Introduction to clustered tables
Clustered tables in BigQuery are tables that have a user-defined column sort order using clustered columns. Clustered tables can improve query performance and reduce query costs.
In BigQuery, a clustered column is a user-defined table property that sorts storage blocks based on the values in the clustered columns. The storage blocks are adaptively sized based on the size of the table. Colocation occurs at the level of the storage blocks, and not at the level of individual rows; for more information on colocation in this context, see Clustering.
A clustered table maintains the sort properties in the context of each operation that modifies it. Queries that filter or aggregate by the clustered columns only scan the relevant blocks based on the clustered columns, instead of the entire table or table partition. As a result, BigQuery might not be able to accurately estimate the bytes to be processed by the query or the query costs, but it attempts to reduce the total bytes at execution.
When you cluster a table using multiple columns, the column order determines
which columns take precedence when BigQuery sorts and groups the
data into storage blocks, as seen in the following example. Table 1 shows the
logical storage block layout of an unclustered table. In comparison, table 2 is
only clustered by the Country column, whereas table 3 is clustered by multiple
columns, Country and Status.
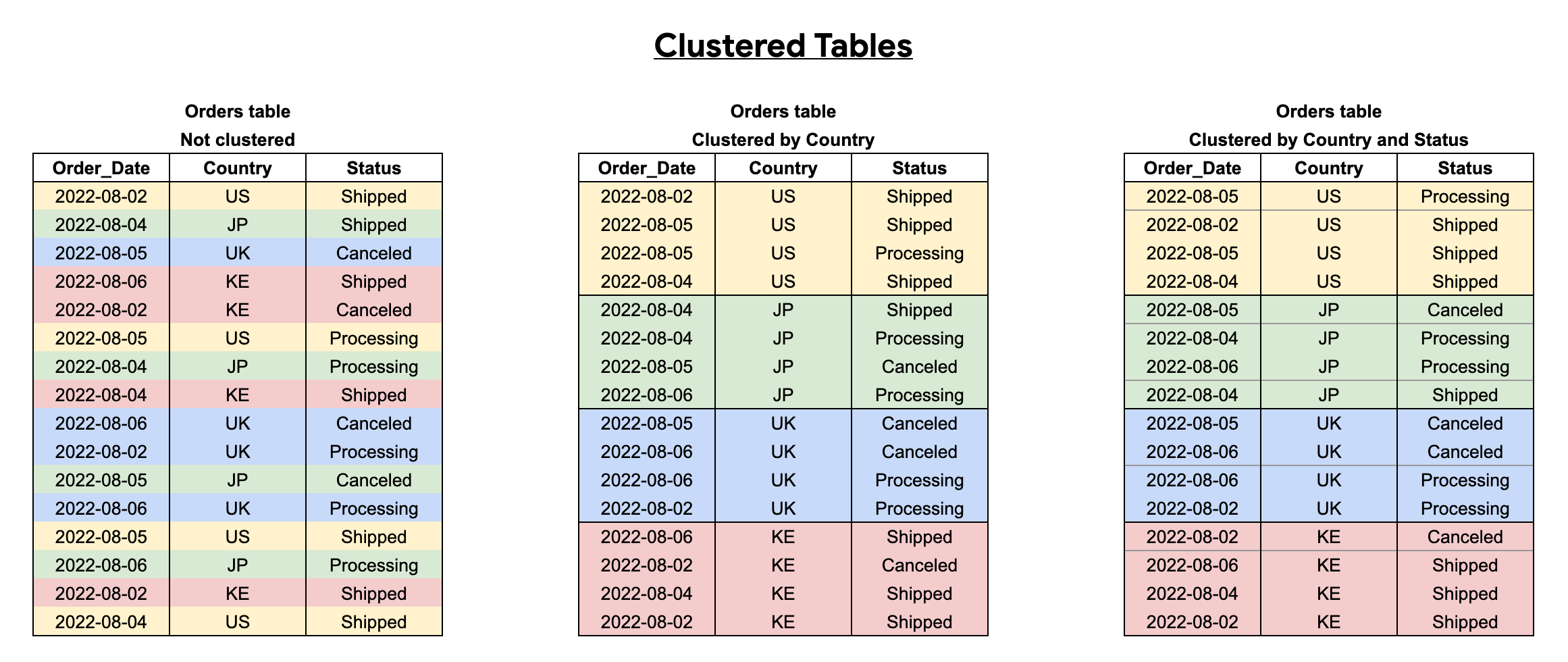
When you query a clustered table, you don't receive an accurate query cost estimate before query execution because the number of storage blocks to be scanned is not known before query execution. The final cost is determined after query execution is complete and is based on the specific storage blocks that were scanned.
When to use clustering
Clustering addresses how a table is stored so it's generally a good first option for improving query performance. You should therefore always consider clustering given the following advantages it provides:
- Unpartitioned tables larger than 64 MB are likely to benefit from clustering. Similarly, table partitions larger than 64 MB are also likely to benefit from clustering. Clustering smaller tables or partitions is possible, but the performance improvement is usually negligible.
- If your queries commonly filter on particular columns, clustering accelerates queries because the query only scans the blocks that match the filter.
- If your queries filter on columns that have many distinct values (high cardinality), clustering accelerates these queries by providing BigQuery with detailed metadata for where to get input data.
- Clustering enables your table's underlying storage blocks to be adaptively sized based on the size of the table.
You might consider partitioning your table in addition to clustering. In this approach, you first segment data into partitions, and then you cluster the data within each partition by the clustering columns. Consider this approach in the following circumstances:
- You need a strict query cost estimate before you run a query. The cost of queries over clustered tables can only be determined after the query is run. Partitioning provides granular query cost estimates before you run a query.
- Partitioning your table results in an average partition size of at least 10 GB per partition. Creating many small partitions increases the table's metadata, and can affect metadata access times when querying the table.
- You need to continually update your table but still want to take advantage of long-term storage pricing. Partitioning enables each partition to be considered separately for eligibility for long term pricing. If your table is not partitioned, then your entire table must not be edited for 90 consecutive days to be considered for long term pricing.
For more information, see Combine clustered and partitioned tables.
Cluster column types and ordering
This section describes column types and how column order works in table clustering.
Cluster column types
Cluster columns must be top-level, non-repeated columns that are one of the following types:
BIGNUMERICBOOLDATEDATETIMEGEOGRAPHYINT64NUMERICRANGESTRINGTIMESTAMP
For more information about data types, see GoogleSQL data types.
Cluster column ordering
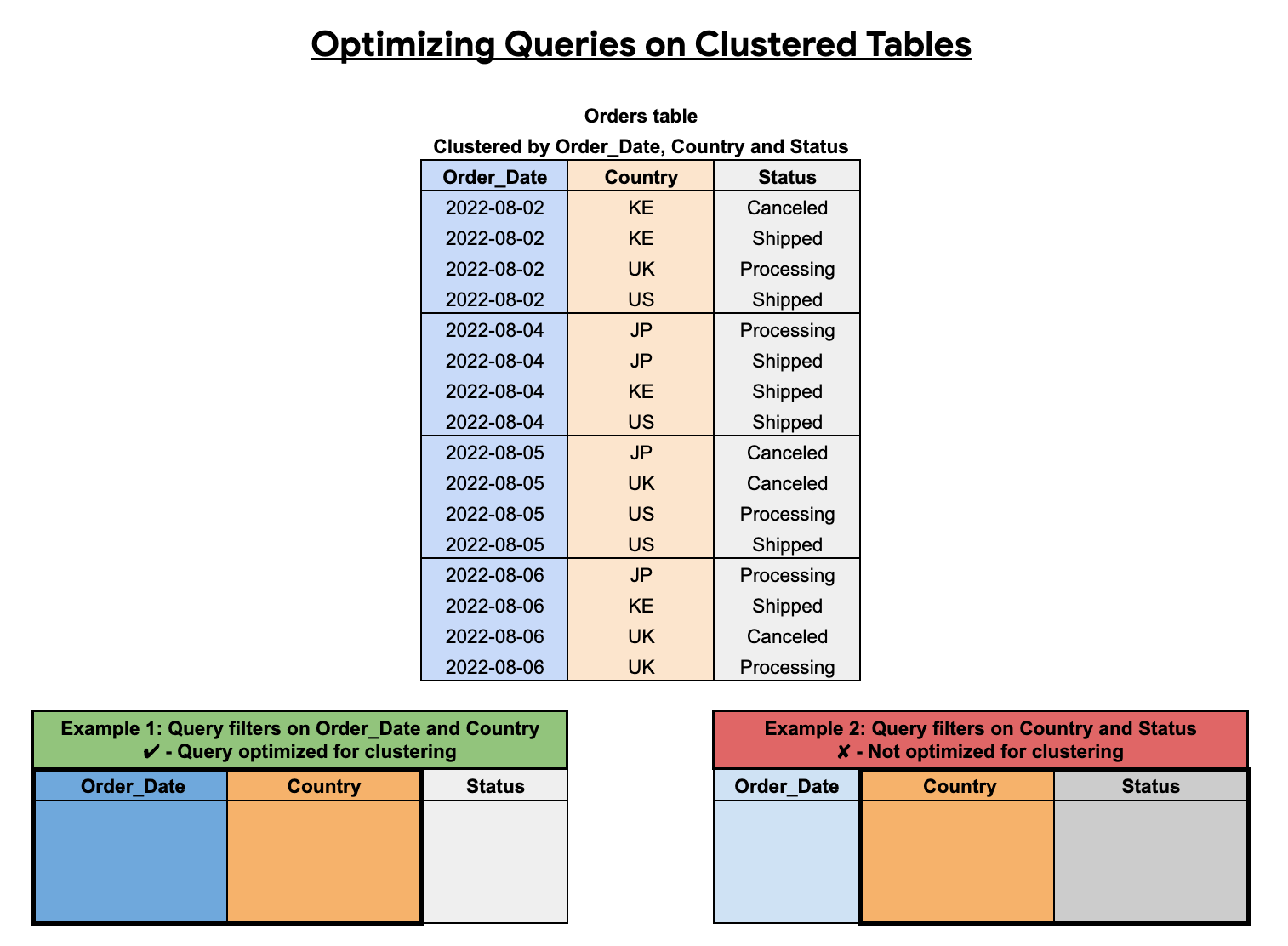
The order of clustered columns affects query performance. In the following example, the Orders table is clustered using a column sort
order of Order_Date, Country, and Status. The first clustered column in
this example is Order_Date, so a query that filters on Order_Date and
Country is optimized for clustering, whereas a query that filters on only
Country and Status is not optimized.
Block pruning
Clustered tables can help you to reduce query costs by pruning data so it's not processed by the query. This process is called block pruning. BigQuery sorts the data in a clustered table based on the values in the clustering columns and organizes them into blocks.
When you run a query against a clustered table, and the query includes a filter on the clustered columns, BigQuery uses the filter expression and the block metadata to prune the blocks scanned by the query. This allows BigQuery to scan only the relevant blocks.
When a block is pruned, it is not scanned. Only the scanned blocks are used to calculate the bytes of data processed by the query. The number of bytes processed by a query against a clustered table equals the sum of the bytes read in each column referenced by the query in the scanned blocks.
If a clustered table is referenced multiple times in a query that uses several filters, BigQuery charges for scanning the columns in the appropriate blocks in each of the respective filters. For an example of how block pruning works, see Example.
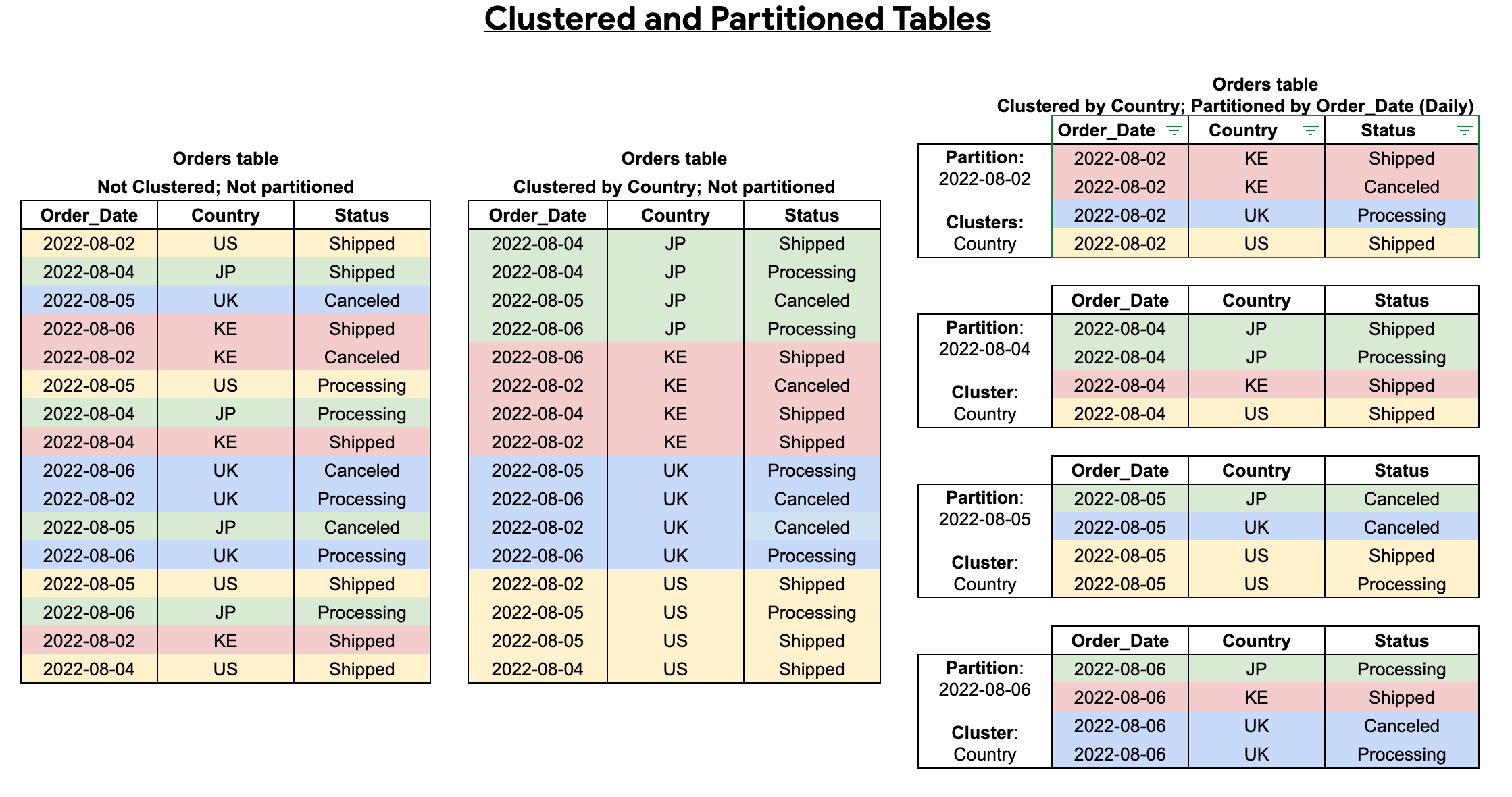
Combine clustered and partitioned tables
You can combine table clustering with table partitioning to achieve finely-grained sorting for further query optimization.
In a partitioned table, data is stored in physical blocks, each of which holds one partition of data. Each partitioned table maintains various metadata about the sort properties across all operations that modify it. The metadata lets BigQuery more accurately estimate a query cost before the query is run. However, partitioning requires BigQuery to maintain more metadata than with an unpartitioned table. As the number of partitions increases, the amount of metadata to maintain increases.
When you create a table that is clustered and partitioned, you can achieve more finely grained sorting, as the following diagram shows:
Example
You have a clustered table named ClusteredSalesData. The table is partitioned
by the timestamp column, and it is clustered by the customer_id column. The
data is organized into the following set of blocks:
| Partition identifier | Block ID | Minimum value for customer_id in the block | Maximum value for customer_id in the block |
|---|---|---|---|
| 20160501 | B1 | 10000 | 19999 |
| 20160501 | B2 | 20000 | 24999 |
| 20160502 | B3 | 15000 | 17999 |
| 20160501 | B4 | 22000 | 27999 |
You run the following query against the table. The query contains a filter on
the customer_id column.
SELECT SUM(totalSale) FROM `mydataset.ClusteredSalesData` WHERE customer_id BETWEEN 20000 AND 23000 AND DATE(timestamp) = "2016-05-01"
The preceding query involves the following steps:
- Scans the
timestamp,customer_id, andtotalSalecolumns in blocks B2 and B4. - Prunes the B3 block because of the
DATE(timestamp) = "2016-05-01"filter predicate on thetimestamppartitioning column. - Prunes the B1 block because of the
customer_id BETWEEN 20000 AND 23000filter predicate on thecustomer_idclustering column.
Automatic reclustering
As data is added to a clustered table, the new data is organized into blocks, which might create new storage blocks or update existing blocks. Block optimization is required for optimal query and storage performance because new data might not be grouped with existing data that has the same cluster values.
To maintain the performance characteristics of a clustered table, BigQuery performs automatic reclustering in the background. For partitioned tables, clustering is maintained for data within the scope of each partition.
Limitations
- Only GoogleSQL is supported for querying clustered tables and for writing query results to clustered tables.
- You can only specify up to four clustering columns. If you need additional columns, consider combining clustering with partitioning.
- When using
STRINGtype columns for clustering, BigQuery uses only the first 1,024 characters to cluster the data. The values in the columns can themselves be longer than 1,024 characters. - If you alter an existing non-clustered table to be clustered, the existing data
is not automatically clustered. Only new data that's stored using the
clustered columns is subject to automatic reclustering. For more
information about reclustering existing data using an
UPDATEstatement, see Modify clustering specification.
Clustered table quotas and limits
BigQuery restricts the use of shared Google Cloud resources with quotas and limits, including limitations on certain table operations or the number of jobs run within a day.
When you use the clustered table feature with a partitioned table, you are subject to the limits on partitioned tables.
Quotas and limits also apply to the different types of jobs that you can run against clustered tables. For information about the job quotas that apply to your tables, see Jobs in "Quotas and Limits".
Clustered table pricing
When you create and use clustered tables in BigQuery, your charges are based on how much data is stored in the tables and on the queries that you run against the data. For more information, see Storage pricing and Query pricing.
Like other BigQuery table operations, clustered table operations take advantage of BigQuery free operations such as batch load, table copy, automatic reclustering, and data export. These operations are subject to BigQuery quotas and limits. For information about free operations, see Free operations.
For a detailed clustered table pricing example, see Estimate storage and query costs.
Table security
To control access to tables in BigQuery, see Control access to resources with IAM.
What's next
- To learn how to create and use clustered tables, see Creating and using clustered tables.
- For information about querying clustered tables, see Querying clustered tables.