Google Cloud Managed Service for Prometheus では、Cloud Monitoring に取り込まれたサンプル数と、Monitoring API への読み取りリクエストに対して課金されます。費用の主な要因は、取り込まれたサンプル数です。
このドキュメントでは、指標の取り込みに関連する費用を制御する方法と、大量の取り込みの原因を特定する方法について説明します。
Managed Service for Prometheus の料金の詳細については、Google Cloud Observability の料金ページの Cloud Monitoring セクションをご覧ください。
請求額を確認する
Google Cloud の請求額を確認するには、次の手順で操作します。
Google Cloud コンソールで [お支払い] ページに移動します。
請求先アカウントが複数ある場合は、[リンクされた請求先アカウントに移動] を選択して、現行プロジェクトの請求先アカウントを表示します。別の請求先アカウントを確認するには、[請求先アカウントを管理] を選択し、使用状況レポートを取得する対象のアカウントを選択します。
[お支払い] ナビゲーション メニューの [費用管理] セクションで、[レポート] を選択します。
[サービス] メニューから [Cloud Monitoring] オプションを選択します。
[SKU] メニューから、次のオプションを選択します。
- Prometheus サンプルの取り込み
- Monitoring API のリクエスト
次のスクリーンショットは、1 つのプロジェクトの Managed Service for Prometheus の請求レポートを示しています。
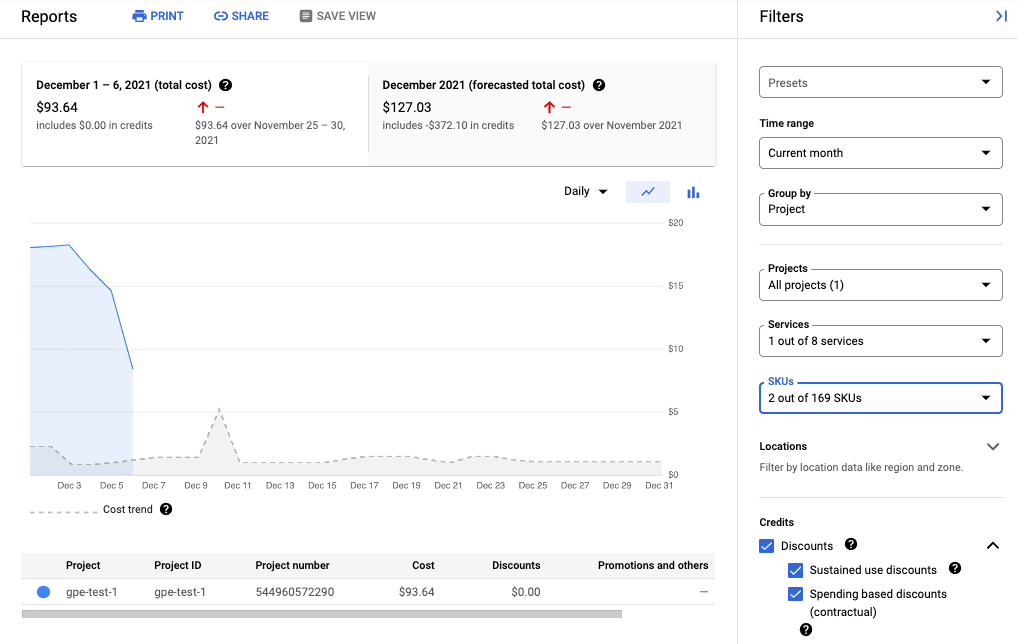
費用を抑制する
Managed Service for Prometheus の使用に関連するコストを抑制するには、次のことを行います。
- 生成した指標データをフィルタすることで、マネージド サービスに送信する時系列の数を減らす。
- 収集間隔を変更して、収集するサンプルの数を減らす。
- カーディナリティの高い指標が誤って構成されているサンプルの数を制限する。
時系列の数を抑制する
オープンソースの Prometheus ドキュメントでは、指標の量をフィルタすることを推奨することはほとんどありません。これは、コストがマシンコストによって制限される場合には妥当な方法です。ただし、マネージド サービス プロバイダに単位ベースで支払っている場合、無制限にデータが送信されると、不必要に請求額が高くなる可能性があります。
kube-prometheus プロジェクトに含まれるエクスポータ(特に kube-state-metrics サービス)が大量の指標データを出力する場合があります。たとえば、kube-state-metrics サービスは数百の指標を出力しますが、その多くはユーザーにとってまったく価値のないものです。kube-prometheus プロジェクトを使用する最新の 3 ノードクラスタは、Managed Service for Prometheus に毎秒約 900 のサンプルを送信します。無関係な指標をフィルタリングしても、請求が適切なレベルに減るだけかもしれません。
指標の数を減らすには、次の操作を行います。
- 収集するターゲット数を少なくするように、収集の構成を変更する。
- 収集した指標を次のようにフィルタリングする。
- マネージド コレクションを使用する場合は、エクスポートした指標をフィルタリングする。
- セルフデプロイ コレクションを使用する場合は、エクスポートした指標をフィルタリングする。
kube-state-metrics サービスを使用している場合は、keep アクションで Prometheus のラベル変更ルールを追加できます。マネージド コレクションの場合、このルールは PodMonitoring または ClusterPodMonitoring の定義に含まれます。セルフデプロイ コレクションの場合、このルールは Prometheus 収集スクレイピング構成または ServiceMonitor 定義(prometheus-operator の場合)に含まれます。
たとえば、新しい 3 ノードクラスタに対して次のフィルタを使用すると、サンプル量が 1 秒あたり約 125 サンプル削減されます。
metricRelabeling:
- action: keep
regex: kube_(daemonset|deployment|pod|namespace|node|statefulset|persistentvolume|horizontalpodautoscaler)_.+
sourceLabels: [__name__]
前のフィルタでは、正規表現を使用して、指標の名前に基づいて保持する指標を指定しています。たとえば、名前が kube_daemonset_ で始まる指標は保持されます。drop のアクションを指定して、正規表現に一致する指標を除外することもできます。
エクスポータのすべてが重要とは限りません。たとえば、kube-prometheus パッケージは次のサービス モニターをデフォルトでインストールしますが、その多くはマネージド環境で不要です。
alertmanagercorednsgrafanakube-apiserverkube-controller-managerkube-schedulerkube-state-metricskubeletnode-exporterprometheusprometheus-adapterprometheus-operator
エクスポートする指標の数を減らすには、不要なサービス モニタリングの収集の削除、無効化、停止を行います。たとえば、新しい 3 ノードクラスタで kube-apiserver サービス モニタリングを無効にすると、サンプル量は 1 秒あたり約 200 サンプル削減されます。
収集されるサンプル数を抑制する
Managed Service for Prometheus では、サンプル単位で課金されます。サンプリング期間を長くすることで、取り込むサンプル数を減らすことができます。次に例を示します。
- サンプリング期間を 10 秒から 30 秒に変更すると、情報はほぼ失われることなく、サンプル量を 66% 削減できます。
- サンプリング期間を 10 秒から 60 秒に変更すると、サンプル量を 83% 削減できます。
サンプルのカウント方法とサンプリング期間がサンプル数に与える影響については、取り込まれたサンプル数で課金される指標データをご覧ください。
収集間隔は通常、ジョブ単位またはターゲット単位で設定できます。
マネージド コレクションの場合、interval フィールドを使用して、PodMonitoring リソースで収集間隔を設定します。セルフデプロイ コレクションの場合、スクレイピング構成でサンプリング間隔を設定し、通常 interval または scrape_interval フィールドを設定します。
ローカル集計を構成する(セルフデプロイ コレクションのみ)
セルフデプロイ コレクション(kube-prometheus や prometheus-operator など)を使用するか、イメージを手動でデプロイしてサービスを構成する場合は、カーディナリティの高い指標をローカルで集計して、Managed Service for Prometheus に送信されるサンプル数を減らすことができます。記録ルールを使用すると、instance などのラベルを集約できます。また、--export.match フラグまたは EXTRA_ARGS 環境変数を使用すると、集計データのみを Monarch に送信できます。
たとえば、high_cardinality_metric_1、high_cardinality_metric_2、low_cardinality_metric の 3 つの指標があるとします。元のデータをすべてローカルに残しながら(アラート目的など)、high_cardinality_metric_1 に送信されるサンプル数を減らし、high_cardinality_metric_2 に送信されるサンプルをすべて除外できます。次のように設定します。
- Managed Service for Prometheus イメージをデプロイします。
- すべての元データをローカル サーバーにスクレイピングするように、スクレイピングを構成します(必要な数のフィルタを使用します)。
high_cardinality_metric_1とhigh_cardinality_metric_2でローカル集計を行うように記録ルールを構成します。たとえば、不要な時系列の数が最も少なくなるように、instanceラベルまたは任意の数の指標ラベルを集計します。次のようなルールを実行すると、instanceラベルが除外され、残りのラベルに対して時系列が集計されます。record: job:high_cardinality_metric_1:sum expr: sum without (instance) (high_cardinality_metric_1)
その他の集計オプションについては、Prometheus ドキュメントの集計演算子をご覧ください。
Managed Service for Prometheus イメージをデプロイするには、次のフィルタフラグを使用します。これにより、指定した指標の生データが Monarch に送信されるのを防ぐことができます。
--export.match='{__name__!="high_cardinality_metric_1",__name__!="high_cardinality_metric_2"}'この
export.matchフラグの例では、カンマ区切りのセレクタと!=演算子を使用して、不要な元データを除外しています。カーディナリティの高い指標を集計する記録ルールを追加した場合は、元データが破棄されるように、フィルタに新しい__name__セレクタを追加する必要があります。複数のセレクタを含む 1 つのフラグを!=演算子とともに使用して不要なデータを除外すると、スクレイピング構成の変更または追加を行うときではなく、新しい集計を作成する場合にのみフィルタの変更が必要になります。prometheus-operator などの特定のデプロイ方法では、角かっこを囲む単一引用符の省略が必要になる場合があります。
このワークフローでは、記録ルールと export.match フラグの作成や管理で運用上のオーバーヘッドが発生する可能性がありますが、カーディナリティが非常に高い指標にのみ焦点を合わせることで、量を大幅に削減できる可能性があります。ローカルでの事前集計によるメリットが特に大きい指標を特定する方法については、大量の指標を特定するをご覧ください。
Managed Service for Prometheus を使用する場合は、連携を実装しないでください。自己デプロイ型の単一の Prometheus サーバーは、必要に応じてクラスタレベルの集約を行うため、このワークフローではフェデレーション サーバーを使用しません。連携によって、「unknown」タイプの指標や 2 倍の取り込み量など、予期しない影響が生じる可能性があります。
カーディナリティの高い指標のサンプルを制限する(セルフデプロイ コレクションのみ)
ユーザー ID や IP アドレスなど、取り得る値が多数あるラベルを追加することで、カーディナリティの非常に高い指標を作成できます。このような指標では、非常に多くのサンプルが生成されます。通常、ラベルの値が多い場合は構成に誤りがあります。収集構成で sample_limit 値を設定することで、セルフデプロイ コレクタでカーディナリティの高い指標を防止できます。
この上限を使用する場合は、明らかに誤って構成した指標のみが取得されるように、非常に高い値に設定することをおすすめします。上限を超えたサンプルは破棄されるため、上限を超えたことが原因で発生する問題を診断することが困難な場合があります。
サンプルの上限の使用は、サンプル取り込みの管理には適しませんが、誤った構成を防止できます。詳しくは、sample_limit を使用して過負荷を避けるをご覧ください。
コストの特定と関連付け
Cloud Monitoring を使用すると、最も多くのサンプルを書き込んでいる Prometheus 指標を特定できます。これらの指標は費用に大きく影響します。最もコストの高い指標を特定したら、取得構成を変更して、それらの指標を適切にフィルタリングできます。
Cloud Monitoring の [指標の管理] ページでは、オブザーバビリティに影響を与えることなく、課金対象の指標に費やす金額を制御するために役立つ情報が提供されます。[指標の管理] ページには、次の情報が表示されます。
- 指標ドメイン全体と個々の指標での、バイトベースとサンプルベースの両方の課金に対する取り込み量。
- 指標のラベルとカーディナリティに関するデータ。
- 各指標の読み取り回数。
- アラート ポリシーとカスタム ダッシュボードでの指標の使用。
- 指標書き込みエラーの割合。
[指標の管理] ページで不要な指標を除外し、取り込みの費用を削減することもできます。
[指標の管理] ページを表示するには、次の操作を行います。
-
Google Cloud コンソールで、[ 指標の管理] ページに移動します。
検索バーを使用してこのページを検索する場合は、小見出しが「Monitoring」の結果を選択します。
- ツールバーで時間枠を選択します。デフォルトでは、[指標の管理] ページには、過去 1 日間に収集された指標に関する情報が表示されます。
[指標の管理] ページの詳細については、指標の使用状況の表示と管理をご覧ください。
以下のセクションでは、Managed Service for Prometheus に送信するサンプルの数を分析し、大量の指標を特定の指標、Kubernetes Namespace、 Google Cloud リージョンに関連付ける方法について説明します。
大量の指標を特定する
取り込み量が最も大きい Prometheus 指標を特定する方法は次のとおりです。
-
Google Cloud コンソールで、[ 指標の管理] ページに移動します。
検索バーを使用してこのページを検索する場合は、小見出しが [Monitoring] の結果を選択します。
- [取り込まれた課金対象のサンプル数] スコアカードで、[グラフを表示] をクリックします。
- [名前空間ボリュームの取り込み] グラフを探して、more_vert [その他のグラフ オプション] をクリックします。
- グラフ オプション [Metrics Explorer で表示する] を選択します。
- Metrics Explorer の [Builder] ペインで、次のようにフィールドを変更します。
- [指標] フィールドで、次のリソースと指標が選択されていることを確認します。
Metric Ingestion Attribution、Samples written by attribution id。 - [集計] フィールドで、[
sum] を選択します。 - [条件] フィールドで、次のラベルを選択します。
attribution_dimensionmetric_type
- [フィルタ] フィールドには [
attribution_dimension = namespace] を使用します。これは、attribution_dimensionラベルで集計した後に行う必要があります。
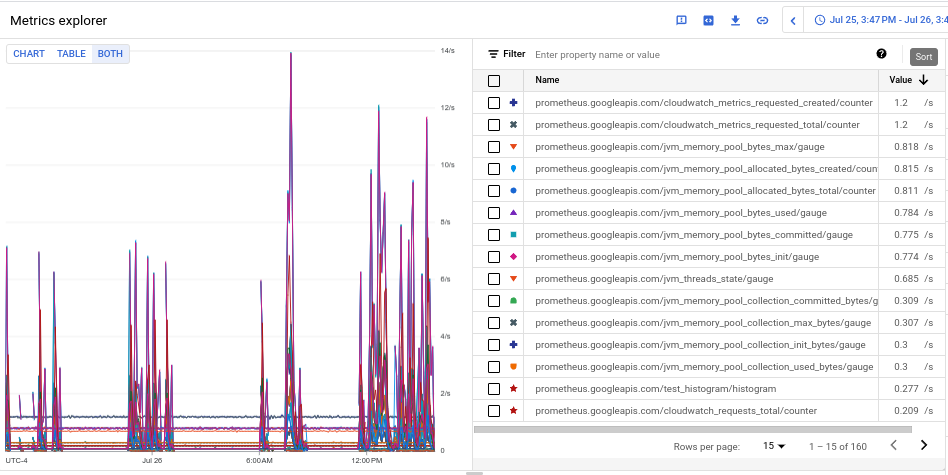
結果のグラフには、指標タイプごとに取り込み量が表示されます。
- [指標] フィールドで、次のリソースと指標が選択されていることを確認します。
- 各指標の取り込み量を確認するには、[Chart Table Both] の切り替えボタンで、[Both] を選択します。このテーブルの [Value] 列には、各指標の取り込み量が表示されます。
- [Value] 列のヘッダーを 2 回クリックして、取り込み量の降順で指標を並べ替えます。
結果のグラフには、次のスクリーンショットのように、平均で上位の指標が表示されます。
大量の指標が生成されている名前空間を特定する
取り込み量を特定の Kubernetes Namespace に関連付けるには、次のようにします。
-
Google Cloud コンソールで、[ 指標の管理] ページに移動します。
検索バーを使用してこのページを検索する場合は、小見出しが [Monitoring] の結果を選択します。
- [取り込まれた課金対象のサンプル数] スコアカードで、[グラフを表示] をクリックします。
- [名前空間ボリュームの取り込み] グラフを探して、more_vert [その他のグラフ オプション] をクリックします。
- グラフ オプション [Metrics Explorer で表示する] を選択します。
- Metrics Explorer の [Builder] ペインで、次のようにフィールドを変更します。
- [指標] フィールドで、次のリソースと指標が選択されていることを確認します。
Metric Ingestion Attribution、Samples written by attribution id。 - 必要に応じて残りのクエリ パラメータを構成します。
- 取り込み量全体と Namespace を関連付けるには:
- [集計] フィールドで、[
sum] を選択します。 - [条件] フィールドで、次のラベルを選択します。
attribution_dimensionattribution_id
- [フィルタ] フィールドには [
attribution_dimension = namespace] を使用します。
- [集計] フィールドで、[
- 個々の指標の取り込み量を Namespace に関連付けるには:
- [集計] フィールドで、[
sum] を選択します。 - [条件] フィールドで、次のラベルを選択します。
attribution_dimensionattribution_idmetric_type
- [フィルタ] フィールドには [
attribution_dimension = namespace] を使用します。
- [集計] フィールドで、[
- 特定の大量の指標の要因になっている Namespace を特定するには:
- 他の指標の例を使用して、大量の指標が発生している指標タイプを特定します。テーブルビューで、指標タイプは
prometheus.googleapis.com/で始まる文字列です。詳細については、大量の指標を特定するをご覧ください。 - 識別された指標タイプにグラフデータを制限するには、[フィルタ] フィールドに指標タイプのフィルタを追加します。例:
metric_type= prometheus.googleapis.com/container_tasks_state/gauge - [集計] フィールドで、[
sum] を選択します。 - [条件] フィールドで、次のラベルを選択します。
attribution_dimensionattribution_id
- [フィルタ] フィールドには [
attribution_dimension = namespace] を使用します。
- 他の指標の例を使用して、大量の指標が発生している指標タイプを特定します。テーブルビューで、指標タイプは
- Google Cloud リージョン別の取り込みを確認するには、[条件] フィールドに
locationラベルを追加します。 - Google Cloud プロジェクト別の取り込みを確認するには、[条件] フィールドに
resource_containerラベルを追加します。
- 取り込み量全体と Namespace を関連付けるには:
- [指標] フィールドで、次のリソースと指標が選択されていることを確認します。