Google Cloud Managed Service for Prometheus は、Prometheus 指標と OpenTelemetry 指標を扱うための Google Cloudのフルマネージド ソリューションであり、マルチクラウドの環境や複数のプロジェクトをまたいで利用できます。Prometheus を大規模に手動で管理、運用することなく、Prometheus と OpenTelemetry を使用してワークロードをグローバルにモニタリングし、アラートを送信できます。
Managed Service for Prometheus は、Prometheus エクスポータから指標を収集し、PromQL を使用したグローバルなデータクエリを可能にします。そのため、既存の Grafana ダッシュボード、PromQL ベースのアラート、ワークフローを引き続き使用できます。ハイブリッド クラウドとマルチクラウドに対応しており、Kubernetes、VM ワークロード、Cloud Run のサーバレス ワークロードをモニタリングできます。データは 24 か月間保持されます。また、アップストリームの Prometheus との互換性を維持するため、ポータビリティが維持されます。PromQL を使用すると Cloud Monitoring で 6,500 を超える無料の指標(無料の GKE システム指標など)をクエリし、Prometheus のモニタリングを補完することもできます。
このドキュメントでは、このマネージド サービスの概要と、サービスを設定して実行する方法について説明します。新機能とリリースに関する最新情報を定期的に受け取るには、登録フォームを送信してください(省略可)。
Home Depot が、Managed Service for Prometheus を使用して、オンプレミスの Kubernetes クラスタを実行している 2,200 のストア全体で統一されたオブザーバビリティを実現している方法をご覧ください。
システムの概要
Google Cloud Managed Service for Prometheus は、Cloud Monitoring のグローバル、マルチクラウド、クロス プロジェクト インフラストラクチャを基盤とし、Prometheus を使いやすくします。
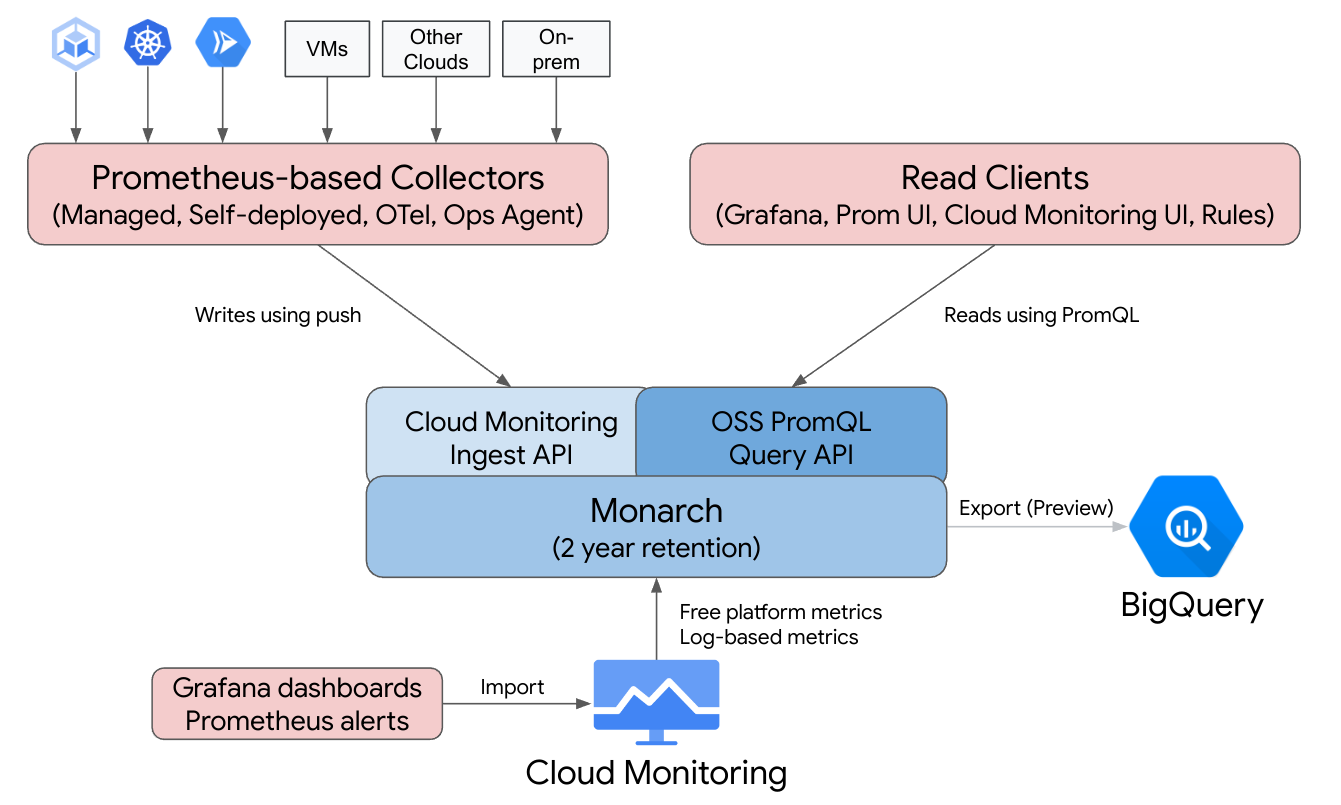
Managed Service for Prometheus は、Google 独自のモニタリングでも使用されているグローバルでスケーラブルなデータストアの Monarch 上に構築されています。Managed Service for Prometheus は、Cloud Monitoring と同じバックエンドと API を使用するため、Cloud Monitoring の指標と Managed Service for Prometheus が取り込んだ指標の両方を Cloud Monitoring の PromQL、Grafana または Prometheus API を読み取ることができる他のツールを使用してクエリできます。
標準の Prometheus のデプロイでは、データ収集、クエリの評価、ルールとアラートの評価、データ ストレージはすべて単一の Prometheus サーバー内で処理されます。Managed Service for Prometheus では、これらの機能を複数のコンポーネントに分担しています。
- データ収集は、マネージド コレクタ、セルフデプロイ コレクタ、OpenTelemetry Collector、または Ops エージェントによって処理されます。これらのコレクタは、ローカル エクスポータをスクレイピングして、収集したデータを Monarch に転送します。これらのコレクタは Kubernetes、サーバレス、従来の VM のワークロードに使用できるため、他のクラウドやオンプレミス デプロイメントなど、あらゆる環境で実行できます。
- クエリの評価は Monarch によって処理されます。Monarch は、すべての Google Cloudリージョンと最大 3,500 個のGoogle Cloud プロジェクトに対してクエリを実行し、結果を統合します。
- ルールとアラートの評価を処理するには、クラウドで完全に実行される PromQL アラートを Cloud Monitoring で作成するか、ローカルで構成されて実行されるルール エバリュエータ コンポーネントを使用します。このコンポーネントは、グローバル Monarch データストアに対してルールとアラートを実行し、発生したアラートを Prometheus AlertManager に転送します。
- データ ストレージは Monarch によって処理されます。Monarch は、すべての Prometheus データを 24 か月間、追加費用なしで保存します。
Grafana は、個々の Prometheus サーバーに接続するのではなく、グローバル Monarch データストアに接続します。すべてのデプロイメントで Managed Service for Prometheus コレクタが構成されている場合、この Grafana インスタンスにより、すべてのクラウドのすべての指標の統合ビューが提供されます。
データ収集
Managed Service for Prometheus では、マネージド データ収集、セルフデプロイのデータ収集、OpenTelemetry Collector または Ops エージェントの 4 つのいずれかのモードで使用できます。
Managed Service for Prometheus は、Kubernetes 環境でマネージド モードでデータを収集するオペレーターを提供します。データの収集はマネージド モードで行うことをおすすめします。これにより、Prometheus サーバーのデプロイ、スケーリング、シャーディング、構成、メンテナンスの複雑さがなくなります。マネージド収集は、GKE と GKE 以外の Kubernetes 環境でサポートされています。
セルフデプロイ収集では、Prometheus 環境を通常どおりユーザー自身で管理します。アップストリーム Prometheus との唯一の違いは、アップストリーム Prometheus バイナリではなく、Managed Service for Prometheus のバイナリを実行する点です。
OpenTelemetry Collector は、Prometheus エクスポータをスクレイピングし、Managed Service for Prometheus にデータを送信するために使用できます。OpenTelemetry では、すべてのシグナルに対して単一のエージェントを使用できます。その場合、1 つのコレクタを任意の環境の指標(Prometheus 指標を含む)、ログ、トレースに使用できます。
任意の Compute Engine インスタンスで、Prometheus の指標をスクレイピングしてグローバル データストアに送信するように Ops エージェントを構成できます。エージェントを使用すると、VM の検出が大幅に簡略化され、VM 環境で Prometheus のインストール、デプロイ、構成を行う必要がなくなります。
Prometheus 指標または OTLP 指標を書き込む Cloud Run サービスがある場合は、サイドカーと Managed Service for Prometheus を使用して、指標を Cloud Monitoring に送信できます。
- Cloud Run から Prometheus 指標を収集するには、Prometheus サイドカーを使用します。
- Cloud Run から OTLP 指標を収集するには、OpenTelemetry サイドカーを使用します。
マネージド コレクタ、セルフデプロイ コレクタ、OpenTelemetry コレクタは、オンプレミス デプロイと任意のクラウドで実行できます。 Google Cloudの外部で実行されるコレクタは、長期保存とグローバル クエリを行うために Monarch にデータを送信します。
収集オプションを選択する際は、次の点を考慮してください。
マネージド モードでの収集:
- すべての Kubernetes 環境で Google が推奨するアプローチです。
- GKE UI、gcloud CLI、
kubectlCLI、または Terraform を使用してデプロイします。 - スクレイピング構成の生成、取り込みのスケーリング、適切なデータに対するルールのスコープ設定など、Prometheus のオペレーションは Kubernetes オペレーターによってすべて処理されます。
- スクレイピングとルールは、軽量のカスタム リソース(CR)を使用して構成されます。
- 簡単に使用できるフルマネージド環境が必要な場合に適しています。
- prometheus-operator 構成ファイルから簡単に移行できます。
- 現在の Prometheus のユースケースのほとんどに対応しています。
- Google Cloud テクニカル サポートによる完全なサポート。
セルフデプロイ モードでの収集:
- アップストリーム Prometheus バイナリの代わりに簡単に使用できます。
- prometheus-operator や手動デプロイなど、任意のデプロイ メカニズムを使用できます。
- スクレイピングは、アノテーションや prometheus-operator などの任意の方法を使用して構成します。
- スケーリングと機能的シャーディングは手動で行います。
- 既存の複雑な設定に迅速に統合する場合に適しています。既存の構成ファイルを再利用し、アップストリーム Prometheus と Managed Service for Prometheus を並べて実行できます。
- ルールとアラートは通常、個々の Prometheus サーバー内で実行されます。ローカルルールの評価ではネットワーク トラフィックが発生しないため、エッジへのデプロイではこれが望ましい場合があります。
- カーディナリティを減らすためのローカル集計など、マネージド モードの収集でまだ未対応のロングテール ユースケースがサポートされている可能性があります。
- Google Cloud テクニカル サポートによる限定的なサポート。
OpenTelemetry Collector:
- 任意の環境から指標(Prometheus 指標を含む)を収集し、互換性のあるバックエンドに送信できる単一のコレクタ。また、ログとトレースを収集し、Cloud Logging や Cloud Trace などの互換性のあるバックエンドに送信するために使用できます。
- 手動または Terraform を使用して任意のコンピューティング環境または Kubernetes 環境にデプロイされます。Cloud Run などのステートレス環境から指標を送信するために使用できます。
- スクレイピングは、コレクタの Prometheus レシーバーで Prometheus に似た構成ファイルを使用して構成されます。
- push ベースの指標収集パターンをサポートします。
- メタデータは、リソース検出プロセッサを使用して任意のクラウドから挿入されます。
- ルールとアラートは、Cloud Monitoring アラート ポリシーまたはスタンドアロンのルール エバリュエータを使用して実行できます。
- クロスシグナルのワークフローや例(例)を最大限サポートします。
- Google Cloud テクニカル サポートによる限定的なサポート。
Ops エージェント:
- Compute Engine 環境(Linux と Windows 両方を含む)から発生する Prometheus 指標データを収集して送信する最も簡単な方法です。
- gcloud CLI、Compute Engine UI、または Terraform を使用してデプロイされます。
- スクレイピングは、エージェントの Prometheus レシーバーの構成ファイルのように Prometheus を使用して構成されます。これは OpenTelemetry を利用します。
- ルールとアラートは、Cloud Monitoring またはスタンドアロンのルール エバリュエータを使用して実行できます。
- オプションの Logging エージェントとプロセス指標がバンドルされています。
- Google Cloud テクニカル サポートによる完全なサポート。
ご利用にあたっては、マネージド・データ コレクションを使ってみる、セルフデプロイ コレクションを使ってみる、OpenTelemetry Collector を使ってみる、または Ops エージェントを使ってみるをご覧ください。
Google Kubernetes Engine または Google Cloudの外部でマネージド サービスを使用する場合は、追加の構成が必要になることがあります。 Google Cloudの外部でマネージド コレクションを実行する、Google Cloudの外部でセルフデプロイ コレクションを実行する、または OpenTelemetry プロセッサを追加するをご覧ください。
クエリの評価
Managed Service for Prometheus は、Grafana や Cloud Monitoring UI など、Prometheus Query API を呼び出すことができるすべてのクエリ UI をサポートしています。ローカルの Prometheus から Managed Service for Prometheus に切り替えると、既存の Grafana ダッシュボードは引き続き機能します。また、一般的なオープンソース リポジトリやコミュニティ フォーラムにある PromQL を引き続き使用できます。
PromQL を使用すると、Managed Service for Prometheus にデータを送信しなくても、Cloud Monitoring で 6,500 以上の無料の指標をクエリできます。PromQL を使用して、無料の Kubernetes 指標、カスタム指標、ログベースの指標をクエリすることもできます。
Managed Service for Prometheus データをクエリするように Grafana を構成する方法については、Grafana を使用したクエリをご覧ください。
PromQL を使用して Cloud Monitoring の指標をクエリする方法については、Cloud Monitoring での PromQL をご覧ください。
ルールとアラートの評価
Managed Service for Prometheus は、完全なクラウドベースのアラート パイプラインとスタンドアロンのルール エバリュエータの両方を提供します。どちらも指標スコープでアクセス可能なすべての Monarch データに対してルールを評価します。マルチ プロジェクト指標のスコープに対してルールを評価することで、対象となるすべてのデータを単一の Prometheus サーバーまたは単一の Google Cloud プロジェクト内に併置する必要がなくなり、プロジェクトのグループに対して IAM 権限を設定できます。
すべてのルール評価オプションは標準の Prometheus rule_files 形式を受け入れるため、既存のルールをコピーして貼り付けるか、一般的なオープンソース リポジトリで見つかったルールをコピーして貼り付けることで、Managed Service for Prometheus に簡単に移行できます。セルフデプロイ コレクタを使用している場合は、引き続きローカルでコレクタの記録ルールを評価できます。記録ルールとアラートルールの結果は、直接収集される指標データと同じように Monarch に保存されます。Prometheus のアラートルールを Cloud Monitoring の PromQL ベースのアラート ポリシーに移行することもできます。
Cloud Monitoring でのアラート評価については、Cloud Monitoring の PromQL アラートをご覧ください。
マネージド収集を使用したルール評価については、マネージド ルールの評価とアラートをご覧ください。
セルフデプロイ コレクション、OpenTelemetry Collector、Ops エージェントを使用したルール評価については、セルフデプロイのルール評価とアラートをご覧ください。
セルフデプロイ コレクタで記録ルールを使用してカーディナリティを減らす方法については、コスト管理とアトリビューションをご覧ください。
データ ストレージ
すべての Managed Service for Prometheus データは 24 か月間保管されます。追加料金はかかりません。
Managed Service for Prometheus は、5 秒の最小取得間隔をサポートしています。データは 1 週間そのままの状態で保存され、次の 5 週間は 1 分間のポイントにダウンサンプリングされます。残りの保持期間は 10 分間のポイントにダウンサンプリングされて保存されます。
Managed Service for Prometheus では、アクティブな時系列数または時系列の合計数に上限はありません。
詳細については、Cloud Monitoring のドキュメントの割り当てと上限をご覧ください。
課金と割り当て
Managed Service for Prometheus は Google Cloud プロダクトであり、課金と使用量の割り当てが適用されます。
課金
このサービスの課金は、主にストレージに取り込まれた指標サンプルの数に基づいて行われます。また、読み取り API 呼び出しにも少額の料金が発生します。Managed Service for Prometheus では、指標データの保存または保持に課金されません。
- 現在の料金については、Google Cloud Observability の料金ページの Cloud Monitoring セクションをご覧ください。
- 予想される時系列数または 1 秒あたりの推定サンプル数に基づいて請求額を見積もるには、Google Cloud 料金計算ツールの [Cloud Operations] タブをご覧ください。
- 請求額の削減方法や、請求額が高額になる原因を特定する方法については、費用管理とアトリビューションをご覧ください。
- 料金モデルの根拠については、Google Cloud Managed Service for Prometheus の費用を最適化するをご覧ください。
- 料金の例については、取り込まれたサンプル数で課金される指標データをご覧ください。
割り当て
Managed Service for Prometheus は、取り込みと読み取りの割り当てを Cloud Monitoring と共有します。取り込みのデフォルトの割り当てはプロジェクトあたり 500 QPS です。1 回の呼び出しで最大 200 のサンプルを取得できます。これは 1 秒あたり 100,000 のサンプルに相当します。読み取りのデフォルトの割り当ては、指標スコープごとに 100 QPS です。
指標とクエリ ボリュームをサポートするために、これらの割り当てを増やすことができます。割り当ての管理と割り当ての増加リクエストについては、割り当ての操作をご覧ください。
利用規約とコンプライアンス
Managed Service for Prometheus は Cloud Monitoring の一部であるため、以下のような特定の規約と認定を Cloud Monitoring から継承します(ただし、以下に限定されるものではありません)。
- Google Cloud 利用規約
- オペレーション サービスレベル契約(SLA)
- US DISA と FedRAMP のコンプライアンス レベル
- VPC-SC(VPC Service Controls)のサポート
次のステップ
- マネージド コレクションを使ってみる。
- セルフデプロイ コレクションを使ってみる。
- OpenTelemetry Collector を使ってみる
- Ops エージェントを使ってみる。
- Cloud Monitoring で PromQL を使用して Prometheus 指標をクエリする。
- Grafana を使用して Prometheus 指標をクエリする。
- PromQL を使用して Cloud Monitoring の指標をクエリする。
- ベスト プラクティスを確認し、アーキテクチャの図を確認する。