Descripción general
En esta página, se proporcionan conceptos sobre los planes de ejecución de consultas y cómo Spanner los usa para realizar consultas en un entorno distribuido. Si quieres aprender a recuperar un plan de ejecución para una consulta específica con la consola de Google Cloud, consulta Comprende cómo Spanner ejecuta las consultas. También puedes ver los planes de consultas históricos de muestra y comparar el rendimiento de una consulta a lo largo del tiempo para algunas consultas. Para obtener más información, consulta Planes de consulta de muestra.
Spanner usa instrucciones de SQL declarativas para consultar sus bases de datos. Las instrucciones de SQL definen lo que el usuario quiere sin especificar cómo obtener los resultados. Un plan de ejecución de consultas es el conjunto de pasos para saber cómo obtener los resultados. Para una instrucción de SQL determinada, puede haber varias formas de obtener los resultados. El optimizador de consultas de Spanner evalúa los diferentes planes de ejecución y elige el que considera más eficiente. Luego, Spanner usa el plan de ejecución para recuperar los resultados.
De forma conceptual, un plan de ejecución es un árbol de operadores relacionales. Cada operador lee filas de sus entradas y produce filas de salida. El resultado del operador en la raíz de la ejecución se muestra como resultado de la consulta de SQL.
Por ejemplo:
SELECT s.SongName FROM Songs AS s;
Mediante la consulta anterior, se obtiene como resultado un plan de ejecución de consultas que se puede visualizar de la siguiente manera:
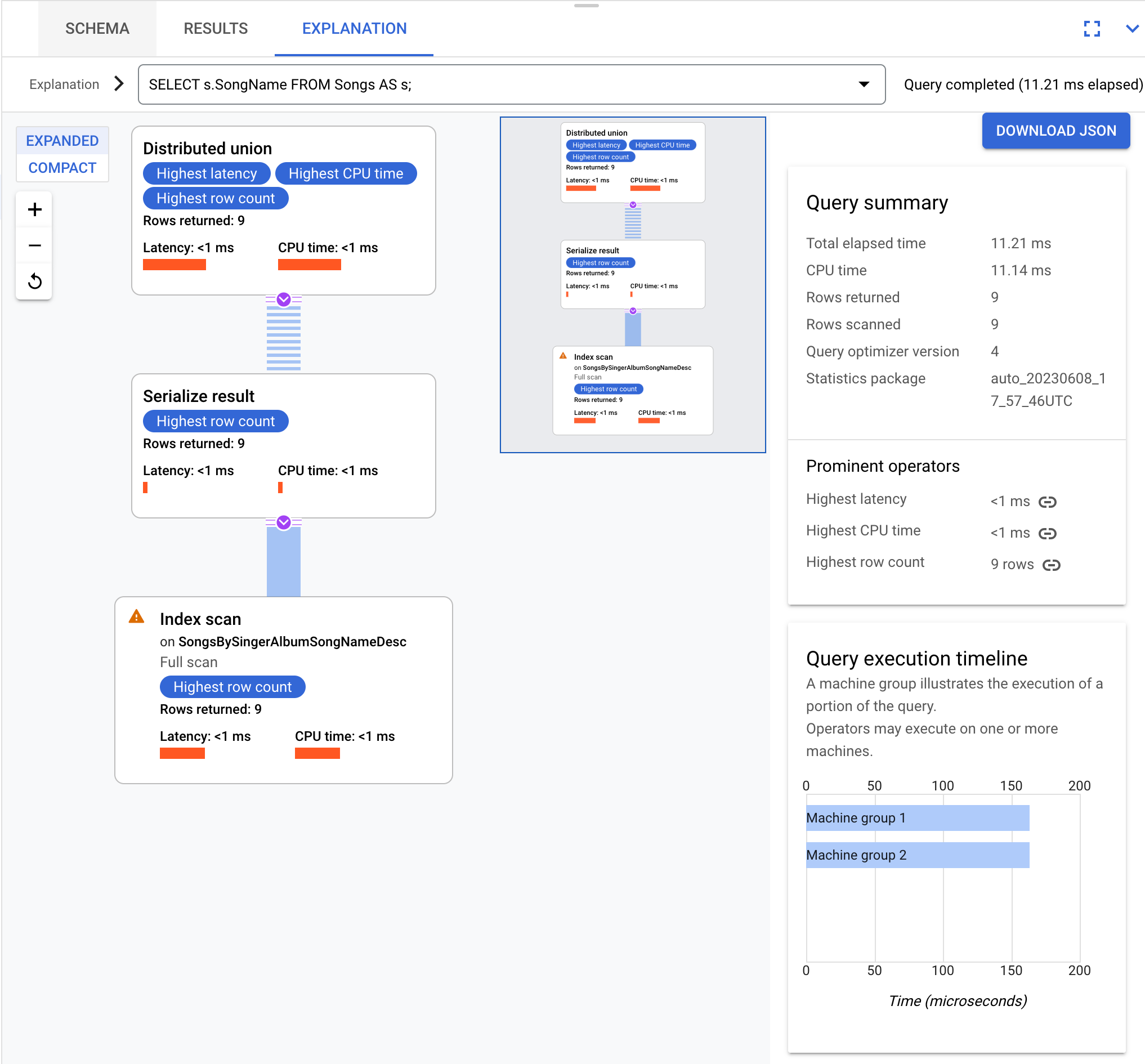
Las consultas y los planes de ejecución en esta página se basan en el siguiente esquema de base de datos:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
Puedes usar las siguientes declaraciones del lenguaje de manipulación de datos (DML) para agregar datos a estas tablas:
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
Obtener planes de ejecución eficientes es un desafío porque Spanner divide los datos en divisiones. Las divisiones se pueden mover de forma independiente unas de otras y pueden asignarse a servidores distintos, que pueden estar en diferentes ubicaciones físicas. Para evaluar los planes de ejecución sobre los datos distribuidos, Spanner usa la ejecución en función de lo siguiente:
- la ejecución local de subplanes en servidores que contienen los datos
- la organización y agregación de varias ejecuciones remotas con una fuerte reducción de la distribución
Spanner usa el operador primitivo distributed union, junto con sus variantes distributed cross apply y distributed outer apply, para habilitar este modelo.
Planes de consultas de muestra
Los planes de consultas de muestra de Spanner te permiten ver muestras de planes de consultas históricos y comparar el rendimiento de una consulta a lo largo del tiempo. No todas las consultas tienen planes de consultas de muestra disponibles. Solo se pueden muestrear consultas que consumen más CPU. La retención de datos para las muestras de planes de consultas de Spanner es de 30 días. Puedes encontrar muestras de planes de consultas en la página Estadísticas de consultas de la consola de Google Cloud. Para obtener instrucciones, visita Visualiza planes de consulta de muestra.
La anatomía de un plan de consultas de muestra es la misma que un plan de ejecución de consultas normal. Si quieres obtener más información para comprender los planes visuales y usarlos a fin de depurar tus consultas, lee Un recorrido por el visualizador del plan de consultas.
Casos de uso comunes para los planes de consultas de muestra:
Estos son algunos casos de uso comunes para los planes de consultas de muestra:
- Observar los cambios en el plan de consultas debido a los cambios en el esquema (por ejemplo, agregar o quitar un índice)
- Observar los cambios en el plan de consultas debido a una actualización de la versión del optimizador
- Observar los cambios en el plan de consultas debido a las nuevas estadísticas del optimizador, que se recopilan cada tres días de forma automática o se realizan de forma manual con el comando
ANALYZE
Si el rendimiento de una consulta muestra una diferencia significativa a lo largo del tiempo o si deseas mejorar el rendimiento de una consulta, consulta las Prácticas recomendadas de SQL para crear instrucciones de consulta optimizadas que ayuden a Spanner a encontrar planes de ejecución eficientes.
El ciclo de una consulta
Una consulta en SQL en Spanner primero se compila en un plan de ejecución y, luego, se envía a un servidor raíz inicial para su ejecución. El servidor raíz se elige a fin de minimizar el número de saltos para alcanzar los datos que se consultan. Luego, el servidor raíz hace lo siguiente:
- inicia la ejecución remota de los subplanes (si es necesario)
- espera los resultados de las ejecuciones remotas
- maneja los pasos de ejecución local restantes, como la agregación de resultados
- muestra los resultados de la consulta
Los servidores remotos que reciben un subplan actúan como un servidor “raíz” para su subplan y siguen el mismo modelo que el servidor raíz superior. El resultado es un árbol de ejecuciones remotas. De forma conceptual, la ejecución de la consulta fluye de arriba abajo y los resultados de la consulta se muestran de abajo arriba. En el siguiente diagrama, se muestra este patrón:

En los siguientes ejemplos, se ilustra este patrón con más detalle.
Consultas agregadas
Una consulta agregada implementa consultas GROUP BY.
Por ejemplo:
SELECT s.SingerId, COUNT(*) AS SongCount
FROM Songs AS s
WHERE s.SingerId < 100
GROUP BY s.SingerId;
Los resultados de la consulta anterior son los siguientes:
+----------+-----------+
| SingerId | SongCount |
+----------+-----------+
| 3 | 1 |
| 2 | 8 |
+----------+-----------+
De manera conceptual, este es el plan de ejecución:
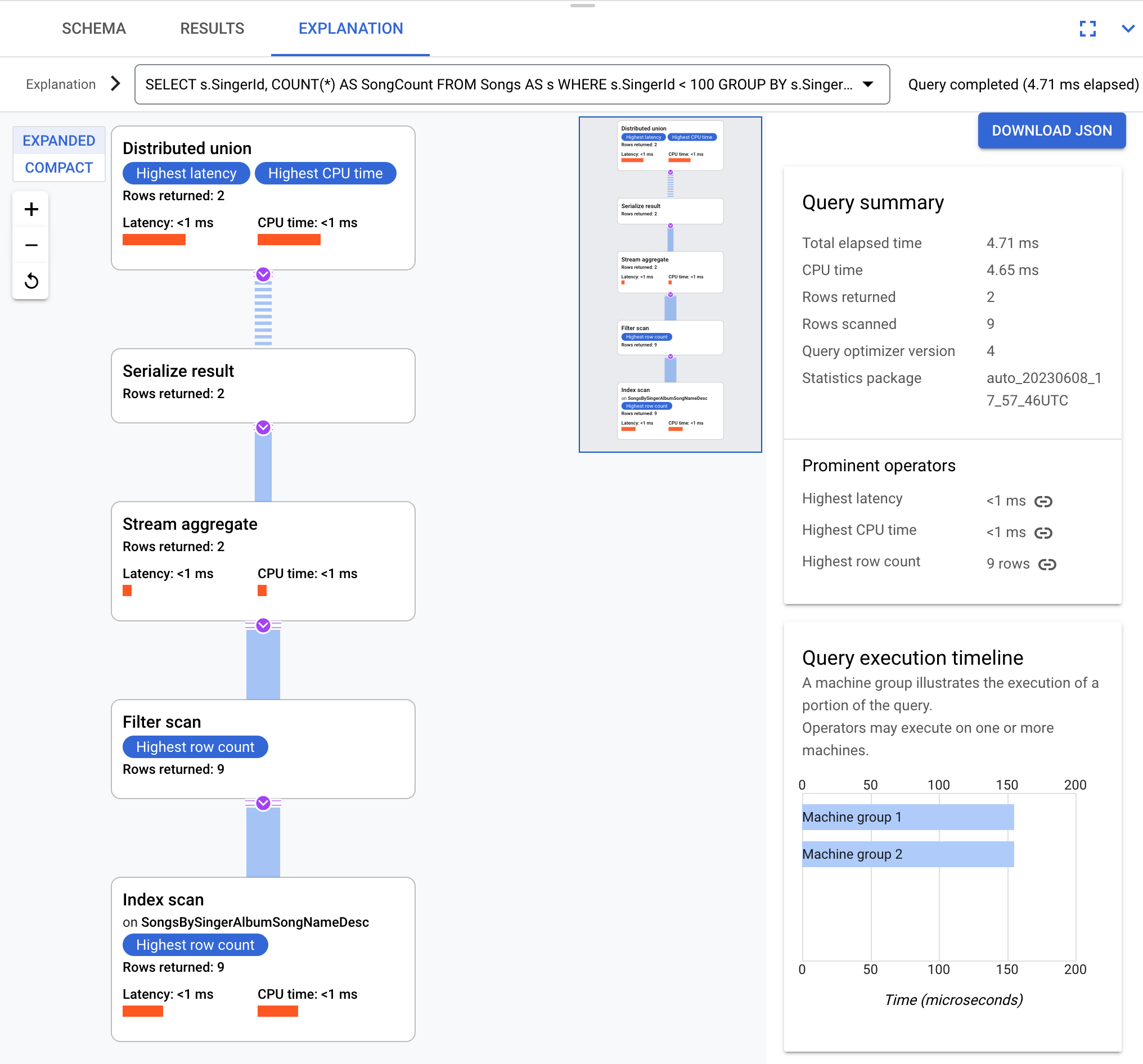
Spanner envía el plan de ejecución a un servidor raíz que coordina la ejecución de la consulta y realiza la distribución remota de los subplanes.
Este plan de ejecución comienza con una unión distribuida, que distribuye los subplanes a servidores remotos con divisiones que cumplan con SingerId < 100. Una vez que se completa el análisis en divisiones individuales, el operador de agregación de transmisión agrega filas para obtener los recuentos de cada SingerId. Luego, el operador de serialización de resultados serializa el resultado. Por último, la unión distribuida combina todos los resultados y muestra los resultados de la consulta.
Para obtener más información sobre los agregados, consulta la página sobre el operador de agregación.
Consultas de unión ubicadas en el mismo lugar
Las tablas intercaladas se almacenan de forma física con sus filas de tablas relacionadas ubicadas en el mismo lugar. Una unión ubicada en el mismo lugar es una unión entre tablas intercaladas. Las uniones ubicadas en el mismo lugar pueden ofrecer beneficios de rendimiento en comparación con las uniones que requieren índices o reversión de uniones.
Por ejemplo:
SELECT al.AlbumTitle, so.SongName
FROM Albums AS al, Songs AS so
WHERE al.SingerId = so.SingerId AND al.AlbumId = so.AlbumId;
(En esta consulta, se da por sentado que Songs está intercalado en Albums).
Los resultados de la consulta anterior son los siguientes:
+-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Nothing To Do With Me | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
+-----------------------+--------------------------+
Este es el plan de ejecución:
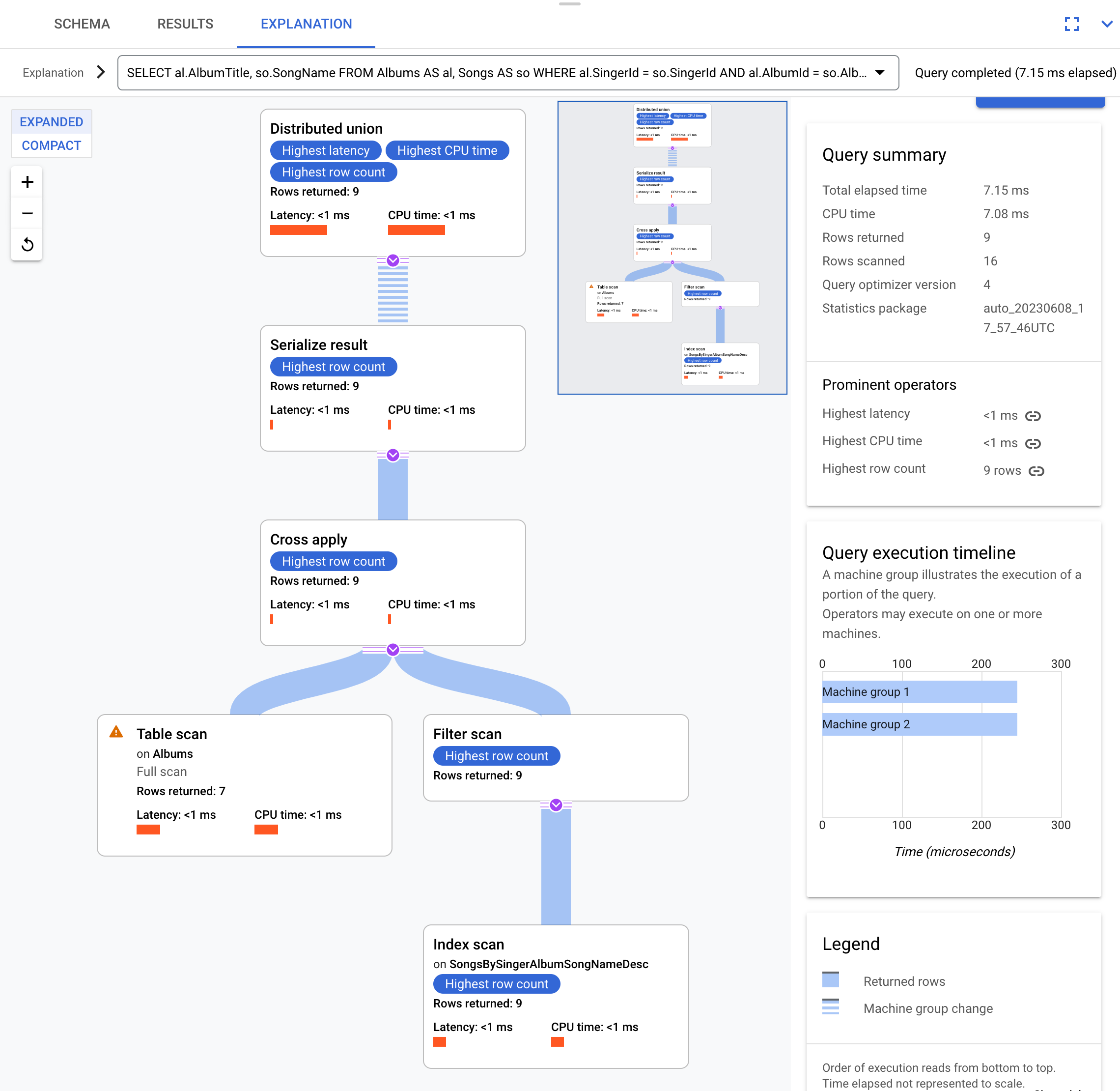
Este plan de ejecución comienza con una unión distribuida, que distribuye los subplanes a servidores remotos que tienen divisiones de la tabla Albums.
Debido a que Songs es una tabla intercalada de Albums, cada servidor remoto puede ejecutar todo el subplan en cada servidor remoto sin requerir una unión a un servidor diferente.
Los subplanes contienen una aplicación cruzada. Cada aplicación cruzada realiza un análisis de tabla en la tabla Albums para recuperar SingerId, AlbumId y AlbumTitle. Luego, la aplicación cruzada asigna el resultado del análisis de la tabla al resultado de un análisis de índice del índice SongsBySingerAlbumSongNameDesc, sujeto a un filtro del SingerId en el índice que coincide con el SingerId del resultado del análisis de la tabla. Cada aplicación cruzada envía sus resultados a un operador de serialización de resultados que serializa los datos AlbumTitle y SongName, y muestra los resultados en las uniones distribuidas locales. La unión distribuida agrega los resultados de las uniones distribuidas locales y los muestra como el resultado de la consulta.
Consultas de índices y de reversiones de uniones
En el ejemplo anterior, se usó una unión en dos tablas, una intercalada en la otra. Los planes de ejecución son más complejos y menos eficaces cuando dos tablas o una tabla y un índice no están intercalados.
Considera un índice creado con el siguiente comando:
CREATE INDEX SongsBySongName ON Songs(SongName)
Usa este índice en la siguiente consulta:
SELECT s.SongName, s.Duration
FROM Songs@{force_index=SongsBySongName} AS s
WHERE STARTS_WITH(s.SongName, "B");
Los resultados de la consulta anterior son los siguientes:
+----------+----------+
| SongName | Duration |
+----------+----------+
| Blue | 238 |
+----------+----------+
Este es el plan de ejecución:
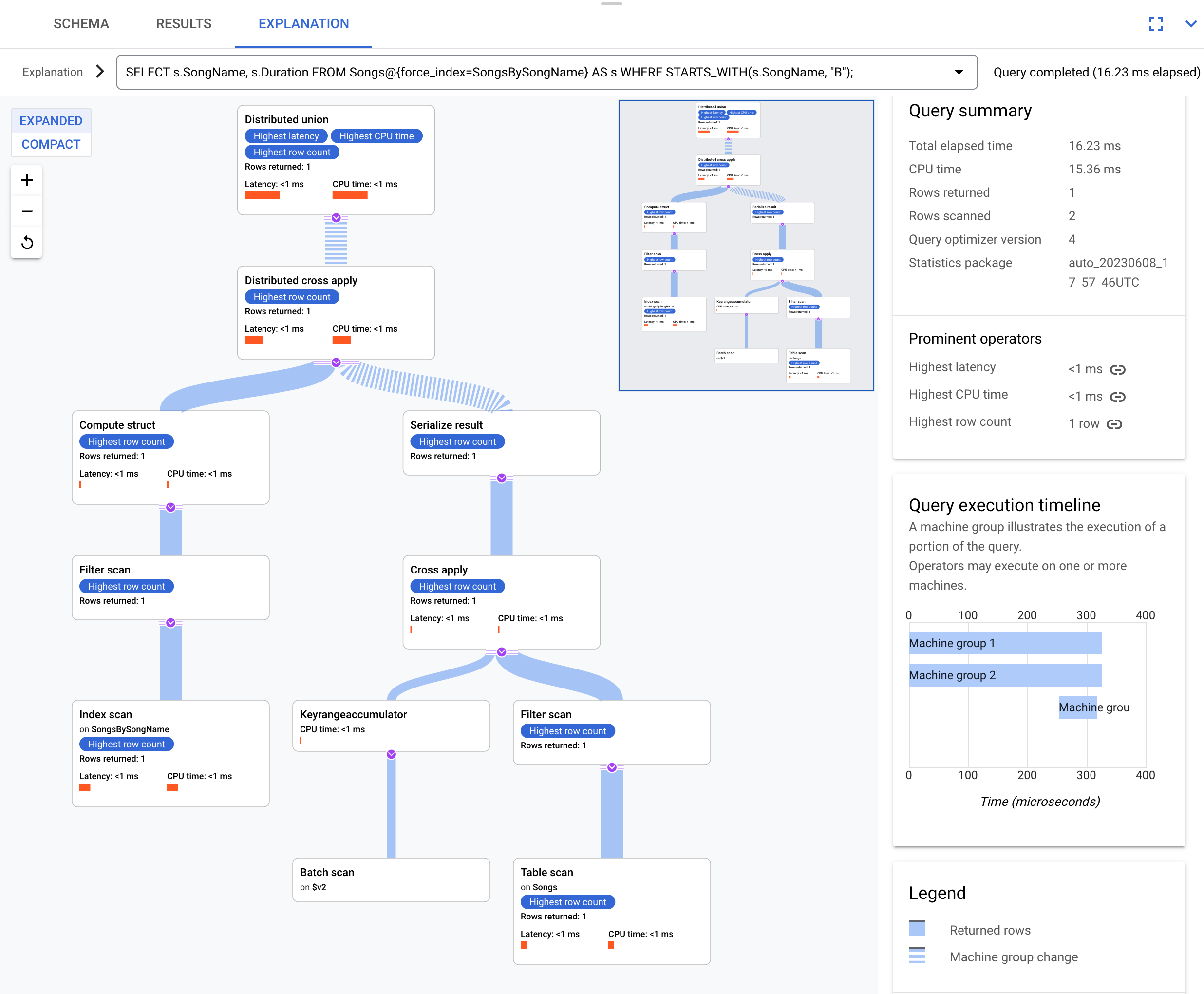
El plan de ejecución resultante es complicado porque el índice SongsBySongName no contiene la columna Duration. Para obtener el valor Duration, Spanner necesita revertir la unión de los resultados indexados a la tabla Songs. Esta es una unión, pero no se ubica en el mismo lugar porque la tabla Songs y el índice global SongsBySongName no están intercalados. El plan de ejecución resultante es más complejo que el ejemplo de unión ubicada en el mismo lugar, ya que Spanner realiza optimizaciones para acelerar la ejecución si los datos no se encuentran en el mismo lugar.
El operador principal es una aplicación distribuida cruzada. La entrada de este operador son lotes de filas del índice SongsBySongName que cumplen con el predicado STARTS_WITH(s.SongName, "B"). Luego, la aplicación distribuida cruzada asigna estos lotes a servidores remotos, cuyas divisiones contienen los datos de Duration. Los servidores remotos usan un análisis de la tabla para recuperar la columna Duration.
El análisis de la tabla usa el filtro Condition:($Songs_key_TrackId' =
$batched_Songs_key_TrackId), que une TrackId de la tabla Songs con TrackId de las filas que se agruparon en lotes del índice SongsBySongName.
Los resultados se agregan a la respuesta final de la consulta. A su vez, el lado de entrada de la aplicación distribuida cruzada contiene un par de unión distribuida y unión distribuida local para evaluar las filas del índice que cumplen con el predicado STARTS_WITH.
Considera hacer una consulta un poco diferente, que no seleccione la columna s.Duration:
SELECT s.SongName
FROM Songs@{force_index=SongsBySongName} AS s
WHERE STARTS_WITH(s.SongName, "B");
Esta consulta puede aprovechar al máximo el índice como se muestra en este plan de ejecución:
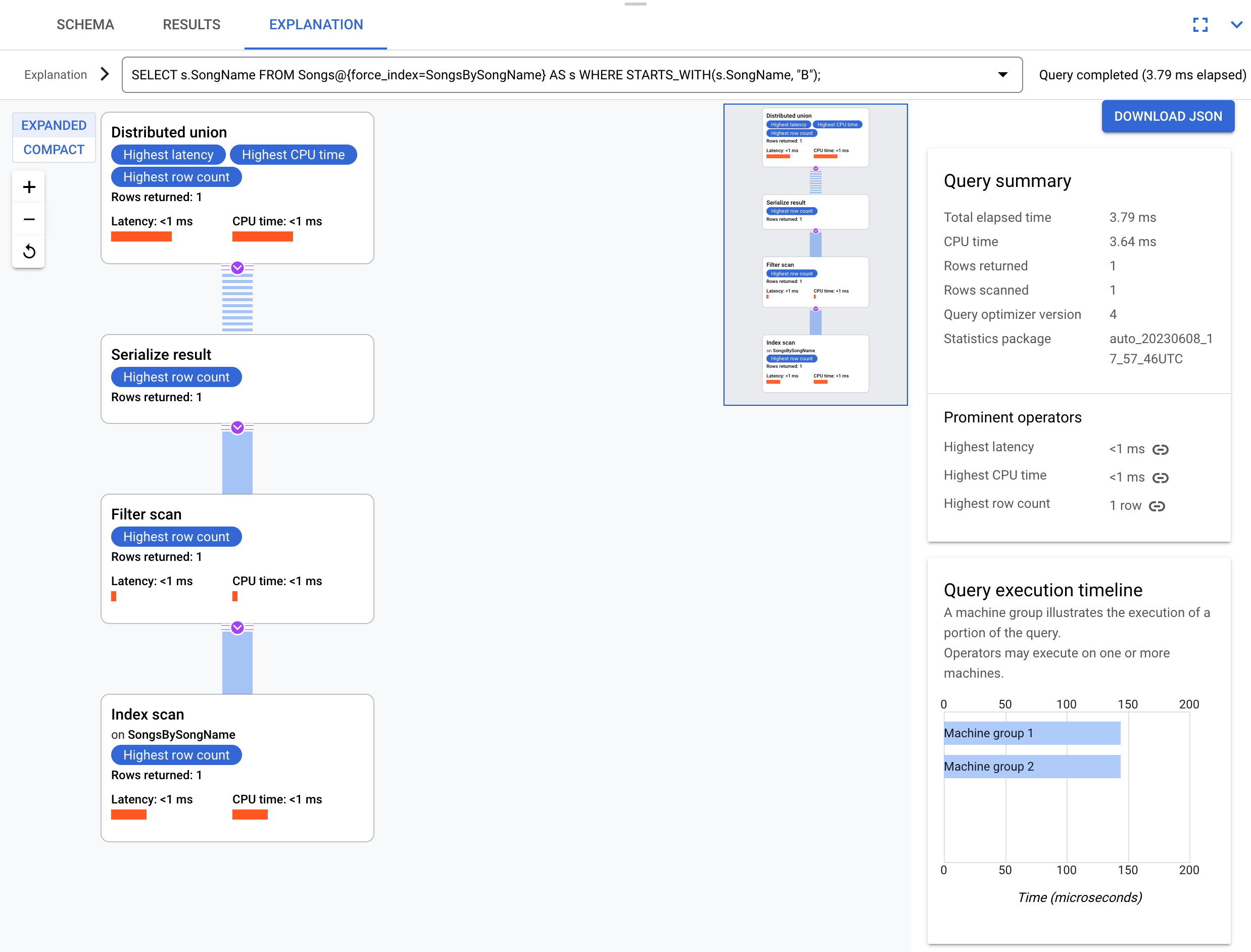
El plan de ejecución no necesita una reversión de la unión, porque todas las columnas que solicita la consulta están presentes en el índice.
¿Qué sigue?
Obtén más información sobre los operadores de ejecución de consultas
Obtén información sobre el optimizador de consultas de Spanner
Obtén más información sobre cómo administrar el optimizador de consultas.