En esta página, se describe cómo usar el panel de estadísticas del sistema para supervisar las instancias y las bases de datos de Spanner.
Información acerca de las estadísticas del sistema
En el panel de estadísticas del sistema, se muestran cuadros de evaluación y gráficos con respecto a una instancia o base de datos seleccionada, y proporciona medidas de latencias, uso de CPU, almacenamiento, capacidad de procesamiento y otras estadísticas de rendimiento. Puedes ver gráficos de varios períodos diferentes, desde la última hora hasta los últimos 30 días.
El panel de estadísticas del sistema incluye las siguientes secciones (consulta la captura de pantalla):
- Lista de bases de datos: Muestra las estadísticas de la base de datos seleccionada. Puedes ver una sola base de datos o un conjunto de todas las bases de datos. Esta opción solo está disponible para instancias.
- Alternador de diseño: Alterna entre un diseño de una o dos columnas.
- Filtro de intervalo de tiempo: Filtra las estadísticas por intervalos de tiempo, como horas, días o un intervalo personalizado.
- Cuadros de evaluación : Muestra las estadísticas en un momento determinado, durante el período seleccionado.
- Gráficos: Muestra gráficos del uso de CPU, la capacidad de procesamiento, las latencias, el uso de almacenamiento y mucho más.
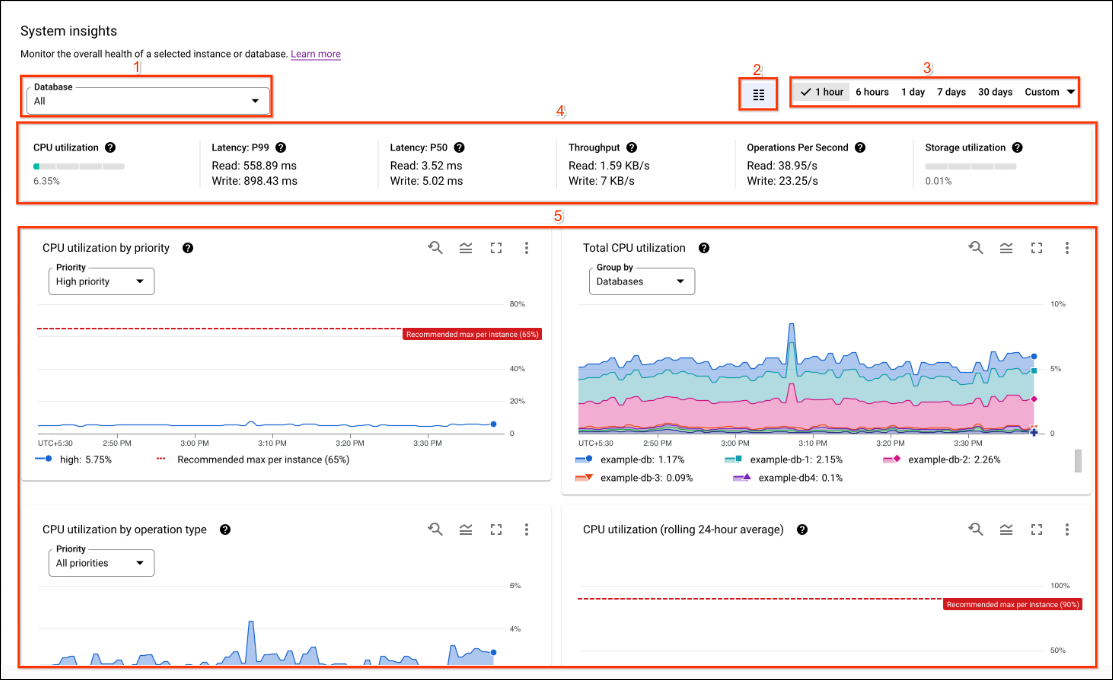
Cuadros de evaluación, gráficos y métricas de las estadísticas del sistema
El panel de estadísticas del sistema proporciona los siguientes gráficos y métricas para mostrar el estado histórico y actual de una instancia. La mayoría de los gráficos y las métricas están disponibles a nivel de la instancia. También puedes ver muchos gráficos y métricas para una sola base de datos dentro de una instancia.
Cuadros de evaluación disponibles
| Nombre | Descripción |
|---|---|
| Uso de CPU | Uso total de CPU dentro de una instancia o base de datos seleccionada. En una instancia multirregional, esta métrica representa la media del uso de CPU entre regiones. |
| Latencia: P99 | Latencia de P99 para operaciones de lectura y escritura dentro de una instancia o base de datos seleccionada. |
| Latencia: P50 | Latencia de P50 para operaciones de lectura y escritura dentro de una instancia o base de datos seleccionada. |
| Capacidad de procesamiento | La cantidad de datos sin comprimir que se leyeron o que se escribieron en la instancia o base de datos cada segundo. Este valor se mide en megabytes binarios (MB), en los que 1 MB equivale a 2^20 bytes. Esta unidad de medida también se conoce como mebibyte (MiB). |
| Operaciones por segundo | Cantidad de operaciones por segundo (tasa) de lectura y escritura dentro de una instancia o base de datos seleccionada. |
| Uso de almacenamiento | A nivel de instancia, es el porcentaje total de uso de almacenamiento en una instancia. A nivel de la base de datos, este es el almacenamiento total que se usó para la base de datos seleccionada. |
Gráficos y métricas disponibles
El siguiente es un gráfico para una métrica de muestra:
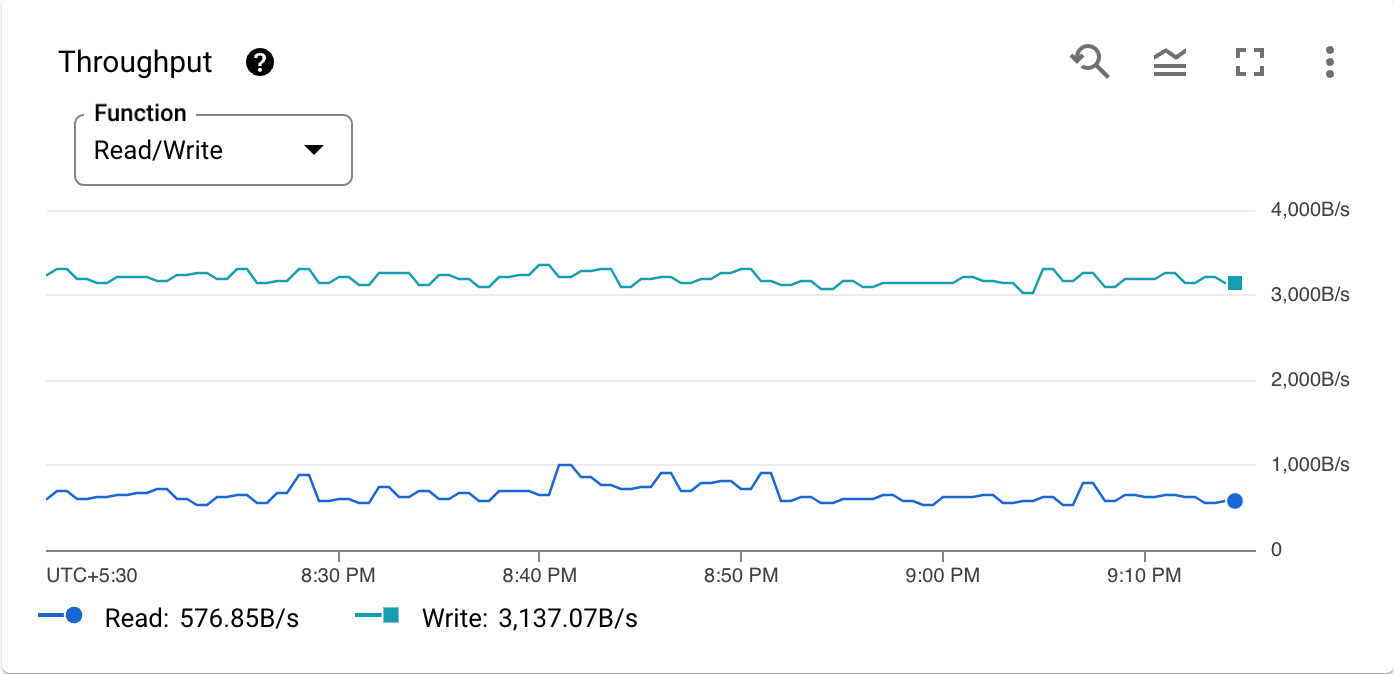
La barra de herramientas de cada tarjeta de gráfico proporciona el siguiente conjunto de opciones estándar:
Para acercar una sección específica de un gráfico, haz clic en el gráfico y arrástralo de manera horizontal o vertical. Para revertir la operación de zoom, haz clic en youtube_searched_for Restablecer zoom. Las operaciones de zoom se aplican a todos los gráficos del panel al mismo tiempo.
Para ocultar o mostrar la leyenda, haz clic en legend_toggle Expandir/contraer leyenda del gráfico.
Para ver un gráfico en el modo de pantalla completa, haz clic en fullscreen Ingresar/salir de pantalla completa. También puedes salir de la pantalla completa haciendo clic en Esc.
Para ver las opciones adicionales, haz clic en more_vert Más opciones de gráfico.
La mayoría de los gráficos ofrecen estas opciones:
- Descarga una imagen PNG.
- Descarga un archivo CSV.
- Agregar al panel personalizado Esta opción te permite agregar un gráfico a un panel nuevo o a uno existente en Cloud Monitoring.
- Ver en el Explorador de métricas. Consulta la métrica en el Explorador de métricas. Puedes ver otras métricas de Spanner en el Explorador de métricas después de seleccionar el tipo de recurso Base de datos de Spanner.
En la siguiente tabla, se describen los gráficos que aparecen de forma predeterminada en el panel de estadísticas del sistema. Se mostrará el tipo de métrica de cada gráfico. Las cadenas de tipo de métrica siguen este prefijo: spanner.googleapis.com/. En Tipo de métrica, se describen las mediciones que se pueden recopilar de un recurso supervisado.
|
Nombre del gráfico y tipo de métrica |
Descripción | Disponible para las instancias | Disponible para bases de datos |
|---|---|---|---|
Uso de CPU por prioridad instance/cpu/utilization_by_priority |
El porcentaje de recursos de CPU de la instancia para tareas altas, medias, bajas o todas ellas por prioridad. Estas tareas incluyen las solicitudes que inicias y las tareas de mantenimiento que Spanner debe completar con rapidez. En las instancias multirregionales, las métricas se agrupan por región y prioridad. Obtén más información sobre las tareas de prioridad alta. Obtén más información sobre el uso de CPU. |
done |
close |
Uso total de CPU instance/cpu/utilization_by_priority |
El uso de CPU total, como un porcentaje de los recursos de CPU de la instancia. Para las instancias, puedes ver el gráfico apilado del uso de CPU total agrupado por base de datos o agrupado por la combinación de tipo de tarea (usuario/sistema) y prioridad. En el caso de las bases de datos, puedes ver el gráfico apilado del uso de CPU total agrupado por combinación de tipo de tarea (usuario/sistema) y prioridad. En las instancias multirregionales, puedes elegir la región que deseas ver o puedes mostrar todas las regiones como varios gráficos de líneas. |
done |
done |
Uso de CPU por tipo de operación instance/cpu/utilization_by_operation_type |
Un gráfico apilado del uso de CPU como un porcentaje de los recursos de CPU de la instancia, agrupados por operaciones iniciadas por el usuario, como lecturas, escrituras y confirmaciones. Usa esta métrica para obtener un desglose detallado del uso de CPU y solucionar más problemas, como se explica en Investiga el uso alto de CPU. Puedes filtrar las tareas por prioridad mediante el menú desplegable Prioridad. Para instancias multirregionales, las métricas del gráfico de líneas muestran el porcentaje medio entre regiones. |
done |
done |
Uso de CPU (promedio móvil de 24 horas) instance/cpu/smoothed_utilization |
Un promedio móvil del uso de Spanner de CPU total, como un porcentaje de los recursos de CPU de la instancia, para cada base de datos. Cada dato es un promedio de las 24 horas anteriores. Para las instancias multirregionales, puedes filtrar las métricas en el gráfico de líneas por región mediante el menú desplegable Región. |
done |
close |
Latencia api/request_latencies |
La cantidad de tiempo que Spanner tardó en manejar una solicitud de lectura o escritura. Usa el menú desplegable Función para seleccionar Lectura o Escritura, o selecciona Lectura/escritura para ver las métricas de ambas. Esta medición comienza cuando Spanner recibe una solicitud y finaliza cuando Spanner comienza a enviar una respuesta. Puedes ver las métricas de latencia para las latencias de los percentiles 50 y 99 mediante el menú desplegable Percentil:
|
done |
done |
Latencia por base de datos api/request_latencies |
Es el tiempo que Spanner tardó en manejar una solicitud de lectura o escritura, agrupado por base de datos. Usa el menú desplegable Función para seleccionar Lectura o Escritura, o selecciona Lectura/escritura para ver las métricas de ambas. Esta medición comienza cuando Spanner recibe una solicitud y finaliza cuando Spanner comienza a enviar una respuesta. Puedes ver las métricas de la latencia de los percentiles 50 y 99 mediante el menú desplegable Percentil:
|
done |
close |
Latencia por método de API api/request_latencies |
Es el tiempo que Spanner tardó en manejar una solicitud, agrupado por los métodos de la API de Spanner. Esta medición comienza cuando Spanner recibe una solicitud y finaliza cuando Spanner comienza a enviar una respuesta. Puedes ver las métricas de las latencias de los percentiles 50 y 99 mediante el menú desplegable Percentil:
|
close |
done |
Latencia de la transacción api/request_latencies_by_transaction_type |
Es el tiempo que Spanner tardó en procesar una transacción. Puedes elegir ver las métricas de las transacciones de tipo de lectura y escritura y las de solo lectura. La diferencia principal entre el gráfico de latencia y el gráfico de latencia de transacciones es que el gráfico de latencia de transacciones te permite seleccionar la participación líder para el tipo de solo lectura. Puedes seleccionar líder está involucrado o Ningún líder está involucrado en la transacción de solo lectura. Las lecturas que involucran al líder podrían experimentar una latencia más alta. Puedes usar este gráfico para evaluar si debes usar lecturas inactivas sin comunicarte con el líder, suponiendo que el límite de la marca de tiempo es de al menos 15 segundos. En el caso de las transacciones de lectura y escritura, el líder siempre está involucrado en la transacción, por lo que los datos que se muestran en el gráfico siempre incluyen el tiempo que tardó la solicitud en llegar al líder y recibir una respuesta. Puedes ver las métricas de la latencia de los percentiles 50 y 99:
|
done |
done |
Latencia de transacciones por base de datos api/request_latencies_by_transaction_type |
Es el tiempo que Spanner tardó en procesar una transacción. Puedes elegir ver las métricas de las transacciones de tipo de lectura y escritura y las de solo lectura. La diferencia principal entre el gráfico de latencia y el gráfico de latencia de transacciones por base de datos es que el gráfico de latencia de transacciones por base de datos te permite seleccionar la participación líder para el tipo de solo lectura. Puedes seleccionar líder está involucrado o Ningún líder está involucrado en la transacción de solo lectura. Las lecturas que involucran al líder podrían experimentar una latencia más alta. Puedes usar este gráfico para evaluar si debes usar lecturas inactivas sin comunicarte con el líder, suponiendo que el límite de la marca de tiempo es de al menos 15 segundos. En el caso de las transacciones de lectura y escritura, el líder siempre está involucrado en la transacción, por lo que los datos que se muestran en el gráfico siempre incluyen el tiempo que tardó la solicitud en llegar al líder y recibir una respuesta. Puedes ver las métricas de la latencia de los percentiles 50 y 99:
|
done |
close |
Latencia de la transacción por método de API api/request_latencies_by_transaction_type |
Es el tiempo que Spanner tardó en procesar una transacción. Puedes elegir ver las métricas de las transacciones de tipo de lectura y escritura y las de solo lectura. La diferencia principal entre el gráfico de latencia y el gráfico de latencia de transacciones por método de API es que el gráfico de latencia de transacciones por método de API te permite seleccionar la participación líder para el tipo de solo lectura. Puedes seleccionar El líder está involucrado o El líder está involucrado en la transacción de solo lectura. Las lecturas que involucran al líder podrían experimentar una latencia más alta. Puedes usar este gráfico para evaluar si debes usar lecturas inactivas sin comunicarte con el líder, suponiendo que el límite de la marca de tiempo es de al menos 15 segundos. En el caso de las transacciones de lectura y escritura, el líder siempre está involucrado en la transacción, por lo que los datos que se muestran en el gráfico siempre incluyen el tiempo que tardó la solicitud en llegar al líder y recibir una respuesta. Puedes ver las métricas de la latencia de los percentiles 50 y 99:
|
close |
done |
Operaciones por segundo api/api_request_count |
La cantidad de operaciones (lectura/escritura) que Spanner realizó por segundo o la cantidad de errores que se produjeron en el servidor de Spanner por segundo. Puedes elegir qué operaciones ver en este gráfico:
|
done |
done |
Operaciones por segundo por base de datos api/api_request_count |
La cantidad de operaciones (lectura/escritura) que Spanner realizó por segundo o la cantidad de errores que se produjeron en el servidor de Spanner por segundo. Este gráfico está agrupado por base de datos. Puedes elegir qué operaciones ver en este gráfico:
|
done |
close |
Operaciones por segundo según el método de API api/api_request_count |
La cantidad de operaciones que Spanner realizó por segundo, agrupadas por el método de la API de Spanner |
close |
done |
Capacidad de procesamiento api/sent_bytes_count (lectura) api/received_bytes_count (escritura) |
La cantidad de datos sin comprimir que se leyeron o se escribieron en la instancia o base de datos cada segundo. Este valor se mide en unidades de bytes binarios. Esta unidad de medida se basa en la potencia de 2. Por ejemplo, 1 gigabyte (GB) binario equivale a 2^30 bytes. Esta unidad de medida también se conoce como gibibyte (GiB). La capacidad de procesamiento de lectura incluye solicitudes y respuestas para los métodos en la API de lectura y las consultas en SQL. También incluye solicitudes y respuestas para declaraciones DML. La capacidad de procesamiento de escritura incluye solicitudes y respuestas para confirmar datos a través de la API de mutación. Excluye solicitudes y respuestas para declaraciones DML. |
done |
done |
Capacidad de procesamiento por base de datos api/sent_bytes_count (lectura) api/received_bytes_count (escritura) |
La cantidad de datos sin comprimir que se leyeron o se escribieron en la instancia o base de datos cada segundo, agrupados por base de datos. Este valor se mide en unidades de bytes binarios. Esta unidad de medida se basa en la potencia de 2. Por ejemplo, 1 gigabyte (GB) binario equivale a 2^30 bytes. Esta unidad de medida también se conoce como gibibyte (GiB). La capacidad de procesamiento de lectura incluye solicitudes y respuestas para los métodos en la API de lectura y las consultas en SQL. También incluye solicitudes y respuestas para declaraciones DML. La capacidad de procesamiento de escritura incluye solicitudes y respuestas para confirmar datos a través de la API de mutación. Excluye solicitudes y respuestas para declaraciones DML. |
done |
close |
Capacidad de procesamiento por método de API api/sent_bytes_count (lectura) api/received_bytes_count (escritura) |
La cantidad de datos sin comprimir que se leyeron o se escribieron cada segundo en la instancia o base de datos, agrupados por el método de API. Este valor se mide en unidades de bytes binarios. Esta unidad de medida se basa en la potencia de 2. Por ejemplo, 1 gigabyte (GB) binario equivale a 2^30 bytes. Esta unidad de medida también se conoce como gibibyte (GiB). La capacidad de procesamiento de lectura incluye solicitudes y respuestas para los métodos en la API de lectura y las consultas en SQL. También incluye solicitudes y respuestas para declaraciones DML. La capacidad de procesamiento de escritura incluye solicitudes y respuestas para confirmar datos a través de la API de mutación. Excluye solicitudes y respuestas para declaraciones DML. |
close |
done |
Almacenamiento total instance/storage/used_bytes |
La cantidad de datos que se almacenan en la instancia o base de datos. Este valor se mide en unidades de bytes binarios. Por ejemplo, 1 gigabyte binario (GB) equivale a 2^30 bytes. Esta unidad de medida también se conoce como gibibyte (GiB). |
done |
done |
Almacenamiento total de la base de datos por base de datos instance/storage/used_bytes |
La cantidad de datos que se almacenan en la instancia o base de datos, agrupados por base de datos. Este valor se mide en unidades de bytes binarios. Por ejemplo, 1 gigabyte binario (GB) equivale a 2^30 bytes. Esta unidad de medida también se conoce como gibibyte (GiB). |
done |
close |
Almacenamiento de bases de datos por tabla (ninguno) |
La cantidad de datos que se almacenan en la instancia o base de datos, agrupados por tablas en la base de datos seleccionada. Este valor se mide en unidades de bytes binarios. Por ejemplo, 1 gigabyte binario (GB) equivale a 2^30 bytes. Esta unidad de medida también se conoce como gibibyte (GiB). Este gráfico obtiene los datos mediante la consulta a SPANNER_SYS.TABLE_SIZES_STATS_1HOUR. Para obtener más información, consulta
Estadísticas de tamaños de tablas. |
close |
done |
Tablas más usadas por operaciones (ninguna) |
Son los 15 índices y tablas más usados en la instancia o base de datos, determinados por la cantidad de operaciones de lectura, escritura o eliminación. En este gráfico, se obtienen los datos mediante una consulta a las tablas de estadísticas de operaciones de la tabla. Para obtener más información, consulta Estadísticas de operaciones de la tabla. |
close |
done |
Tablas menos usadas por operaciones (ninguna) |
Son los 15 índices y tablas que menos se usan en la instancia o base de datos, determinados por la cantidad de operaciones de lectura, escritura o eliminación. En este gráfico, se obtienen los datos mediante una consulta a las tablas de estadísticas de operaciones de la tabla. Para obtener más información, consulta Estadísticas de operaciones de la tabla. |
close |
done |
Tiempo de espera de bloqueo lock_stat/total/lock_wait_time |
El tiempo de espera de bloqueo de una transacción es el tiempo necesario para adquirir un bloqueo en un recurso que retiene otra transacción. El tiempo de espera total de bloqueo por conflictos de bloqueo se registra para toda la base de datos. |
done |
done |
Bloquear tiempo de espera por base de datos lock_stat/total/lock_wait_time |
El tiempo de espera de bloqueo de una transacción es el tiempo necesario para adquirir un bloqueo en un recurso que retiene otra transacción. El tiempo de espera total de bloqueo por conflictos de bloqueo se registra para toda la base de datos. |
done |
close |
Almacenamiento total de la copia de seguridad instance/backup/used_bytes |
La cantidad de datos que se almacenan en las copias de seguridad asociadas con la instancia o base de datos. Este valor se mide en unidades de bytes binarios. Por ejemplo, 1 gigabyte (GB) binario equivale a 2^30 bytes. Esta unidad de medida también se conoce como gibibyte (GiB). |
done |
done |
Almacenamiento total de copia de seguridad por base de datos instance/backup/used_bytes |
La cantidad de datos que se almacenan en las copias de seguridad asociadas con la instancia o base de datos, agrupadas por base de datos. Este valor se mide en unidades de bytes binarios. Por ejemplo, 1 gigabyte (GB) binario equivale a 2^30 bytes. Esta unidad de medida también se conoce como gibibyte (GiB). |
done |
close |
Capacidad de procesamiento instance/processing_units instance/nodes |
La capacidad de procesamiento es la cantidad de nodos o unidades de procesamiento disponibles en una instancia. Puedes elegir mostrar la capacidad en unidades de procesamiento o en nodos. |
done |
close |
Distribución de líderes instance/leader_percentage_by_region |
Para las instancias multirregionales, puedes ver la cantidad de bases de datos con la mayoría de líderes (>=50%) en una región determinada. En el menú desplegable Regiones, si seleccionas una región específica, el gráfico muestra la cantidad total de bases de datos dentro de esa instancia que tienen la región seleccionada como la región líder. Si seleccionas Todas las regiones en el menú desplegable Regiones, el gráfico mostrará una línea para cada región, y cada línea mostrará la cantidad total de bases de datos en la instancia que tiene esa región como su región líder. Para las bases de datos en una instancia multirregional, puedes ver el porcentaje de líderes agrupados por región. Por ejemplo, si una base de datos tiene cinco líderes, uno en us-west1 y cuatro en us-east1 en un momento determinado, el gráfico “Todas las regiones” muestra dos líneas (una por región). Una línea para us-west1 está al 20% y la otra línea para us-east1 está al 80%. En el gráfico de us-west1, se muestra una sola línea al 20%, y en el gráfico de us-east1, se muestra una sola línea, del 80%. Ten en cuenta que, si se creó una base de datos o se modificó hace poco una región líder, es posible que los gráficos no se estabilicen de inmediato. Este gráfico solo está disponible para instancias multirregionales. |
done |
done |
|
Recuento de llamadas de servicio remoto query_stat/total/remote_service_calls_count |
Recuento de llamadas de servicio remotas agrupadas por servicio y códigos de respuesta. Responde con un código de respuesta HTTP, como 200 o 500. |
done |
done |
|
Latencias de llamadas de servicio remoto query_stat/total/remote_service_calls_latencies |
La latencia de las llamadas de servicio remotas agrupadas por servicio. Puedes ver las métricas de latencia de las latencias de los percentiles 50 y 99 con el menú desplegable Percentil:
|
done |
done |
|
Recuento de filas procesadas del servicio remoto query_stat/total/remote_service_processed_rows_count |
Recuento de filas procesadas por un servicio remoto y agrupadas por proveedor y códigos de respuesta. Responde con un código de respuesta HTTP, como 200 o 500. |
done |
done |
|
Latencias de filas de servicio remoto query_stat/total/remote_service_processed_rows_latencies |
Recuento de filas procesadas por un servicio remoto, agrupadas por servicio y códigos de respuesta. Puedes ver las métricas de latencia de las latencias de los percentiles 50 y 99 con el menú desplegable Percentil:
|
done |
done |
|
Bytes de red del servicio remoto query_stat/total/remote_service_network_bytes_sizes |
Bytes de red que se intercambian con el servicio remoto agrupados por servicio y dirección Este valor se mide en unidades de bytes binarios. Esta unidad de medida se basa en la potencia de 2. Por ejemplo, 1 gigabyte (GB) binario equivale a 2^30 bytes. Esta unidad de medida también se conoce como gibibyte (GiB). La dirección se refiere al tráfico que se envía o se recibe. Puedes ver las métricas del percentil 50 y 99 del intercambio de bytes de red con el menú desplegable Percentil:
|
done |
done |
Gráficos y métricas administrados del escalador automático
Además de las opciones que se muestran en la sección anterior, cuando una instancia tiene habilitado el escalador automático administrado, el gráfico de capacidad de procesamiento tiene el botón Ver registros. Cuando haces clic en este botón, se muestran los registros del escalador automático administrado.
Las siguientes métricas están disponibles para las instancias que tienen habilitado el escalador automático administrado.
| Nombre del gráfico y tipo de métrica | Descripción |
|---|---|
| Capacidad de procesamiento | Con nodos seleccionados. |
|
instance/autoscaling/min_node_count |
La cantidad mínima de nodos del escalador automático está configurada para asignarse a la instancia. |
|
instance/autoscaling/max_node_count |
La cantidad máxima de nodos del escalador automático está configurada para asignar a la instancia. |
|
instance/autoscaling/recommended_node_count_for_cpu |
Cantidad de nodos recomendada en función del uso de CPU de la instancia. |
|
instance/autoscaling/recommended_node_count_for_storage |
Cantidad de nodos recomendada en función del uso de almacenamiento de la instancia. |
| Capacidad de procesamiento | Con unidades de procesamiento seleccionadas. |
|
instance/autoscaling/min_processing_units |
El escalador automático de la cantidad mínima de unidades de procesamiento está configurado para asignarse a la instancia. |
|
instance/autoscaling/max_processing_units |
El escalador automático de la cantidad máxima de unidades de procesamiento está configurado para asignarse a la instancia. |
|
instance/autoscaling/recommended_processing_units_for_cpu |
Cantidad recomendada de unidades de procesamiento. Esta recomendación se basa en el uso de CPU anterior de la instancia. |
|
instance/autoscaling/recommended_processing_units_for_storage |
Cantidad recomendada de unidades de procesamiento para usar. Esta recomendación se basa en el uso de almacenamiento anterior de la instancia. |
| Uso de CPU por prioridad | |
|
instance/autoscaling/high_priority_cpu_utilization_target |
Objetivo de uso de CPU de alta prioridad para usar en el ajuste de escala automático. |
| Almacenamiento total | Con unidades de procesamiento seleccionadas. |
|
instance/storage/limit_bytes |
Límite de almacenamiento de la instancia, expresado en bytes. |
|
instance/autoscaling/storage_utilization_target |
Objetivo de uso de almacenamiento para usar en el ajuste de escala automático. |
Retención de datos
La retención máxima de datos para la mayoría de las métricas del panel de estadísticas del sistema es de seis semanas. Sin embargo, para el gráfico Almacenamiento de base de datos por tabla, los datos se consumen de la tabla SPANNER_SYS.TABLE_SIZES_STATS_1HOUR (en lugar de Spanner), que tiene una retención máxima de 30 días. Consulta Retención de datos para obtener más información.
Visualiza el panel de estadísticas del sistema
Para ver la página de estadísticas del sistema, necesitas los siguientes permisos de Identity and Access Management (IAM), además de los permisos de Spanner y Spanner en los niveles de instancia y de la base de datos:
spanner.databases.beginReadOnlyTransactionspanner.databases.selectspanner.sessions.create
Para obtener más información sobre los permisos de IAM de Spanner, consulta Control de acceso con IAM.
Si habilitas el escalador automático administrado en tu instancia, también necesitas el permiso logging.logEntries.list para ver los registros del escalador automático administrado.
Para obtener más información sobre este permiso, consulta Funciones predefinidas.
Para ver el panel de estadísticas del sistema, sigue estos pasos:
En la consola de Google Cloud, abre la lista de instancias de Spanner.
Realiza una de las siguientes acciones:
Para ver las métricas de una instancia, haz clic en el nombre de la instancia sobre la que deseas obtener información y, luego, en Estadísticas del sistema en el menú de navegación.
Para ver las métricas de una base de datos, haz clic en el nombre de la instancia, selecciona una base de datos y, luego, haz clic en Estadísticas del sistema en el menú de navegación.
Opcional: Para ver los datos históricos de un período diferente, busca los botones en la parte superior derecha de la página y, luego, haz clic en el período que deseas ver.
Opcional: Para controlar qué datos aparecen en el gráfico, haz clic en una de las listas desplegables del gráfico. Por ejemplo, si la instancia usa una configuración multirregional, algunos gráficos proporcionan una lista desplegable para ver los datos de una región específica. No todos los gráficos tienen listas desplegables.
¿Qué sigue?
- Comprende las métricas de uso de CPU y latencia para Spanner.
- Configurar gráficos y alertas personalizados con Monitoring
- Obtén detalles sobre los tipos de instancias de Spanner.