モデルを作成(トレーニング)してデプロイすると、オンライン(または同期)予測リクエストを行うことができます。
オンライン(個別)予測の例
トレーニング済みのモデルをデプロイすると、predict メソッドを使用して画像の予測をリクエストできます。また、UI を使用して予測のアノテーションを取得できます。predict メソッドは、画像のオブジェクト境界ボックスにラベルを適用します。
モデルがデプロイされている間は料金がかかります。トレーニング済みのモデルで予測を行った後で、モデルのデプロイを解除すると、モデルのホスティング料金の発生を防ぐことができます。
ウェブ UI
AutoML Vision Object Detection UI を開き、左側のナビゲーション バーで電球のアイコンがある [モデル] タブをクリックすると、使用可能なモデルが表示されます。
別のプロジェクトのモデルを表示するには、タイトルバーの右上にあるプルダウン リストからプロジェクトを選択します。
画像のラベル付けに使用するモデルの行をクリックします。
モデルがまだデプロイされていない場合は、[モデルのデプロイ] を選択してデプロイします。
オンライン予測を使用するには、モデルをデプロイする必要があります。モデルのデプロイでは料金が発生します。詳細については、料金のページをご覧ください。
タイトルバーのすぐ下にある [テストと使用] タブをクリックします。
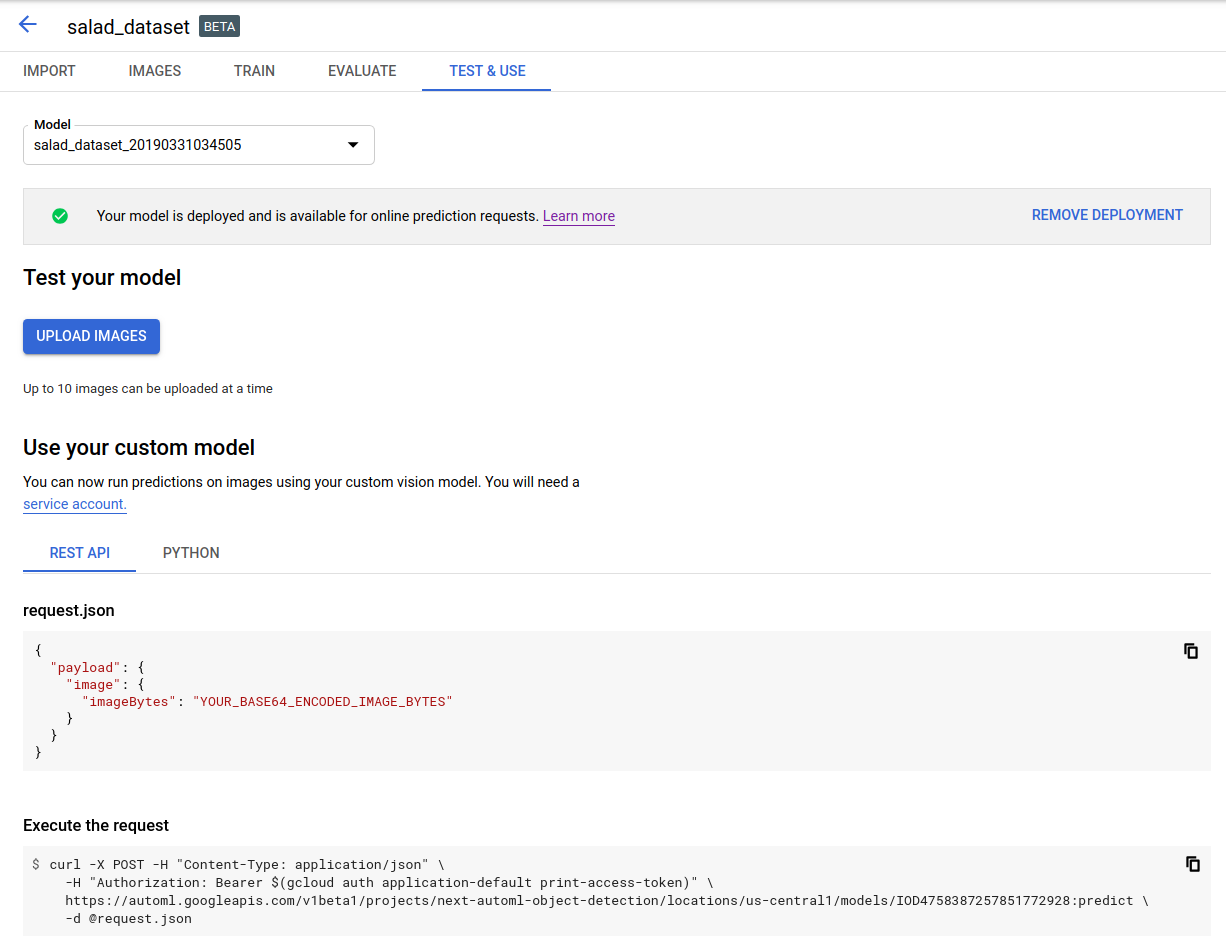
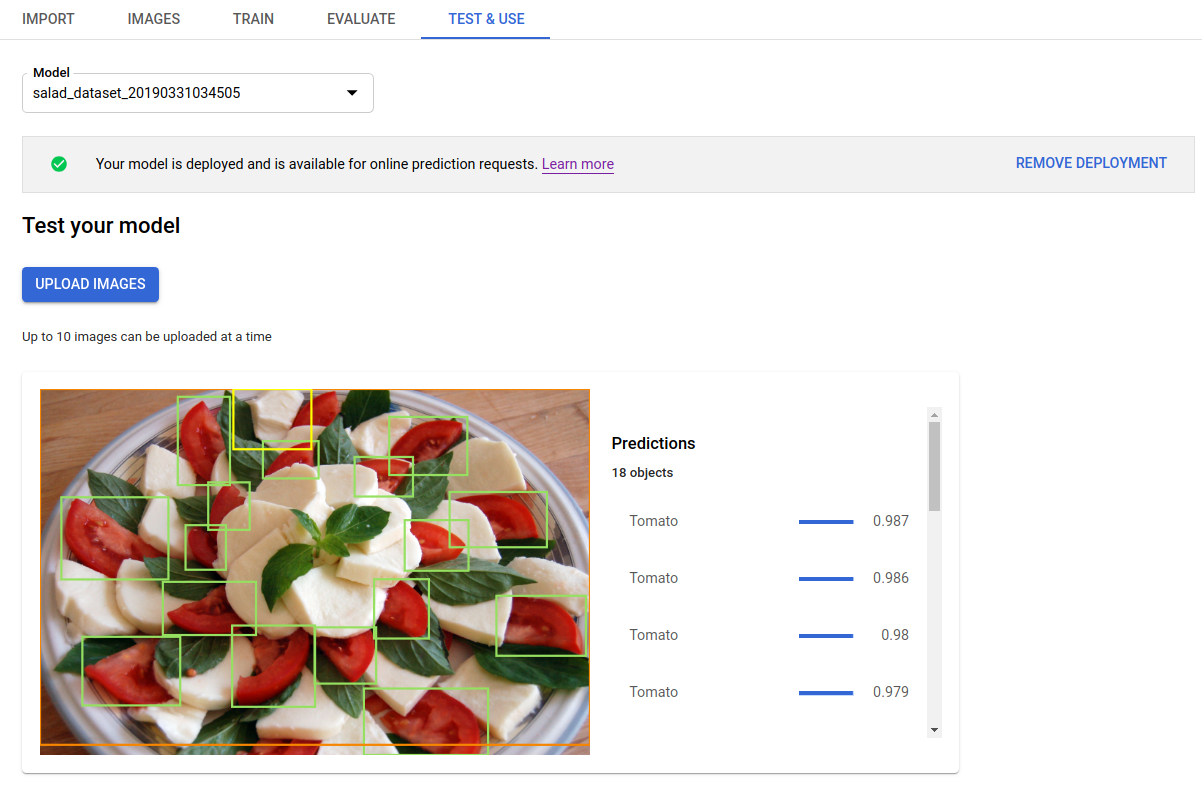
[画像をアップロード] をクリックして、ラベルを付ける画像をアップロードします。
REST
予測をテストする前に、クラウドでホストされるモデルをデプロイする必要があります。
リクエストのデータを使用する前に、次のように置き換えます。
- project-id: GCP プロジェクト ID
- model-id: モデルを作成したときにレスポンスで返されたモデルの ID。この ID は、モデルの名前の最後の要素です。例:
- モデル名:
projects/project-id/locations/location-id/models/IOD4412217016962778756 - モデル ID:
IOD4412217016962778756
- モデル名:
- base64-encoded-image: バイナリ画像データの base64 表現(ASCII 文字列)。この文字列は、
/9j/4QAYRXhpZgAA...9tAVx/zDQDlGxn//2Q==のような文字列になります。詳細については、Base64 エンコードのトピックをご覧ください。
フィールド固有の考慮事項:
scoreThreshold- 0~1 の値です。スコアしきい値がこの値以上の値のみが表示されます。デフォルト値は 0.5 です。maxBoundingBoxCount- レスポンスで返される境界ボックスの最大数(上限)です。デフォルト値は 100、最大値は 500 です。この値はリソース制約の対象となり、サーバーによって制限されます。
HTTP メソッドと URL:
POST https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:predict
リクエストの本文(JSON):
{
"payload": {
"image": {
"imageBytes": "BASE64_ENCODED_IMAGE"
}
},
"params": {
"scoreThreshold": "0.5",
"maxBoundingBoxCount": "100"
}
}
リクエストを送信するには、次のいずれかのオプションを選択します。
curl
リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:predict"
PowerShell
リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:predict" | Select-Object -Expand Content
出力が JSON 形式で返されます。payload フィールドに AutoML Vision Object Detection モデルからの予測が含まれます。
- オブジェクトの
boundingBoxは対角線上の頂点によって指定されます。 displayNameは、AutoML Vision Object Detection モデルによって予測されたラベルです。scoreは、指定されたラベルが画像に適用する信頼度を表します。これは0(信頼できない)から1(信頼度が高い)までの値で表されます。
{
"payload": [
{
"imageObjectDetection": {
"boundingBox": {
"normalizedVertices": [
{
"x": 0.034553755,
"y": 0.015524037
},
{
"x": 0.941527,
"y": 0.9912563
}
]
},
"score": 0.9997793
},
"displayName": "Salad"
},
{
"imageObjectDetection": {
"boundingBox": {
"normalizedVertices": [
{
"x": 0.11737197,
"y": 0.7098793
},
{
"x": 0.510878,
"y": 0.87987
}
]
},
"score": 0.63219965
},
"displayName": "Tomato"
}
]
}
Go
このサンプルを試す前に、クライアント ライブラリ ページを参照して、この言語の設定手順を完了してください。
Java
このサンプルを試す前に、クライアント ライブラリ ページを参照して、この言語の設定手順を完了してください。
Node.js
このサンプルを試す前に、クライアント ライブラリ ページを参照して、この言語の設定手順を完了してください。
Python
このサンプルを試す前に、クライアント ライブラリ ページを参照して、この言語の設定手順を完了してください。
その他の言語
C#: クライアント ライブラリ ページの C# の設定手順を行ってから、.NET 用の AutoML Vision Object Detection リファレンス ドキュメントをご覧ください。
PHP: クライアント ライブラリ ページの PHP の設定手順を行ってから、PHP 用の AutoML Vision Object Detection リファレンス ドキュメントをご覧ください。
Ruby: クライアント ライブラリ ページの Ruby の設定手順を行ってから、Ruby 用の AutoML Vision Object Detection リファレンス ドキュメントをご覧ください。