Questa pagina descrive come utilizzare la dashboard Query Insights per rilevare e analizzare i problemi di prestazioni di Spanner.
Panoramica di Query Insights
Query Insights ti aiuta a rilevare e diagnosticare i problemi di prestazioni delle query e delle istruzioni
DML (INSERT, UPDATE e DELETE)
per un database Spanner. Supporta
il monitoraggio intuitivo e fornisce informazioni diagnostiche che ti aiutano ad andare
oltre il rilevamento per identificare la causa principale dei problemi di prestazioni.
Query Insights ti aiuta a migliorare le prestazioni delle query Spanner guidandoti nei seguenti passaggi:
- Determina se le query inefficienti causano un utilizzo elevato della CPU.
- Identificare una query o un tag potenzialmente problematici.
- Analizza il tag di query o richiesta per identificare i problemi.
Query Insights è disponibile nelle configurazioni a regione singola e a più regioni.
Prezzi
Non sono previsti costi aggiuntivi per Query Insights.
Conservazione dei dati
Approfondimenti sulle query conserva i dati per un massimo di 30 giorni.
Per il grafico Utilizzo totale della CPU (per tag di query o richiesta), Spanner recupera i dati dalle tabelle SPANNER_SYS.QUERY_STATS_TOP_*. Queste tabelle hanno un periodo di conservazione massimo di 30 giorni. Per scoprire di più, consulta la sezione Conservazione dei dati.
Ruoli obbligatori
A seconda che tu sia un utente IAM o un utente con controllo dell'accesso dell'accesso granulare, hai bisogno di ruoli e autorizzazioni IAM diversi.
Utente Identity and Access Management (IAM)
Per ottenere le autorizzazioni necessarie per visualizzare la pagina Query Insights, chiedi all'amministratore di concederti i seguenti ruoli IAM sull'istanza:
-
Visualizzatore Cloud Spanner (
roles/spanner.viewer) -
Lettore database Cloud Spanner (
roles/spanner.databaseReader)
Per visualizzare la pagina Query Insights sono necessarie le seguenti autorizzazioni nel ruolo Cloud Spanner Database Reader(
roles/spanner.databaseReader):
spanner.databases.beginReadOnlyTransactionspanner.databases.selectspanner.sessions.create
Utente con controllo dell'accesso granulare
Se utilizzi il controllo dell'accesso granulare, verifica di:
- Disporre del ruolo Cloud Spanner Viewer(
roles/spanner.viewer) - Disporre di privilegi di controllo dell'accesso granulare e disporre del ruolo di sistema
spanner_sys_readero di uno dei suoi ruoli membri. - Seleziona
spanner_sys_readero un ruolo del membro come ruolo di sistema attuale nella pagina di panoramica del database.
Per saperne di più, consulta Informazioni sul controllo dell'accesso granulare e Ruoli di sistema per controllo dell'accesso dell'accesso granulare.
La dashboard Query Insights
La dashboard Approfondimenti sulle query mostra il carico delle query in base al database e all'intervallo di tempo selezionati. Il carico delle query è una misura dell'utilizzo totale della CPU per tutte le query nell'istanza nell'intervallo di tempo selezionato. La dashboard fornisce una serie di filtri che ti aiutano a visualizzare il carico delle query.
Per visualizzare la dashboard Approfondimenti sulle query per un database:
- Seleziona Approfondimenti sulle query nel pannello di navigazione a sinistra. Si apre la dashboard Approfondimenti sulle query.
- Seleziona un database dall'elenco Database. La dashboard mostra le informazioni sul carico delle query per il database.
Le aree della dashboard includono:
- Elenco dei database: filtra il carico delle query su un database specifico o su tutti i database.
- Filtro intervallo di tempo: filtra il carico delle query in base a intervalli di tempo, ad esempio ore, giorni o un intervallo personalizzato.
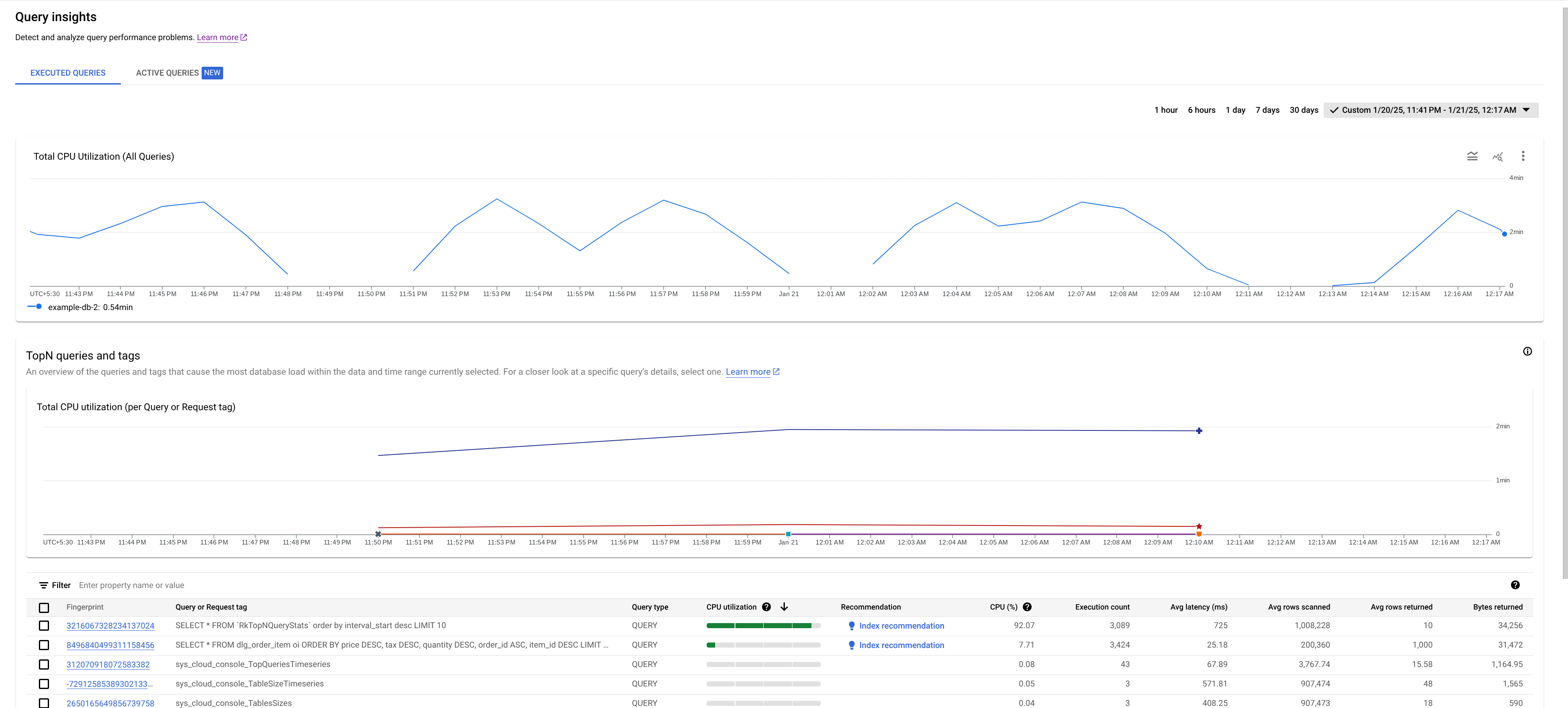
- Grafico Utilizzo totale della CPU (tutte le query): mostra il carico aggregato di tutte le query.
- Grafico Utilizzo totale della CPU (per tag di query o richiesta): mostra l'utilizzo della CPU per ogni tag di query o richiesta.
- Tabella Query e tag TopN: mostra l'elenco delle query e dei tag di richiesta principali ordinati in base all'utilizzo della CPU. Consulta Identificare una query o un tag potenzialmente problematico.
Rendimento della dashboard
Utilizza i parametri delle query o tagga le query per ottimizzare il rendimento di Query Insights. Se non parametrizzi o non tagghi le query, potrebbero essere restituiti troppi risultati, il che potrebbe causare il mancato caricamento corretto della tabella delle query e dei tag TopN.
Verifica se le query inefficienti sono responsabili dell'utilizzo elevato della CPU
L'utilizzo totale della CPU è una misura del lavoro (in secondi CPU) che le query eseguite nel database selezionato eseguono nel tempo.

Esamina il grafico per rispondere a queste domande:
Quale database sta riscontrando il carico? Seleziona database diversi dall'elenco Database per trovare quelli con i carichi più elevati. Per scoprire quale database ha il carico più elevato, puoi anche esaminare il grafico Utilizzo CPU - totale per i database nella consoleGoogle Cloud .
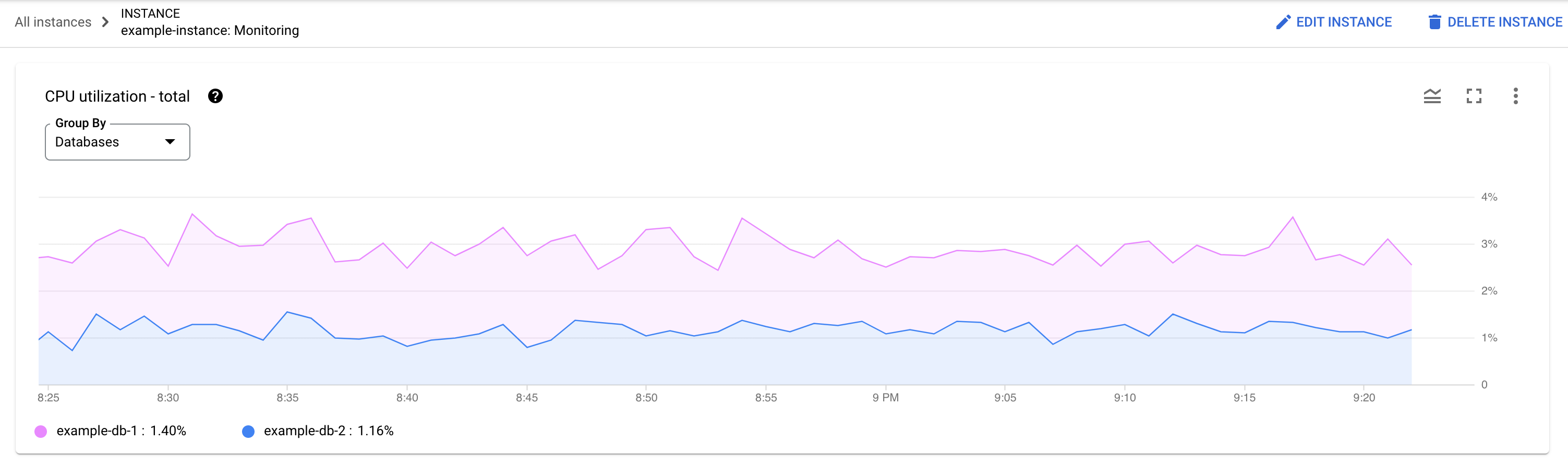
L'utilizzo della CPU è elevato? Il grafico mostra picchi o valori elevati nel tempo? Se non noti un utilizzo elevato della CPU, il problema non riguarda le query.
Da quanto tempo l'utilizzo della CPU è elevato? È aumentato di recente o è rimasto costantemente alto per un po' di tempo? Utilizza il selettore dell'intervallo per selezionare vari periodi di tempo per scoprire da quanto tempo dura il problema. Aumenta lo zoom per visualizzare una finestra temporale in cui si osservano picchi di carico delle query. Diminuisci lo zoom per visualizzare fino a una settimana della sequenza temporale.
Se nel grafico vedi un picco o un aumento corrispondente all'utilizzo complessivo della CPU dell'istanza, è molto probabile che sia dovuto a una o più query costose. Successivamente, puoi approfondire il percorso di debug identificando un tag di query o richiesta potenzialmente problematico.
Identificare un tag di query o richiesta potenzialmente problematico
Per identificare un tag di query o richiesta potenzialmente problematico, osserva la sezione Query TopN:
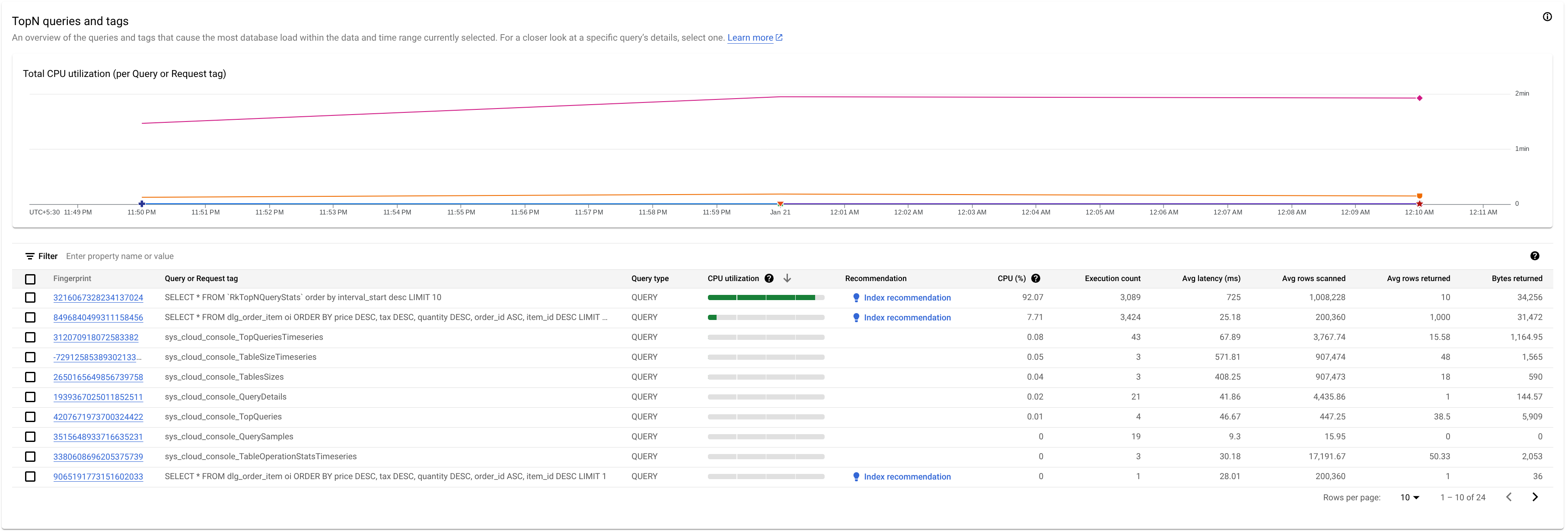
Qui vediamo che la query con l'impronta 3216067328234137024 ha un utilizzo elevato della CPU e può essere problematica.
La tabella Query TopN fornisce una panoramica delle query che utilizzano la maggior parte della CPU durante il periodo di tempo scelto, ordinate dalla più alta alla più bassa. Il numero di query TopN è limitato a 100.
Per i grafici, recuperiamo i dati dalla tabella delle statistiche delle query TopN, che ha tre granularità diverse: 1 minuto, 10 minuti e 1 ora. Il valore di ciascun punto dati nei grafici rappresenta il valore medio in un intervallo di un minuto.
Ti consigliamo di aggiungere tag alle query SQL. Il tagging delle query consente di trovare problemi in costrutti di livello superiore, ad esempio nella logica di business o in un microservizio.

La tabella mostra le seguenti proprietà:
- Impronta: hash del tag di richiesta o, se il tag non è presente, hash del testo della query.
Tag di query o richiesta: se alla query è associato un tag, viene visualizzato il tag di richiesta. Le statistiche per più query con la stessa stringa di tag sono raggruppate in una singola riga con il valore
REQUEST_TAGcorrispondente alla stringa di tag. Per saperne di più sull'utilizzo dei tag di richiesta, vedi Risoluzione dei problemi relativi ai tag di richiesta e di transazione.Se la query non ha un tag associato, viene visualizzata la query SQL, troncata a circa 64 KB. Per DML batch, le istruzioni SQL vengono compresse in una singola riga e concatenate, utilizzando un punto e virgola come delimitatore. I testi SQL identici consecutivi vengono deduplicati prima del troncamento.
Tipo di query: indica se una query è una
PARTITIONED_QUERYo unaQUERY. UnaPARTITIONED_QUERYè una query con unpartitionTokenottenuto dall'API PartitionQuery. Tutte le altre query e istruzioni DML sono indicate dal tipo di queryQUERY.Utilizzo CPU: consumo di risorse CPU da parte di una query, espresso come percentuale delle risorse CPU totali utilizzate da tutte le query eseguite sui database in quell'intervallo di tempo, mostrato su una barra orizzontale con un intervallo da 0 a 100.
Suggerimento: Spanner analizza le query per determinare se possono trarre vantaggio da indici migliorati. In questo caso, consiglia indici nuovi o modificati che possono migliorare il rendimento delle query. Per saperne di più, vedi Utilizzare lo strumento di suggerimento degli indici di Spanner.
CPU (%): consumo di risorse CPU da parte di una query, espresso come percentuale delle risorse CPU totali utilizzate da tutte le query in esecuzione sui database in quell' intervallo di tempo.
Conteggio esecuzioni: il numero di volte in cui Spanner ha visto la query durante l'intervallo.
Latenza media (ms): durata media, in microsecondi, di ogni esecuzione di query all'interno del database. Questa media esclude il tempo di codifica e trasmissione per il set di risultati, nonché il sovraccarico.
Media righe scansionate: il numero medio di righe scansionate dalla query, esclusi i valori eliminati.
Media righe restituite: il numero medio di righe restituite dalla query.
Byte restituiti: il numero di byte di dati restituiti dalla query, escluso l'overhead di codifica della trasmissione.
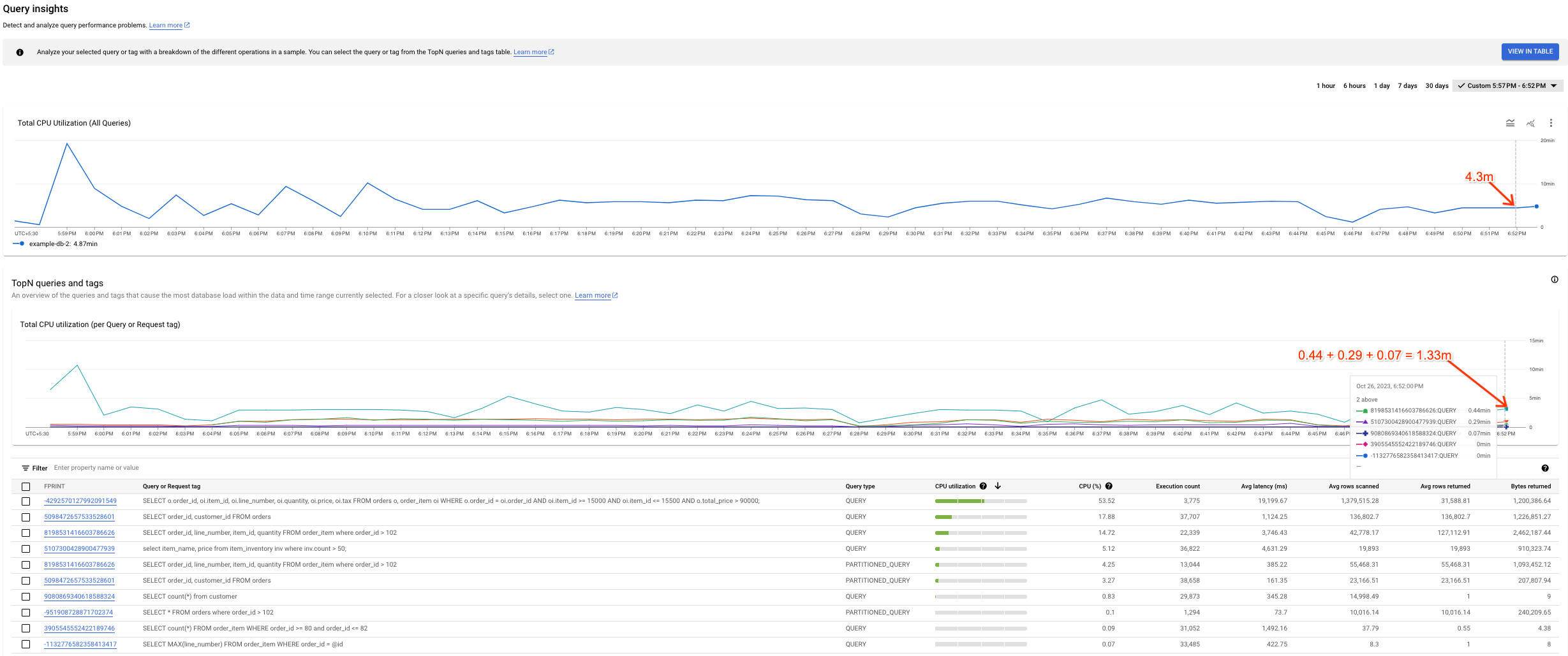
Possibile varianza tra i grafici
Potresti notare alcune variazioni tra il grafico Utilizzo totale della CPU (tutte le query) e il grafico Utilizzo totale della CPU (per tag di query o richiesta). Esistono due motivi che potrebbero portare a questo scenario:
Diverse origini dati: i dati di Cloud Monitoring, che alimentano il grafico Utilizzo totale CPU (tutte le query), sono in genere più precisi perché vengono inviati ogni minuto e hanno un periodo di conservazione di 45 giorni. D'altra parte, i dati della tabella di sistema, che alimentano il grafico Utilizzo totale della CPU (per tag di query o richiesta), potrebbero essere calcolati in media su 10 minuti (o 1 ora), nel qual caso potremmo perdere i dati ad alta granularità visualizzati nel grafico Utilizzo totale della CPU (tutte le query).
Finestre di aggregazione diverse: entrambi i grafici hanno finestre di aggregazione diverse. Ad esempio, quando esaminiamo un evento più vecchio di 6 ore, eseguiamo una query sulla tabella
SPANNER_SYS.QUERY_STATS_TOTAL_10MINUTE. In questo caso, un evento che si verifica alle 10:01 viene aggregato in 10 minuti e sarà presente nella tabella di sistema corrispondente al timestamp delle 10:10.
Lo screenshot seguente mostra un esempio di questa varianza.
Analizzare un tag di query o richiesta specifico
Per determinare se un tag di query o richiesta è la causa principale del problema, fai clic sul tag di query o richiesta che sembra avere il carico più elevato o che richiede più tempo rispetto agli altri. Puoi selezionare più query e richiedere tag contemporaneamente.
Puoi tenere il puntatore del mouse sul grafico per le query nella sequenza temporale per conoscere l'utilizzo della CPU (in secondi).
Prova a restringere il campo del problema esaminando quanto segue:
- Da quanto tempo il carico è elevato? È solo alta ora? O è alta da molto tempo? Modifica gli intervalli di tempo per trovare la data e l'ora in cui la query ha iniziato a registrare un rendimento scarso.
- Si sono verificati picchi nell'utilizzo della CPU? Puoi modificare la finestra temporale per studiare l'utilizzo storico della CPU per la query.
- Che cos'è il consumo di risorse? Qual è la sua relazione con altre query? Esamina la tabella e confronta i dati delle altre query con quella selezionata. Esiste una differenza significativa?
Per verificare che la query selezionata contribuisca all'utilizzo elevato della CPU, puoi esaminare in dettaglio la forma della query specifica (o il tag della richiesta) e analizzarla ulteriormente nella pagina Dettagli query.
Visualizzare la pagina Dettagli query
Per visualizzare i dettagli di una forma di query o di un tag di richiesta specifico in formato grafico, fai clic sull'impronta associata alla query o al tag di richiesta. Viene visualizzata la pagina Dettagli query.
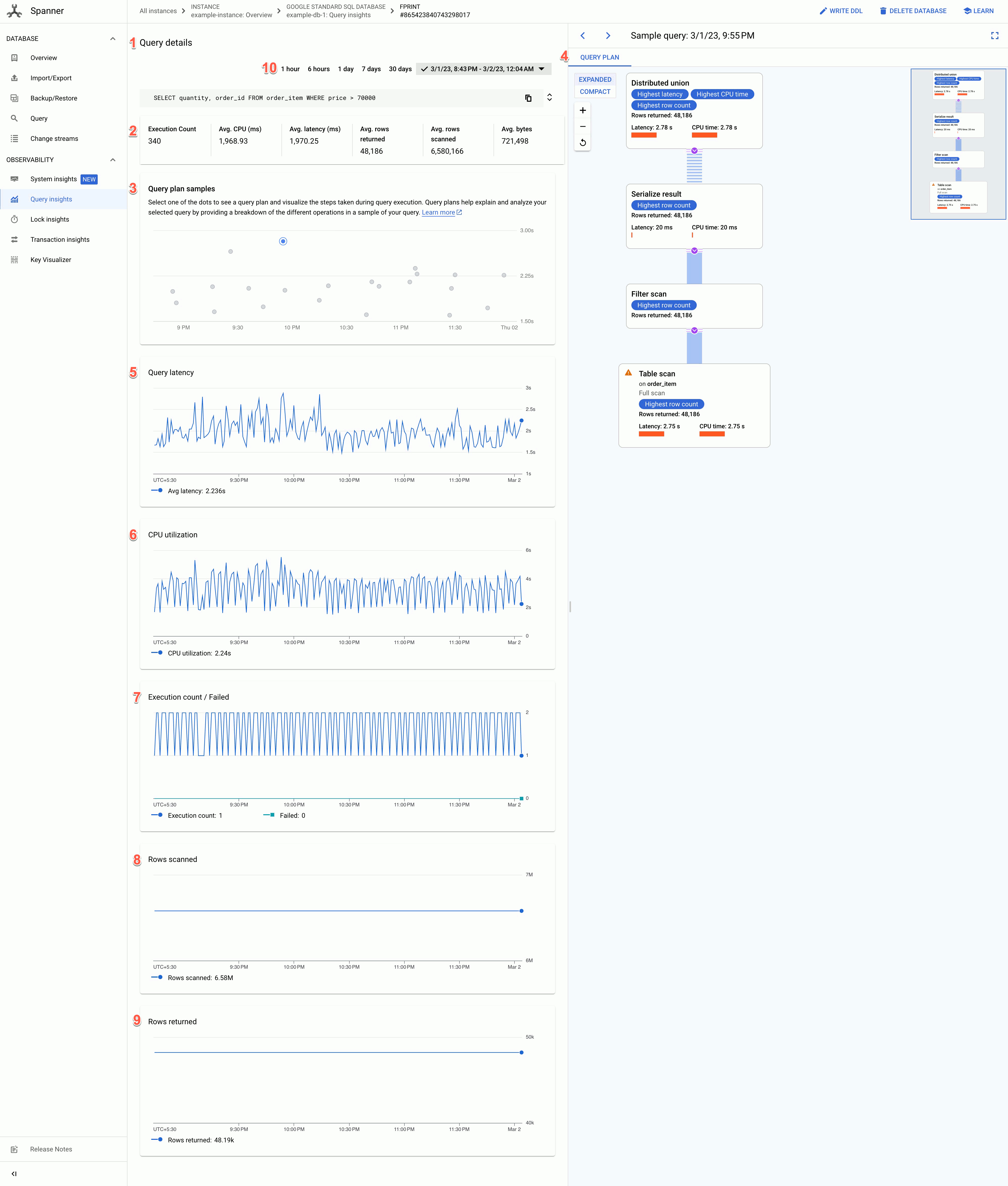
La pagina Dettagli query mostra le seguenti informazioni:
- Testo dei dettagli della query: testo della query SQL, troncato a circa 64 kB. Le statistiche per più query con la stessa stringa di tag vengono raggruppate in una singola riga con REQUEST_TAG corrispondente alla stringa di tag. In questo campo viene visualizzato solo il testo di una di queste query. Per il linguaggio DML batch, l'insieme di istruzioni SQL viene compresso in una singola riga, concatenata utilizzando un delimitatore punto e virgola. I testi SQL identici consecutivi vengono deduplicati prima del troncamento.
- I valori dei seguenti campi:
- Conteggio esecuzioni: il numero di volte in cui Spanner ha visto la query durante l'intervallo.
- CPU media (ms): consumo medio di risorse della CPU, in millisecondi, da parte di una query delle risorse della CPU dell'istanza in un intervallo di tempo.
- Latenza media (ms): tempo medio, in millisecondi, per ogni esecuzione della query all'interno del database. Questa media esclude il tempo di codifica e trasmissione per il set di risultati e l'overhead.
- Media righe restituite: il numero medio di righe restituite dalla query.
- Media righe scansionate: numero medio di righe scansionate dalla query, esclusi i valori eliminati.
- Byte medi: numero di byte di dati restituiti dalla query, escluso l'overhead di codifica della trasmissione.
- Grafico dei campioni dei piani di query: ogni punto del grafico rappresenta un piano di query campionato in un momento specifico e la relativa latenza della query. Fai clic su uno dei punti del grafico per visualizzare il piano di query e i passaggi eseguiti durante l'esecuzione della query. Nota: i piani di query non sono supportati per le query con partitionTokens ottenuti dall'API PartitionQuery e query DML partizionate.
Visualizzatore del piano di query: mostra il piano di query campionato selezionato. Spanner fornisce le seguenti opzioni di layout:
- Visualizzazione ad albero: la visualizzazione ad albero visualizza il piano di query come un grafico in cui ogni nodo o scheda rappresenta un iteratore che utilizza le righe dei relativi input e produce righe per il relativo elemento principale. Puoi fare clic su ogni iteratore per visualizzare informazioni più dettagliate.
Visualizzazione sequenziale: la visualizzazione sequenziale visualizza il piano di query in una tabella gerarchica in cui ogni riga rappresenta un operatore. Puoi fare clic su ogni riga per visualizzare informazioni più dettagliate.

La tabella mostra le seguenti colonne:
- Nome: il nome dell'operatore.
- Gruppo di macchine: il gruppo di macchine in cui è stato eseguito questo operatore.
- Latenza: il tempo trascorso durante l'esecuzione dell'operazione corrente. Potrebbe essere superiore al tempo di CPU (ad esempio, se l'operatore è rimasto in attesa di chiamate remote o per un ritardo del file system).
- Latenza cumulativa: il tempo trascorso durante l'esecuzione dell'intero sottoalbero con radice in questo operatore. Questo non include il tempo di creazione del piano e altri costi generali, pertanto la latenza cumulativa potrebbe essere inferiore alla durata totale della query.
- Tempo CPU: quantità totale di tempo di CPU dedicato all'esecuzione della query. Latenza di rete esclusa. Alcune parti dell'esecuzione della query potrebbero procedere in parallelo, pertanto il tempo di CPU potrebbe essere maggiore rispetto al tempo totale trascorso. Ad esempio, se una query esegue dieci operazioni in parallelo in 1 millisecondo (ms), il tempo trascorso è di 1 ms, ma il tempo di CPU è di 10 ms.
- Righe restituite: il numero di righe restituite dall'operatore.
Grafico della latenza delle query: mostra il valore della latenza delle query per una query selezionata in un periodo di tempo. Mostra anche la latenza media.
Grafico Utilizzo CPU: mostra l'utilizzo della CPU da parte di una query, in percentuale, in un periodo di tempo. Mostra anche l'utilizzo medio della CPU.
Grafico Conteggio esecuzioni/non riuscite: mostra il conteggio delle esecuzioni di una query in un periodo di tempo e il numero di volte in cui l'esecuzione della query non è riuscita.
Grafico Righe scansionate: mostra il numero di righe scansionate dalla query in un periodo di tempo.
Grafico Righe restituite: mostra il numero di righe restituite dalla query in un periodo di tempo.
Filtro intervallo di tempo: filtra i dettagli della query in base agli intervalli di tempo, ad esempio ora, giorno o un intervallo personalizzato.
Per i grafici, recuperiamo i dati dalla tabella delle statistiche delle query TopN, che ha tre granularità diverse: 1 minuto, 10 minuti e 1 ora. Il valore di ciascun punto dati nei grafici rappresenta il valore medio in un intervallo di un minuto.
Cercare tutte le esecuzioni di una query nel log di controllo
Per cercare tutte le esecuzioni di un'impronta di query specifica in
Cloud Audit Logs,
esegui una query sul log di controllo e cerca qualsiasi
query_fingerprint corrispondente al campo Fingerprint nella tabella delle statistiche delle query TopN. Per ulteriori informazioni, consulta la panoramica delle query e della visualizzazione dei log. Utilizza questo metodo per identificare l'utente che ha avviato la query.