigQuery).
When you open a table in BigQuery data preparation, a BigQuery job runs using your credentials. The run creates sample rows from the chosen table and writes the results into a temporary table in the same project. Gemini uses the sample data and schema to generate data preparation suggestions shown in the data preparation editor.
Views in the data preparation editor
Data preparations appear as tabs on the BigQuery page. Each tab has a series of sub-tabs, or data preparation views, where you design and manage your data preparations.
Data view
When you create a new data preparation, a data preparation editor tab opens, displaying the data view, which contains a representative sample of the table. For existing data preparations, you can navigate to the data view by clicking a node in the graph view of your data preparation pipeline.
The data view lets you do the following:
- Interact with your data to form data preparation steps.
- Apply suggestions from Gemini.
- Improve the quality of the Gemini suggestions by entering example values in the cells.
Over each column in your table, a statistical profile (a histogram) shows the count for each column's top values in the preview rows.

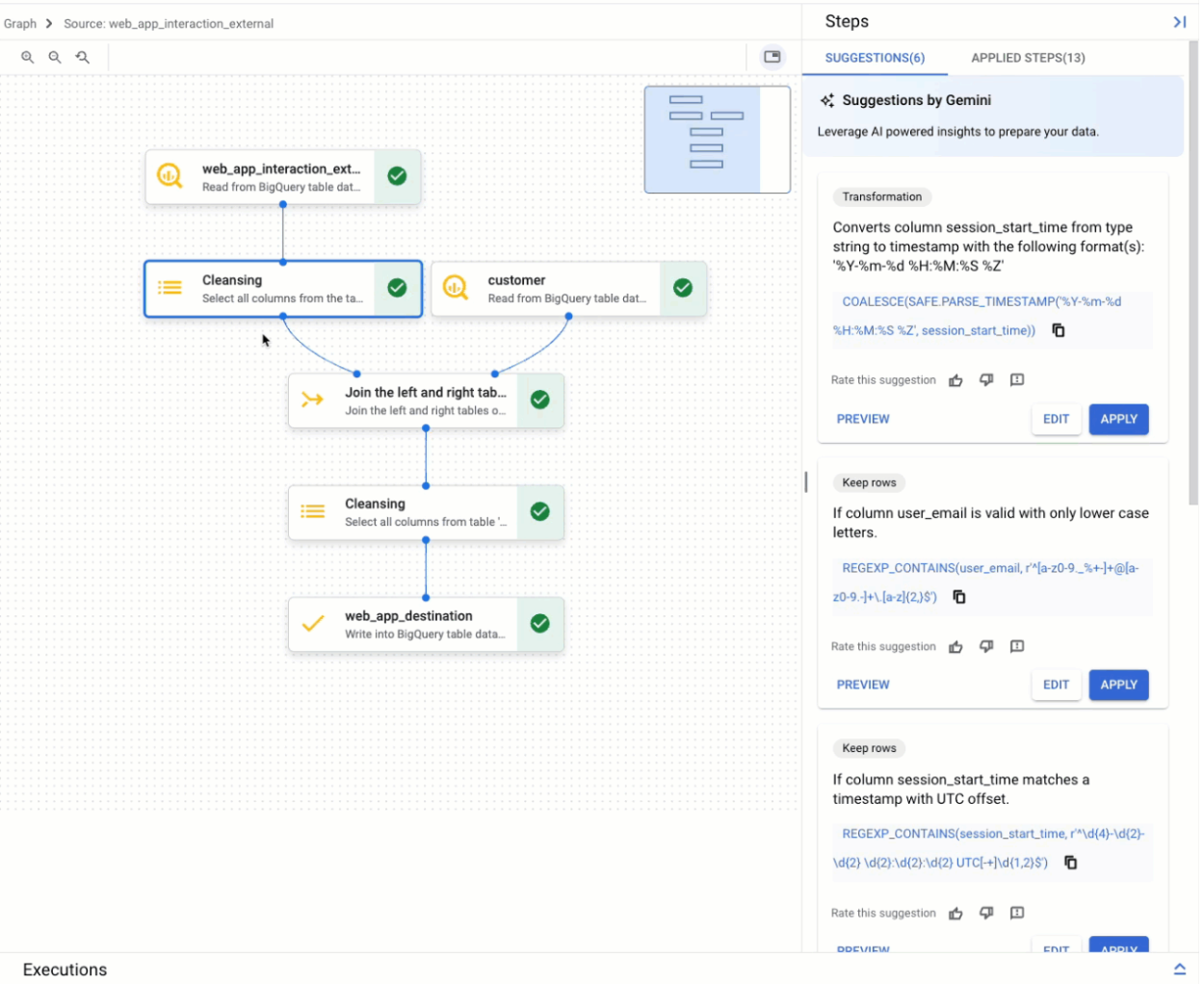
Graph view
The graph view is a visual overview of your data preparation. It appears as a tab on the BigQuery page in the console, when you open a data preparation. The graph displays nodes for all steps in your data preparation pipeline. You can select a node on the graph to configure the data preparation steps it represents.
Schema view
The data preparation schema view displays the current schema of the active data preparation step. The schema shown matches the columns in the data view.
In the schema view, you can perform dedicated schema operations, such as removing columns, which also creates steps in the Applied steps list.
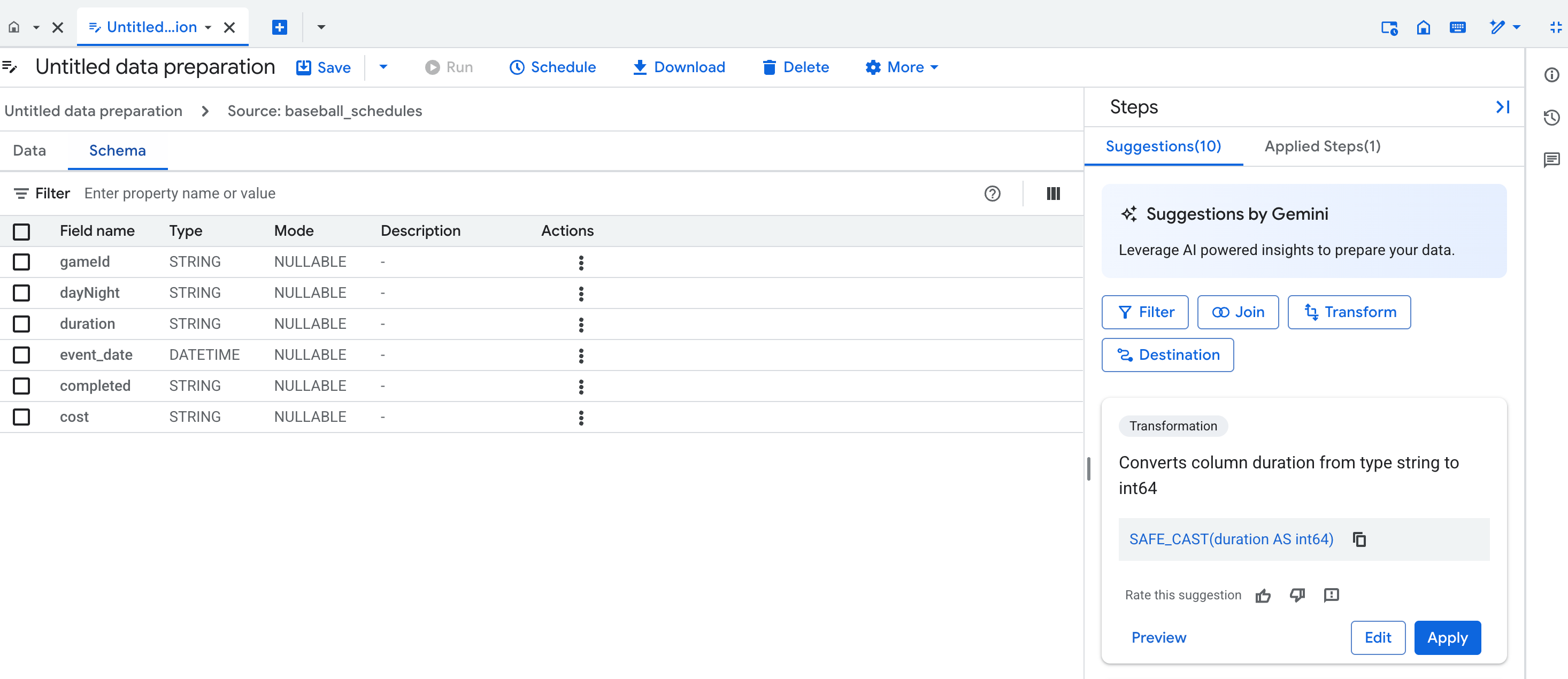
Suggestions by Gemini
Gemini provides context-aware suggestions to assist with the following data preparation tasks:
- Applying transformations and data quality rules
- Standardizing and enriching data
- Automating schema mapping
Each suggestion appears in a card in the suggestions list of the data preparation editor. The card contains the following information:
- The high-level category of the step, such as Keep rows or Transformation
- A description of the step, such as Keep rows if
COLUMN_NAMEis notNULL - The corresponding SQL expression used to execute the step
You can preview, edit, or apply the suggestion card, or fine-tune the suggestion. You can also add steps manually. For more information, see Prepare data with Gemini.
To fine-tune the suggestions from Gemini, give it an example of what to change in a column.
Data sampling
BigQuery uses data sampling to provide a preview of your data preparation. You can view the sample in the data view for each node.
When you add BigQuery standard tables as a source, the data is
prepared using a BigQuery
TABLESAMPLE function. This function creates a 10k-record
sample.
When you add a view or an external table as a source, the system reads the first 1 million records. From these records, the system selects a representative 10k-record sample.
Data in the sample isn't automatically refreshed. Sample tables are stored as cached query results and expire in approximately 24 hours. To manually refresh the sample table, see Refresh data preparation samples.
Write mode
To optimize costs and processing time, you can change the write mode settings to incrementally process new data from the source. For example, if you have a table in BigQuery where records are inserted daily, and a Looker dashboard that must reflect the changed data, you can schedule the BigQuery data preparation to incrementally read the new records from the source table and propagate them to the destination table.
To configure the way your data preparation is written into a destination table, see Optimize data preparation by incrementally processing data.
The following write modes are supported:
| Write mode option | Description |
|---|---|
| Full refresh | Performs the data preparation steps on all source data, and then rebuilds the destination table in full. The table is recreated, not truncated. Full refresh is the default mode when writing to a destination table. |
| Append | Inserts all the data from the data preparation as additional rows in the destination table. |
| Incremental | Inserts only the new or, depending on your incremental column choice, changed data in the destination table. Based on your incremental column choice, data preparation will select the optimal change record detection mechanism. It picks Maximum values for numeric and datetime data types and Unique for categorical data. Maximum inserts only records where the specified column value is greater than the max value for this same column in the destination table. Unique inserts only records where the specified column values aren't present in the existing values for the same column in the destination table. |
Supported data preparation steps
BigQuery supports the following types of data preparation steps:
| Step type | Description |
|---|---|
| Source | Adds a source when you select a BigQuery table to read from or when you add a join step. |
| Transformation | Cleans and transforms data using a SQL expression. You receive
suggestion cards for the following expressions:
You can also use any valid BigQuery SQL expressions in manual transformation steps. For example:
For more information, see Add a transformation. |
| Filter | Removes rows through the WHERE clause syntax. When you
add a filter step, you can choose to make it into a validation step.
For more information, see Filter rows. |
| Deduplicate (Preview) | Removes duplicate rows from the data based on selected keys and
ordering.
For more information, see Deduplicate data. |
| Validation | Sends rows that don't meet the validation rule criteria to an error
table. If data fails the validation rule and no error table is
configured, the data preparation fails during execution.
For more information, see Configure the error table and add a validation rule. |
| Join | Joins values from two sources. Tables must be in the same location.
Join key columns must be of the same data type. Data preparations
support the following join operations:
For more information, see Add a join operation. |
| Destination | Defines a destination for outputting data preparation steps. If you
enter a destination table that doesn't exist, the data preparation
creates a new table using the current schema information. For more information, see Add or change a destination table. |
| Delete columns | Deletes columns from the schema. You perform
this step from the schema view.
For more information, see Delete a column. |
Scheduling data preparation runs
To execute the data preparation steps and load the prepared data into the destination table, create a schedule. You can schedule data preparations from the data preparation editor, and manage them from the BigQuery Scheduling page. For more information, see Schedule data preparations.
Building pipelines with data preparation tasks
You can build BigQuery pipelines composed of data preparation, SQL query, and notebook tasks. You can then run these pipelines on a schedule. For more information, see Introduction to BigQuery pipelines.
Controlling access
Control access to data preparations using Identity and Access Management (IAM) roles, encryption with BigQuery and Dataform Cloud KMS keys, and VPC Service Controls.
IAM roles and permissions
Users who are preparing the data and the Dataform service accounts that are running the jobs require IAM permissions. For more information, see Required roles and Set up Gemini for BigQuery.
Encryption with Cloud KMS keys
Encrypt data at the dataset- or project-level by using the default customer-managed Cloud KMS keys in BigQuery. For more information, see Set a dataset default key and Set a project default key.
You can encrypt pipeline code at the project-level by default using a Dataform Cloud KMS key.
VPC Service Controls perimeters
If you use VPC Service Controls, you must configure the perimeter to protect Dataform and BigQuery. For more information, see the VPC Service Controls limitations for BigQuery and Dataform.
Limitations
Data preparation is available with the following limitations:
- All BigQuery data preparation source and destination datasets of a given data preparation must be in the same location. For more information, see Locations.
- During pipeline editing, data and interactions are sent to a Gemini data center for processing. For more information, see Locations.
- Gemini in BigQuery isn't supported by Assured Workloads.
- BigQuery data preparations don't support viewing, comparing, or restoring data preparation versions.
- Responses from Gemini are based on a sample of the dataset you provide when you design your data preparation pipeline. For more information, see how Gemini for Google Cloud uses your data and the terms in the Gemini for Google Cloud Trusted Tester Program.
- BigQuery data preparation doesn't have its own API. For necessary APIs, see Set up Gemini in BigQuery.
Locations
You can use data preparation in any supported BigQuery location. Your data processing jobs are executed and stored in the location of your source datasets. If a repository location is specified, then it must be the same as the source datasets location. The data preparation code storage region can be different from the job execution region.
All code assets in BigQuery Studio use the same default region. To set the default region for code assets, follow these steps:
Go to the BigQuery page.
In the Explorer pane, find the project in which you have enabled code assets.
Click View actions next to the project, and then click Change my default code region.
For Region, select the region that you want to use for code assets.
Click Select.
For a list of supported regions, see BigQuery Studio locations.
Gemini in BigQuery operates globally, so you can't restrict data processing of Gemini to a specific region when you design your data preparations, although BigQuery data processing in design and execution time is always performed in the location of your source datasets. To learn more about locations where Gemini in BigQuery processes data, see Gemini serving locations.
Pricing
Running data preparations and creating data preview samples use BigQuery resources, which are charged at the rates shown in BigQuery pricing.
Data preparation is included in the Gemini in BigQuery pricing. You can use BigQuery data preparation during Preview at no additional cost. For more information, see Set up Gemini in BigQuery.
Quotas
For more information, see quotas for Gemini in BigQuery.
What's next
- Learn how to prepare data with Gemini in BigQuery.
- Learn how to run data preparations manually or with a schedule.