This document describes how to set up the OpenTelemetry Collector to scrape standard Prometheus metrics and report those metrics to Google Cloud Managed Service for Prometheus. The OpenTelemetry Collector is an agent that you can deploy yourself and configure to export to Managed Service for Prometheus. The set-up is similar to running Managed Service for Prometheus with self-deployed collection.
You might choose the OpenTelemetry Collector over self-deployed collection for the following reasons:
- The OpenTelemetry Collector lets you route your telemetry data to multiple backends by configuring different exporters in your pipeline.
- The Collector also supports signals from metrics, logs, and traces, so by using it you can handle all three signal types in one agent.
- OpenTelemetry's vendor-agnostic data format (the OpenTelemetry Protocol, or OTLP) supports a strong ecosystem of libraries and pluggable Collector components. This allows for a range of customizability options for receiving, processing, and exporting your data.
The trade-off for these benefits is that running an OpenTelemetry Collector requires a self-managed deployment and maintenance approach. Which approach you choose will depend on your specific needs, but in this document we offer recommended guidelines for configuring the OpenTelemetry Collector using Managed Service for Prometheus as a backend.
Before you begin
This section describes the configuration needed for the tasks described in this document.
Set up projects and tools
To use Google Cloud Managed Service for Prometheus, you need the following resources:
A Google Cloud project with the Cloud Monitoring API enabled.
If you don't have a Google Cloud project, then do the following:
In the Google Cloud console, go to New Project:
In the Project Name field, enter a name for your project and then click Create.
Go to Billing:
Select the project you just created if it isn't already selected at the top of the page.
You are prompted to choose an existing payments profile or to create a new one.
The Monitoring API is enabled by default for new projects.
If you already have a Google Cloud project, then ensure that the Monitoring API is enabled:
Go to APIs & services:
Select your project.
Click Enable APIs and Services.
Search for "Monitoring".
In the search results, click through to "Cloud Monitoring API".
If "API enabled" is not displayed, then click the Enable button.
A Kubernetes cluster. If you do not have a Kubernetes cluster, then follow the instructions in the Quickstart for GKE.
You also need the following command-line tools:
gcloudkubectl
The gcloud and kubectl tools are part of the
Google Cloud CLI. For information about installing
them, see Managing Google Cloud CLI components. To see the
gcloud CLI components you have installed, run the following command:
gcloud components list
Configure your environment
To avoid repeatedly entering your project ID or cluster name, perform the following configuration:
Configure the command-line tools as follows:
Configure the gcloud CLI to refer to the ID of your Google Cloud project:
gcloud config set project PROJECT_ID
Configure the
kubectlCLI to use your cluster:kubectl config set-cluster CLUSTER_NAME
For more information about these tools, see the following:
Set up a namespace
Create the NAMESPACE_NAME Kubernetes namespace for resources you create
as part of the example application:
kubectl create ns NAMESPACE_NAME
Verify service account credentials
If your Kubernetes cluster has Workload Identity Federation for GKE enabled, then you can skip this section.
When running on GKE, Managed Service for Prometheus
automatically retrieves credentials from the environment based on the
Compute Engine default service account. The default service account has the
necessary permissions, monitoring.metricWriter and monitoring.viewer, by
default. If you don't use Workload Identity Federation for GKE, and you have previously
removed either of those roles from the default node service account, you will
have to re-add those missing permissions before continuing.
Configure a service account for Workload Identity Federation for GKE
If your Kubernetes cluster doesn't have Workload Identity Federation for GKE enabled, then you can skip this section.
Managed Service for Prometheus captures metric data by using the Cloud Monitoring API. If your cluster is using Workload Identity Federation for GKE, you must grant your Kubernetes service account permission to the Monitoring API. This section describes the following:
- Creating a dedicated Google Cloud service account,
gmp-test-sa. - Binding the Google Cloud service account to the default Kubernetes
service account in a test namespace,
NAMESPACE_NAME. - Granting the necessary permission to the Google Cloud service account.
Create and bind the service account
This step appears in several places in the Managed Service for Prometheus documentation. If you have already performed this step as part of a prior task, then you don't need to repeat it. Skip ahead to Authorize the service account.
The following command sequence creates the gmp-test-sa service account
and binds it to the default Kubernetes service account in the
NAMESPACE_NAME namespace:
gcloud config set project PROJECT_ID \ && gcloud iam service-accounts create gmp-test-sa \ && gcloud iam service-accounts add-iam-policy-binding \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:PROJECT_ID.svc.id.goog[NAMESPACE_NAME/default]" \ gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ && kubectl annotate serviceaccount \ --namespace NAMESPACE_NAME \ default \ iam.gke.io/gcp-service-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
If you are using a different GKE namespace or service account, adjust the commands appropriately.
Authorize the service account
Groups of related permissions are collected into roles, and you grant the roles to a principal, in this example, the Google Cloud service account. For more information about Monitoring roles, see Access control.
The following command grants the Google Cloud service account,
gmp-test-sa, the Monitoring API roles it needs to
write
metric data.
If you have already granted the Google Cloud service account a specific role as part of prior task, then you don't need to do it again.
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
Debug your Workload Identity Federation for GKE configuration
If you are having trouble getting Workload Identity Federation for GKE to work, see the documentation for verifying your Workload Identity Federation for GKE setup and the Workload Identity Federation for GKE troubleshooting guide.
As typos and partial copy-pastes are the most common sources of errors when configuring Workload Identity Federation for GKE, we strongly recommend using the editable variables and clickable copy-paste icons embedded in the code samples in these instructions.
Workload Identity Federation for GKE in production environments
The example described in this document binds the Google Cloud service account to the default Kubernetes service account and gives the Google Cloud service account all necessary permissions to use the Monitoring API.
In a production environment, you might want to use a finer-grained approach, with a service account for each component, each with minimal permissions. For more information on configuring service accounts for workload-identity management, see Using Workload Identity Federation for GKE.
Set up the OpenTelemetry Collector
This section guides you through setting up and using the OpenTelemetry Collector to scrape metrics from an example application and send the data to Google Cloud Managed Service for Prometheus. For detailed configuration information, see the following sections:
The OpenTelemetry Collector is analogous to the Managed Service for Prometheus agent binary. The OpenTelemetry community regularly publishes releases including source code, binaries, and container images.
You can either deploy these artifacts on VMs or Kubernetes clusters using the best-practice defaults, or you can use the collector builder to build your own collector consisting of only the components you need. To build a collector for use with Managed Service for Prometheus, you need the following components:
- The Managed Service for Prometheus exporter, which writes your metrics to Managed Service for Prometheus.
- A receiver to scrape your metrics. This document assumes that you are using the OpenTelemetry Prometheus receiver, but the Managed Service for Prometheus exporter is compatible with any OpenTelemetry metrics receiver.
- Processors to batch and mark up your metrics to include important resource identifiers depending on your environment.
These components are enabled by using a configuration
file
that is passed to the Collector with the --config flag.
The following sections discuss how to configure each of these components in more detail. This document describes how to run the collector on GKE and elsewhere.
Configure and deploy the Collector
Whether you are running your collection on Google Cloud or in another environment, you can still configure the OpenTelemetry Collector to export to Managed Service for Prometheus. The biggest difference will be in how you configure the Collector. In non-Google Cloud environments, there may be additional formatting of metric data that is needed for it to be compatible with Managed Service for Prometheus. On Google Cloud, however, much of this formatting can be automatically detected by the Collector.
Run the OpenTelemetry Collector on GKE
You can copy the following config into a file called config.yaml to set up the
OpenTelemetry Collector on GKE:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
# Note that the googlemanagedprometheus exporter block is intentionally blank
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resourcedetection, transform]
exporters: [googlemanagedprometheus]
The preceding config uses the Prometheus receiver and the Managed Service for Prometheus exporter to scrape the metrics endpoints on Kubernetes Pods and export those metrics to Managed Service for Prometheus. The pipeline processors format and batch the data.
For more details on what each part of this config does, along with configurations for different platforms, see the detailed following sections on scraping metrics and adding processors.
When using an existing Prometheus configuration with the OpenTelemetry Collector's
prometheus receiver, replace any single dollar sign characters,
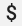 , with double characters,
, with double characters, 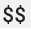 ,
to avoid triggering environment variable substitution. For more information, see
Scrape Prometheus metrics.
,
to avoid triggering environment variable substitution. For more information, see
Scrape Prometheus metrics.
You can modify this config based on your environment, provider, and the metrics you want to scrape, but the example config is a recommended starting point for running on GKE.
Run the OpenTelemetry Collector outside Google Cloud
Running the OpenTelemetry Collector outside Google Cloud, such as on-premises or on other cloud providers, is similar to running the Collector on GKE. However, the metrics you scrape are less likely to automatically include data that best formats it for Managed Service for Prometheus. Therefore, you must take extra care to configure the collector to format the metrics so they are compatible with Managed Service for Prometheus.
You can copy the following config into a file called config.yaml to set up the
OpenTelemetry Collector for deployment on a non-GKE Kubernetes
cluster:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resource:
attributes:
- key: "cluster"
value: "CLUSTER_NAME"
action: upsert
- key: "namespace"
value: "NAMESPACE_NAME"
action: upsert
- key: "location"
value: "REGION"
action: upsert
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
exporters:
googlemanagedprometheus:
project: "PROJECT_ID"
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resource, transform]
exporters: [googlemanagedprometheus]
This config does the following:
- Sets up a Kubernetes service discovery scrape config for Prometheus. For more information, see scraping Prometheus metrics.
- Manually sets
cluster,namespace, andlocationresource attributes. For more information about resource attributes, including resource detection for Amazon EKS and Azure AKS, see Detect resource attributes. - Sets the
projectoption in thegooglemanagedprometheusexporter. For more information about the exporter, see Configure thegooglemanagedprometheusexporter.
When using an existing Prometheus configuration with the OpenTelemetry Collector's
prometheus receiver, replace any single dollar sign characters,
, with double characters, ,
to avoid triggering environment variable substitution. For more information, see
Scrape Prometheus metrics.
For information about best practices for configuring the Collector on other clouds, see Amazon EKS or Azure AKS.
Deploy the example application
The example application emits the
example_requests_total counter metric and the example_random_numbers
histogram metric (among others) on its metrics port.
The manifest for this example defines three replicas.
To deploy the example application, run the following command:
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/example-app.yaml
Create your collector config as a ConfigMap
After you have created your config and placed it in a file called config.yaml,
use that file to create a Kubernetes ConfigMap based on your config.yaml file.
When the collector is deployed, it mounts the ConfigMap and loads the file.
To create a ConfigMap named otel-config with your config, use the following
command:
kubectl -n NAMESPACE_NAME create configmap otel-config --from-file config.yaml
Deploy the collector
Create a file called collector-deployment.yaml with the following content:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: NAMESPACE_NAME:prometheus-test
rules:
- apiGroups: [""]
resources:
- pods
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: NAMESPACE_NAME:prometheus-test
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: NAMESPACE_NAME:prometheus-test
subjects:
- kind: ServiceAccount
namespace: NAMESPACE_NAME
name: default
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: otel-collector
spec:
replicas: 1
selector:
matchLabels:
app: otel-collector
template:
metadata:
labels:
app: otel-collector
spec:
containers:
- name: otel-collector
image: otel/opentelemetry-collector-contrib:0.128.0
args:
- --config
- /etc/otel/config.yaml
- --feature-gates=exporter.googlemanagedprometheus.intToDouble
volumeMounts:
- mountPath: /etc/otel/
name: otel-config
volumes:
- name: otel-config
configMap:
name: otel-config
Create the Collector deployment in your Kubernetes cluster by running the following command:
kubectl -n NAMESPACE_NAME create -f collector-deployment.yaml
After the pod starts, it scrapes the sample application and reports metrics to Managed Service for Prometheus.
For information about ways to query your data, see Query using Cloud Monitoring or Query using Grafana.
Provide credentials explicitly
When running on GKE, the OpenTelemetry Collector
automatically retrieves credentials from the environment based on the
node's service account.
In non-GKE Kubernetes clusters, credentials must be explicitly
provided to the OpenTelemetry Collector by using flags or the
GOOGLE_APPLICATION_CREDENTIALS environment variable.
Set the context to your target project:
gcloud config set project PROJECT_ID
Create a service account:
gcloud iam service-accounts create gmp-test-sa
This step creates the service account that you might have already created in the Workload Identity Federation for GKE instructions.
Grant the required permissions to the service account:
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
Create and download a key for the service account:
gcloud iam service-accounts keys create gmp-test-sa-key.json \ --iam-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
Add the key file as a secret to your non-GKE cluster:
kubectl -n NAMESPACE_NAME create secret generic gmp-test-sa \ --from-file=key.json=gmp-test-sa-key.json
Open the OpenTelemetry Deployment resource for editing:
kubectl -n NAMESPACE_NAME edit deployment otel-collector
Add the text shown in bold to the resource:
apiVersion: apps/v1 kind: Deployment metadata: namespace: NAMESPACE_NAME name: otel-collector spec: template spec: containers: - name: otel-collector env: - name: "GOOGLE_APPLICATION_CREDENTIALS" value: "/gmp/key.json" ... volumeMounts: - name: gmp-sa mountPath: /gmp readOnly: true ... volumes: - name: gmp-sa secret: secretName: gmp-test-sa ...Save the file and close the editor. After the change is applied, the pods are re-created and start authenticating to the metric backend with the given service account.
Scrape Prometheus metrics
This section and the subsequent section provide additional customization information for using the OpenTelemetry Collector. This information might be helpful in certain situations, but none of it is necessary to run the example described in Set up the OpenTelemetry Collector.
If your applications are already exposing Prometheus endpoints, the OpenTelemetry Collector can scrape those endpoints using the same scrape config format you would use with any standard Prometheus config. To do this, enable the Prometheus receiver in your collector config.
A Prometheus receiver config for Kubernetes pods might look like the following:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
service:
pipelines:
metrics:
receivers: [prometheus]
This is a service discovery-based scrape config that you can modify as needed to scrape your applications.
When using an existing Prometheus configuration with the OpenTelemetry Collector's
prometheus receiver, replace any single dollar sign characters,
, with double characters, ,
to avoid triggering environment variable substitution. This is especially important to do for
the replacement
value within your relabel_configs section. For example, if you have the
following relabel_config section:
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $1:$2 target_label: __address__
Then rewrite it to be:
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $$1:$$2 target_label: __address__
For more information, see the OpenTelemetry documentation.
Next, we strongly recommend that you use processors to format your metrics. In many cases, processors must be used to properly format your metrics.
Add processors
OpenTelemetry processors modify telemetry data before it is exported. You can use the following processors to make sure that your metrics are written in a format compatible with Managed Service for Prometheus.
Detect resource attributes
The Managed Service for Prometheus exporter for OpenTelemetry uses the
prometheus_target monitored
resource
to uniquely identify time series data points. The exporter parses the required
monitored-resource fields from resource attributes on the metric data points.
The fields and the attributes from which the values are scraped are:
- project_id: auto-detected by Application Default
Credentials,
gcp.project.id, orprojectin exporter config (see configuring the exporter) - location:
location,cloud.availability_zone,cloud.region - cluster:
cluster,k8s.cluster_name - namespace:
namespace,k8s.namespace_name - job:
service.name+service.namespace - instance:
service.instance.id
Failure to set these labels to unique values can result in "duplicate timeseries" errors when exporting to Managed Service for Prometheus. In many cases, values can be automatically detected for these labels, but in some cases, you might have to map them yourself. The rest of this section describes these scenarios.
The Prometheus receiver automatically sets the service.name attribute
based on the job_name in the scrape config, and service.instance.id
attribute based on the scrape target's instance. The receiver also sets
k8s.namespace.name when using role: pod in the scrape config.
When possible, populate the other attributes automatically by using the resource detection processor. However, depending on your environment, some attributes might not be automatically detectable. In this case, you can use other processors to either manually insert these values or parse them from metric labels. The following sections illustrate configurations for detecting resources on various platforms.
GKE
When running OpenTelemetry on GKE, you need to enable the resource-detection processor to fill out the resource labels. Be sure that your metrics don't already contain any of the reserved resource labels. If this is unavoidable, see Avoid resource attribute collisions by renaming attributes.
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
This section can be copied directly into your config file, replacing the
processors section if it already exists.
Amazon EKS
The EKS resource detector does not automatically fill in the cluster or
namespace attributes. You can provide these values manually by using
the resource
processor,
as shown in the following example:
processors:
resourcedetection:
detectors: [eks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
You can also convert these values from metric labels using the groupbyattrs
processor (see move metric labels to resource labels below).
Azure AKS
The AKS resource detector does not automatically fill in the cluster or
namespace attributes. You can provide these values manually by using the
resource
processor,
as shown in the following example:
processors:
resourcedetection:
detectors: [aks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
You can also convert these values from metric labels by using the groupbyattrs
processor; see Move metric labels to resource labels.
On-premises and non-cloud environments
With on-premises or non-cloud environments, you probably can't detect any of the necessary resource attributes automatically. In this case, you can emit these labels in your metrics and move them to resource attributes (see Move metric labels to resource labels), or manually set all of the resource attributes as shown in the following example:
processors:
resource:
attributes:
- key: "cluster"
value: "my-on-prem-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
- key: "location"
value: "us-east-1"
action: upsert
Create your collector config as a ConfigMap describes how
to use the config. That section assumes you have put your config in a file
called config.yaml.
The project_id resource attribute can still be automatically set when running
the Collector with Application Default
Credentials.
If your Collector does not have access to Application Default Credentials, see
Setting project_id.
Alternatively, you can manually set the resource attributes you need in an
environment variable, OTEL_RESOURCE_ATTRIBUTES, with a comma-separated list of
key-value pairs, for example:
export OTEL_RESOURCE_ATTRIBUTES="cluster=my-cluster,namespace=my-app,location=us-east-1"
Then use the env resource detector
processor
to set the resource attributes:
processors:
resourcedetection:
detectors: [env]
Avoid resource attribute collisions by renaming attributes
If your metrics already contain labels that collide with the required
resource attributes (such as location, cluster, or namespace), rename them
to avoid the collision. The Prometheus convention is to add the prefix exported_
to the label name. To add this prefix, use the transform
processor.
The following processors config renames any potential collisions and
resolves any conflicting keys from the metric:
processors:
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
Move metric labels to resource labels
In some cases, your metrics might be intentionally reporting labels such as
namespace because your exporter is monitoring multiple namespaces. For
example, when running the
kube-state-metrics
exporter.
In this scenario, these labels can be moved to resource attributes using the groupbyattrs processor:
processors:
groupbyattrs:
keys:
- namespace
- cluster
- location
In the previous example, given a metric with the labels namespace, cluster,
or location, those labels will be converted to the matching resource
attributes.
Limit API requests and memory usage
Two other processors, the batch processor and memory limiter processor allow you to limit the resource consumption of your collector.
Batch processing
Batching requests lets you define how many data points to send in a single request. Note that Cloud Monitoring limit of 200 time series per request. Enable the batch processor by using the following settings:
processors:
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
Memory limiting
We recommend enabling the memory-limiter processor to prevent your collector from crashing at times of high throughput. Enable the processing by using the following settings:
processors:
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
Configure the googlemanagedprometheus exporter
By default, using the googlemanagedprometheus exporter on GKE
requires no additional configuration. For many use cases you only need to enable
it with an empty block in the exporters section:
exporters: googlemanagedprometheus:
However, the exporter does provide some optional configuration settings. The following sections describe the other configuration settings.
Setting project_id
To associate your time series with a Google Cloud project, the
prometheus_target monitored resource must have project_id set.
When running OpenTelemetry on Google Cloud, the Managed Service for Prometheus exporter defaults to setting this value based on the Application Default Credentials it finds. If no credentials are available, or you want to override the default project, you have two options:
- Set
projectin the exporter config - Add a
gcp.project.idresource attribute to your metrics.
We strongly recommend using the default (unset) value for project_id rather
than explicitly setting it, when possible.
Set project in the exporter config
The following config excerpt sends metrics to
Managed Service for Prometheus in the Google Cloud project MY_PROJECT:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
project: MY_PROJECT
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
The only change from previous examples is the new line project: MY_PROJECT.
This setting is useful if you know that every metric coming through this
Collector should be sent to MY_PROJECT.
Set gcp.project.id resource attribute
You can set project association on a per-metric basis by adding a
gcp.project.id resource attribute to your metrics. Set the value of the
attribute to the name of the project the metric should be associated with.
For example, if your metric already has a label project, this label can be
moved to a resource attribute and renamed to gcp.project.id by using
processors in the Collector config, as shown in the following example:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
groupbyattrs:
keys:
- project
resource:
attributes:
- key: "gcp.project.id"
from_attribute: "project"
action: upsert
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection, groupbyattrs, resource]
exporters: [googlemanagedprometheus]
Setting client options
The googlemanagedprometheus exporter uses gRPC clients for
Managed Service for Prometheus. Therefore, optional settings
are available for configuring the gRPC client:
compression: Enables gzip compression for gRPC requests, which is useful for minimizing data transfer fees when sending data from other clouds to Managed Service for Prometheus (valid values:gzip).user_agent: Overrides the user-agent string sent on requests to Cloud Monitoring; only applies to metrics. Defaults to the build and version number of your OpenTelemetry Collector, for example,opentelemetry-collector-contrib 0.128.0.endpoint: Sets the endpoint to which metric data is going to be sent.use_insecure: If true, uses gRPC as the communication transport. Has an effect only when theendpointvalue is not "".grpc_pool_size: Sets the size of the connection pool in the gRPC client.prefix: Configures the prefix of metrics sent to Managed Service for Prometheus. Defaults toprometheus.googleapis.com. Don't change this prefix; doing so causes metrics to not be queryable with PromQL in the Cloud Monitoring UI.
In most cases, you don't need to change these values from their defaults. However, you can change them to accommodate special circumstances.
All of these settings are set under a metric block in the
googlemanagedprometheus exporter section, as shown in the following example:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
metric:
compression: gzip
user_agent: opentelemetry-collector-contrib 0.128.0
endpoint: ""
use_insecure: false
grpc_pool_size: 1
prefix: prometheus.googleapis.com
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
What's next
- Use PromQL in Cloud Monitoring to query Prometheus metrics.
- Use Grafana to query Prometheus metrics.
- Set up the OpenTelemetry Collector as a sidecar agent in Cloud Run.
-
The Cloud Monitoring Metrics Management page provides information that can help you control the amount you spend on billable metrics without affecting observability. The Metrics Management page reports the following information:
- Ingestion volumes for both byte- and sample-based billing, across metric domains and for individual metrics.
- Data about labels and cardinality of metrics.
- Number of reads for each metric.
- Use of metrics in alerting policies and custom dashboards.
- Rate of metric-write errors.
You can also use the Metrics Management page to exclude unneeded metrics, eliminating the cost of ingesting them. For more information about the Metrics Management page, see View and manage metric usage.