In diesem Dokument wird beschrieben, wie Sie den OpenTelemetry Collector so einrichten, dass er Standard-Prometheus-Messwerte erfasst und an Google Cloud Managed Service for Prometheus meldet. Der OpenTelemetry Collector ist ein Agent, den Sie selbst bereitstellen und für den Export nach Managed Service for Prometheus konfigurieren können. Die Einrichtung ähnelt dem Ausführen von Managed Service for Prometheus mit selbst bereitgestellter Sammlung.
Sie können den OpenTelemetry Collector aus folgenden Gründen gegenüber einer selbst bereitgestellten Sammlung auswählen:
- Mit dem OpenTelemetry Collector können Sie Ihre Telemetriedaten an mehrere Back-Ends weiterleiten, indem Sie verschiedene Exporter in Ihrer Pipeline konfigurieren.
- Der Collector unterstützt auch Signale aus Messwerten, Logs und Traces. Sie können also alle drei Signaltypen in einem Agent verarbeiten.
- Das anbieterunabhängige Datenformat von OpenTelemetry (das OpenTelemetry Protocol oder OTLP) unterstützt ein starkes Ökosystem von Bibliotheken und Collector-Komponenten, die sich einfügen lassen. So können Sie Ihre Daten auf verschiedene Weise empfangen, verarbeiten und exportieren.
Im Gegenzug zu diesen Vorteilen erfordert die Ausführung eines OpenTelemetry Collectors eine selbstverwaltete Bereitstellung und Wartung. Welchen Ansatz Sie wählen, hängt von Ihren konkreten Bedürfnissen ab, aber in diesem Dokument bieten wir Ihnen empfohlene Richtlinien für die Konfiguration des OpenTelemetry Collector mit Managed Service for Prometheus als Backend.
Hinweise
In diesem Abschnitt wird die Konfiguration beschrieben, die für die in diesem Dokument beschriebenen Aufgaben erforderlich ist.
Projekte und Tools einrichten
Zum Verwenden von Google Cloud Managed Service for Prometheus benötigen Sie folgende Ressourcen:
Ein Google Cloud -Projekt mit aktivierter Cloud Monitoring API.
Wenn Sie kein Google Cloud -Projekt haben, gehen Sie so vor:
Wechseln Sie in der Google Cloud Console zu Neues Projekt:
Geben Sie im Feld Projektname einen Namen für Ihr Projekt ein und klicken Sie dann auf Erstellen.
Wechseln Sie zu Billing (Abrechnung):
Wählen Sie das Projekt aus, das Sie gerade erstellt haben, falls es nicht bereits oben auf der Seite ausgewählt wurde.
Sie werden aufgefordert, ein vorhandenes Zahlungsprofil auszuwählen oder ein neues Zahlungsprofil zu erstellen.
Die Monitoring API ist für neue Projekte standardmäßig aktiviert.
Wenn Sie bereits ein Google Cloud -Projekt haben, muss die Monitoring API aktiviert sein:
Gehen Sie zu APIs & Dienste:
Wählen Sie Ihr Projekt aus.
Klicken Sie auf APIs und Dienste aktivieren.
Suchen Sie nach „Monitoring“.
Klicken Sie in den Suchergebnissen auf "Cloud Monitoring API".
Wenn "API aktiviert" nicht angezeigt wird, klicken Sie auf die Schaltfläche Aktivieren.
Einen Kubernetes-Cluster. Wenn Sie keinen Kubernetes-Cluster haben, folgen Sie der Anleitung in der Kurzanleitung für GKE.
Sie benötigen außerdem die folgenden Befehlszeilentools:
gcloudkubectl
Die Tools gcloud und kubectl sind Teil der Google Cloud CLI. Informationen zur Installation finden Sie unter Komponenten der Google Cloud-Befehlszeile verwalten. Führen Sie den folgenden Befehl aus, um die installierten gloud CLI-Komponenten aufzurufen:
gcloud components list
Konfigurierung Ihrer Umgebung
Führen Sie die folgende Konfiguration aus, um zu vermeiden, dass Sie Ihre Projekt-ID oder den Clusternamen wiederholt eingeben müssen:
Konfigurieren Sie die Befehlszeilentools so:
Konfigurieren Sie die gcloud CLI so, dass sie auf die ID IhresGoogle Cloud -Projekts verweist:
gcloud config set project PROJECT_ID
Konfigurieren Sie die
kubectl-Befehlszeile für die Verwendung Ihres Clusters:kubectl config set-cluster CLUSTER_NAME
Weitere Informationen zu diesen Tools finden Sie hier:
Namespace einrichten
Erstellen Sie den Kubernetes-Namespace NAMESPACE_NAME für Ressourcen, die Sie als Teil der Beispielanwendung erstellen:
kubectl create ns NAMESPACE_NAME
Anmeldedaten für das Dienstkonto prüfen
Wenn in Ihrem Kubernetes-Cluster die Workload Identity Federation for GKE aktiviert ist, können Sie diesen Abschnitt überspringen.
Bei Ausführung in GKE ruft Managed Service for Prometheus automatisch Anmeldedaten aus der Umgebung anhand des Compute Engine-Standarddienstkontos ab. Das Standarddienstkonto hat standardmäßig die erforderlichen Berechtigungen monitoring.metricWriter und monitoring.viewer. Wenn Sie Workload Identity Federation for GKE nicht verwenden und zuvor eine dieser Rollen aus dem Standardknotendienstkonto entfernt haben, müssen Sie diese fehlenden Berechtigungen wieder hinzufügen, bevor Sie fortfahren.
Dienstkonto für die Workload Identity Federation for GKE konfigurieren
Wenn in Ihrem Kubernetes-Cluster die Workload Identity Federation for GKE nicht aktiviert ist, können Sie diesen Abschnitt überspringen.
Managed Service for Prometheus erfasst Messwertdaten mithilfe der Cloud Monitoring API. Wenn Ihr Cluster Workload Identity Federation for GKE verwendet, müssen Sie Ihrem Kubernetes-Dienstkonto die Berechtigung für die Monitoring API erteilen. In diesem Abschnitt wird Folgendes beschrieben:
- Dediziertes Google Cloud -Dienstkonto
gmp-test-saerstellen - Google Cloud -Dienstkonto an das Standard-Kubernetes-Dienstkonto im Test-Namespace
NAMESPACE_NAMEbinden - Dem Google Cloud -Dienstkonto die erforderliche Berechtigung gewähren
Dienstkonto erstellen und binden
Dieser Schritt wird an mehreren Stellen in der Dokumentation zu Managed Service for Prometheus aufgeführt. Wenn Sie diesen Schritt bereits als Teil einer vorherigen Aufgabe ausgeführt haben, müssen Sie ihn nicht wiederholen. Fahren Sie mit Dienstkonto autorisieren fort.
Mit der folgenden Befehlssequenz wird das Dienstkonto gmp-test-sa erstellt und an das Standard-Kubernetes-Dienstkonto im Namespace NAMESPACE_NAME gebunden:
gcloud config set project PROJECT_ID \ && gcloud iam service-accounts create gmp-test-sa \ && gcloud iam service-accounts add-iam-policy-binding \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:PROJECT_ID.svc.id.goog[NAMESPACE_NAME/default]" \ gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ && kubectl annotate serviceaccount \ --namespace NAMESPACE_NAME \ default \ iam.gke.io/gcp-service-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
Wenn Sie einen anderen GKE-Namespace oder ein anderes GKE-Dienstkonto verwenden, passen Sie die Befehle entsprechend an.
Dienstkonto autorisieren
Gruppen zusammengehöriger Berechtigungen werden in Rollen zusammengefasst und Sie weisen die Rollen einem Hauptkonto zu, in diesem Beispiel dem Dienstkonto Google Cloud. Weitere Informationen zu Monitoring-Rollen finden Sie unter Zugriffssteuerung.
Mit dem folgenden Befehl werden dem Dienstkonto Google Cloud , gmp-test-sa, die Monitoring API-Rollen zugewiesen, die zum Schreiben von Messwertdaten erforderlich sind.
Wenn Sie dem Dienstkonto Google Cloud im Rahmen der vorherigen Aufgabe bereits eine bestimmte Rolle zugewiesen haben, müssen Sie dies nicht noch einmal tun.
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
Fehlerbehebung der Konfiguration von Workload Identity Federation for GKE
Wenn Sie Probleme mit der Workload Identity Federation for GKE haben, lesen Sie die Dokumentation zum Prüfen der Workload Identity Federation for GKE-Einrichtung und zur Fehlerbehebung bei der Workload Identity Federation for GKE.
Da Tippfehler und partielle Kopierfunktionen die häufigsten Fehlerquellen bei der Konfiguration von Workload Identity Federation for GKE sind, empfehlen wir dringend die bearbeitbaren Variablen und anklickbaren Symbole, die in die Codebeispiele in dieser Anleitung eingebettet sind.
Workload Identity Federation for GKE in Produktionsumgebungen
Das in diesem Dokument beschriebene Beispiel bindet das Google Cloud -Dienstkonto an das Standard-Kubernetes-Dienstkonto und gewährt dem Google Cloud-Dienstkonto alle erforderlichen Berechtigungen zur Verwendung der Monitoring API.
In einer Produktionsumgebung können Sie einen feiner abgestimmten Ansatz mit einem Dienstkonto für jede Komponente nutzen, das jeweils nur minimale Berechtigungen hat. Weitere Informationen zum Konfigurieren von Dienstkonten für die Verwaltung von Workload Identity finden Sie unter Workload Identity Federation for GKE verwenden.
OpenTelemetry Collector einrichten
In diesem Abschnitt wird beschrieben, wie Sie den OpenTelemetry Collector einrichten und verwenden, um Messwerte aus einer Beispielanwendung zu extrahieren und die Daten an Google Cloud Managed Service for Prometheus zu senden. Ausführliche Informationen zur Konfiguration finden Sie in den folgenden Abschnitten:
- Prometheus-Messwerte extrahieren
- Prozessoren hinzufügen
googlemanagedprometheus-Exporter konfigurieren
Der OpenTelemetry Collector entspricht dem Binärprogramm des Managed Service for Prometheus-Agents. Die OpenTelemetry-Community veröffentlicht regelmäßig Releases, einschließlich Quellcode, Binärprogramme und Container-Images.
Sie können diese Artefakte entweder auf VMs oder Kubernetes-Clustern mit den Best-Practices-Standardeinstellungen bereitstellen oder den Collector-Builder verwenden, um einen eigenen Collector zu erstellen, der nur aus den Komponenten besteht, die Sie benötigen. Um einen Collector für die Verwendung mit Managed Service for Prometheus zu erstellen, benötigen Sie die folgenden Komponenten:
- Der Managed Service for Prometheus-Exporter, der Ihre Messwerte in Managed Service for Prometheus schreibt.
- Ein Empfänger zum Erfassen Ihrer Messwerte. In diesem Dokument wird davon ausgegangen, dass Sie den OpenTelemetry Prometheus-Empfänger verwenden. Der Managed Service for Prometheus-Exporter ist jedoch mit jedem OpenTelemetry-Messwertempfänger kompatibel.
- Prozessoren zum Batching und Markup von Messwerten, um je nach Umgebung wichtige Ressourcenkennungen zu enthalten.
Diese Komponenten werden mit einer Konfigurationsdatei aktiviert, die mit dem Flag --config an den Collector übergeben wird.
In den folgenden Abschnitten wird die Konfiguration der einzelnen Komponenten genauer beschrieben. In diesem Dokument wird beschrieben, wie Sie den Collector in GKE und anderswo ausführen.
Collector konfigurieren und bereitstellen
Unabhängig davon, ob Sie die Sammlung auf Google Cloud oder in einer anderen Umgebung ausführen, können Sie den OpenTelemetry Collector so konfigurieren, dass er in Managed Service for Prometheus exportiert. Der größte Unterschied besteht in der Konfiguration des Collectors. In Nicht-Google Cloud -Umgebungen ist möglicherweise eine zusätzliche Formatierung der Messwertdaten erforderlich, damit sie mit Managed Service for Prometheus kompatibel sind. Auf Google Cloudkann ein Großteil dieser Formatierung jedoch automatisch vom Collector erkannt werden.
OpenTelemetry Collector in GKE ausführen
Sie können die folgende Konfiguration in eine Datei namens config.yaml kopieren, um den OpenTelemetry Collector in GKE einzurichten:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
# Note that the googlemanagedprometheus exporter block is intentionally blank
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resourcedetection, transform]
exporters: [googlemanagedprometheus]
Die vorherige Konfiguration verwendet den Prometheus-Empfänger und den Managed Service for Prometheus-Exporter, um die Messwertendpunkte auf Kubernetes-Pods zu extrahieren und diese Messwerte nach Managed Service for Prometheus zu exportieren. Die Pipelineprozessoren formatieren und verarbeiten die Daten im Batch.
Weitere Informationen zur Funktionsweise der einzelnen Teile dieser Konfiguration sowie Konfigurationen für verschiedene Plattformen finden Sie in den folgenden Abschnitten unter Messwerte extrahieren und Prozessoren hinzufügen.
Wenn Sie eine vorhandene Prometheus-Konfiguration mit dem prometheus-Empfänger des OpenTelemetry Collectors verwenden, ersetzen Sie alle einzelnen Dollarzeichen (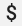 ) durch doppelte Zeichen (
) durch doppelte Zeichen (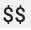 ), um das Auslösen der Umgebungsvariablen zu vermeiden. Weitere Informationen finden Sie unter Prometheus-Messwerte extrahieren.
), um das Auslösen der Umgebungsvariablen zu vermeiden. Weitere Informationen finden Sie unter Prometheus-Messwerte extrahieren.
Sie können diese Konfiguration basierend auf Ihrer Umgebung, Ihrem Anbieter und den zu extrahierenden Messwerten ändern. Die Beispielkonfiguration ist jedoch ein empfohlener Ausgangspunkt für die Ausführung in GKE.
OpenTelemetry Collector außerhalb von Google Cloudausführen
Die Ausführung des OpenTelemetry Collector außerhalb von Google Cloud, z. B. lokal oder bei anderen Cloud-Anbietern, ähnelt der Ausführung des Collectors in GKE. Bei den extrahierten Messwerten ist es jedoch weniger wahrscheinlich, dass sie automatisch Daten enthalten, die sie für Managed Service for Prometheus am besten formatieren. Daher müssen Sie den Collector so konfigurieren, dass die Messwerte so formatiert werden, dass sie mit Managed Service for Prometheus kompatibel sind.
Sie können die folgende Konfiguration in eine Datei namens config.yaml kopieren, um den OpenTelemetry Collector für die Bereitstellung in einem Nicht-GKE-Kubernetes-Cluster einzurichten:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resource:
attributes:
- key: "cluster"
value: "CLUSTER_NAME"
action: upsert
- key: "namespace"
value: "NAMESPACE_NAME"
action: upsert
- key: "location"
value: "REGION"
action: upsert
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
exporters:
googlemanagedprometheus:
project: "PROJECT_ID"
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resource, transform]
exporters: [googlemanagedprometheus]
Diese Konfiguration hat folgende Auswirkungen:
- Richtet eine Kubernetes-Service Discovery-Konfiguration für Prometheus ein. Weitere Informationen finden Sie unter Prometheus-Messwerte extrahieren.
- Legt die Ressourcenattribute
cluster,namespaceundlocationmanuell fest. Weitere Informationen zu Ressourcenattributen, einschließlich der Ressourcenerkennung für Amazon EKS und Azure AKS, finden Sie unter Ressourcenattribute erkennen. - Legt die Option
projectimgooglemanagedprometheus-Exporter fest. Weitere Informationen zum Exporter finden Sie untergooglemanagedprometheus-Exporter konfigurieren.
Wenn Sie eine vorhandene Prometheus-Konfiguration mit dem prometheus-Empfänger des OpenTelemetry Collectors verwenden, ersetzen Sie alle einzelnen Dollarzeichen () durch doppelte Zeichen (), um das Auslösen der Umgebungsvariablen zu vermeiden. Weitere Informationen finden Sie unter Prometheus-Messwerte extrahieren.
Informationen zu Best Practices für die Konfiguration des Collectors in anderen Clouds finden Sie unter Amazon EKS oder Azure AKS.
Beispielanwendung bereitstellen
Die Beispielanwendung gibt Folgendes aus:
den Zählermesswert example_requests_total und den example_random_numbers
Histogramm-Messwert (unter anderem) am Port metrics.
Das Manifest für dieses Beispiel definiert drei Replikate.
Führen Sie den folgenden Befehl aus, um die Beispielanwendung bereitzustellen:
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/example-app.yaml
Collector-Konfiguration als ConfigMap erstellen
Nachdem Sie Ihre Konfiguration erstellt und in einer Datei mit dem Namen config.yaml gespeichert haben, verwenden Sie diese Datei, um eine Kubernetes-ConfigMap auf Grundlage Ihrer config.yaml-Datei zu erstellen.
Wenn der Collector bereitgestellt wird, wird die ConfigMap eingebunden und die Datei geladen.
Verwenden Sie den folgenden Befehl, um eine ConfigMap mit dem Namen otel-config mit Ihrer Konfiguration zu erstellen:
kubectl -n NAMESPACE_NAME create configmap otel-config --from-file config.yaml
Collector bereitstellen
Erstellen Sie eine Datei mit dem Namen collector-deployment.yaml und mit folgendem Inhalt:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: NAMESPACE_NAME:prometheus-test
rules:
- apiGroups: [""]
resources:
- pods
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: NAMESPACE_NAME:prometheus-test
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: NAMESPACE_NAME:prometheus-test
subjects:
- kind: ServiceAccount
namespace: NAMESPACE_NAME
name: default
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: otel-collector
spec:
replicas: 1
selector:
matchLabels:
app: otel-collector
template:
metadata:
labels:
app: otel-collector
spec:
containers:
- name: otel-collector
image: otel/opentelemetry-collector-contrib:0.128.0
args:
- --config
- /etc/otel/config.yaml
- --feature-gates=exporter.googlemanagedprometheus.intToDouble
volumeMounts:
- mountPath: /etc/otel/
name: otel-config
volumes:
- name: otel-config
configMap:
name: otel-config
Erstellen Sie das Collector-Deployment in Ihrem Kubernetes-Cluster, indem Sie den folgenden Befehl ausführen:
kubectl -n NAMESPACE_NAME create -f collector-deployment.yaml
Nachdem der Pod gestartet wurde, extrahiert er die Beispielanwendung und meldet Messwerte an Managed Service for Prometheus.
Informationen zum Abfragen Ihrer Daten finden Sie unter Abfrage mit Cloud Monitoring oder Abfrage mit Grafana.
Anmeldedaten explizit angeben
Bei der Ausführung in GKE ruft der OpenTelemetry Collector automatisch Anmeldedaten aus der Umgebung anhand des Dienstkontos des Knotens ab.
In Nicht-GKE-Kubernetes-Clustern müssen Anmeldedaten explizit mit Flags oder der Umgebungsvariablen GOOGLE_APPLICATION_CREDENTIALS für den OpenTelemetry Collector bereitgestellt werden.
Legen Sie den Kontext auf Ihr Zielprojekt fest:
gcloud config set project PROJECT_ID
Erstellen Sie ein Dienstkonto:
gcloud iam service-accounts create gmp-test-sa
Mit diesem Schritt wird das Dienstkonto erstellt, das Sie möglicherweise bereits in der Anleitung für Workload Identity Federation for GKE erstellt haben.
Gewähren Sie die erforderlichen Berechtigungen für das Dienstkonto:
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
Erstellen Sie einen Schlüssel für das Dienstkonto und laden Sie ihn herunter:
gcloud iam service-accounts keys create gmp-test-sa-key.json \ --iam-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
Fügen Sie dem Nicht-GKE-Cluster die Schlüsseldatei als Secret hinzu:
kubectl -n NAMESPACE_NAME create secret generic gmp-test-sa \ --from-file=key.json=gmp-test-sa-key.json
Öffnen Sie die OpenTelemetry-Deployment-Ressource zur Bearbeitung:
kubectl -n NAMESPACE_NAME edit deployment otel-collector
Fügen Sie der Ressource den fett formatierten Text hinzu:
apiVersion: apps/v1 kind: Deployment metadata: namespace: NAMESPACE_NAME name: otel-collector spec: template spec: containers: - name: otel-collector env: - name: "GOOGLE_APPLICATION_CREDENTIALS" value: "/gmp/key.json" ... volumeMounts: - name: gmp-sa mountPath: /gmp readOnly: true ... volumes: - name: gmp-sa secret: secretName: gmp-test-sa ...Speichern Sie die Datei und schließen Sie den Editor. Nachdem die Änderung angewendet wurde, werden die Pods neu erstellt und beginnen mit der Authentifizierung beim Messwert-Backend mit dem angegebenen Dienstkonto.
Prometheus-Messwerte extrahieren
In diesem und im folgenden Abschnitt finden Sie zusätzliche Informationen zur Anpassung des OpenTelemetry Collectors. Diese Informationen können in bestimmten Situationen hilfreich sein, aber nichts davon ist erforderlich, um das unter OpenTelemetry Collector einrichten beschriebene Beispiel auszuführen.
Wenn Ihre Anwendungen bereits Prometheus-Endpunkte bereitstellen, kann der OpenTelemetry Collector diese Endpunkte mit demselben Format für die Scraping-Konfiguration abrufen, das Sie für jede Standard-Prometheus-Konfiguration verwenden würden. Aktivieren Sie dazu den Prometheus-Empfänger in der Collector-Konfiguration.
Eine Prometheus-Empfängerkonfiguration für Kubernetes-Pods könnte so aussehen:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
service:
pipelines:
metrics:
receivers: [prometheus]
Dies ist eine einfache Service Discovery-basierte Extraktionskonfiguration, die Sie nach Bedarf ändern können.
Wenn Sie eine vorhandene Prometheus-Konfiguration mit dem prometheus-Empfänger des OpenTelemetry Collectors verwenden, ersetzen Sie alle einzelnen Dollarzeichen () durch doppelte Zeichen (), um das Auslösen der Umgebungsvariablen zu vermeiden. Dies ist besonders wichtig für den replacement-Wert im Abschnitt relabel_configs. Als Beispiel der folgende Abschnitt relabel_config:
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $1:$2 target_label: __address__
Schreiben Sie ihn dann so um:
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $$1:$$2 target_label: __address__
Weitere Informationen finden Sie in der OpenTelemetry-Dokumentation.
Als Nächstes empfehlen wir dringend, Prozessoren zum Formatieren Ihrer Messwerte zu verwenden. In vielen Fällen müssen Prozessoren verwendet werden, um Ihre Messwerte richtig zu formatieren.
Prozessoren hinzufügen
OpenTelemetry-Prozessoren ändern Telemetriedaten, bevor sie exportiert werden. Sie können die folgenden Prozessoren verwenden, um sicherzustellen, dass Ihre Messwerte in einem Format geschrieben werden, das mit Managed Service for Prometheus kompatibel ist.
Ressourcenattribute erkennen
Der Managed Service for Prometheus-Exporter für OpenTelemetry verwendet die überwachte Ressource prometheus_target, um Zeitreihendatenpunkte eindeutig zu identifizieren. Der Exporter parst die erforderlichen überwachte Ressourcen Felder aus Ressourcenattributen auf den Messwertdatenpunkten.
Die Felder und Attribute, aus denen die Werte abgerufen werden, sind:
- project_id: automatisch erkannt von den Standardanmeldedaten für Anwendungen,
gcp.project.idoderprojectin der Exporter-Konfiguration (siehe Exporter konfigurieren) - Standort:
location,cloud.availability_zone,cloud.region - Cluster:
cluster,k8s.cluster_name - Namespace:
namespace,k8s.namespace_name - Job:
service.name+service.namespace - Instanz:
service.instance.id
Wenn diese Labels nicht auf eindeutige Werte festgelegt werden, können beim Exportieren nach Managed Service for Prometheus Fehler des Typs "doppelte Zeitreihe" auftreten. In vielen Fällen können Werte für diese Labels automatisch erkannt werden. In einigen Fällen müssen Sie sie jedoch selbst zuordnen. Im weiteren Verlauf dieses Abschnitts werden diese Szenarien beschrieben.
Der Prometheus-Empfänger legt das Attribut service.name automatisch anhand von job_name in der Scraping-Konfiguration und das Attribut service.instance.id anhand von instance des Scraping-Ziels fest. Der Empfänger legt auch k8s.namespace.name fest, wenn role: pod in der Scraping-Konfiguration verwendet wird.
Füllen Sie die anderen Attribute nach Möglichkeit automatisch mit dem Prozessor zur Ressourcenerkennung aus. Je nach Umgebung sind einige Attribute jedoch möglicherweise nicht automatisch erkennbar. In diesem Fall können Sie diese Werte mit anderen Prozessoren manuell einfügen oder aus Messwertlabels parsen. In den folgenden Abschnitten werden Konfigurationen zum Erkennen von Ressourcen auf verschiedenen Plattformen veranschaulicht.
GKE
Wenn Sie OpenTelemetry in GKE ausführen, müssen Sie den Ressourcenerkennungsprozessor aktivieren, um die Ressourcenlabels auszufüllen. Achten Sie darauf, dass Ihre Messwerte keine der reservierten Ressourcenlabels enthalten. Wenn dies unvermeidlich ist, lesen Sie den Abschnitt Kollisionen von Ressourcenattributen durch Umbenennen von Attributen vermeiden.
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
Dieser Abschnitt kann direkt in Ihre Konfigurationsdatei kopiert werden und ersetzt den Abschnitt processors, falls er bereits vorhanden ist.
Amazon EKS
Der EKS-Ressourcendetektor füllt die Attribute cluster und namespace nicht automatisch aus. Sie können diese Werte manuell mit dem Ressourcenprozessor angeben, wie im folgenden Beispiel gezeigt:
processors:
resourcedetection:
detectors: [eks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
Sie können diese Werte auch mit dem Prozessor groupbyattrs aus Messwertlabels konvertieren. Weitere Informationen finden Sie unter Messwertlabels in Ressourcenlabels verschieben.
Azure AKS
Der AKS-Ressourcendetektor füllt die Attribute cluster und namespace nicht automatisch aus. Sie können diese Werte manuell mit dem Ressourcenprozessor angeben, wie im folgenden Beispiel gezeigt:
processors:
resourcedetection:
detectors: [aks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
Sie können diese Werte auch mit dem Prozessor groupbyattrs aus Messwertlabels konvertieren. Weitere Informationen finden Sie unter Messwertlabels in Ressourcenlabels verschieben.
Lokale und Nicht-Cloud-Umgebungen
In lokalen oder Nicht-Cloud-Umgebungen können Sie wahrscheinlich keine der erforderlichen Ressourcenattribute automatisch erkennen. In diesem Fall können Sie diese Labels in Ihren Messwerten ausgeben und sie in Ressourcenattribute verschieben (siehe Messwertlabels in Ressourcenlabels verschieben) oder alle Ressourcenattribute manuell festlegen, wie im folgenden Beispiel gezeigt:
processors:
resource:
attributes:
- key: "cluster"
value: "my-on-prem-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
- key: "location"
value: "us-east-1"
action: upsert
Unter Collector-Konfiguration als ConfigMap erstellen wird beschrieben, wie Sie die Konfiguration verwenden. In diesem Abschnitt wird davon ausgegangen, dass Sie Ihre Konfiguration in einer Datei namens config.yaml gespeichert haben.
Das Ressourcenattribut project_id kann weiterhin automatisch festgelegt werden, wenn der Collector mit Application Default Credentials ausgeführt wird.
Wenn Ihr Collector keinen Zugriff auf Standardanmeldedaten für Anwendungen hat, lesen Sie den Abschnitt project_id festlegen.
Alternativ können Sie die benötigten Ressourcenattribute manuell in einer Umgebungsvariablen (OTEL_RESOURCE_ATTRIBUTES) mit einer durch Kommas getrennten Liste von Schlüssel/Wert-Paaren festlegen, z. B.:
export OTEL_RESOURCE_ATTRIBUTES="cluster=my-cluster,namespace=my-app,location=us-east-1"
Verwenden Sie dann den Prozessor für die Erkennung von env-Ressourcen, um die Ressourcenattribute festzulegen:
processors:
resourcedetection:
detectors: [env]
Kollisionen von Ressourcenattributen durch Umbenennen von Attributen vermeiden
Wenn Ihre Messwerte bereits Labels enthalten, die mit den erforderlichen Ressourcenattributen (z. B. location, cluster oder namespace) in Konflikt stehen, benennen Sie sie um, um den Konflikt zu vermeiden. Gemäß der Prometheus-Konvention wird dem Labelnamen das Präfix exported_ vorangestellt. Verwenden Sie den Transformationsprozessor, um dieses Präfix hinzuzufügen.
Mit der folgenden processors-Konfiguration werden alle potenziellen Konflikte umbenannt und alle in Konflikt stehenden Schlüssel aus dem Messwert behoben:
processors:
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
Messwertlabels in Ressourcenlabels verschieben
In einigen Fällen werden in Ihren Messwerten möglicherweise absichtlich Labels wie
namespace angezeigt, weil Ihr Exporttool mehrere Namespaces überwacht. Dies ist beispielsweise beim Ausführen des kube-state-metrics-Exporters der Fall.
In diesem Szenario können diese Labels mit dem groupbyattrs-Prozessor in Ressourcenattribute verschoben werden:
processors:
groupbyattrs:
keys:
- namespace
- cluster
- location
Im vorherigen Beispiel werden die Labels namespace, cluster oder location eines Messwerts in die entsprechenden Ressourcenattribute konvertiert.
API-Anfragen und Arbeits-Speichernutzung begrenzen
Mit zwei anderen Prozessoren, der Batchverarbeitung und dem Speicherlimitprozessor, können Sie den Ressourcenverbrauch Ihres Collectors begrenzen.
Batchverarbeitung
Mit Batching-Anfragen können Sie festlegen, wie viele Datenpunkte in einer einzelnen Anfrage gesendet werden sollen. Beachten Sie, dass in Cloud Monitoring ein Limit von 200 Zeitreihen pro Anfrage gilt. Aktivieren Sie die Batchverarbeitung mit den folgenden Einstellungen:
processors:
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
Arbeitsspeicherbegrenzung
Wir empfehlen die Aktivierung der Arbeitsspeicherbegrenzung, um zu verhindern, dass Ihr Collector bei Zeiten mit hohem Durchsatz abstürzt. Aktivieren Sie die Verarbeitung mit den folgenden Einstellungen:
processors:
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
googlemanagedprometheus-Exporter konfigurieren
Standardmäßig ist für die Verwendung des googlemanagedprometheus-Exporters in GKE keine zusätzliche Konfiguration erforderlich. In vielen Anwendungsfällen müssen Sie ihn nur mit einem leeren Block im Abschnitt exporters aktivieren:
exporters: googlemanagedprometheus:
Der Exporter bietet jedoch einige optionale Konfigurationseinstellungen. In den folgenden Abschnitten werden die anderen Konfigurationseinstellungen beschrieben.
Einstellen von project_id
Zum Verknüpfen Ihrer Zeitreihe mit einem Google Cloud -Projekt muss für die überwachte Ressource prometheus_target der Wert project_id festgelegt sein.
Wenn Sie OpenTelemetry unter Google Cloudausführen, wird dieser Wert vom Managed Service for Prometheus-Exporter standardmäßig auf Grundlage der Standardanmeldedaten für Anwendungen festgelegt, die er findet. Wenn keine Anmeldedaten verfügbar sind oder Sie das Standardprojekt überschreiben möchten, haben Sie zwei Möglichkeiten:
projectin der Exporterkonfiguration festlegen- Fügen Sie Ihren Messwerten ein
gcp.project.id-Ressourcenattribut hinzu.
Es wird dringend empfohlen, den Standardwert (nicht festgelegt) für project_id zu verwenden, anstatt ihn explizit festzulegen, wenn möglich
project in der Exporterkonfiguration festlegen
Im folgenden Konfigurationsausschnitt werden Messwerte an den Managed Service for Prometheus im Google Cloud -Projekt MY_PROJECT gesendet:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
project: MY_PROJECT
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
Die einzige Änderung gegenüber den vorherigen Beispielen ist die neue Zeile project: MY_PROJECT.
Diese Einstellung ist nützlich, wenn Sie wissen, dass alle Messwerte, die über diesen Collector eingehen, an MY_PROJECT gesendet werden sollen.
gcp.project.id-Ressourcenattribut festlegen
Sie können die Projektzuordnung für jeden Messwert einzeln festlegen, indem Sie Ihren Messwerten ein gcp.project.id-Ressourcenattribut hinzufügen. Legen Sie den Wert des Attributs auf den Namen des Projekts fest, mit dem der Messwert verknüpft werden soll.
Wenn Ihr Messwert beispielsweise bereits das Label project hat, kann dieses Label in ein Ressourcenattribut verschoben und mithilfe von Prozessoren in der Collector-Konfiguration in gcp.project.id umbenannt werden, wie im folgenden Beispiel gezeigt:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
groupbyattrs:
keys:
- project
resource:
attributes:
- key: "gcp.project.id"
from_attribute: "project"
action: upsert
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection, groupbyattrs, resource]
exporters: [googlemanagedprometheus]
Clientoptionen festlegen
Der googlemanagedprometheus-Exporter verwendet gRPC-Clients für Managed Service for Prometheus. Daher sind für die Konfiguration des gRPC-Clients optionale Einstellungen verfügbar:
compression: Aktiviert die GZIP-Komprimierung für gRPC-Anfragen, die zum Minimieren von Datenübertragungsgebühren beim Senden von Daten aus anderen Clouds an Managed Service for Prometheus (gültige Werte:gzip) nützlich ist.user_agent: Überschreibt den String des User-Agents, der bei Anfragen an Cloud Monitoring gesendet wird; gilt nur für Messwerte. Die Standardeinstellung ist die Build- und Versionsnummer Ihres OpenTelemetry Collectors, z. B.opentelemetry-collector-contrib 0.128.0.endpoint: Legt den Endpunkt fest, an den Messwertdaten gesendet werden.use_insecure: Wenn „true“, wird gRPC als Kommunikationstransport verwendet. Wirkt sich nur aus, wenn derendpoint-Wert nicht leer ist.grpc_pool_size: Legt die Größe des Verbindungspools im gRPC-Client fest.prefix: Konfiguriert das Präfix von Messwerten, die an den Managed Service für Prometheus gesendet werden. Die Standardeinstellung istprometheus.googleapis.com. Ändern Sie dieses Präfix nicht. Sonst können Messwerte mit PromQL in der Cloud Monitoring-UI nicht abgefragt werden.
In den meisten Fällen müssen Sie diese Werte nicht von den Standardwerten abweichend ändern. Sie können sie jedoch im Falle von spezieller Umstände ändern.
Alle diese Einstellungen werden in einem metric-Block im googlemanagedprometheus-Exporter-Abschnitt festgelegt, wie im folgenden Beispiel gezeigt:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
metric:
compression: gzip
user_agent: opentelemetry-collector-contrib 0.128.0
endpoint: ""
use_insecure: false
grpc_pool_size: 1
prefix: prometheus.googleapis.com
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
Wie geht es weiter?
- PromQL in Cloud Monitoring zum Abfragen von Prometheus-Messwerten verwenden
- Prometheus-Messwerte mit Grafana abfragen
- Richten Sie den OpenTelemetry Collector als Sidecar-Agent in Cloud Run ein.
-
Auf der Cloud Monitoring-Seite Messwertverwaltung können Sie den Betrag steuern, den Sie für abrechenbare Messwerte ausgeben, ohne die Beobachtbarkeit zu beeinträchtigen. Die Seite Messwertverwaltung enthält die folgenden Informationen:
- Aufnahmevolumen für byte- und probenbasierte Abrechnung für Messwertdomains und einzelne Messwerte
- Daten zu Labels und zur Kardinalität von Messwerten
- Anzahl der Lesevorgänge für jeden Messwert
- Nutzung von Messwerten in Benachrichtigungsrichtlinien und benutzerdefinierten Dashboards
- Fehlerrate beim Schreiben von Messwerten
Auf der Seite Messwertverwaltung können Sie auch nicht benötigte Messwerte ausschließen, um unnötige Kosten bei der Datenaufnahme zu vermeiden. Weitere Informationen zur Seite Messwertverwaltung finden Sie unter Messwertnutzung ansehen und verwalten.