AutoML Vision Object Detection のドキュメント
機能の概要
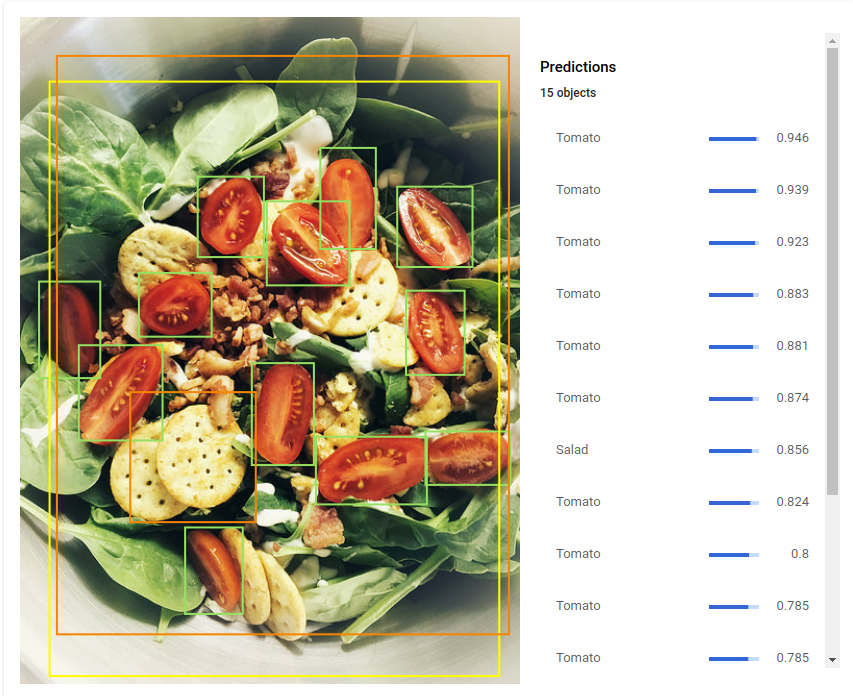
AutoML Vision Object Detection を使用すると、カスタムの機械学習モデルをトレーニングして、指定された画像内の個々のオブジェクトを、境界ボックス、ラベルとともに検出できます。
AutoML Vision Object Detection リリースには次の機能があります。
オブジェクトのローカライズ - 画像内の複数のオブジェクトを検出し、オブジェクトに関する情報とそのオブジェクトが画像内で見つかった場所を示します。
API / UI - API とカスタム ユーザー インターフェースを使うことで、Google Cloud Storage がホストする CSV ファイルとトレーニング画像からのデータセットのインポート、インポートされた画像からのアノテーションの追加と削除、モデルの評価指標のトレーニングとレビュー、オンライン予測でのモデルの使用ができます。
AutoML Vision Edge では、AutoML Vision Object Detection のトレーニング済みカスタムモデルをエクスポートできます。
- AutoML Vision Edge により、エッジデバイス向けに最適化された、低レイテンシ、高精度のモデルをトレーニングしてデプロイできます。
- TensorFlow Lite、Core ML、コンテナ エクスポート形式など、AutoML Vision Edge はさまざまなデバイスに対応しています。
- サポート対象のハードウェア アーキテクチャ: Edge TPU、ARM、NVIDIA
- iOS や Android デバイスでアプリケーションを作成するには、ML Kit の AutoML Vision Edge を使用します。このソリューションは Firebase から利用できます。ML Kit クライアント ライブラリを使用して、カスタムモデルを作成してモバイル デバイスにデプロイするエンドツーエンドの開発フローを提供します。
ドキュメント リソース
クイックスタートやガイド、主なリファレンス、一般的な問題のヘルプをご覧いただけます。