Questo documento descrive come utilizzare la dashboard approfondimenti del sistema per monitorare le istanze e i database Spanner.
Informazioni sugli insight sul sistema
La dashboard Approfondimenti sul sistema mostra prospetti e grafici relativi a un'istanza o un database selezionato e fornisce misure di latenze, utilizzo della CPU, spazio di archiviazione, velocità effettiva e altre statistiche sul rendimento. Puoi visualizzare grafici per periodi di tempo selezionabili, che vanno dall'ultima ora agli ultimi 30 giorni.
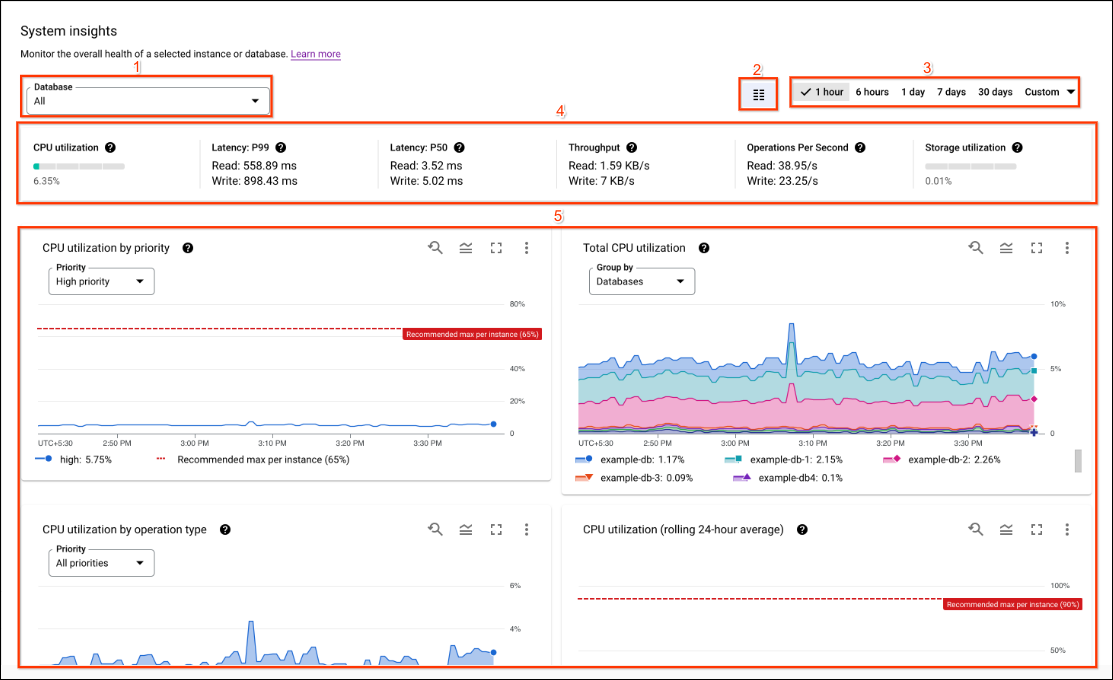
La dashboard Approfondimenti del sistema include le seguenti sezioni, con i numeri corrispondenti allo screenshot dell'interfaccia utente:
- Selettori di approfondimenti:seleziona i database, le partizioni delle istanze e le regioni che popolano la dashboard. System Insights mostra le partizioni dell'istanza e le selezioni delle regioni quando nell'istanza sono disponibili più partizioni o regioni.
- Filtro intervallo di tempo:filtra le statistiche in base a un intervallo di tempo, ad esempio ore, giorni o un intervallo personalizzato.
- Selettore della dashboard:seleziona le visualizzazioni personalizzate dall'utente o ripristina le statistiche di sistema alla visualizzazione predefinita.
- Annotazioni:seleziona i tipi di evento di avviso di insight per annotare i grafici.
- Personalizza le dashboard:personalizza l'aspetto, il posizionamento e i contenuti dei widget della dashboard e della dashboard approfondimenti del sistema. Questo documento descrive la presentazione predefinita della dashboard.
- Prospetti:mostrano le statistiche in un determinato momento, nel periodo selezionato.
- Grafici:mostra grafici relativi a utilizzo della CPU, throughput, latenze, utilizzo dello spazio di archiviazione e altro ancora. Gli avvisi sugli approfondimenti impostati dalle annotazioni vengono visualizzati nei grafici con le icone a forma di campana.
Ruoli obbligatori
Per ottenere le autorizzazioni necessarie per visualizzare o modificare le dashboard di approfondimenti, incluse quelle personalizzate, chiedi all'amministratore di concederti i seguenti ruoli IAM sul progetto:
-
Per creare e modificare dashboard personalizzate:
Editor configurazione dashboard Monitoring (
roles/monitoring.dashboardEditor) -
Per aprire e visualizzare i grafici di Metrics Explorer:
Visualizzatore configurazione dashboard Monitoring (
roles/monitoring.dashboardViewer) -
Per creare e modificare gli avvisi di Metrics Explorer:
Monitoring Editor (
roles/monitoring.editor)
Per ulteriori informazioni sulla concessione dei ruoli, consulta Gestisci l'accesso a progetti, cartelle e organizzazioni.
Questi ruoli predefiniti contengono le autorizzazioni necessarie per visualizzare o modificare le dashboard di approfondimento, incluse quelle personalizzate. Per vedere quali sono esattamente le autorizzazioni richieste, espandi la sezione Autorizzazioni obbligatorie:
Autorizzazioni obbligatorie
Per visualizzare o modificare le dashboard di approfondimento, incluse quelle personalizzate, sono necessarie le seguenti autorizzazioni:
-
Per creare dashboard personalizzate:
monitoring.dashboards.create -
Per modificare le dashboard personalizzate:
monitoring.dashboards.update -
Per visualizzare le dashboard personalizzate:
monitoring.dashboards.get, monitoring.dashboards.list
Potresti anche ottenere queste autorizzazioni con ruoli personalizzati o altri ruoli predefiniti.
Personalizzare la dashboard degli approfondimenti sul sistema
La dashboard degli approfondimenti di sistema è una dashboard predefinita che puoi personalizzare per visualizzare le informazioni più importanti per te. Puoi aggiungere nuovi grafici, modificare il layout e filtrare i dati per concentrarti su risorse specifiche.
Le modifiche alla dashboard degli approfondimenti di sistema non sono distruttive e possono essere ripristinate impostando il selettore della dashboard su Predefinito.
Modificare la dashboard
Per modificare la dashboard, fai clic su Personalizza dashboard. Sono disponibili le seguenti opzioni:
- Aggiungi un widget:nella barra degli strumenti della dashboard, fai clic su Aggiungi widget, seleziona il widget che vuoi aggiungere e poi configuralo.
- Modificare un widget:passa il mouse sopra un widget per visualizzare la relativa barra degli strumenti, quindi fai clic su Modifica. Puoi modificare il tipo di widget e personalizzare i dati visualizzati.
- Clonare un widget:passa il mouse sopra un widget per visualizzare la relativa barra degli strumenti, fai clic su Altre opzioni del grafico, poi su Clona widget.
- Eliminare un widget: passa il mouse sopra un widget per visualizzarne la barra degli strumenti, fai clic su Altre opzioni del grafico, poi su Elimina widget.
- Modificare il layout: puoi trascinare i widget per riposizionarli e trascinare i loro angoli per ridimensionarli.
- Dai un nome alla vista personalizzata:puoi impostare il nome della vista personalizzata nella casella Nome vista personalizzata.
- Salva la dashboard:puoi salvare la visualizzazione personalizzata facendo clic su Salva. Puoi anche uscire senza salvare facendo clic su Esci dalla modalità di modifica.
Prospetti, grafici e metriche degli approfondimenti sul sistema
La dashboard approfondimenti del sistema fornisce i seguenti grafici e metriche per mostrare lo stato attuale e storico di un'istanza. La maggior parte dei grafici e delle metriche sono disponibili a livello di istanza. Puoi anche visualizzare molti grafici e metriche per un singolo database all'interno di un'istanza.
Prospetti disponibili
| Nome | Descrizione |
|---|---|
| Utilizzo CPU | Utilizzo totale della CPU all'interno di un'istanza o del database selezionato. In un'istanza multiregionale o dual-region, questa metrica rappresenta la media dell'utilizzo della CPU tra le regioni. |
| Latenza (p99) | Latenza P99 (99° percentile) per le operazioni di lettura e scrittura all'interno di un'istanza o del database selezionato, che rappresenta il tempo entro il quale viene completato il 99% di queste operazioni. |
| Latenza (p50) | Latenza P50 (50° percentile) per le operazioni di lettura e scrittura all'interno di un'istanza o del database selezionato, che rappresenta il tempo entro il quale viene completato il 50% di queste operazioni. |
| Throughput | Quantità di dati non compressi letti o scritti nell'istanza o nel database ogni secondo. Questo valore è misurato in byte binari, ad esempio KiB, MiB o GiB. |
| Operazioni al secondo | Numero di operazioni al secondo (frequenza) di letture e scritture all'interno di un'istanza o del database selezionato. |
| Utilizzo archiviazione | A livello di istanza, è la percentuale di utilizzo dello spazio di archiviazione totale all'interno di un'istanza. A livello di database, si tratta dello spazio di archiviazione totale utilizzato per il database selezionato. |
Grafici e metriche disponibili
Di seguito è riportato un grafico per una metrica di esempio, l'utilizzo della CPU per tipo di operazione:
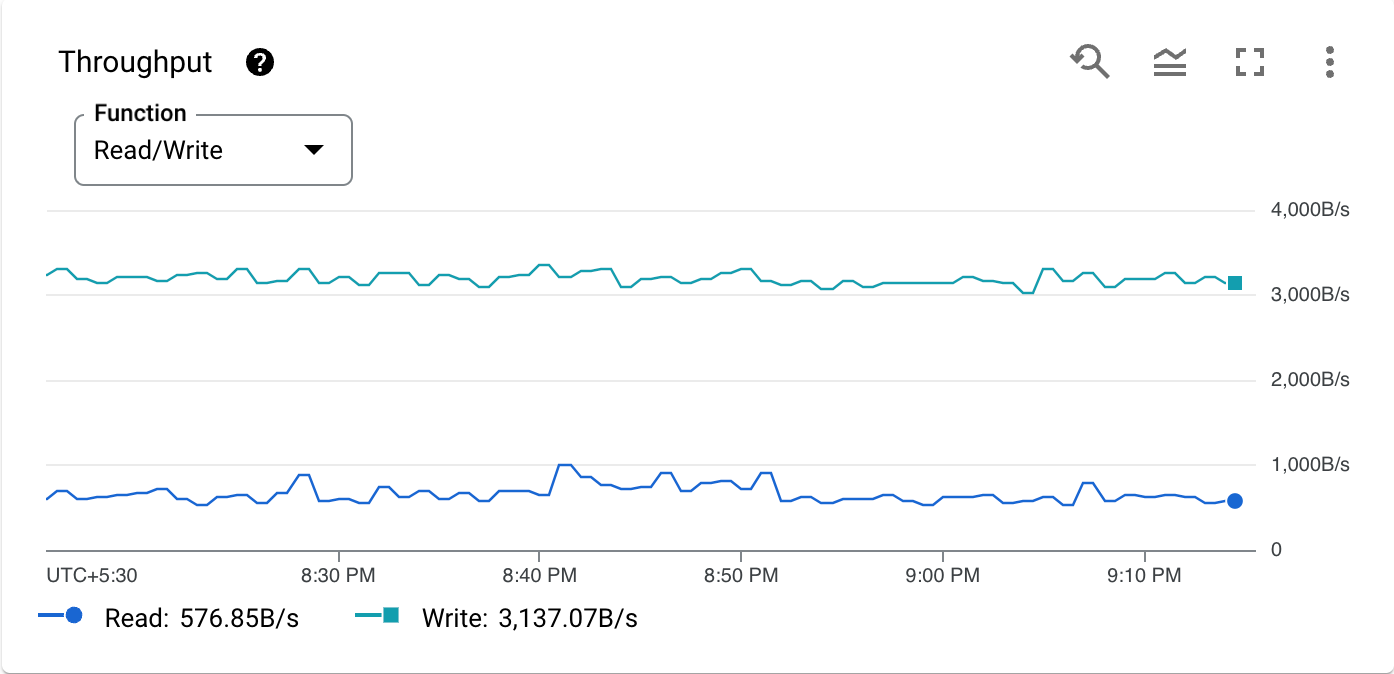
La barra degli strumenti di ogni grafico fornisce le seguenti opzioni standard. Alcuni elementi sono nascosti a meno che non tieni il puntatore sopra il grafico.
Per aumentare lo zoom di una sezione specifica di un grafico, trascina il puntatore sulla sezione che vuoi visualizzare. Questa azione imposta un intervallo di tempo personalizzato, che puoi modificare o ripristinare con il filtro dell'intervallo di tempo.
Per visualizzare una descrizione del grafico e dei relativi dati, fai clic su help.
Per visualizzare i filtri e i raggruppamenti applicati al grafico, fai clic su info.
Per creare un avviso basato sui dati del grafico, fai clic su add_alert.
Per esplorare i dati nel grafico, fai clic su query_stats.
Per visualizzare altre opzioni per il grafico, fai clic su more_vert Altre opzioni per il grafico.
Per visualizzare un grafico in modalità a schermo intero, fai clic su Visualizza a schermo intero. Puoi uscire dalla modalità a schermo intero facendo clic su Annulla o premendo Esc.
Per espandere o comprimere la legenda del grafico, fai clic su Espandi/Comprimi legenda grafico.
Per scaricare il grafico, fai clic su Scarica e poi seleziona un formato di download.
Per modificare il formato visivo del grafico, fai clic su Modalità e seleziona una modalità di visualizzazione.
Per visualizzare la metrica in Esplora metriche, fai clic su Visualizza in Esplora metriche. Puoi visualizzare altre metriche Spanner in Metrics Explorer dopo aver selezionato il tipo di risorsa Database Spanner.
La seguente tabella descrive i grafici visualizzati per impostazione predefinita nella dashboard
approfondimenti del sistema. Viene elencato il tipo di metrica per ogni grafico. Le stringhe del tipo di metrica
seguono questo prefisso: spanner.googleapis.com/. Il tipo
di metrica descrive le misurazioni che possono essere raccolte da una risorsa monitorata.
| Nome del grafico e tipo di metrica |
Descrizione | Disponibile per le istanze | Disponibile per i database |
|---|---|---|---|
|
Sequenza temporale dell'integrità del quorum a due regioni instance/dual_region_quorum_availability |
Questo grafico viene mostrato solo per le configurazioni di istanze a due regioni. Mostra l'integrità di tre quorum: il quorum a due regioni ( Global) e il quorum a una regione in ogni regione
(ad esempio, Sydney e Melbourne).
Mostra una barra arancione nella sequenza temporale in caso di interruzione del servizio. Puoi passare il mouse sopra la barra per visualizzare l'ora di inizio e di fine dell'interruzione. Utilizza questo grafico insieme alle metriche relative a tassi di errore e latenza per prendere decisioni di failover autogestite in caso di errori a livello di regione. Per saperne di più, consulta Failover e failback. Per eseguire manualmente il failover e il failback, vedi Modificare il quorum a doppia regione. |
done |
done |
Utilizzo della CPU per priorità instance/cpu/utilization_by_priority |
La percentuale delle risorse della CPU dell'istanza per le attività ad alta, media, bassa o tutte le priorità. Queste attività includono le richieste che avvii e le attività di manutenzione che Spanner deve completare tempestivamente. Per le istanze a due regioni o multiregionali, le metriche vengono raggruppate per regione e priorità. Scopri di più sulle attività ad alta priorità. Scopri di più sull'utilizzo della CPU. |
done |
close |
|
Utilizzo della CPU per regione instance/cpu/utilization_by_priority |
Utilizzo della CPU nell'istanza o nel database selezionati, raggruppato per regione. | done |
done |
|
Utilizzo della CPU per database instance/cpu/utilization_by_priority |
Utilizzo della CPU nell'istanza selezionata, raggruppato per database e regione. | done |
close |
|
Utilizzo della CPU per utente/sistema instance/cpu/utilization_by_priority |
Utilizzo della CPU nell'istanza o nel database selezionato, raggruppato per attività utente e di sistema e per priorità. | done |
done |
Utilizzo della CPU per tipo di operazione instance/cpu/utilization_by_operation_type |
Un grafico a barre in pila dell'utilizzo della CPU come percentuale delle risorse della CPU dell'istanza, raggruppato per operazioni avviate dall'utente, ad esempio letture, scritture e commit. Utilizza questa metrica per ottenere una suddivisione dettagliata dell'utilizzo della CPU e per risolvere ulteriormente i problemi, come spiegato in Indagine sull'utilizzo elevato della CPU. Puoi filtrare ulteriormente in base alla priorità delle attività utilizzando l'elenco delle opzioni. Per le istanze a due regioni o multiregionali, le metriche nel grafico a linee mostrano la percentuale media tra le regioni. |
done |
done |
Utilizzo della CPU (media mobile su 24 ore) instance/cpu/smoothed_utilization |
Una media mobile dell'utilizzo totale della CPU Spanner, come percentuale delle risorse della CPU dell'istanza, per ogni database. Ogni punto dati è una media delle 24 ore precedenti. |
done |
close |
Latenza api/request_latencies |
Il tempo impiegato da Spanner per gestire una richiesta di lettura o scrittura. Questa misurazione inizia quando Spanner riceve una richiesta e termina quando Spanner inizia a inviare una risposta. Puoi visualizzare le metriche di latenza per il 50° e il 99° percentile utilizzando l'elenco delle opzioni. |
close |
done |
Latenza per database api/request_latencies |
Il tempo impiegato da Spanner per gestire una richiesta di lettura o scrittura, raggruppata per database. Questa misurazione inizia quando Spanner riceve una richiesta e termina quando Spanner inizia a inviare una risposta. Puoi visualizzare le metriche per la latenza del 50° e del 99° percentile utilizzando l'elenco delle visualizzazioni in questo grafico. |
done |
close |
Latenza per metodo API api/request_latencies |
Il tempo impiegato da Spanner per gestire una richiesta, raggruppato per metodi API Spanner. Questa misurazione inizia quando Spanner riceve una richiesta e termina quando Spanner inizia a inviare una risposta. Puoi visualizzare le metriche per le latenze del 50° e del 99° percentile utilizzando l'elenco di visualizzazione in questo grafico. |
close |
done |
Latenza delle transazioni api/request_latencies_by_transaction_type |
Il tempo impiegato da Spanner per elaborare una transazione. Puoi scegliere di visualizzare le metriche per le transazioni di tipo lettura/scrittura e sola lettura. La differenza principale tra il grafico della latenza e il grafico della latenza delle transazioni è che quest'ultimo ti consente di visualizzare il coinvolgimento del leader per il tipo di sola lettura. Le letture che coinvolgono il leader potrebbero riscontrare una latenza maggiore. Puoi utilizzare questo grafico per valutare se devi utilizzare letture non aggiornate senza comunicare con il leader, supponendo che il limite del timestamp sia di almeno 15 secondi. Per le transazioni di lettura-scrittura, il leader è sempre coinvolto nella transazione, quindi i dati mostrati nel grafico includono sempre il tempo impiegato dalla richiesta per raggiungere il leader e ricevere una risposta. La località corrisponde alla regione del frontend dell'API Cloud Spanner. Puoi visualizzare le metriche per le latenze del 50° e del 99° percentile utilizzando l'elenco di visualizzazione in questo grafico. |
close |
done |
Latenza transazione per database api/request_latencies_by_transaction_type |
Il tempo impiegato da Spanner per elaborare una transazione. La differenza principale tra il grafico Latenza e il grafico Latenza transazione per database è che quest'ultimo ti consente di visualizzare il coinvolgimento del leader per il tipo di sola lettura. Le letture che coinvolgono il leader potrebbero riscontrare una latenza maggiore. Puoi utilizzare questo grafico per valutare se devi utilizzare letture obsolete senza comunicare con il leader, supponendo che il limite temporale sia di almeno 15 secondi. Per le transazioni di lettura-scrittura, il leader è sempre coinvolto nella transazione, quindi i dati mostrati nel grafico includono sempre il tempo impiegato dalla richiesta per raggiungere il leader e ricevere una risposta. La località corrisponde alla regione del frontend dell'API Cloud Spanner. Puoi visualizzare le metriche per le latenze del 50° e del 99° percentile utilizzando l'elenco di visualizzazione in questo grafico. |
done |
close |
Latenza transazione per metodo API api/request_latencies_by_transaction_type |
Il tempo impiegato da Spanner per elaborare una transazione. La differenza principale tra il grafico Latenza e il grafico Latenza transazione per metodo API è che quest'ultimo consente di visualizzare il coinvolgimento del leader per il tipo di sola lettura. Le letture che coinvolgono il leader potrebbero avere una latenza maggiore. Puoi utilizzare questo grafico per valutare se devi utilizzare letture non aggiornate senza comunicare con il leader, supponendo che il limite del timestamp sia di almeno 15 secondi. Per le transazioni di lettura-scrittura, il leader è sempre coinvolto nella transazione, quindi i dati mostrati nel grafico includono sempre il tempo impiegato dalla richiesta per raggiungere il leader e ricevere una risposta. La località corrisponde alla regione del frontend dell'API Cloud Spanner. |
close |
done |
Operazioni al secondo api/api_request_count |
Il numero di operazioni di lettura e scrittura eseguite da Spanner al secondo o il numero di errori del server Spanner al secondo. Puoi scegliere quali operazioni visualizzare in questo grafico:
|
close |
done |
Operazioni al secondo per database api/api_request_count |
Il numero di operazioni di lettura e scrittura eseguite da Spanner al secondo o il numero di errori del server Spanner al secondo. Questo grafico è raggruppato per database. Puoi scegliere quali operazioni visualizzare in questo grafico:
|
done |
close |
Operazioni al secondo per metodo API api/api_request_count |
Il numero di operazioni eseguite da Spanner al secondo, raggruppate per metodo API Spanner |
close |
done |
Throughput api/sent_bytes_count (lettura) api/received_bytes_count (scrittura) |
La quantità di dati non compressi letti e scritti nel database ogni secondo. Questo valore è misurato in byte binari, ad esempio KiB, MiB o GiB. Il throughput di lettura include richieste e risposte per i metodi nell'API di lettura e per le query SQL. Include anche richieste e risposte per le istruzioni DML. Il throughput di scrittura include richieste e risposte per il commit dei dati tramite l'API Mutation. Sono escluse le richieste e le risposte per le istruzioni DML. |
close |
done |
Throughput per database api/sent_bytes_count (lettura) api/received_bytes_count (scrittura) |
La quantità di dati non compressi letti e scritti nell'istanza ogni secondo, raggruppati per database. Questo valore è misurato in byte binari, ad esempio KiB, MiB o GiB. Il throughput di lettura include richieste e risposte per i metodi nell'API di lettura e per le query SQL. Include anche richieste e risposte per le istruzioni DML. Il throughput di scrittura include richieste e risposte per il commit dei dati tramite l'API Mutation. Sono escluse le richieste e le risposte per le istruzioni DML. |
done |
close |
Throughput per metodo API api/sent_bytes_count (lettura) api/received_bytes_count (scrittura) |
La quantità di dati non compressi letti o scritti nell'istanza o nel database ogni secondo, raggruppati per metodo API. Questo valore è misurato in byte binari, ad esempio KiB, MiB o GiB. Il throughput di lettura include richieste e risposte per i metodi nell'API di lettura e per le query SQL. Include anche richieste e risposte per le istruzioni DML. Il throughput di scrittura include richieste e risposte per il commit dei dati tramite l'API Mutation. Sono escluse le richieste e le risposte per le istruzioni DML. |
close |
done |
Spazio di archiviazione totale instance/storage/used_bytes |
La quantità di dati archiviati nel database. Questo valore è misurato in byte binari, ad esempio KiB, MiB o GiB. |
close |
done |
Spazio di archiviazione totale del database per database instance/storage/used_bytes |
La quantità di dati archiviati nell'istanza, raggruppati per database. Questo valore è misurato in byte binari, ad esempio KiB, MiB o GiB. |
done |
close |
Spazio di archiviazione di backup totale instance/backup/used_bytes |
La quantità di dati archiviata nei backup associati al database. Questo valore è misurato in byte binari, ad esempio KiB, MiB o GiB. |
close |
done |
Tempo di attesa per il blocco lock_stat/total/lock_wait_time |
Il tempo di attesa del blocco per una transazione è il tempo necessario per acquisire un blocco su una risorsa detenuta da un'altra transazione. Il tempo di attesa totale per il blocco per i conflitti di blocco viene registrato per l'intero database. |
close |
done |
Tempo di attesa per il blocco per database lock_stat/total/lock_wait_time |
Il tempo di attesa per il blocco per una transazione è il tempo necessario per acquisire un blocco su una risorsa detenuta da un'altra transazione, raggruppato per database. Il tempo di attesa totale per i conflitti di blocco viene registrato per l'intera istanza. |
done |
close |
Spazio di archiviazione totale di backup per database instance/backup/used_bytes |
La quantità di dati archiviata nei backup associati all'istanza, raggruppata per database. Questo valore è misurato in byte binari, ad esempio KiB, MiB o GiB. |
done |
close |
Capacità di calcolo istanza/unità_di_elaborazione istanza/nodi |
La capacità di calcolo è la quantità di unità di elaborazione o nodi disponibili in un'istanza. Puoi scegliere di visualizzare la capacità in unità di elaborazione o in nodi. |
done |
close |
Distribuzione leader instance/leader_percentage_by_region |
Per le istanze a due o più regioni, puoi visualizzare il numero di database con la maggior parte dei leader (>=50%) in una determinata regione. Nel menu Regioni, se selezioni una regione specifica, il grafico mostra il numero totale di database all'interno di quell'istanza che hanno la regione selezionata come regione leader. Se selezioni Tutte le regioni nel menu dell'elenco Regioni, il grafico mostra una riga per ogni regione e ogni riga mostra il numero totale di database nell'istanza che ha quella regione come regione leader. Per i database in un'istanza a due o più regioni, puoi visualizzare la percentuale di leader raggruppati per regione. Ad esempio, se un database ha cinque leader, uno in us-west1 e quattro in us-east1 in un
momento specifico, il grafico "Tutte le regioni" mostra due linee (una per regione). Una
linea per us-west1 è al 20% e l'altra linea per
us-east1 è all'80%. Il grafico us-west1 mostra una
singola linea al 20%, mentre il grafico us-east1 mostra una singola linea all'80%.Tieni presente che se un database è stato creato di recente o se una regione leader è stata modificata di recente, i grafici potrebbero non stabilizzarsi immediatamente. Questo grafico è disponibile solo per le istanze a due regioni e più regioni. |
done |
done |
Punteggio utilizzo CPU con suddivisioni massime instance/peak_split_peak |
L'utilizzo massimo della CPU con suddivisioni massime osservato in tutte le suddivisioni di un database. Questa metrica mostra la percentuale di risorse dell'unità di elaborazione utilizzate in una divisione. Una percentuale superiore al 50% indica una suddivisione calda, il che significa che la suddivisione utilizza la metà delle risorse dell'unità di elaborazione del server host. Una percentuale del 100% indica una suddivisione molto attiva, ovvero una suddivisione che utilizza la maggior parte delle risorse dell'unità di elaborazione del server host. Spanner utilizza la suddivisione basata sul carico per risolvere gli hotspot e bilanciare il carico. Tuttavia, Spanner potrebbe non essere in grado di bilanciare il carico, anche dopo diversi tentativi di suddivisione, a causa di pattern problematici nell'applicazione. Pertanto, i punti di accesso che durano almeno 10 minuti potrebbero richiedere ulteriore risoluzione dei problemi e potrebbero potenzialmente richiedere modifiche all'applicazione. Per maggiori informazioni, vedi Trovare gli hotspot nelle frazioni. | done |
done |
|
Chiamate a servizio remoto query_stat/total/remote_service_calls_count |
Numero di chiamate di servizi remoti, raggruppate per servizio e codici di risposta. Risponde con un codice di risposta HTTP, ad esempio 200 o 500. |
done |
done |
|
Latenza: chiamate a servizio remoto query_stat/total/remote_service_calls_latencies |
La latenza delle chiamate a servizio remoto, raggruppate per servizio. Puoi visualizzare le metriche di latenza per il 50° e il 99° percentile utilizzando l'elenco delle opzioni. |
done |
done |
|
Righe elaborate dal servizio remoto query_stat/total/remote_service_processed_rows_count |
Numero di righe elaborate da un servizio remoto, raggruppate per servizio e codici di risposta. Risponde con un codice di risposta HTTP, ad esempio 200 o 500. |
done |
done |
|
Latenza: righe di servizio remoto query_stat/total/remote_service_processed_rows_latencies |
Numero di righe elaborate da un servizio remoto, raggruppate per servizio e codici di risposta. Puoi visualizzare le metriche di latenza per il 50° e il 99° percentile utilizzando l'elenco delle opzioni. |
done |
done |
|
Byte di rete del servizio remoto query_stat/total/remote_service_network_bytes_sizes |
Byte di rete scambiati con il servizio remoto, raggruppati per servizio e direzione. Questo valore è misurato in byte binari, ad esempio KiB, MiB o GiB. La direzione si riferisce al traffico inviato o ricevuto. Puoi visualizzare le metriche per il 50° e il 99° percentile dello scambio di byte di rete utilizzando l'elenco delle opzioni. |
done |
done |
|
Chiamate di microservizi query_stat/total/remote_service_calls_count |
Numero di chiamate di microservizi, raggruppate per microservizio e codice di risposta. | done |
done |
|
Latenza: chiamate di microservizi query_stat/total/remote_service_calls_latencies |
Latenze delle chiamate di microservizi, raggruppate per microservizio. | done |
done |
Archiviazione dei database per tabella (nessuno) |
La quantità di dati archiviata nell'istanza o nel database, raggruppata per tabelle nel database selezionato. Questo valore è misurato in byte binari, ad esempio KiB, MiB o GiB. Questo grafico ottiene i dati eseguendo query su SPANNER_SYS.TABLE_SIZES_STATS_1HOUR. Per ulteriori informazioni, vedi
Statistiche sulle dimensioni delle tabelle. |
close |
done |
Tabelle più utilizzate per operazioni (nessuno) |
Le 15 tabelle e i 15 indici più utilizzati nell'istanza o nel database, determinati dal numero di operazioni di lettura, scrittura o eliminazione. Questo grafico ottiene i dati eseguendo query sulle tabelle delle statistiche delle operazioni della tabella. Per saperne di più, consulta Statistiche sulle operazioni sulle tabelle. |
close |
done |
Tabelle meno utilizzate per operazioni (nessuno) |
Le 15 tabelle e indici meno utilizzati nell'istanza o nel database, determinati dal numero di operazioni di lettura, scrittura o eliminazione. Questo grafico ottiene i dati eseguendo query sulle tabelle delle statistiche delle operazioni della tabella. Per saperne di più, consulta Statistiche sulle operazioni sulle tabelle. |
close |
done |
Grafici e metriche del gestore della scalabilità automatica gestito
Oltre alle opzioni mostrate nella sezione precedente, quando una VM ha la scalabilità automatica gestita abilitata, il grafico della capacità di calcolo ha il pulsante Visualizza log. Quando fai clic su questo pulsante, vengono visualizzati i log dello strumento di scalabilità automatica gestito.
Sono disponibili le seguenti metriche per le istanze per cui è attivato lo strumento di scalabilità automatica gestito.
| Nome e tipo di metrica | Descrizione |
|---|---|
| Capacità di computing | Con i nodi selezionati. |
|
instance/autoscaling/min_node_count |
Numero minimo di nodi che il gestore della scalabilità automatica è configurato per allocare all'istanza. |
|
instance/autoscaling/max_node_count |
Numero massimo di nodi che il gestore della scalabilità automatica è configurato per allocare all'istanza. |
|
instance/autoscaling/recommended_node_count_for_cpu |
Numero consigliato di nodi in base all'utilizzo della CPU dell'istanza. |
|
instance/autoscaling/recommended_node_count_for_storage |
Numero consigliato di nodi in base all'utilizzo dello spazio di archiviazione dell'istanza. |
| Capacità di computing | Con le unità di elaborazione selezionate. |
|
instance/autoscaling/min_processing_units |
Numero minimo di unità di elaborazione che il gestore della scalabilità automatica è configurato per allocare all'istanza. |
|
instance/autoscaling/max_processing_units |
Numero massimo di unità di elaborazione per cui è configurato il gestore della scalabilità automatica da allocare all'istanza. |
|
instance/autoscaling/recommended_processing_units_for_cpu |
Numero consigliato di unità di elaborazione. Questo consiglio si basa sull'utilizzo precedente della CPU dell'istanza. |
|
instance/autoscaling/recommended_processing_units_for_storage |
Numero consigliato di unità di elaborazione da utilizzare. Questo suggerimento si basa sull'utilizzo precedente dello spazio di archiviazione dell'istanza. |
| Utilizzo della CPU per priorità | |
|
instance/autoscaling/high_priority_cpu_utilization_target |
Target di utilizzo ad alta priorità della CPU da utilizzare per la scalabilità automatica. |
| Spazio di archiviazione totale | Con le unità di elaborazione selezionate. |
|
instance/storage/limit_bytes |
Limite di spazio di archiviazione per l'istanza in byte. |
|
instance/autoscaling/storage_utilization_target |
Target di utilizzo dello spazio di archiviazione da utilizzare per la scalabilità automatica. |
Grafici e metriche dell'archiviazione a livelli
Per le istanze che utilizzano l'archiviazione a livelli sono disponibili le seguenti metriche.
| Nome e tipo di metrica | Descrizione |
|---|---|
| instance/storage/used_bytes | Byte totali di dati archiviati su spazio di archiviazione SSD e HDD. |
| instance/storage/combined/limit_bytes | Limiti di spazio di archiviazione combinati SSD e HDD. |
| instance/storage/combined/limit_per_processing_unit | Limite di archiviazione combinato SSD e HDD per ogni unità di elaborazione. |
| instance/storage/combined/utilization | Spazio di archiviazione SSD e HDD combinato utilizzato, rispetto al limite di spazio di archiviazione combinato. |
| instance/disk_load | Utilizzo del carico dell'HDD. |
Conservazione dei dati
Il periodo massimo di conservazione dei dati per la maggior parte delle metriche nella dashboard approfondimenti di sistema è di
6 settimane. Tuttavia, per il grafico
Spazio di archiviazione del database per tabella, i dati vengono utilizzati dalla
tabella SPANNER_SYS.TABLE_SIZES_STATS_1HOUR (anziché da Spanner), che ha un periodo di conservazione massimo di 30 giorni.
Per scoprire di più, consulta la sezione
Conservazione dei dati.
Visualizzare la dashboard degli approfondimenti sul sistema
Per visualizzare la pagina Approfondimenti del sistema, devi disporre delle seguenti autorizzazioni Identity and Access Management (IAM) oltre alle autorizzazioni Spanner e alle autorizzazioni Spanner a livello di istanza e database:
spanner.databases.beginReadOnlyTransactionspanner.databases.selectspanner.sessions.create
Per ulteriori informazioni sulle autorizzazioni IAM di Spanner, consulta Controllo dell'accesso con IAM.
Se abiliti il gestore della scalabilità automatica gestito sulla tua istanza, devi disporre anche delle autorizzazioni logging.logEntries.list, logging.logs.list e logging.logServices.list per visualizzare i log del gestore della scalabilità automatica gestito.
Per saperne di più su questa autorizzazione, consulta Ruoli predefiniti.
Per visualizzare la dashboard approfondimenti del sistema:
Nella console Google Cloud , apri l'elenco delle istanze Spanner.
Esegui una di queste operazioni:
Per visualizzare le metriche di un'istanza, fai clic sul nome dell'istanza che ti interessa, poi fai clic su Approfondimenti di sistema nel menu di navigazione.
Per visualizzare le metriche di un database, fai clic sul nome dell'istanza, seleziona un database, poi fai clic su Approfondimenti di sistema nel menu di navigazione.
(Facoltativo) Per visualizzare i dati storici per un periodo di tempo diverso, individua i pulsanti in alto a destra della pagina, quindi fai clic sul periodo di tempo che vuoi visualizzare.
(Facoltativo) Per controllare quali dati vengono visualizzati nel grafico, fai clic su uno degli elenchi nel grafico. Ad esempio, se l'istanza utilizza una configurazione a due regioni o multiregionale, alcuni grafici forniscono un elenco per visualizzare i dati di una regione specifica. Non tutti i grafici hanno elenchi di visualizzazioni.
Passaggi successivi
- Comprendi le metriche Utilizzo della CPU e Latenza per Spanner.
- Configura grafici e avvisi personalizzati con Monitoring.
- Scopri di più sui tipi di istanze Spanner.