このページでは、サービスに関連付けられたダッシュボードを表示、使用する方法について説明します。
プロジェクト内の各サービスには、それぞれ独自のダッシュボードがあります。ダッシュボードでは、ログ、パフォーマンス指標、アラート ポリシーのステータスなど、サービスの多くの側面とサービスのパフォーマンスを確認できます。
次の方法で、サービスのダッシュボードを表示できます。
既存のサービスの場合は、[サービスの概要] ページのインベントリ テーブルでサービスの名前をクリックします。詳細については、マイクロサービスの表示をご覧ください。
新しいカスタム サービスを正常に定義したら、[サービス ダッシュボードの表示] をクリックします。詳細については、サービスの定義をご覧ください。
ダッシュボードの構造
Cloud Monitoring の各サービスのダッシュボードの一般的な構造は同じです。
どの種類のサービスのダッシュボードにも次の情報が表示されます。
- サービスの詳細: サービスの識別情報を表します。
- アラート情報: アラート ポリシーの動作を表します。
- 現在の SLO ステータス: サービスレベル目標(SLO)に対するサービスのパフォーマンスを示します。
- Logging 情報: このサービスに対する Cloud Logging の最近のログエントリを表示します。
GKE ベースのサービスの場合、ダッシュボードには以下も表示されます。
- 指標: サービスに関連する指標のグラフを表示します。
- エンティティの詳細: サービスの根拠となっている GKE エンティティに関する情報を一覧表示します。
サービスの詳細
[サービスの詳細] ペインには、サービスに関連付けられた ID、タイプ、ラベルが表示されます。次のスクリーンショットは、App Engine サービスの例を示しています。
![[サービスの詳細] には、サービスの識別情報が表示されます。](https://cloud.google.com/static/stackdriver/docs/solutions/slo-monitoring/images/svcmon-svcdb-details.png?hl=ja)
アラートのスケジュール
[アラートのスケジュール] ペインには、最近発生した SLO ベースのアラート ポリシーの履歴が表示されます。アラート ポリシーに該当すると、インシデントが発生されます。次のスクリーンショットは、前日に発生したインシデントを示しています。
![[アラートのスケジュール] に SLO ベースの最新のインシデントが表示されている。](https://cloud.google.com/static/stackdriver/docs/solutions/slo-monitoring/images/svcmon-svcdb-alert.png?hl=ja)
色付きの帯は、インシデントの期間を示します。インシデントの詳細情報を表示するには、色付きの帯の上にカーソルを置きます。アラート ポリシーを識別し、アラート ポリシーが発生した日時と、インシデントの現在のステータスを示すカードが表示されます。カードの [インシデントを表示] をクリックすると、Cloud Monitoring の [インシデントの詳細] ページが表示されます。インシデントの詳細ページの詳細については、インシデントをご覧ください。
デフォルトの表示期間は 1 時間です。表示期間を変更するには、[期間] セレクタで別の値を選択します。
表示画面からアラートのスケジュールを削除するには、schedule [タイムラインを非表示] をクリックします。
現在の SLO のステータス
[現在のステータス] ペインには、サービスについて定義されている個々の SLO のステータスが表示されます。次のスクリーンショットは、2 つの SLO が設定されたサービスの現在のステータスを示しています。
![[現在のステータス] に SLO のパフォーマンスが表示されています。](https://cloud.google.com/static/stackdriver/docs/solutions/slo-monitoring/images/svcmon-svcdb-slostatus.png?hl=ja)
各 SLO は、テーブルで以下の列を持つ行として表示されます。
- [ステータス] は、サービスが SLO を満たしているかどうかを示します。
- [目標] は、SLO のパフォーマンス目標の概要を示します。
- [タイプ] は、SLO で使用されるサービスレベル インジケーター(SLI)を表します。
- [アラートの起動] には、アラート ポリシーの総数と起動されたアラート ポリシーの比率が表示されます。
- [エラー バジェット] は、残りのエラー バジェットの割合を示します。
- more_vert [その他のオプション] には、アラート ポリシーの作成など、サービスに対して可能な構成の変更が表示されます。
- expand_more [さらに表示] をクリックすると、現在の行が展開され、SLO のパフォーマンスの詳細が表示されます。
[現在のステータス] ペインには、[SLO の作成] ボタンも表示されます。1 個のサービスに複数の SLO を設定できます。SLO の作成については、SLO の作成をご覧ください。
ステータスの詳細
expand_more [さらに表示] をクリックすると、ステータス行が展開され、SLO の詳細が表示されます。
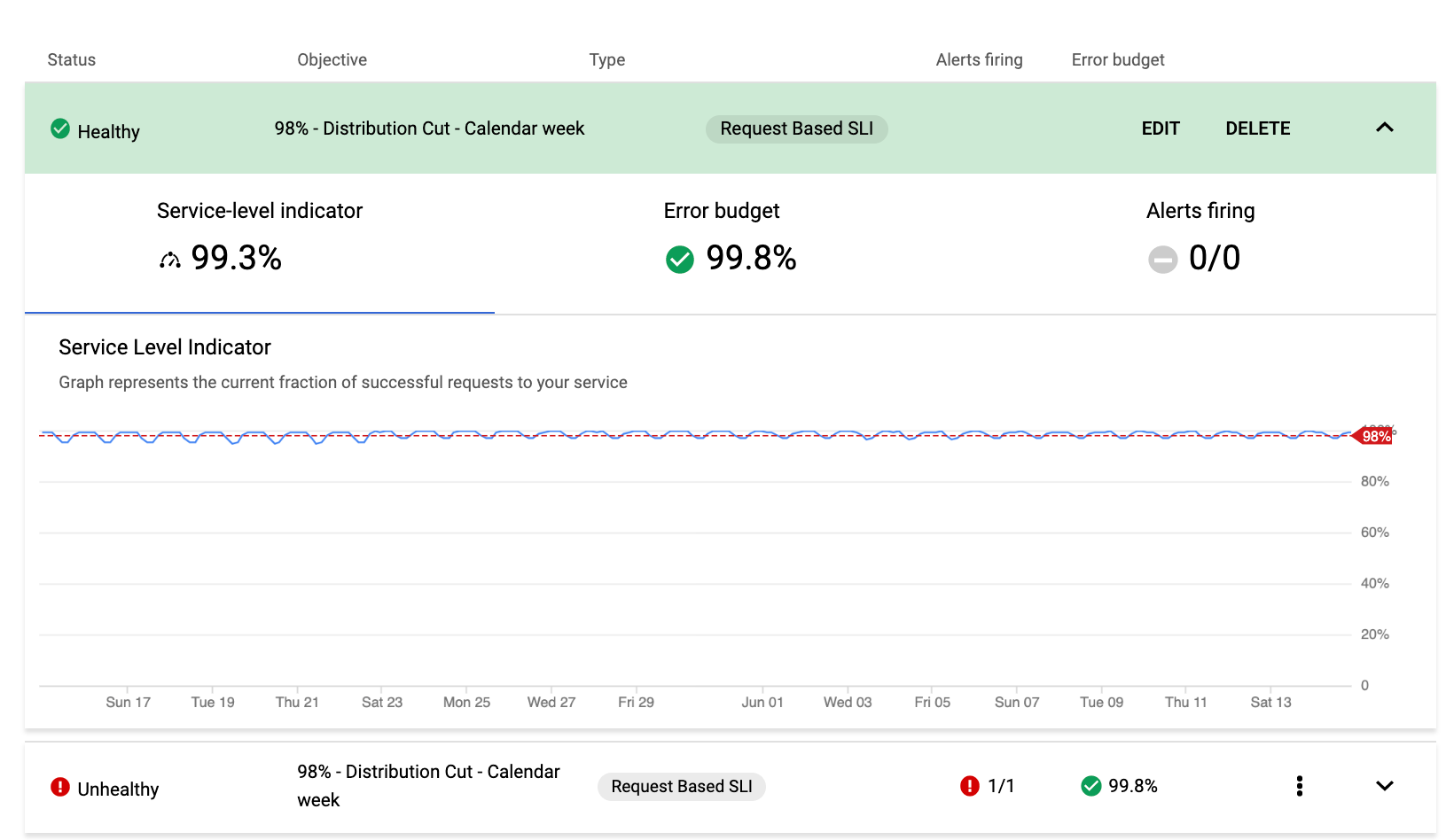
expand_more [さらに表示] をクリックすると、元のエントリが SLO のステータスを示す色分けされたバーに置き換えられます。このバーには SLO の表示名とタイプが表示され、SLO 構成を変更または削除する [編集] ボタンと [削除] ボタンが表示されます。
ステータスの概要ビューに戻るには、expand_less [折りたたむ] をクリックします。
展開した詳細には、以下のステータス インジケーターも含まれます。
- サービスレベル指標の現在の値。
- 残りのエラー バジェットのステータスと値。
- この SLO のアラート ポリシーのステータス。
これらの指標はタブであり、各タブを選択すると詳細表示の残りが変化します。デフォルトでは、[サービスレベル指標] タブが選択されています。このタブには、SLO しきい値に対する SLI のパフォーマンスの推移がグラフで表示されます。前のスクリーンショットには、そのグラフが表示されています。
[エラー バジェット] タブ
[エラー バジェット] タブをクリックすると、時系列でのエラー バジェットの消費を示すグラフが表示されます。
![エラー バジェットの [詳細] タブにグラフが表示されます。](https://cloud.google.com/static/stackdriver/docs/solutions/slo-monitoring/images/svcmon-svcdb-budget-tab.png?hl=ja)
SLI が SLO のパフォーマンスのしきい値に収まらない各コンプライアンス期間において、エラー バジェットの一部が消費されます。詳細情報は、SLO のタイプとコンプライアンス期間によって異なります。詳しくは、エラー バジェットとエラー バジェットの経過をご覧ください。
コンプライアンス期間のエラー バジェットを使い切ると、サービスが SLO を満たせなくなります。
[アラート] タブ
[アラートの起動] タブをクリックすると、対応待ちのインシデント数とアラート ポリシーのステータスが表示され、アラート ポリシーを追加で定義できます。
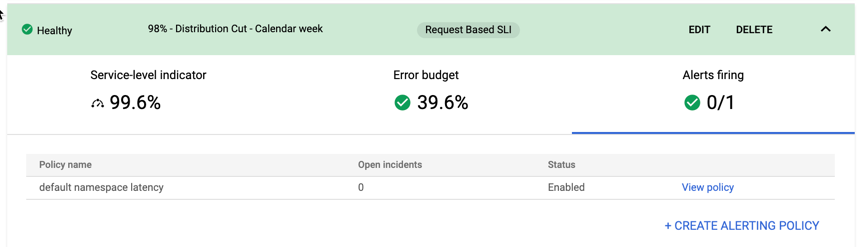
[ポリシーを表示] をクリックすると、この SLO に関連付けられたアラート ポリシーの [ポリシーの詳細] ページに移動します。
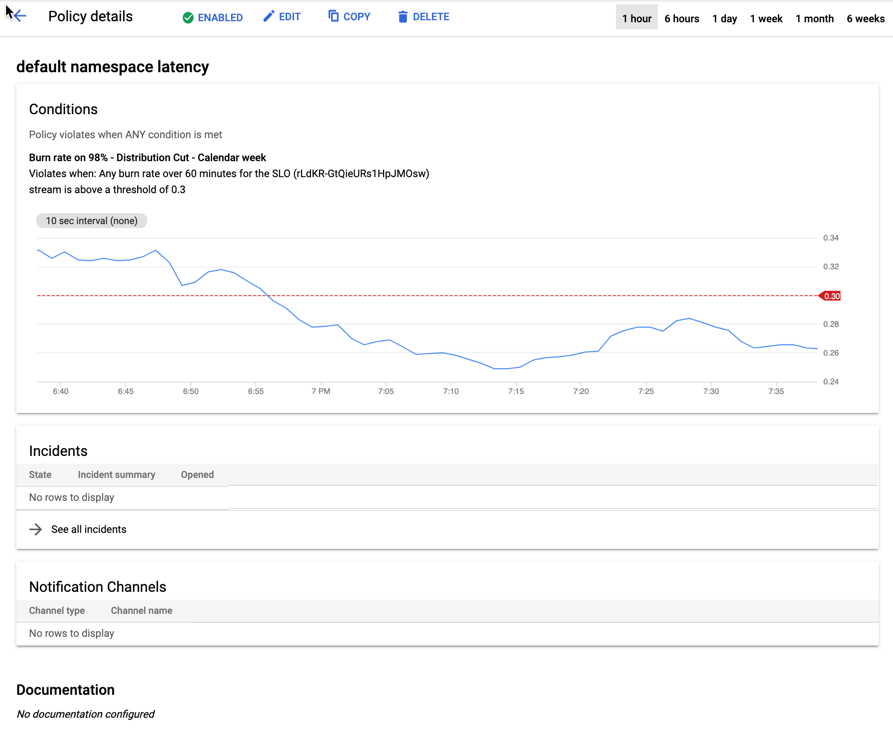
[ポリシーの詳細] には、サービスがエラー バジェットを消費している速度を表すグラフが表示されます。アラート ポリシーを作成するときは、エラー バジェットのサイズとコンプライアンス期間の長さに基づいてしきい値を設定します。しきい値とは、コンプライアンス期間の終了前にエラー バジェットを使い果たすことなくエラー バジェットを消費できる速度の推定値です。また、この速度を超えると、アラート ポリシーにより警告が表示されます。
これらのアラート ポリシーの仕組みの詳細については、バーンレートに関する警告をご覧ください。アラート ポリシーの作成については、アラート ポリシーの作成をご覧ください。
ログ
[ログ] ペインには、このサービスによって Cloud Logging に書き込まれたログエントリが表示されます。次のスクリーンショットの例をご覧ください。
![[ログ] には、このサービスによって書き込まれた Cloud Logging のログエントリが表示されます。](https://cloud.google.com/static/stackdriver/docs/solutions/slo-monitoring/images/svcmon-svcdb-logs.png?hl=ja)
ログエントリを分析するには、Cloud Logging の一部である [ログ エクスプローラを開く] をクリックします。詳細については、ログ エクスプローラを使用してログを表示するをご覧ください。
指標
GKE ベースのサービスにのみ適用されます。
[指標] ペインには、サービスによって書き込まれた指標群のグラフが表示されます。使用可能な指標群は、サービスが表すエンティティのタイプによって異なります。次のスクリーンショットは、Kubernetes クラスタに基づくサービスのデフォルトのグラフを示しています。
![[指標] には、選択したサービス指標のグラフが表示されます。](https://cloud.google.com/static/stackdriver/docs/solutions/slo-monitoring/images/svcmon-svcdb-metrics.png?hl=ja)
各グラフには、次のボタンを備えたツールバーがあります。
- legend_toggle [凡例の切り替え] を押すと、グラフの下に凡例が表示されます。グラフの凡例については、凡例の構成をご覧ください。
- fullscreen [全画面表示] を押すと、グラフが全画面モードで表示されます。
- more_vert [その他のオプション] を押すと、次の選択肢を含むメニューが表示されます。
- [PNG をダウンロード] を押すと、グラフの画像を PNG 形式で保存できます。
- [Metrics Explorer で表示する] を押すと、グラフが Metrics Explorer で開きます。ここで、グラフに表示されるデータとグラフの表示特性を変更できます。詳しくは、Metrics Explorer をご確認ください。
Monitoring のグラフの概要については、ダッシュボード ウィジェットを追加するをご覧ください。
その他のグラフ
デフォルトでは、[指標] パネルにクラスタの CPU 使用率のグラフが表示されます。指標メニューから別の指標群を選択すると、複数のグラフ群を表示できます。次のスクリーンショットは、クラスタベースのサービスのメニューを示しています。
![その他のグラフは [指標] ペインに表示されます。](https://cloud.google.com/static/stackdriver/docs/solutions/slo-monitoring/images/svcmon-svcdb-metric-choices.png?hl=ja)
このメニューには、このサービス、コンテナ、Pod、ネットワークで利用可能な指標のカテゴリが表示されます。これらのカテゴリにはそれぞれ、いくつかの指標タイプとともに、このペインに表示されるグラフが含まれます。
サンプル サービスの [指標] ペインにはまず、コンテナの CPU 使用率のグラフが表示されますが、コンテナの一時ストレージ、メモリ、その他の指標のグラフも表示されます。また、Pod とノードの指標についても、グラフが表示されます。
グラフで使用可能な指標の詳細については、help [ヘルプ] をクリックしてください。このメニューのグラフは、Kubernetes 指標のリストの指標タイプに対応しています。
エンティティの詳細
GKE ベースのサービスにのみ適用されます。
[Kubernetes エンティティの詳細] ペインに、このサービスに関連付けられている GKE エンティティに関する情報が表示されます。表示される情報は、サービスが表すエンティティの種類によって異なります。次のスクリーンショットは、Kubernetes クラスタに基づいてサービスの一部のエンティティを示しています。
![[Kubernetes エンティティの詳細] に、サービス内のエンティティに関する情報が表示されます。](https://cloud.google.com/static/stackdriver/docs/solutions/slo-monitoring/images/svcmon-svcdb-entities.png?hl=ja)
テーブルの各行には、このエンティティに関する情報を表示する他の方法のメニューを表示する more_vert [その他のオプション] ボタンも表示されます。
- Google Kubernetes Engine のダッシュボードの表示。このダッシュボードの詳細については、Google Kubernetes Engine のドキュメントの GKE ダッシュボードをご覧ください。
- このサービスによって書き込まれたログエントリのログ エクスプローラでの表示。詳細については、ログ エクスプローラを使用してログを表示するをご覧ください。