Il documento descrive come eseguire il deployment di una topologia di failover a freddo per un server web utilizzando un gruppo di istanze gestite e snapshot di dischi permanenti. Questo documento è destinato agli architetti e alle persone che lavorano nei team operativi e amministrativi.
Crei un gruppo di istanze gestite che esegue una singola VM con un disco permanente che archivia i dati. Gli snapshot pianificati del disco permanente riducono al minimo la perdita di dati in uno scenario di failover. Un bilanciatore del carico delle applicazioni esterno indirizza gli utenti alla VM eseguita nel gruppo di istanze gestite, come mostrato nel diagramma seguente:

In caso di errore dell'istanza, il gruppo di istanze gestite tenta di ricreare la VM nella stessa zona. Se l'errore si verifica a livello di zona, Cloud Monitoring o un sistema simile possono segnalarti un problema e creare manualmente un altro gruppo di istanze gestite in un'altra zona o regione. In entrambi gli scenari di failover, la piattaforma utilizza lo snapshot del disco permanente più recente per creare un disco sostitutivo e collegarlo alla nuova VM nel gruppo di istanze.
In questo documento utilizzerai l'indirizzo IP esterno della VM o del bilanciatore del carico per visualizzare una pagina di base sul server web. Questo approccio ti consente di testare il pattern di failover coldover se non hai un nome di dominio registrato e senza alcuna modifica al DNS. In un ambiente di produzione, crea e configura una zona e un record Cloud DNS che si risolvano nell'indirizzo IP esterno assegnato al bilanciatore del carico.
Questo pattern bilancia la differenza di costo dell'esecuzione di più VM o dischi permanenti a livello di regione con il mantenimento di un determinato livello di protezione dei dati. I costi sono inferiori con l'esecuzione di una VM e di un disco permanente, ma esiste il rischio di perdita di dati poiché gli snapshot dei dischi permanenti vengono acquisiti solo a un intervallo impostato. Per ridurre la potenziale perdita di dati, valuta la possibilità di eseguire il deployment di un server web recuperabile a freddo che utilizza dischi permanenti a livello di regione.
La tabella seguente illustra alcune differenze generali nelle opzioni di protezione dei dati per gli approcci recuperabili a freddo che utilizzano dischi permanenti a livello di regione o snapshot di disco permanente. Per ulteriori informazioni, consulta Opzioni di alta disponibilità che utilizzano dischi permanenti.
| Dischi permanenti a livello di area geografica | Snapshot di dischi permanenti | |
|---|---|---|
| Perdita di dati - RPO (Recovery Point Objective) | Zero per un singolo errore, come un'interruzione prolungata in una zona o la disconnessione di rete. | Tutti i dati dall'acquisizione dell'ultimo snapshot, che in genere è pari o superiore a un'ora. La potenziale perdita di dati dipende dalla pianificazione degli snapshot, che controlla la frequenza con cui vengono acquisiti gli snapshot. |
| RTO (Recovery Time Objective) | Tempo di deployment per una nuova VM, più diversi secondi per il collegamento del disco permanente a livello di regione. | Tempo di deployment per una nuova VM, più il tempo per creare un nuovo disco permanente dallo snapshot più recente. Il tempo di creazione del disco dipende dalle dimensioni dello snapshot e potrebbe richiedere decine di minuti o ore. |
| Costo | I costi di archiviazione raddoppiano, poiché il disco permanente a livello di regione viene replicato continuativamente in un'altra zona. | Paghi solo per la quantità di spazio di snapshot consumata. |
| Per ulteriori informazioni, consulta la sezione Prezzi di dischi e immagini. | ||
Obiettivi
- Crea un gruppo di istanze gestite per eseguire una VM con un disco permanente.
- Configura una pianificazione di snapshot per acquisire snapshot regolari del disco permanente.
- Creare un modello di istanza e uno script di avvio.
- Crea e configura un bilanciatore del carico delle applicazioni esterno.
- Testa il failover del server web freddo con un gruppo di istanze gestite sostitutivo.
Costi
In questo documento vengono utilizzati i seguenti componenti fatturabili di Google Cloud:
Per generare una stima dei costi in base all'utilizzo previsto,
utilizza il Calcolatore prezzi.
Prima di iniziare
- Accedi al tuo account Google Cloud. Se non conosci Google Cloud, crea un account per valutare le prestazioni dei nostri prodotti in scenari reali. I nuovi clienti ricevono anche 300 $di crediti gratuiti per l'esecuzione, il test e il deployment dei carichi di lavoro.
-
Nella pagina del selettore di progetti della console Google Cloud, seleziona o crea un progetto Google Cloud.
-
Assicurati che la fatturazione sia attivata per il tuo progetto Google Cloud.
-
Attiva l'API Compute Engine.
- Installa Google Cloud CLI.
-
Per initialize gcloud CLI, esegui questo comando:
gcloud init
-
Nella pagina del selettore di progetti della console Google Cloud, seleziona o crea un progetto Google Cloud.
-
Assicurati che la fatturazione sia attivata per il tuo progetto Google Cloud.
-
Attiva l'API Compute Engine.
- Installa Google Cloud CLI.
-
Per initialize gcloud CLI, esegui questo comando:
gcloud init
Puoi eseguire Google Cloud CLI nella console Google Cloud senza installare Google Cloud CLI. Per eseguire gcloud CLI nella console Google Cloud, usa Cloud Shell.
Prepara l'ambiente
In questa sezione definisci alcune variabili per le località e i nomi delle risorse. Queste variabili sono utilizzate dai comandi di Google Cloud CLI durante il deployment delle risorse.
In tutto questo documento, se non diversamente indicato, inserirai tutti i comandi in Cloud Shell o nel tuo ambiente di sviluppo locale.
Sostituisci
PROJECT_IDcon l'ID del tuo progetto. Se necessario, specifica il tuo suffisso del nome per le risorse, ad esempioapp.Specifica una regione, ad esempio
us-central1, e due zone all'interno di quell'area geografica, ad esempious-central1-aeus-central1-f. Queste zone definiscono dove viene eseguito il deployment del disco permanente iniziale e del gruppo di istanze gestite e dove è possibile eseguire manualmente il failover, se necessario.PROJECT_ID=PROJECT_ID NAME_SUFFIX=app REGION=us-central1 ZONE1=us-central1-a ZONE2=us-central1-f
Crea un VPC e una subnet
Per fornire l'accesso di rete alle VM, crea un VPC (Virtual Private Cloud) e una subnet. Poiché il gruppo di istanze gestite funziona in più zone all'interno di un'unica regione, viene creata una sola subnet. Per ulteriori informazioni sui vantaggi della modalità subnet personalizzata per gestire gli intervalli di indirizzi IP in uso nel tuo ambiente, consulta Utilizzare le reti VPC in modalità personalizzata.
Crea il VPC con una modalità di subnet personalizzata:
gcloud compute networks create network-$NAME_SUFFIX \ --subnet-mode=customSe viene visualizzato un prompt di Cloud Shell, autorizza questa prima richiesta a effettuare chiamate API.
Crea una subnet nel nuovo VPC. Definisci il tuo intervallo di indirizzi, ad esempio
10.1.0.0/20, adatto all'intervallo di rete:gcloud compute networks subnets create subnet-$NAME_SUFFIX-$REGION \ --network=network-$NAME_SUFFIX \ --range=10.1.0.0/20 \ --region=$REGION
Crea regole firewall
Crea regole firewall per consentire il traffico web e i controlli di integrità per il bilanciatore del carico e i gruppi di istanze gestite:
gcloud compute firewall-rules create allow-http-$NAME_SUFFIX \ --network=network-$NAME_SUFFIX \ --direction=INGRESS \ --priority=1000 \ --action=ALLOW \ --rules=tcp:80 \ --source-ranges=0.0.0.0/0 \ --target-tags=http-server gcloud compute firewall-rules create allow-health-check-$NAME_SUFFIX \ --network=network-$NAME_SUFFIX \ --action=allow \ --direction=ingress \ --source-ranges=130.211.0.0/22,35.191.0.0/16 \ --target-tags=allow-health-check \ --rules=tcp:80La regola HTTP consente il traffico verso qualsiasi VM in cui è applicato il tag
http-servere da qualsiasi origine che utilizzi l'intervallo0.0.0.0/0. Per la regola per il controllo di integrità, gli intervalli predefiniti per Google Cloud sono impostati in modo da consentire alla piattaforma di verificare correttamente l'integrità delle risorse.Per consentire il traffico SSH per la configurazione iniziale di un'immagine VM di base, limita l'ambito della regola firewall al tuo ambiente utilizzando il parametro
--source-range. Potrebbe essere necessario collaborare con il team di rete per determinare quali intervalli di origine vengono utilizzati dalla tua organizzazione.Sostituisci
IP_ADDRESS_SCOPEcon i tuoi ambiti degli indirizzi IP:gcloud compute firewall-rules create allow-ssh-$NAME_SUFFIX \ --network=network-$NAME_SUFFIX \ --direction=INGRESS \ --priority=1000 \ --action=ALLOW \ --rules=tcp:22 \ --source-ranges=IP_ADDRESS_SCOPEDopo aver creato le regole firewall, verifica che siano state aggiunte:
gcloud compute firewall-rules list \ --project=$PROJECT_ID \ --filter="NETWORK=network-$NAME_SUFFIX"Il seguente output di esempio mostra che le tre regole sono state create correttamente:
NAME NETWORK DIRECTION PRIORITY ALLOW allow-health-check-app network-app INGRESS 1000 tcp:80 allow-http-app network-app INGRESS 1000 tcp:80 allow-ssh-app network-app INGRESS 1000 tcp:22
Crea e configura un'immagine VM di base
Per creare VM identiche di cui esegui il deployment senza configurazioni aggiuntive, utilizza un'immagine VM personalizzata. Questa immagine acquisisce la configurazione del sistema operativo e di Apache e viene utilizzata nei passaggi successivi per creare ogni VM nel gruppo di istanze gestite.
Per archiviare i dati dell'applicazione utilizzi un disco permanente. In questo documento, utilizzerai un sito web Apache di base per gestire l'applicazione. Più avanti in questo documento, creerai una pianificazione di snapshot collegata a questo disco permanente per creare snapshot automatici del disco.
Sulla VM, puoi creare un file index.html di base sul disco permanente e montarlo in /var/www/example.com. Un file di configurazione Apache in /etc/apache2/sites-available/example.com.conf pubblica contenuti web dal percorso del disco permanente montato.
Il seguente diagramma mostra la pagina HTML di base fornita da Apache e archiviata sul disco permanente:
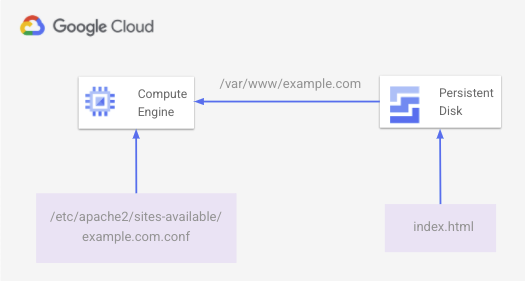
Per creare questo ambiente, segui questi passaggi.
Crea un'unità SSD da 10 GiB. Scopri quali sono le tue esigenze di archiviazione e i costi associati del pagamento per lo spazio di cui è stato eseguito il provisioning, non lo spazio utilizzato. Per ulteriori informazioni, consulta la pagina relativa ai prezzi dei dischi permanenti.
gcloud compute disks create disk-$NAME_SUFFIX \ --zone $ZONE1 \ --size=10 \ --type=pd-ssdCrea una VM di base con il disco permanente collegato:
gcloud compute instances create vm-base-$NAME_SUFFIX \ --zone=$ZONE1 \ --machine-type=n1-standard-1 \ --subnet=subnet-$NAME_SUFFIX-$REGION \ --tags=http-server \ --image=debian-10-buster-v20210721 \ --image-project=debian-cloud \ --boot-disk-size=10GB \ --boot-disk-type=pd-balanced \ --boot-disk-device-name=vm-base-$NAME_SUFFIX \ --disk=mode=rw,name=disk-$NAME_SUFFIX,device-name=disk-$NAME_SUFFIXUtilizza i parametri definiti all'inizio di questo documento per assegnare un nome alla VM e connetterti alla subnet corretta. Vengono assegnati nomi anche dai parametri per il disco di avvio e il disco dati.
Per installare e configurare il sito web semplice, connettiti prima alla VM di base utilizzando SSH:
gcloud compute ssh vm-base-$NAME_SUFFIX --zone=$ZONE1Nella sessione SSH per la VM, crea uno script per configurare la VM in un editor a tua scelta. L'esempio seguente utilizza Nano come editor:
nano configure-vm.shIncolla il seguente script di configurazione nel file. Aggiorna la variabile
NAME_SUFFIXin modo che corrisponda al valore impostato all'inizio di questo documento, ad esempio app:#!/bin/bash NAME_SUFFIX=app # Create directory for the basic website files sudo mkdir -p /var/www/example.com sudo chmod a+w /var/www/example.com sudo chown -R www-data: /var/www/example.com # Find the disk name, then format and mount it DISK_NAME="google-disk-$NAME_SUFFIX" DISK_PATH="$(find /dev/disk/by-id -name "${DISK_NAME}" | xargs -I '{}' readlink -f '{}')" sudo mkfs.ext4 -m 0 -E lazy_itable_init=0,lazy_journal_init=0,discard $DISK_PATH sudo mount -o discard,defaults $DISK_PATH /var/www/example.com # Install Apache, additional utilities, and cloud-init sudo apt-get update && sudo apt-get -y install apache2 moreutils cloud-init # Write out a basic HTML file to the mounted persistent disk sudo tee -a /var/www/example.com/index.html >/dev/null <<'EOF' <!doctype html> <html lang=en> <head> <meta charset=utf-8> <title>HA / DR example</title> </head> <body> <p>Welcome to a test web server with persistent disk snapshots!</p> </body> </html> EOF # Write out an Apache configuration file sudo tee -a /etc/apache2/sites-available/example.com.conf >/dev/null <<'EOF' <VirtualHost *:80> ServerName www.example.com ServerAdmin webmaster@localhost DocumentRoot /var/www/example.com ErrorLog ${APACHE_LOG_DIR}/error.log CustomLog ${APACHE_LOG_DIR}/access.log combined </VirtualHost> EOF # Enable the Apache configuration file and reload service sudo a2dissite 000-default sudo a2ensite example.com.conf sudo systemctl reload apache2Scrivi il file ed esci dall'editor. Ad esempio, in Nano usi
Ctrl-Oper scrivere il file, quindi esci conCtrl-X.Rendi eseguibile lo script di configurazione, quindi eseguilo:
chmod +x configure-vm.sh ./configure-vm.shSe si verifica un errore dell'istanza e il gruppo di istanze gestite deve creare una sostituzione da questa VM di base, i dati dell'applicazione devono essere disponibili. I passaggi seguenti dovrebbero essere eseguiti automaticamente su ogni nuova VM:
- Richiedi alcune informazioni dal server dei metadati.
- Ottieni lo snapshot più recente per il disco permanente.
- Crea un disco da questo snapshot più recente.
- Collega il nuovo disco alla VM.
- Montare il disco all'interno della VM.
Crea uno script di avvio denominato
app-startup.shche esegua i passaggi necessari per la VM. Questo script di avvio viene applicato a un modello di istanza in un passaggio successivo.sudo mkdir /opt/cloud-init-scripts sudo tee -a /opt/cloud-init-scripts/app-startup.sh >/dev/null <<'EOF' #!/bin/bash # Install jq and get an access token for API requests apt-get install -y jq OAUTH_TOKEN=$(curl "http://metadata.google.internal/computeMetadata/v1/instance/service-accounts/default/token" \ -H "Metadata-Flavor: Google" --silent | jq -r '.access_token') # Make a request against the metadata server to determine the project name, # instance name, and what zone it's running in ZONE_INFO=$(curl http://metadata.google.internal/computeMetadata/v1/instance/zone \ -H "Metadata-Flavor: Google" --silent) PROJECT_NAME=$(curl http://metadata.google.internal/computeMetadata/v1/instance/zone \ -H "Metadata-Flavor: Google" --silent | awk -v FS="/" '{print $2}') ZONE_NAME=$(curl http://metadata.google.internal/computeMetadata/v1/instance/zone \ -H "Metadata-Flavor: Google" --silent | sed 's:.*/::') INSTANCE_NAME=$(curl http://metadata.google.internal/computeMetadata/v1/instance/name \ -H "Metadata-Flavor: Google" --silent) # Get the latest snapshot of the app disk LATEST_SNAPSHOT=$(curl -X GET -H "Authorization: Bearer $OAUTH_TOKEN" \ https://compute.googleapis.com/compute/v1/projects/$PROJECT_NAME/global/snapshots \ --silent | jq -s '.[].items[] | select(.name | contains("disk-$NAME")) | .name' \ | sort -r | head -n 1 | tr -d '"') # Create a persistent disk using the latest persistent disk snapshot curl -X POST -H "Authorization: Bearer $OAUTH_TOKEN" -H "Content-Type: application/json; charset=utf-8" \ https://compute.googleapis.com/compute/v1/$ZONE_INFO/disks \ --data '{"name":"'$LATEST_SNAPSHOT'-restored","sizeGb":"10","type":"zones/'$ZONE_NAME'/diskTypes/pd-ssd","sourceSnapshot":"https://www.googleapis.com/compute/v1/projects/'$PROJECT_NAME'/global/snapshots/'$LATEST_SNAPSHOT'"}' # Wait for the persistent disk to be created from the disk snapshot DISK_STATUS=$(curl -X GET -H "Authorization: Bearer $OAUTH_TOKEN" \ https://compute.googleapis.com/compute/v1/projects/$PROJECT_NAME/zones/$ZONE_NAME/disks/$LATEST_SNAPSHOT-restored \ --silent | jq -r .status) while [ $DISK_STATUS != "READY" ] do sleep 2 DISK_STATUS=$(curl -X GET -H "Authorization: Bearer $OAUTH_TOKEN" \ https://compute.googleapis.com/compute/v1/projects/$PROJECT_NAME/zones/$ZONE_NAME/disks/$LATEST_SNAPSHOT-restored \ --silent | jq -r .status) done # Attach the new persistent disk created from the snapshot to the VM curl -X POST -H "Authorization: Bearer $OAUTH_TOKEN" -H "Content-Type: application/json; charset=utf-8" \ https://compute.googleapis.com/compute/v1/$ZONE_INFO/instances/$INSTANCE_NAME/attachDisk \ --data '{ "source": "/compute/v1/'$ZONE_INFO'/disks/'$LATEST_SNAPSHOT'-restored"}' # Wait for the persistent disk to be attached before mounting ATTACH_STATUS=$(curl -X GET -H "Authorization: Bearer $OAUTH_TOKEN" \ https://compute.googleapis.com/compute/v1/projects/$PROJECT_NAME/zones/$ZONE_NAME/instances/$INSTANCE_NAME \ --silent | jq '.disks[] | select(.source | contains("disk-"))') while [ -z "$ATTACH_STATUS" ] do sleep 2 ATTACH_STATUS=$(curl -X GET -H "Authorization: Bearer $OAUTH_TOKEN" GET \ https://compute.googleapis.com/compute/v1/projects/$PROJECT_NAME/zones/$ZONE_NAME/instances/$INSTANCE_NAME \ --silent | jq '.disks[] | select(.source | contains("disk-"))') done # With the disk attached, mount the disk and restart Apache echo UUID=`blkid -s UUID -o value /dev/sdb` /var/www/example.com ext4 discard,defaults,nofail 0 2 \ | tee -a /etc/fstab mount -a systemctl reload apache2 # Remove jq so it's not left on the VM apt-get remove -y jq EOFPer applicare la variabile
NAME_SUFFIXdefinita all'inizio del documento nello script di avvio, ad esempioapp, utilizza il comandoenvsubst:export NAME=app envsubst '$NAME' < "/opt/cloud-init-scripts/app-startup.sh" \ | sudo sponge "/opt/cloud-init-scripts/app-startup.sh"Esci dalla sessione SSH sulla VM:
exitOttieni l'indirizzo IP della VM e usa
curlper visualizzare la pagina web di base:curl $(gcloud compute instances describe vm-base-$NAME_SUFFIX \ --zone $ZONE1 \ --format="value(networkInterfaces.accessConfigs.[0].natIP)")Viene restituito il sito web di base, come mostrato nell'output di esempio seguente:
<!doctype html> <html lang=en> <head> <meta charset=utf-8> <title>HA / DR example</title> </head> <body> <p>Welcome to a test web server with persistent disk snapshots!</p> </body> </html>Questo passaggio conferma che Apache sia configurato correttamente e che la pagina venga caricata dal disco permanente collegato. Nelle sezioni seguenti creerai un'immagine utilizzando questa VM di base e configurerai un modello di istanza con uno script di avvio.
Crea una pianificazione di snapshot del disco permanente
Per assicurarti che le VM create nel gruppo di istanze gestite dispongano sempre dei dati più recenti dal disco permanente, puoi creare una pianificazione di snapshot. Questa pianificazione acquisisce snapshot automatici di un disco permanente in orari definiti e controlla per quanto tempo conservare gli snapshot. L'immagine seguente mostra come funziona questo processo snapshot:
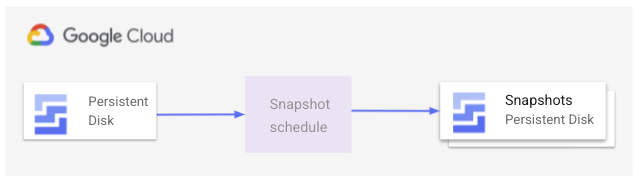
Pensa alle esigenze della tua applicazione e agli obiettivi aziendali riguardo alla frequenza con cui dovresti acquisire gli snapshot. Ad esempio, un sito web statico ha bisogno di snapshot meno frequenti rispetto a un'applicazione attiva che scrive dati su disco.
Per ulteriori informazioni su come determinare l'approccio migliore per le tue applicazioni e sul metodo di ripristino da utilizzare, consulta la guida alla pianificazione del ripristino di emergenza.
In questo scenario, utilizzerai una pianificazione di snapshot per creare regolari snapshot di dischi permanenti. Questa pianificazione di snapshot viene definita in un criterio delle risorse. I criteri delle risorse consentono di definire le azioni da eseguire e di collegarle alle risorse nel tuo ambiente.
In questo criterio delle risorse, definisci una pianificazione per la creazione di uno snapshot con le seguenti impostazioni:
- Scatta un'istantanea ogni 4 ore, a partire dalle 22:00 UTC
- Conserva gli snapshot per 1 giorno
Configura questa pianificazione in base alle esigenze del tuo ambiente, ad esempio l'ora di inizio e la frequenza con cui vuoi acquisire gli snapshot:
gcloud compute resource-policies create snapshot-schedule snapshot-schedule-$NAME_SUFFIX \ --description "Snapshot persistent disk every 4 hours" \ --max-retention-days 1 \ --start-time 22:00 \ --hourly-schedule 4 \ --region $REGIONPer ulteriori informazioni, consulta l'articolo su come utilizzare snapshot pianificati per i dischi permanenti.
Per utilizzare la pianificazione degli snapshot, collega il criterio delle risorse al disco permanente. Specifica il nome del tuo disco permanente e il criterio delle risorse creato nel passaggio precedente:
gcloud compute disks add-resource-policies disk-$NAME_SUFFIX \ --resource-policies snapshot-schedule-$NAME_SUFFIX \ --zone $ZONE1Non puoi completare il resto di questo documento e vedere il gruppo di istanze gestite in azione finché non viene creato il primo snapshot del disco. Crea manualmente uno snapshot del disco ora e consenti allo snapshot dei criteri delle risorse di pianificare la creazione di snapshot aggiuntivi come definito:
gcloud compute disks snapshot disk-$NAME_SUFFIX \ --zone=$ZONE1 \ --snapshot-names=disk-$NAME_SUFFIX-$(date "+%Y%m%d%H%M%S")
Crea un account di servizio
Ogni VM nel gruppo di istanze gestite creato nei passaggi successivi deve eseguire uno script di avvio. Questo script di avvio crea un disco permanente da uno snapshot e lo collega alla VM. Come best practice di sicurezza, crea un nuovo account di servizio con solo le autorizzazioni necessarie per eseguire queste operazioni sul disco. Successivamente, assegnerai questo account di servizio alla VM.
Crea un account di servizio da utilizzare con le VM nel gruppo di istanze gestite:
gcloud iam service-accounts create instance-sa-$NAME_SUFFIX \ --description="Service account for HA/DR example" \ --display-name="HA/DR for VM instances"Crea un ruolo personalizzato e assegna solo le autorizzazioni necessarie per eseguire le attività di gestione dei dischi. Sono richieste le seguenti autorizzazioni:
compute.snapshots.listcompute.snapshots.useReadOnlycompute.disks.getcompute.disks.createcompute.instances.getcompute.instances.attachDiskcompute.disks.use
gcloud iam roles create instance_snapshot_management_$NAME_SUFFIX \ --project=$PROJECT_ID \ --title="Snapshot management for VM instances" \ --description="Custom role to allow an instance to create a persistent disk from a snapshot and attach to VM." \ --permissions=compute.snapshots.list,compute.snapshots.useReadOnly,compute.disks.get,compute.disks.create,compute.instances.get,compute.instances.attachDisk,compute.disks.use \ --stage=GAAggiungi le associazioni di ruoli richieste per il nuovo account di servizio:
gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:instance-sa-$NAME_SUFFIX@$PROJECT_ID.iam.gserviceaccount.com" \ --role="projects/$PROJECT_ID/roles/instance_snapshot_management_$NAME_SUFFIX" gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:instance-sa-$NAME_SUFFIX@$PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/iam.serviceAccountUser"
Crea un'immagine VM e un modello di istanza
Per creare VM identiche di cui sia possibile eseguire il deployment automatico senza bisogno di ulteriori configurazioni, utilizza un'immagine VM personalizzata. Questa immagine acquisisce il sistema operativo e la configurazione Apache. Ogni VM creata nel gruppo di istanze gestite nei passaggi successivi utilizza questa immagine.
Prima di poter creare un'immagine, devi arrestare la VM:
gcloud compute instances stop vm-base-$NAME_SUFFIX --zone=$ZONE1Crea un'immagine della VM di base configurata nella sezione precedente:
gcloud compute images create image-$NAME_SUFFIX \ --source-disk=vm-base-$NAME_SUFFIX \ --source-disk-zone=$ZONE1 \ --storage-location=$REGIONUtilizza cloud-init per eseguire lo script di avvio precedente al primo avvio di una VM nei gruppi di istanze gestite. Uno script di avvio regolare applicato alla VM viene eseguito a ogni avvio, ad esempio se la VM si riavvia dopo gli aggiornamenti.
Crea un file di configurazione cloud-init da utilizzare con il modello di istanza:
tee -a cloud-init.yaml >/dev/null <<'EOF' #cloud-config runcmd: - [ bash, /opt/cloud-init-scripts/app-startup.sh ] EOFCrea un modello di istanza che applichi la configurazione cloud-init per eseguire lo script di avvio che crea un disco dallo snapshot, quindi collega e monta il disco alla VM:
gcloud compute instance-templates create template-$NAME_SUFFIX \ --machine-type=n1-standard-1 \ --subnet=projects/$PROJECT_ID/regions/$REGION/subnetworks/subnet-$NAME_SUFFIX-$REGION \ --tags=http-server \ --image=image-$NAME_SUFFIX \ --scopes cloud-platform \ --service-account="instance-sa-$NAME_SUFFIX@$PROJECT_ID.iam.gserviceaccount.com" \ --metadata-from-file user-data=cloud-init.yaml
Creare un gruppo di istanze gestite
Un gruppo di istanze gestite esegue le VM. Il gruppo di istanze gestite viene eseguito in una zona definita e monitora l'integrità delle VM. Se si verifica un errore e l'esecuzione della VM si interrompe, il gruppo di istanze gestite tenta di ricreare un'altra VM nella stessa zona e crea un disco permanente dallo snapshot più recente. Se l'errore è a livello di zona, devi eseguire manualmente il failover a freddo e creare un altro gruppo di istanze gestite in una zona diversa. La stessa immagine personalizzata e lo stesso modello di istanza configurano automaticamente la VM in modo identico.
Crea un controllo di integrità per monitorare le VM nel gruppo di istanze gestite. Questo controllo di integrità assicura che la VM risponda sulla porta 80. Per le tue applicazioni, monitora le porte appropriate per verificare l'integrità della VM.
gcloud compute health-checks create http http-basic-check-$NAME_SUFFIX --port 80Creare un gruppo di istanze gestite con una sola VM. Questa singola VM si avvia e crea un disco permanente a partire dallo snapshot più recente, quindi lo monta e inizia a gestire il traffico web.
gcloud compute instance-groups managed create instance-group-$NAME_SUFFIX-$ZONE1 \ --base-instance-name=instance-vm-$NAME_SUFFIX \ --template=template-$NAME_SUFFIX \ --size=1 \ --zone=$ZONE1 \ --health-check=http-basic-check-$NAME_SUFFIX
Crea e configura un bilanciatore del carico
Affinché gli utenti possano accedere al tuo sito web, devi consentire il traffico verso le VM in esecuzione nel gruppo di istanze gestite. Vuoi anche reindirizzare automaticamente il traffico a nuove VM in caso di errore di una zona in un gruppo di istanze gestite.
Nella sezione seguente, crei un bilanciatore del carico esterno con un servizio di backend per il traffico HTTP sulla porta 80, utilizzerai il controllo di integrità creato nei passaggi precedenti e mappa un indirizzo IP esterno tramite il servizio di backend.
Per saperne di più, consulta Come configurare un bilanciatore del carico HTTP esterno semplice.
Crea e configura il bilanciatore del carico per la tua applicazione:
# Configure port rules for HTTP port 80 gcloud compute instance-groups set-named-ports \ instance-group-$NAME_SUFFIX-$ZONE1 \ --named-ports http:80 \ --zone $ZONE1 # Create a backend service and add the managed instance group to it gcloud compute backend-services create \ web-backend-service-$NAME_SUFFIX \ --protocol=HTTP \ --port-name=http \ --health-checks=http-basic-check-$NAME_SUFFIX \ --global gcloud compute backend-services add-backend \ web-backend-service-$NAME_SUFFIX \ --instance-group=instance-group-$NAME_SUFFIX-$ZONE1 \ --instance-group-zone=$ZONE1 \ --global # Create a URL map for the backend service gcloud compute url-maps create web-map-http-$NAME_SUFFIX \ --default-service web-backend-service-$NAME_SUFFIX # Configure forwarding for the HTTP traffic gcloud compute target-http-proxies create \ http-lb-proxy-$NAME_SUFFIX \ --url-map web-map-http-$NAME_SUFFIX gcloud compute forwarding-rules create \ http-content-rule-$NAME_SUFFIX \ --global \ --target-http-proxy=http-lb-proxy-$NAME_SUFFIX \ --ports=80Ottieni l'indirizzo IP della regola di forwarding per il traffico web:
IP_ADDRESS=$(gcloud compute forwarding-rules describe http-content-rule-$NAME_SUFFIX \ --global \ --format="value(IPAddress)")Utilizza
curlo apri il browser web per visualizzare il sito web utilizzando l'indirizzo IP del bilanciatore del carico del passaggio precedente:curl $IP_ADDRESSIl bilanciatore del carico impiega alcuni minuti per completare il deployment e indirizzare correttamente il traffico al tuo backend. Viene restituito un errore HTTP 404 o 502 se il deployment del bilanciatore del carico è ancora in corso. Se necessario, attendi qualche minuto e riprova ad accedere al sito web.
Viene restituito il sito web di base, come mostrato nell'output di esempio seguente:
<!doctype html> <html lang=en> <head> <meta charset=utf-8> <title>HA / DR example</title> </head> <body> <p>Welcome to a Compute Engine website with warm failover to Cloud Storage!</p> </body> </html>
Simulare errori e ripristino di una zona
Esamina i deployment delle risorse prima di simulare un errore a livello di zona. Tutte le risorse sono state create per supportare il seguente ambiente:
- Una VM viene eseguita in un gruppo di istanze gestite con un disco permanente collegato che archivia un sito web di base.
- Gli snapshot vengono eseguiti regolarmente sul disco permanente utilizzando una pianificazione di snapshot dei criteri delle risorse.
- Uno script di avvio viene applicato a un modello di istanza in modo che qualsiasi VM creata nel gruppo di istanze gestite crei un disco permanente dall'ultimo snapshot del disco e lo colleghino.
- Un controllo di integrità monitora lo stato della VM all'interno del gruppo di istanze gestite.
- Il bilanciatore del carico delle applicazioni esterno indirizza gli utenti alla VM eseguita nel gruppo di istanze gestite.
- In caso di errore della VM, il gruppo di istanze gestite tenta di ricreare una VM nella stessa zona. Se l'errore si trova a livello di zona, devi creare manualmente un gruppo di istanze gestite di sostituzione in un'altra zona di lavoro.
In un ambiente di produzione, potresti ricevere un avviso utilizzando Cloud Monitoring o un'altra soluzione di monitoraggio quando si verifica un problema. Questo avviso richiede a una persona di comprendere l'ambito dell'errore prima di creare manualmente un gruppo di istanze gestite sostitutivo in un'altra zona di lavoro. Un approccio alternativo consiste nell'utilizzare la tua soluzione di monitoraggio per rispondere automaticamente alle interruzioni con il gruppo di istanze gestite.
Quando tu o la tua soluzione di monitoraggio determinate che l'azione più appropriata è il failover, crea un gruppo di istanze gestite sostitutivo. In questo documento, crei manualmente questa risorsa sostitutiva.
Per simulare un errore a livello di zona, elimina il backend e il gruppo di istanze gestite del bilanciatore del carico:
gcloud compute backend-services remove-backend \ web-backend-service-$NAME_SUFFIX \ --instance-group=instance-group-$NAME_SUFFIX-$ZONE1 \ --instance-group-zone=$ZONE1 \ --global gcloud compute instance-groups managed delete instance-group-$NAME_SUFFIX-$ZONE1 \ --zone=$ZONE1Quando richiesto, conferma la richiesta di eliminazione del gruppo di istanze gestite.
In un ambiente di produzione, il sistema di monitoraggio genera un avviso per richiedere ora l'azione di failover a freddo.
Utilizza di nuovo
curlo il browser web per accedere all'indirizzo IP del bilanciatore del carico:curl $IP_ADDRESS --max-time 5La richiesta
curlha esito negativo poiché non esistono target in stato integro per il bilanciatore del carico.Per simulare il failover a freddo, crea un gruppo di istanze gestite in una zona diversa:
gcloud compute instance-groups managed create instance-group-$NAME_SUFFIX-$ZONE2 \ --template=template-$NAME_SUFFIX \ --size=1 \ --zone=$ZONE2 \ --health-check=http-basic-check-$NAME_SUFFIXL'immagine VM, il modello di istanza e il disco permanente mantengono tutta la configurazione per l'istanza dell'applicazione.
Aggiorna il bilanciatore del carico per aggiungere il nuovo gruppo di istanze gestite e la nuova VM:
gcloud compute instance-groups set-named-ports \ instance-group-$NAME_SUFFIX-$ZONE2 \ --named-ports http:80 \ --zone $ZONE2 gcloud compute backend-services add-backend \ web-backend-service-$NAME_SUFFIX \ --instance-group=instance-group-$NAME_SUFFIX-$ZONE2 \ --instance-group-zone=$ZONE2 \ --globalUsa
curlo il tuo browser web ancora una volta per accedere all'indirizzo IP del bilanciatore del carico che indirizza il traffico alla VM in esecuzione nel gruppo di istanze gestite:curl $IP_ADDRESSLa VM impiega alcuni minuti per completare il deployment e ripristinare i dati dallo snapshot più recente del disco permanente. Se il deployment della VM è ancora in corso, viene restituito un errore HTTP 404 o 502 e viene visualizzato il messaggio Apache predefinito se il ripristino dei dati è ancora in corso. Se necessario, attendi qualche minuto e prova ad accedere di nuovo al sito web.
La seguente risposta di esempio mostra la pagina web in esecuzione correttamente sulla VM:
<!doctype html> <html lang=en> <head> <meta charset=utf-8> <title>HA / DR example</title> </head> <body> <p>Welcome to a test web server with persistent disk snapshots!</p> </body> </html>Controlla lo stato di integrità del gruppo di istanze gestite:
gcloud compute instance-groups managed list-instances instance-group-$NAME_SUFFIX-$ZONE2 \ --zone $ZONE2Il seguente output di esempio mostra lo stato della VM come
RUNNINGeHEALTHY:NAME ZONE STATUS HEALTH_STATE ACTION instance-vm-app us-central1-f RUNNING HEALTHY NONEPer verificare che il disco permanente collegato sia stato creato da uno snapshot, esamina l'origine. Specifica l'istanza
NAMEvisualizzata dal comandolist-instancesprecedente.gcloud compute instances describe NAME \ --zone=$ZONE2 \ --format="value(disks.[1].source)"Il seguente output di esempio mostra che il disco permanente è denominato disk-app-us-central1-a-20210630165529-umopkt17-restored. Il suffisso -restored viene aggiunto dallo script di avvio al nome dello snapshot del disco più recente:
https://www.googleapis.com/compute/v1/projects/project/zones/us-central1-f/disks/disk-app-us-central1-a-20210630165529-umopkt17-restored
Esegui la pulizia
Per evitare che al tuo Account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Per eliminare le singole risorse create in questo documento, completa i passaggi seguenti.
Elimina la configurazione del bilanciatore del carico:
gcloud compute forwarding-rules delete \ http-content-rule-$NAME_SUFFIX --global --quiet gcloud compute target-http-proxies delete \ http-lb-proxy-$NAME_SUFFIX --quiet gcloud compute url-maps delete web-map-http-$NAME_SUFFIX --quiet gcloud compute backend-services delete \ web-backend-service-$NAME_SUFFIX --global --quietElimina il gruppo di istanze gestite e il controllo di integrità:
gcloud compute instance-groups managed delete instance-group-$NAME_SUFFIX-$ZONE2 \ --zone=$ZONE2 --quiet gcloud compute health-checks delete http-basic-check-$NAME_SUFFIX --quietElimina il modello di istanza, la configurazione cloud-init, le immagini, la VM di base, il disco permanente e la pianificazione degli snapshot.
gcloud compute instance-templates delete template-$NAME_SUFFIX --quiet rm cloud-init.yaml gcloud compute images delete image-$NAME_SUFFIX --quiet gcloud compute instances delete vm-base-$NAME_SUFFIX --zone=$ZONE1 --quiet gcloud compute disks delete disk-$NAME_SUFFIX --zone=$ZONE1 --quiet gcloud compute resource-policies delete \ snapshot-schedule-$NAME_SUFFIX --region $REGION --quietElenca ed elimina gli snapshot e i dischi creati dalle istanze:
gcloud compute disks list --filter="name:disk-$NAME_SUFFIX" \ --uri | xargs gcloud compute disks delete gcloud compute snapshots list --filter="name:disk-$NAME_SUFFIX" \ --uri | xargs gcloud compute snapshots deleteElimina il ruolo personalizzato e l'account di servizio:
gcloud iam roles delete instance_snapshot_management_$NAME_SUFFIX \ --project=$PROJECT_ID --quiet gcloud iam service-accounts delete \ instance-sa-$NAME_SUFFIX@$PROJECT_ID.iam.gserviceaccount.com --quietElimina le regole firewall:
gcloud compute firewall-rules delete allow-health-check-$NAME_SUFFIX --quiet gcloud compute firewall-rules delete allow-ssh-$NAME_SUFFIX --quiet gcloud compute firewall-rules delete allow-http-$NAME_SUFFIX --quietElimina la subnet e il VPC:
gcloud compute networks subnets delete \ subnet-$NAME_SUFFIX-$REGION --region=$REGION --quiet gcloud compute networks delete network-$NAME_SUFFIX --quiet
Passaggi successivi
- Per un approccio alternativo per ridurre la potenziale perdita di dati, consulta Eseguire il deployment di un'applicazione recuperabile a freddo che utilizza dischi permanenti a livello di regione.
- Per scoprire come determinare l'approccio migliore per le tue applicazioni e quale metodo di ripristino utilizzare, consulta la Guida alla pianificazione del ripristino di emergenza.
- Per vedere altri pattern per le applicazioni, come il failover a caldo e a freddo, consulta Scenari di ripristino di emergenza per le applicazioni.
- Per conoscere altri modi per gestire scalabilità e disponibilità, consulta la sezione Pattern per app scalabili e resilienti.
- Esplora le architetture di riferimento, i diagrammi e le best practice su Google Cloud. Dai un'occhiata al nostro Cloud Architecture Center.