Google Cloud Observability
Google Cloud およびそれ以降で稼働するアプリケーションやシステムのための統合モニタリング、ロギング、トレース マネージド サービス。
Monitoring と Logging のクイックスタート ガイドでオブザーバビリティの使用を開始する
オブザーバビリティを組み込むと信頼性が向上する可能性が 4.1 倍高くなることが調査で明らかに
最新のブログと o11y in-depth 動画シリーズで最新情報を入手する
概要資料(Google Cloud でのオブザーバビリティ)をダウンロードする
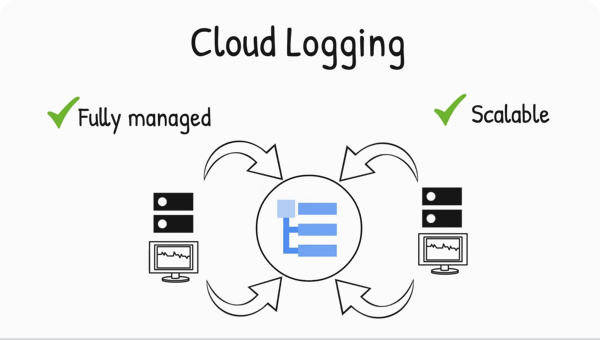
主な機能
主な機能
リアルタイムでログを管理して分析
Cloud Logging は大規模で実行が可能なフルマネージド サービスです。アプリケーションとプラットフォームのログデータ、および GKE 環境や VM をはじめ、Google Cloud 内外のサービスからのカスタム ログデータを取り込むことができます。BigQuery の機能を Cloud Logging に統合することで、Log Analytics でパフォーマンス、トラブルシューティング、セキュリティ、ビジネス分析の詳細情報を取得できます。
大規模な組み込みの指標オブザーバビリティ
Cloud Monitoring では、クラウドで実行されるアプリケーションのパフォーマンスや稼働時間、全体的な動作状況を確認できます。Google Cloud サービス、ホストされた稼働時間プローブ、アプリケーション インストゥルメンテーション、その他のさまざまなアプリケーション コンポーネントから、指標、イベント、メタデータを収集します。このデータをグラフやダッシュボードで可視化して、指標が想定の範囲外になったときに通知されるようアラートを作成できます。
Prometheus での実行とスケーリングのためのスタンドアロン マネージド サービス
Managed Service for Prometheus は、フルマネージドの Prometheus 対応のモニタリング ソリューションで、Cloud Monitoring と同じグローバルに拡張可能なデータストアを基盤に構築されています。このデータは PromQL や Cloud Monitoring でクエリできるので、既存の可視化、分析、アラート サービスをそのまま活用できます。
AI アプリケーションのモニタリングと改善
AI を取り巻く状況が急速に進化するなか、エージェントの構築とデプロイには固有の課題があります。AI エージェントは、知らぬ間にドリフト、ハルシネーション、回帰を引き起こし、従来のソフトウェアとはまったく異なる方法で失敗する可能性があります。Google の実績あるエンタープライズ セキュリティとガバナンスのフレームワークを AI エージェント向けに拡張することで、Cloud Trace を使用してすべてのエージェント アクションにエンドツーエンドでアクセスして明確なトレーサビリティを確保します。
導入事例
オペレーション ツールを使用しているお客様の事例




最新情報
最新情報
Google Cloud のニュースレターにご登録いただくと、プロダクトの最新情報、イベント情報、特典のお知らせなどが配信されます。

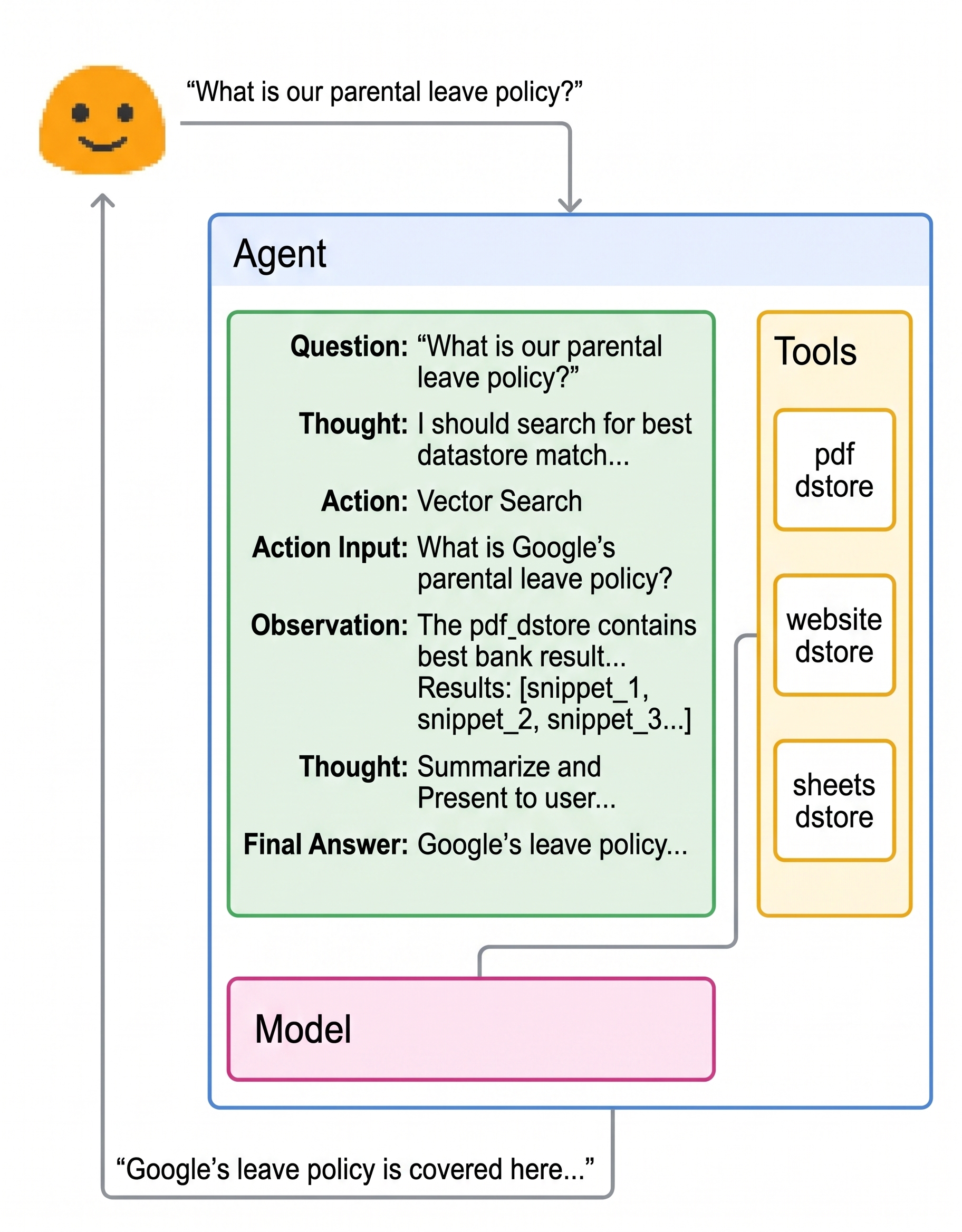

ドキュメント
ドキュメント
ユースケース
ユースケース
インフラストラクチャのモニタリング
Cloud Logging と Cloud Monitoring により、皆様の IT Ops / SRE / DevOps チームは、インフラストラクチャとアプリケーションのモニタリングに必要なオブザーバビリティを容易に手にすることができます。Cloud Logging では、Google Cloud 監査ログとプラットフォーム ログが自動的に取り込まれるので、すぐに使い始めることができます。Cloud Monitoring は、Google Cloud のすべての指標を無料で表示でき、Google Cloud 以外のモニタリングに対応するさまざまなプロバイダと統合されています。

アプリケーションのトラブルシューティング
Cloud Ops ツールのフルパッケージを使用して、平均復元時間(MTTR)を短縮し、アプリケーションのパフォーマンスを最適化します。ダッシュボードを使用して、サービス指標とカスタム アプリケーション指標の両方から分析情報を引き出します。Monitoring の SLO とアラート機能を利用してエラーを特定します。
すべての機能
すべての機能
| ログ管理 | ログルーターを使用すると、ユーザーがログの送信先を制御できます。監査ログ、プラットフォーム ログ、ユーザーログを含むすべてのログは Cloud Logging API に送信され、そこでログルーターを通過します。ログルーターは、各ログエントリを既存のルールと照合して、破棄するログエントリ、取り込むログエントリ、エクスポートに含めるログエントリを決定します。 |
| 予防的なモニタリング | Cloud Monitoring により、指標、ヘルスチェック結果、稼働時間チェックの結果が指定の基準に達したときに通知するようアラート ポリシーを作成できます。Slack や PagerDuty など、多くの通知チャネルと統合されています。 |
| マネージド サービスとしての Prometheus | Prometheus のインフラストラクチャ、更新、ストレージなどのスケーリングと管理を Managed Service for Prometheus でオフロード。ベンダー ロックインを回避して、Prometheus の指標の可視化、アラート、分析に現在使用しているオープンソース ツールをすべて継続使用できます。 |
| カスタムの可視化 | Cloud Monitoring には、すぐに使えるダッシュボードがデフォルトで用意されており、強力な可視化ツールを使用して、ニーズに適した独自のダッシュボードを作成することができます。 |
| ヘルスチェックのモニタリング | Cloud Monitoring は、クラウド環境で実行されているウェブ アプリケーションやその他のインターネットからアクセス可能なサービスに対する稼働時間チェックを提供します。URL、グループ、リソース(インスタンスやロードバランサなど)に対して稼働時間チェックを構成できます。 |
| サービスのモニタリング | Service モニタリング には、すぐに使用できるテレメトリーとダッシュボードが用意されています。これにより、トポロジとコンテキスト グラフによるコンテキストのトラブルシューティングが可能となり、SLO とエラー バジェット管理を通じて健全性モニタリングを自動化できます。 |
| レイテンシ管理 | Cloud Trace は、App Engine のレイテンシをサンプリングし、URL ごとの統計やレイテンシの分布などを報告します。 |
| パフォーマンス管理とコスト管理 | Cloud Profiler は、本番環境のアプリケーションのリソース消費を継続的にプロファイリングします。この情報を使って潜在的なパフォーマンスの問題を特定し、問題を解消できます。 |
| セキュリティ管理 | Cloud Audit Logs は、Google Cloud 全体のユーザー アクティビティをほぼリアルタイムで可視化します。 |
料金
料金
Google Cloud Observability の料金体系では、お客様が使用量と費用を管理できます。Google Cloud Observability プロダクトの料金は、データ量または使用量によって決まります。無料のデータ使用量枠を利用すると、契約や初期費用なしで使用を開始できます。
Cloud Logging
機能 | 料金 | 毎月の無料割り当て量 | 発効日 |
|---|---|---|---|
ロギングのストレージ1 | $0.50/GiB インデックス登録、クエリ、分析を行うために、ログバケットへのログのストリーミングに対して 1 回限りの料金を課金します。これには、最大 30 日分のログバケット ストレージが含まれます。ログデータのクエリと分析に対して追加料金は発生しません。 | 毎月プロジェクトごとに最初の 50GiB | 2018 年 7 月 1 日 |
ロギングの保持2 | 30 日を超えて保持されたログについては、1 か月で GiB あたり $0.01。保持に応じて月単位で請求されます。 | デフォルトの保持期間用に保持されているログに保持費用はかかりません。 | 2023 年 4 月 1 日 |
追加料金なし | 該当なし | 該当なし | |
ログ分析4 | 追加料金なし | 該当なし | 該当なし |
Cloud Monitoring
機能 | 料金 | 毎月の無料割り当て量 | 発効日 |
|---|---|---|---|
Prometheus 形式の Monitoring データ(ほとんどの OTLP 指標や Managed Service for Prometheus を使用して取り込まれた指標など) | $0.060/100 万サンプル†: 取り込まれた最初の 0~500 億個のサンプル# $0.048/100 万サンプル: 取り込まれた次の 500~2,500 億個のサンプル $0.036/100 万サンプル: 取り込まれた次の 2,500~5,000 億個のサンプル $0.024/100 万サンプル: 取り込まれた 5,000 億個を超えるサンプル | 該当なし | 2023 年 8 月 8 日 |
その他のすべての Monitoring データ | $0.2580/MiB6: 最初の 150~100,000 MiB の場合 $0.1510/MiB: 次の 100,000~250,000 MiB の場合 $0.0610/MiB: 250,000 MiB を超える場合 | 取り込みバイト数に応じた課金対象指標の請求先アカウントごとに最初の 150 MiB | 2018 年 7 月 1 日 |
Monitoring の API 呼び出し | 書き込み API 呼び出しに対する課金なし 読み取り API 呼び出し: 返される時系列 100 万件あたり $0.50♥ | 書き込み API 呼び出し: 該当なし 読み取り API 呼び出し: 請求先アカウントごとに最初の 100 万件の時系列が返されます | 2025 年 10 月 2 日 |
Monitoring の API 呼び出し | 読み取り API 呼び出し 1,000 回ごとに $0.01(書き込み API 呼び出しは無料) | 請求先アカウントごとの最初の 100 万回の読み取り API 呼び出し | 2018 年 7 月 1 日から 2025 年 10 月 1 日まで |
$0.30/1,000 回の実行‡ | Google Cloud プロジェクトあたり 100 万回の実行 | 2022 年 10 月 1 日 | |
$1.20/1,000 回の実行* | 請求先アカウントあたり 100 回の実行 | 2023 年 11 月 1 日 | |
アラート ポリシーの指標参照あたり月額 $0.35 指標アラート ポリシー条件のクエリによって返される 1,000,000 ポイントあたり $0.50 ♣ | 該当なし | 2026 年 9 月 1 日 |
Cloud Trace
機能 | 料金 | 毎月の無料割り当て量 | 発効日 |
|---|---|---|---|
Trace での取り込み | 100 万スパンごとに $0.20 | 最初の 250 万スパン | 2018 年 11 月 1 日 |
1 ストレージ ボリュームは、インデックス作成前にログエントリの実際のサイズをカウントします。Required ログバケットに保存されたログにストレージ料金は課金されません。
2 保持期間が 400 日で固定の _Required ログバケットに保存されたログに保持料金は課金されません。
3 ログ ルーティングは、受信したログをサポートされている宛先に転送することとして定義されます。転送されたログに宛先料金が適用される場合があります。
4 ログ分析を使用する、またはログ分析ページから SQL クエリを発行するためにログバケットをアップグレードしても料金はかかりません。
注: Cloud Logging の料金言語は 2023 年 7 月 19 日に変更されましたが、無料割り当て量とレートは変わりません。請求書に以前の料金言語が記載されている可能性があります。
6 料金計算では、すべての単位がバイナリ測定として扱われます。たとえば、メビバイト(MiB、または 220 バイト)または、ギビバイト(GiB、または 230 バイト)などです。
# サンプルは、請求先アカウントごとにカウントされます。
‡ 実行の料金は、定義されている請求先アカウントに請求されます。詳細については、稼働時間チェックの実行料金をご覧ください。
* 実行の料金は、定義されている請求先アカウントに請求されます。実行のたびに、Cloud Functions、Cloud Storage、Cloud Logging などの他の Google Cloud サービスから追加料金が発生する可能性があります。これらの追加料金については、該当する Google Cloud サービスの料金に関するドキュメントをご覧ください。
† Managed Service for Prometheus によって出力されるデータなど、Prometheus 形式のデータは、Prometheus の表記法に沿ったバイト数ではなく、取り込まれたサンプル数に基づいて計測されます。Monitoring API は、Prometheus 形式のデータを含むすべての指標データを取得するために使用されます。サンプルベースの測定の詳細については、管理可能かつ予測可能な料金をご覧ください。計算例については、取り込まれたサンプル数に基づく料金の例をご覧ください。
♥ Google API Console を介して発行された読み取り API 呼び出しには料金は発生しません(Cloud Shell を介して発行されたものを除く)。Google API Console から発行されず、時系列データを返すことができる読み取り API 呼び出しは、返される時系列の数または 1 つの時系列のいずれか大きい方に基づいて課金されます。その他の読み取り API 呼び出しには料金は発生しません。詳細については、Cloud Monitoring API の料金をご覧ください。
詳細についてはアラートの料金をご覧ください。









Bindplane は observIQ, Inc. の登録商標です。
開始にあたりサポートが必要な場合
お問い合わせ信頼できるパートナーと連携する
パートナーを探すもっと見る
すべてのプロダクトを見る











