このドキュメントでは、OpenTelemetry Collector を設定して標準の Prometheus 指標をスクレイピングし、それらの指標を Google Cloud Managed Service for Prometheus に報告する方法について説明します。OpenTelemetry Collector は、自身でデプロイし、Managed Service for Prometheus にエクスポートするように構成できるエージェントです。この設定は、セルフデプロイ モードでの収集で Managed Service for Prometheus を実行する場合と似ています。
セルフデプロイ モードでの収集よりも OpenTelemetry Collector を優先的に選択する理由としては、次のようなものがあります。
- OpenTelemetry Collector を使用すると、パイプラインで異なるエクスポータを構成して、テレメトリー データを複数のバックエンドに転送できます。
- Collector は指標、ログ、トレースからのシグナルもサポートしているため、1 つのエージェントで 3 つのシグナルタイプをすべて処理できます。
- OpenTelemetry のベンダーに依存しないデータ形式(OpenTelemetry Protocol、OTLP)は、ライブラリとのプラグインに対応する Collector コンポーネントの強力なエコシステムをサポートしています。これにより、データを受信、処理、エクスポートするためのさまざまなカスタマイズ オプションを利用できます。
このような利点はありますが、OpenTelemetry Collector を実行するには、セルフマネージド型のデプロイメントとメンテナンスのアプローチが必要になります。どの方法を選択するかは特定のニーズによって異なります。このドキュメントでは、Managed Service for Prometheus をバックエンドとして使用し、OpenTelemetry Collector を構成する際に推奨されるガイドラインについて説明します。
始める前に
このセクションでは、このドキュメントで説明するタスクに必要な構成について説明します。
プロジェクトとツールを設定する
Google Cloud Managed Service for Prometheus を使用するには、次のリソースが必要です。
Cloud Monitoring API が有効になっている Google Cloud プロジェクト。
Google Cloud プロジェクトが存在しない場合は、次の操作を行います。
Google Cloud コンソールで、[新しいプロジェクト] に移動します。
[プロジェクト名] フィールドにプロジェクトの名前を入力して、[作成] をクリックします。
[お支払い] に移動します。
作成したプロジェクトをまだ選択していない場合は、ページ上部でプロジェクトを選択します。
既存のお支払いプロファイルを選択するか、新しいお支払いプロファイルを作成するように求められます。
新しいプロジェクトでは、Monitoring API がデフォルトで有効になっています。
Google Cloud プロジェクトがすでに存在する場合は、Monitoring API が有効になっていることを確認します。
[API とサービス] に移動します。
プロジェクトを選択します。
[API とサービスの有効化] をクリックします。
「Monitoring」を検索します。
検索結果で、[Cloud Monitoring API] をクリックします。
[API が有効です] と表示されていない場合は、[有効にする] をクリックします。
Kubernetes クラスタ。Kubernetes クラスタがない場合は、GKE のクイックスタートの手順を行います。
また、次のコマンドライン ツールも必要です。
gcloudkubectl
gcloud ツールと kubectl ツールは Google Cloud CLI に含まれています。インストールの詳細については、Google Cloud CLI コンポーネントの管理をご覧ください。インストールされている gcloud CLI コンポーネントを確認するには、次のコマンドを実行します。
gcloud components list
環境を構成する
プロジェクト ID またはクラスタ名を繰り返し入力しないようにするには、次の構成を行います。
コマンドライン ツールを次のように構成します。
Google Cloud プロジェクトの ID を参照するように gcloud CLI を構成します。
gcloud config set project PROJECT_ID
クラスタを使用するように
kubectlCLI を構成します。kubectl config set-cluster CLUSTER_NAME
これらのツールの詳細については、以下をご覧ください。
名前空間を設定する
サンプル アプリケーションの一部として作成するリソースに NAMESPACE_NAME Kubernetes Namespace を作成します。
kubectl create ns NAMESPACE_NAME
サービス アカウントの認証情報を確認する
Kubernetes クラスタで Workload Identity Federation for GKE が有効になっている場合は、このセクションをスキップできます。
GKE で実行すると、Managed Service for Prometheus は Compute Engine のデフォルトのサービス アカウントに基づいて環境から認証情報を自動的に取得します。デフォルトのサービス アカウントには、必要な権限である monitoring.metricWriter と monitoring.viewer がデフォルトで付与されています。Workload Identity Federation for GKE を使用しておらず、以前にいずれかのロールをデフォルトのノードサービス アカウントから削除している場合は、続行する前に、不足している権限を再度追加する必要があります。
Workload Identity Federation for GKE 用のサービス アカウントを構成する
Kubernetes クラスタで Workload Identity Federation for GKE が有効になっていない場合は、このセクションをスキップできます。
Managed Service for Prometheus は、Cloud Monitoring API を使用して指標データをキャプチャします。クラスタで Workload Identity Federation for GKE を使用している場合は、Kubernetes サービス アカウントに Monitoring API の権限を付与する必要があります。このセクションでは、次のことを説明します。
- 専用の Google Cloud サービス アカウント
gmp-test-saを作成する。 - テスト用の名前空間
NAMESPACE_NAMEのデフォルトの Kubernetes サービス アカウントに Google Cloud サービス アカウントをバインドする。 - 必要な権限を Google Cloud サービス アカウントに付与する。
サービス アカウントを作成してバインドする
この手順は、Managed Service for Prometheus のドキュメントの複数の場所で説明されています。前のタスクですでに行っている場合は、この手順を繰り返す必要はありません。サービス アカウントを承認するに進んでください。
次のコマンド シーケンスでは、gmp-test-sa サービス アカウントを作成し、NAMESPACE_NAME 名前空間でデフォルトの Kubernetes サービス アカウントにバインドします。
gcloud config set project PROJECT_ID \ && gcloud iam service-accounts create gmp-test-sa \ && gcloud iam service-accounts add-iam-policy-binding \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:PROJECT_ID.svc.id.goog[NAMESPACE_NAME/default]" \ gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ && kubectl annotate serviceaccount \ --namespace NAMESPACE_NAME \ default \ iam.gke.io/gcp-service-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
別の GKE 名前空間またはサービス アカウントを使用している場合は、コマンドを適宜調整してください。
サービス アカウントを承認する
ロールには関連する権限がまとめられています。このロールをプリンシパル(この例では Google Cloudサービス アカウント)に付与します。Monitoring のロールの詳細については、アクセス制御をご覧ください。
次のコマンドを実行すると、 Google Cloud サービス アカウント gmp-test-sa に、指標データの読み取りと書き込みに必要な Monitoring API のロールが付与されます。
前のタスクで Google Cloud サービス アカウントに特定のロールを付与している場合は、再度付与する必要はありません。
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
Workload Identity Federation for GKE の構成をデバッグする
Workload Identity Federation for GKE の動作に問題がある場合は、Workload Identity Federation for GKE の設定の確認と Workload Identity Federation for GKE のトラブルシューティング ガイドをご覧ください。
Workload Identity Federation for GKE の構成で最も一般的なエラーの原因は入力ミスや、部分的なコピー / 貼り付けです。これらの手順のコードサンプルに埋め込まれた編集可能な変数と、クリック可能なコピー / 貼り付けアイコンを使用することを強くおすすめします。
本番環境での Workload Identity Federation for GKE
このドキュメントの例では、 Google Cloud サービス アカウントをデフォルトの Kubernetes サービス アカウントにバインドし、Monitoring API を使用するために必要なすべての権限を Google Cloudサービス アカウントに付与しています。
本番環境では、各コンポーネントのサービス アカウントを最小権限で使用し、よりきめ細かいアプローチを使用する必要があります。Workload Identity 管理のサービス アカウントを構成する詳細については、Workload Identity Federation for GKE の使用をご覧ください。
OpenTelemetry Collector を設定する
このセクションでは、OpenTelemetry Collector を設定して使用し、サンプル アプリケーションから指標をスクレイピングして、データを Google Cloud Managed Service for Prometheus に送信する方法について説明します。詳細な構成情報については、次のセクションをご覧ください。
OpenTelemetry Collector は Managed Service for Prometheus エージェント バイナリに似ています。OpenTelemetry コミュニティでは、ソースコード、バイナリ、コンテナ イメージなどのリリースが定期的に公開されています。
これらのアーティファクトは、ベスト プラクティスのデフォルトを使用して VM または Kubernetes クラスタにデプロイできます。また、コレクタ ビルダーを使用して、必要なコンポーネントのみで構成される独自のコレクタを構築することもできます。Managed Service for Prometheus で使用するコレクタを構築するには、次のコンポーネントが必要です。
- Managed Service for Prometheus エクスポータ。Managed Service for Prometheus に指標を書き込みます。
- 指標をスクレイピングするレシーバー。このドキュメントでは、OpenTelemetry Prometheus レシーバーを使用していることを前提としていますが、Managed Service for Prometheus エクスポータは任意の OpenTelemetry 指標レシーバーと互換性があります。
- プロセッサ。指標をバッチ処理してマークアップして、環境に応じて重要なリソースの ID を含めます。
これらのコンポーネントを有効にするには、構成ファイルを使用します(このファイルを --config フラグで Collector に渡します)。
以降のセクションで、これらの各コンポーネントを構成する方法について詳しく説明します。このドキュメントでは、GKE とその他の場所でコレクタを実行する方法について説明します。
Collector を構成してデプロイする
コレクションを Google Cloud で実行しているか、別の環境で実行しているかにかかわらず、OpenTelemetry Collector を Managed Service for Prometheus にエクスポートするように構成できます。最も大きな違いは Collector の構成にあります。Google Cloud 以外の環境では、Managed Service for Prometheus との互換性を維持するために、指標データに追加のフォーマットが必要になることがあります。ただし Google Cloudでは、このフォーマットの多くが Collector によって自動的に検出されます。
GKE で OpenTelemetry Collector を実行する
次の構成ファイルを config.yaml というファイルにコピーして、GKE で OpenTelemetry Collector を設定できます。
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
# Note that the googlemanagedprometheus exporter block is intentionally blank
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resourcedetection, transform]
exporters: [googlemanagedprometheus]
前述の構成では、Prometheus レシーバーと Managed Service for Prometheus エクスポータを使用して、Kubernetes Pod の指標エンドポイントをスクレイピングし、これらの指標を Managed Service for Prometheus にエクスポートしています。パイプライン プロセッサは、データのフォーマットとバッチ処理を行います。
この構成ファイルの各部分の機能と、さまざまなプラットフォームの構成について詳しくは、指標のスクレイピングとプロセッサの追加に関する詳細内容を記載した次の各セクションをご覧ください。
OpenTelemetry Collector の prometheus レシーバーで既存の Prometheus 構成を使用する場合は、環境変数の置換がトリガーされないように、単一のドル記号 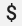 を二重のドル記号
を二重のドル記号 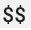 に置き換えます。詳細については、Prometheus 指標をスクレイピングするをご覧ください。
に置き換えます。詳細については、Prometheus 指標をスクレイピングするをご覧ください。
この構成ファイルは、環境、プロバイダ、スクレイピングする指標に基づいて変更できますが、GKE で実行する出発点としてサンプルの構成を使用することをおすすめします。
Google Cloudの外部で OpenTelemetry Collector を実行する
Google Cloudの外部(オンプレミスや他のクラウド プロバイダなど)で OpenTelemetry Collector を実行する手順は、GKE で Collector を実行する場合と同様です。ただし、スクレイピングする指標に、Managed Service for Prometheus に最適な形式のデータが自動的に含まれる可能性は低くなります。したがって、Managed Service for Prometheus と互換性を持たせるため、指標の形式を整えるようにコレクタを構成する作業が必要になります。
次の構成ファイルを config.yaml というファイルにコピーして、GKE 以外の Kubernetes クラスタのデプロイ用に OpenTelemetry Collector を設定できます。
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resource:
attributes:
- key: "cluster"
value: "CLUSTER_NAME"
action: upsert
- key: "namespace"
value: "NAMESPACE_NAME"
action: upsert
- key: "location"
value: "REGION"
action: upsert
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
exporters:
googlemanagedprometheus:
project: "PROJECT_ID"
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resource, transform]
exporters: [googlemanagedprometheus]
この構成ファイルにより、次の処理が行われます。
- Prometheus 用に Kubernetes サービス ディスカバリ スクレイピング構成を設定します。詳細については、Prometheus 指標のスクレイピングをご覧ください。
cluster、namespace、locationリソース属性を手動で設定します。Amazon EKS と Azure AKS のリソース検出など、リソース属性の詳細については、リソース属性を検出するをご覧ください。googlemanagedprometheusエクスポータにprojectオプションを設定します。エクスポータの詳細については、googlemanagedprometheusエクスポータを構成するをご覧ください。
OpenTelemetry Collector の prometheus レシーバーで既存の Prometheus 構成を使用する場合は、環境変数の置換がトリガーされないように、単一のドル記号 を二重のドル記号 に置き換えます。詳細については、Prometheus 指標をスクレイピングするをご覧ください。
他のクラウドで Collector を構成するためのベスト プラクティスについては、Amazon EKS または Azure AKS をご覧ください。
サンプル アプリケーションをデプロイする
このサンプル アプリケーションでは、metrics ポートに example_requests_total カウンタ指標と example_random_numbers ヒストグラム指標が出力されます。このサンプルのマニフェストでは 3 つのレプリカを定義しています。
サンプル アプリケーションをデプロイするには、次のコマンドを実行します。
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/example-app.yaml
コレクタ構成を ConfigMap として作成する
構成を作成して config.yaml というファイルに配置したら、そのファイルを使用して config.yaml ファイルに基づく Kubernetes ConfigMap を作成します。コレクタがデプロイされると、ConfigMap がマウントされ、ファイルが読み込まれます。
構成ファイルで otel-config という名前の ConfigMap を作成するには、次のコマンドを使用します。
kubectl -n NAMESPACE_NAME create configmap otel-config --from-file config.yaml
コレクタをデプロイする
次の内容の collector-deployment.yaml ファイルを作成します。
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: NAMESPACE_NAME:prometheus-test
rules:
- apiGroups: [""]
resources:
- pods
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: NAMESPACE_NAME:prometheus-test
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: NAMESPACE_NAME:prometheus-test
subjects:
- kind: ServiceAccount
namespace: NAMESPACE_NAME
name: default
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: otel-collector
spec:
replicas: 1
selector:
matchLabels:
app: otel-collector
template:
metadata:
labels:
app: otel-collector
spec:
containers:
- name: otel-collector
image: otel/opentelemetry-collector-contrib:0.128.0
args:
- --config
- /etc/otel/config.yaml
- --feature-gates=exporter.googlemanagedprometheus.intToDouble
volumeMounts:
- mountPath: /etc/otel/
name: otel-config
volumes:
- name: otel-config
configMap:
name: otel-config
次のコマンドを実行して、Kubernetes クラスタに Collector の Deployment を作成します。
kubectl -n NAMESPACE_NAME create -f collector-deployment.yaml
Pod が開始すると、Pod はサンプル アプリケーションをスクレイピングして、Managed Service for Prometheus に指標を報告します。
データのクエリ方法については、Cloud Monitoring を使用したクエリまたは Grafana を使用したクエリをご覧ください。
認証情報を明示的に提供する
GKE で実行する場合、OpenTelemetry Collector は、ノードのサービス アカウントに基づいて環境から認証情報を自動的に取得します。GKE 以外の Kubernetes クラスタでは、フラグまたは GOOGLE_APPLICATION_CREDENTIALS 環境変数を使用して、認証情報を OpenTelemetry Collector に明示的に提供する必要があります。
コンテキストをターゲット プロジェクトに設定します。
gcloud config set project PROJECT_ID
サービス アカウントの作成:
gcloud iam service-accounts create gmp-test-sa
この手順では、Workload Identity Federation for GKE の手順ですでに作成したサービス アカウントを作成します。
サービス アカウントに必要な権限を付与します。
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
サービス アカウント キーを作成してダウンロードします。
gcloud iam service-accounts keys create gmp-test-sa-key.json \ --iam-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
鍵ファイルを Secret として GKE 以外のクラスタに追加します。
kubectl -n NAMESPACE_NAME create secret generic gmp-test-sa \ --from-file=key.json=gmp-test-sa-key.json
編集する OpenTelemetry Deployment リソースを開きます。
kubectl -n NAMESPACE_NAME edit deployment otel-collector
太字で示されているテキストをリソースに追加します。
apiVersion: apps/v1 kind: Deployment metadata: namespace: NAMESPACE_NAME name: otel-collector spec: template spec: containers: - name: otel-collector env: - name: "GOOGLE_APPLICATION_CREDENTIALS" value: "/gmp/key.json" ... volumeMounts: - name: gmp-sa mountPath: /gmp readOnly: true ... volumes: - name: gmp-sa secret: secretName: gmp-test-sa ...ファイルを保存して、エディタを閉じます。変更が適用されると、Pod が再作成され、指定されたサービス アカウントで指標のバックエンドに対する認証が開始します。
Prometheus 指標をスクレイピングする
このセクションと次のセクションでは、OpenTelemetry Collector を使用するための追加のカスタマイズ情報を説明します。この情報は、特定の状況で役立つ場合がありますが、OpenTelemetry Collector の設定で説明されているサンプルを実行する必要はありません。
アプリケーションがすでに Prometheus エンドポイントを公開している場合、OpenTelemetry Collector は、標準の Prometheus 構成で使用するのと同じスクレイピング構成形式を使用して、これらのエンドポイントをスクレイピングできます。これを行うには、コレクタ構成で Prometheus レシーバーを有効にします。
Kubernetes Pod の Prometheus レシーバー構成は、次のようになります。
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
service:
pipelines:
metrics:
receivers: [prometheus]
これは、サービス ディスカバリ ベースのスクレイピング構成であり、アプリケーションをスクレイピングするために必要に応じて変更できます。
OpenTelemetry Collector の prometheus レシーバーで既存の Prometheus 構成を使用する場合は、環境変数の置換がトリガーされないように、単一のドル記号 を二重のドル記号 に置き換えます。これは、relabel_configs セクションの replacement 値で特に重要です。たとえば、次の relabel_config セクションがあるとします。
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $1:$2 target_label: __address__
次のように書き換えます。
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $$1:$$2 target_label: __address__
詳細については、OpenTelemetry ドキュメントをご覧ください。
次に、プロセッサを使用して指標の形式を設定することを強くおすすめします。多くの場合、プロセッサを使用して指標を適切にフォーマットする必要があります。
プロセッサを追加する
OpenTelemetry プロセッサは、エクスポートする前にテレメトリー データを変更します。以下のプロセッサを使用すると、Managed Service for Prometheus と互換性のある形式で指標を書き込むことができます。
リソース属性を検出する
OpenTelemetry 用の Managed Service for Prometheus エクスポータでは、prometheus_target モニタリング対象リソースを使用して、時系列のデータポイントを一意に識別します。このエクスポータは、指標データポイントのリソース属性から、必要なモニタリング対象リソース フィールドを解析します。値をスクレイピングするフィールドと属性は次のとおりです。
- project_id: エクスポータ構成ファイルのアプリケーションのデフォルト認証情報、
gcp.project.id、またはprojectによって自動検出されます(エクスポータの構成をご覧ください) - location:
location、cloud.availability_zone、cloud.region - cluster:
cluster、k8s.cluster_name - namespace:
namespace、k8s.namespace_name - job:
service.name+service.namespace - instance:
service.instance.id
これらのラベルに一意の値を設定しないと、Managed Service for Prometheus にエクスポートするときに「duplicate timeseries」エラーが発生することがあります。 多くの場合、これらのラベルの値は自動的に検出されますが、場合によっては手動でマッピングする必要があります。このセクションの残りの部分では、そうしたシナリオについて説明します。
Prometheus レシーバーは、スクレイピング構成の job_name に基づいて service.name 属性を設定し、スクレイピング ターゲットの instance に基づいて service.instance.id 属性を自動的に設定します。スクレイピング構成で role: pod を使用する場合も、レシーバーが k8s.namespace.name を設定します。
可能であれば、リソース検出プロセッサを使用して、他の属性を自動的に入力します。ただし、環境によっては、一部の属性が自動的に検出されないことがあります。この場合、他のプロセッサを使用してこれらの値を手動で挿入するか、指標ラベルから解析できます。以降のセクションで、さまざまなプラットフォームでリソースを検出するための構成について説明します。
GKE
GKE で OpenTelemetry を実行する場合、リソースラベルを入力するには、リソース検出プロセッサを有効にする必要があります。指標に予約済みリソースラベルが含まれないようにします。これを回避できない場合は、属性の名前を変更してリソース属性の競合を回避するをご覧ください。
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
このセクションは構成ファイルに直接コピーできるため、processors セクションがすでに存在する場合は置き換えることができます。
Amazon EKS
EKS リソース検出機能では、cluster 属性または namespace 属性の値が自動的に入力されません。これらの値は、次の例に示すようにリソース プロセッサを使用して手動で指定できます。
processors:
resourcedetection:
detectors: [eks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
groupbyattrs プロセッサを使用して、これらの値を指標ラベルから変換することもできます。指標ラベルをリソースラベルに移動するを参照してください。
Azure AKS
AKS リソース検出機能では、cluster 属性または namespace 属性の値が自動的に入力されません。これらの値は、次の例に示すようにリソース プロセッサを使用して手動で指定できます。
processors:
resourcedetection:
detectors: [aks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
groupbyattrs プロセッサを使用して、これらの値を指標ラベルから変換することもできます。指標ラベルをリソースラベルに移動するをご覧ください。
オンプレミス環境とクラウド以外の環境
オンプレミス環境またはクラウド以外の環境では、必要なリソース属性を自動的に検出できない可能性があります。この場合、これらのラベルを指標に出力してリソース属性に移動できます(指標ラベルをリソースラベルに移動するを参照)。また、リソース属性の例にあるように、すべてのラベルを手動で設定することもできます。
processors:
resource:
attributes:
- key: "cluster"
value: "my-on-prem-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
- key: "location"
value: "us-east-1"
action: upsert
コレクタ構成を ConfigMap として作成するでは、構成ファイルの使用方法について説明しています。このセクションは、config.yaml というファイルに構成ファイルが配置されていることを前提としています。
project_id リソース属性は、アプリケーションのデフォルト認証情報を使用してコレクタを実行するときに自動的に設定できます。Collector がアプリケーションのデフォルト認証情報にアクセスできない場合は、project_id の設定をご覧ください。
また、Key-Value ペアのカンマ区切りリストを使用して、環境変数 OTEL_RESOURCE_ATTRIBUTES に必要なリソース属性を手動で設定することもできます。次に例を示します。
export OTEL_RESOURCE_ATTRIBUTES="cluster=my-cluster,namespace=my-app,location=us-east-1"
次に、env リソース検出プロセッサを使用してリソース属性を設定します。
processors:
resourcedetection:
detectors: [env]
属性名を変更してリソース属性の競合を回避する
必要なリソース属性(location、cluster、namespace など)と競合するラベルがすでに指標に含まれている場合は、競合を回避するため、これらの名前を変更してください。Prometheus では、ラベル名に接頭辞 exported_ を追加するのが慣例になっています。この接頭辞を追加するには変換プロセッサを使用します。
次の processors 構成ファイルは、競合の可能性のある名前を変更し、指標のキーの競合を解決します。
processors:
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
指標ラベルをリソースラベルに移動する
エクスポータが複数の Namespace をモニタリングするため、指標が namespace などのラベルを意図的に報告することがあります。たとえば、kube-state-metrics エクスポータを実行する場合などです。
このシナリオでは、groupbyattrs プロセッサを使用して、これらのラベルをリソース属性に移動できます。
processors:
groupbyattrs:
keys:
- namespace
- cluster
- location
上記の例では、namespace、cluster、location のいずれかのラベルを持つ指標を指定すると、これらのラベルは一致するリソース属性に変換されます。
API リクエストとメモリ使用量を制限する
バッチ プロセッサとメモリ リミット プロセッサの 2 つのプロセッサを使用すると、コレクタのリソース消費量を制限できます。
バッチ処理
バッチ処理リクエストでは、1 回のリクエストで送信するデータポイントの数を定義できます。Cloud Monitoring には、リクエストごとに 200 時系列という上限があります。バッチ プロセッサを有効にするには、次の設定を使用します。
processors:
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
メモリ制限
高スループット時でもコレクタがクラッシュしないように、メモリ リミッタ プロセッサを有効にすることをおすすめします。次の設定を使用して処理を有効にします。
processors:
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
googlemanagedprometheus エクスポータを構成する
GKE で googlemanagedprometheus エクスポータを使用する場合、デフォルトでは追加の構成は必要ありません。多くのユースケースでは、exporters セクションで空のブロックを使用するだけで有効にできます。
exporters: googlemanagedprometheus:
ただし、エクスポータでオプションの構成設定を使用することもできます。以降のセクションでは、その他の構成について説明します。
project_id を設定する
時系列を Google Cloud プロジェクトに関連付けるには、prometheus_target モニタリング対象リソースに project_id を設定する必要があります。
Google Cloudで OpenTelemetry を実行している場合、デフォルトでは、Managed Service for Prometheus エクスポータは検出したアプリケーションのデフォルト認証情報に基づいてこの値を設定します。使用可能な認証情報がない場合や、デフォルトのプロジェクトをオーバーライドする場合は、次の 2 つの方法があります。
- エクスポータ構成ファイルで
projectを設定する gcp.project.idリソース属性を指標に追加する。
可能であれば、明示的に設定するのではなく、project_id のデフォルト値(未設定)を使用することを強くおすすめします。
エクスポータ構成ファイルで project を設定する
次の構成ファイルの抜粋部分は、 Google Cloud プロジェクト MY_PROJECT の Managed Service for Prometheus に指標を送信します。
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
project: MY_PROJECT
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
前の例からの唯一の違いは、新しい行(project: MY_PROJECT)がある点です。この設定は、この Collector を経由するすべての指標を MY_PROJECT に送信する必要があることがわかっている場合に便利です。
gcp.project.id リソース属性を設定する
指標ごとにプロジェクトの関連付けを設定するには、指標に gcp.project.id リソース属性を追加します。属性の値を、指標を関連付ける必要があるプロジェクトの名前に設定します。
たとえば、指標にすでに project というラベルがある場合、このラベルはリソース属性に移動でき、Collector 構成ファイルでプロセッサを使用することによって名前を gcp.project.id に変更できます(下記の例を参照)。
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
groupbyattrs:
keys:
- project
resource:
attributes:
- key: "gcp.project.id"
from_attribute: "project"
action: upsert
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection, groupbyattrs, resource]
exporters: [googlemanagedprometheus]
クライアント オプションの設定
googlemanagedprometheus エクスポータは、Managed Service for Prometheus 用の gRPC クライアントを使用します。したがって、gRPC クライアントを構成するオプションの設定を使用できます。
compression: gRPC リクエストの gzip 圧縮を有効にします。これは、他のクラウドから Managed Service for Prometheus にデータを送信する際のデータ転送費用を最小限に抑えるのに役立ちます(有効な値:gzip)。user_agent: Cloud Monitoring へのリクエストで送信されるユーザー エージェント文字列をオーバーライドします。これは指標にのみ適用されます。デフォルトは、OpenTelemetry Collector のビルド番号とバージョン番号(opentelemetry-collector-contrib 0.128.0など)です。endpoint: 指標データを送信するエンドポイントを設定します。use_insecure: true の場合、通信トランスポートとして gRPC を使用します。endpoint値が "" でない場合にのみ効果があります。grpc_pool_size: gRPC クライアントの接続プールのサイズを設定します。prefix: Managed Service for Prometheus に送信される指標の接頭辞を構成します。デフォルトはprometheus.googleapis.comです。この接頭辞は変更しないでください。これを行うと、Cloud Monitoring UI で PromQL を使用して指標をクエリできなくなります。
ほとんどの場合、これらの値をデフォルトから変更する必要はありません。ただし、特殊な状況に合わせて変更が必要になる場合もあります。
これらの設定はすべて、googlemanagedprometheus エクスポータ セクションの metric ブロックで設定します。次の例をご覧ください。
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
metric:
compression: gzip
user_agent: opentelemetry-collector-contrib 0.128.0
endpoint: ""
use_insecure: false
grpc_pool_size: 1
prefix: prometheus.googleapis.com
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
次のステップ
- Cloud Monitoring で PromQL を使用して Prometheus 指標をクエリする。
- Grafana を使用して Prometheus 指標をクエリする。
- Cloud Run で、サイドカー エージェントとして OpenTelemetry Collector を設定する。
-
Cloud Monitoring の [指標の管理] ページでは、オブザーバビリティに影響を与えることなく、課金対象の指標に費やす金額を制御するために役立つ情報を確認できます。[指標の管理] ページには、次の情報が表示されます。
- 指標ドメイン全体と個々の指標での、バイトベースとサンプルベースの両方の課金に対する取り込み量。
- 指標のラベルとカーディナリティに関するデータ。
- 各指標の読み取り回数。
- アラート ポリシーとカスタム ダッシュボードでの指標の使用。
- 指標書き込みエラーの割合。
[指標の管理] ページで不要な指標を除外し、取り込みの費用を削減することもできます。[指標の管理] ページの詳細については、指標の使用状況の表示と管理をご覧ください。