Tabel turunan membuka berbagai kemungkinan analisis tingkat lanjut, tetapi bisa jadi sulit untuk didekati, diterapkan, dan dipecahkan masalahnya. Cookbook ini berisi kasus penggunaan tabel turunan yang paling populer di Looker.
Halaman ini berisi contoh berikut:
- Membuat tabel setiap hari pukul 03.00
- Menambahkan data baru ke tabel besar
- Menggunakan fungsi jendela SQL
- Membuat kolom turunan untuk nilai yang dihitung
- Strategi pengoptimalan
- Menggunakan PDT untuk menguji pengoptimalan
UNIONdua tabel- Menghitung jumlah dari jumlah (mengelompokkan ukuran menurut dimensi)
- Tabel gabungan dengan kesadaran agregat
Resource tabel turunan
Cookbook ini mengasumsikan bahwa Anda memiliki pemahaman pengantar tentang LookML dan tabel turunan. Anda harus sudah terbiasa membuat tampilan dan mengedit file model. Jika Anda ingin mempelajari kembali salah satu topik ini, lihat referensi berikut:
- Tabel turunan
- Istilah dan konsep LookML
- Membuat tabel turunan native
- Referensi parameter
derived_table - Meng-cache kueri dan membangun ulang PDT dengan grup data
Membangun tabel setiap hari pukul 03.00
Data dalam contoh ini masuk pada pukul 02.00 setiap hari. Hasil kueri pada data ini akan sama, baik dijalankan pada pukul 03.00 maupun 21.00. Oleh karena itu, sebaiknya buat tabel sekali sehari dan izinkan pengguna menarik hasil dari cache.
Dengan menyertakan grup data dalam file model, Anda dapat menggunakannya kembali dengan beberapa tabel dan Eksplorasi. Grup data ini berisi parameter sql_trigger_value yang memberi tahu grup data kapan harus memicu dan membangun ulang tabel turunan.
Untuk contoh ekspresi pemicu lainnya, lihat dokumentasi sql_trigger_value.
## in the model file
datagroup: standard_data_load {
sql_trigger_value: SELECT FLOOR(((TIMESTAMP_DIFF(CURRENT_TIMESTAMP(),'1970-01-01 00:00:00',SECOND)) - 60*60*3)/(60*60*24)) ;;
max_cache_age: "24 hours"
}
explore: orders {
…
Tambahkan parameter datagroup_trigger ke definisi derived_table dalam file tampilan, dan tentukan nama grup data yang ingin Anda gunakan. Dalam contoh ini, grup datanya adalah standard_data_load.
view: orders {
derived_table: {
indexes: ["id"]
datagroup_trigger: standard_data_load
sql:
SELECT
user_id,
id,
created_at,
status
FROM
demo_db.orders
GROUP BY
user_id ;;
}
…
}
Menambahkan data baru ke tabel besar
PDT inkremental adalah tabel turunan persisten yang dibuat Looker dengan menambahkan data baru ke tabel, bukan membangun ulang tabel secara keseluruhan.
Contoh berikutnya dibuat berdasarkan contoh tabel orders untuk menunjukkan cara tabel dibuat secara inkremental. Data pesanan baru masuk setiap hari dan dapat ditambahkan ke tabel yang ada saat Anda menambahkan parameter increment_key dan parameter increment_offset.
view: orders {
derived_table: {
indexes: ["id"]
increment_key: "created_at"
increment_offset: 3
datagroup_trigger: standard_data_load
distribution_style: all
sql:
SELECT
user_id,
id,
created_at,
status
FROM
demo_db.orders
GROUP BY
user_id ;;
}
dimension: id {
primary_key: yes
type: number
sql: ${TABLE}.id ;; }
…
}
Nilai increment_key ditetapkan ke created_at, yang merupakan inkremen waktu untuk data baru yang harus dikueri dan ditambahkan ke PDT dalam contoh ini.
Nilai increment_offset ditetapkan ke 3 untuk menentukan jumlah periode waktu sebelumnya (pada perincian kunci inkremental) yang dibangun ulang untuk memperhitungkan data yang terlambat tiba.
Menggunakan fungsi jendela SQL
Beberapa dialek database mendukung fungsi jendela, terutama untuk membuat nomor urut, kunci utama, total berjalan dan kumulatif, serta perhitungan multi-baris berguna lainnya. Setelah kueri utama dieksekusi, semua deklarasi derived_column akan dieksekusi dalam proses terpisah.
Jika dialek database Anda mendukung fungsi jendela, Anda dapat menggunakannya dalam tabel turunan native. Buat parameter derived_column dengan parameter sql yang berisi fungsi jendela Anda. Saat merujuk ke nilai, Anda harus menggunakan nama kolom seperti yang ditentukan dalam tabel turunan native.
Contoh berikut menunjukkan cara membuat tabel turunan native yang menyertakan kolom user_id, order_id, dan created_time. Kemudian, Anda akan menggunakan kolom turunan dengan fungsi jendela SQL ROW_NUMBER() untuk menghitung kolom yang berisi nomor urut pesanan pelanggan.
view: user_order_sequences {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: order_id {
field: order_items.order_id
}
column: created_time {
field: order_items.created_time
}
derived_column: user_sequence {
sql: ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY created_time) ;;
}
}
}
dimension: order_id {
hidden: yes
}
dimension: user_sequence {
type: number
}
}
Membuat kolom turunan untuk nilai yang dihitung
Anda dapat menambahkan parameter derived_column untuk menentukan kolom yang tidak ada dalam Eksplorasi parameter explore_source. Setiap parameter derived_column memiliki parameter sql yang menentukan cara membuat nilai.
Penghitungan sql Anda dapat menggunakan kolom apa pun yang telah Anda tentukan menggunakan parameter column. Kolom turunan tidak dapat menyertakan fungsi agregat, tetapi dapat menyertakan penghitungan yang dapat dilakukan pada satu baris tabel.
Contoh ini membuat kolom average_customer_order, yang dihitung dari kolom lifetime_customer_value dan lifetime_number_of_orders dalam tabel turunan native.
view: user_order_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: users.id
}
column: lifetime_number_of_orders {
field: order_items.count
}
column: lifetime_customer_value {
field: order_items.total_profit
}
derived_column: average_customer_order {
sql: lifetime_customer_value / lifetime_number_of_orders ;;
}
}
}
dimension: user_id {
hidden: yes
}
dimension: lifetime_number_of_orders {
type: number
}
dimension: lifetime_customer_value {
type: number
}
dimension: average_customer_order {
type: number
}
}
Strategi pengoptimalan
Karena PDT disimpan di database, Anda harus mengoptimalkan PDT dengan menggunakan strategi berikut, sebagaimana didukung oleh dialek Anda:
Misalnya, untuk menambahkan persistensi, Anda dapat menyetel PDT untuk dibangun kembali saat datagroup orders_datagroup dipicu, lalu Anda dapat menambahkan indeks pada customer_id dan first_order, seperti yang ditunjukkan berikutnya:
view: customer_order_summary {
derived_table: {
explore_source: orders {
...
}
datagroup_trigger: orders_datagroup
indexes: ["customer_id", "first_order"]
}
}
Jika Anda tidak menambahkan indeks (atau yang setara untuk dialek Anda), Looker akan memperingatkan Anda bahwa Anda harus melakukannya untuk meningkatkan performa kueri.
Menggunakan PDT untuk menguji pengoptimalan
Anda dapat menggunakan PDT untuk menguji berbagai opsi pengindeksan, distribusi, dan pengoptimalan lainnya tanpa memerlukan banyak dukungan dari DBA atau developer ETL.
Pertimbangkan kasus saat Anda memiliki tabel, tetapi ingin menguji indeks yang berbeda. LookML awal Anda untuk tampilan mungkin terlihat seperti berikut:
view: customer {
sql_table_name: warehouse.customer ;;
}
Untuk menguji strategi pengoptimalan, Anda dapat menggunakan parameter indexes untuk menambahkan indeks ke LookML, seperti yang ditunjukkan berikutnya:
view: customer {
# sql_table_name: warehouse.customer
derived_table: {
sql: SELECT * FROM warehouse.customer ;;
persist_for: "8 hours"
indexes: [customer_id, customer_name, salesperson_id]
}
}
Buat kueri tampilan sekali untuk membuat PDT. Kemudian, jalankan kueri pengujian dan bandingkan hasilnya. Jika hasilnya menguntungkan, Anda dapat meminta tim DBA atau ETL untuk menambahkan indeks ke tabel asli.
UNION dua tabel
Anda dapat menjalankan operator SQL UNION atau UNION ALL di kedua tabel turunan jika dialek SQL Anda mendukungnya. Operator UNION dan UNION ALL menggabungkan kumpulan hasil dari dua kueri.
Contoh ini menunjukkan tampilan tabel turunan berbasis SQL dengan UNION:
view: first_and_second_quarter_sales {
derived_table: {
sql:
SELECT * AS sales_records
FROM sales_records_first_quarter
UNION
SELECT * AS sales_records
FROM sales_records_second_quarter ;;
}
}
Pernyataan UNION dalam parameter sql menghasilkan tabel turunan yang menggabungkan hasil kedua kueri.
Perbedaan antara UNION dan UNION ALL adalah UNION ALL tidak menghapus baris duplikat. Ada pertimbangan performa yang perlu diingat saat menggunakan UNION versus UNION ALL, karena server database harus melakukan pekerjaan tambahan untuk menghapus baris duplikat.
Menghitung jumlah dari jumlah (menentukan dimensi ukuran)
Sebagai aturan umum dalam SQL — dan, dengan demikian, Looker — Anda tidak dapat mengelompokkan kueri berdasarkan hasil fungsi agregat (yang ditampilkan di Looker sebagai ukuran). Anda hanya dapat mengelompokkan menurut kolom yang tidak diagregasi (ditampilkan di Looker sebagai dimensi).
Untuk mengelompokkan menurut agregat (misalnya, untuk menjumlahkan jumlah), Anda perlu "mengubah dimensi" ukuran. Salah satu cara untuk melakukannya adalah dengan menggunakan tabel turunan, yang secara efektif membuat subkueri agregat.
Dimulai dengan Eksplorasi, Looker dapat membuat LookML untuk semua atau sebagian besar tabel turunan Anda. Cukup buat Eksplorasi dan pilih semua kolom yang ingin Anda sertakan dalam tabel turunan. Kemudian, untuk membuat LookML tabel turunan native (atau berbasis SQL), ikuti langkah-langkah berikut:
Klik menu roda gigi Jelajah, lalu pilih Dapatkan LookML.
Untuk melihat LookML guna membuat tabel turunan native untuk Eksplorasi, klik tab Tabel Turunan.
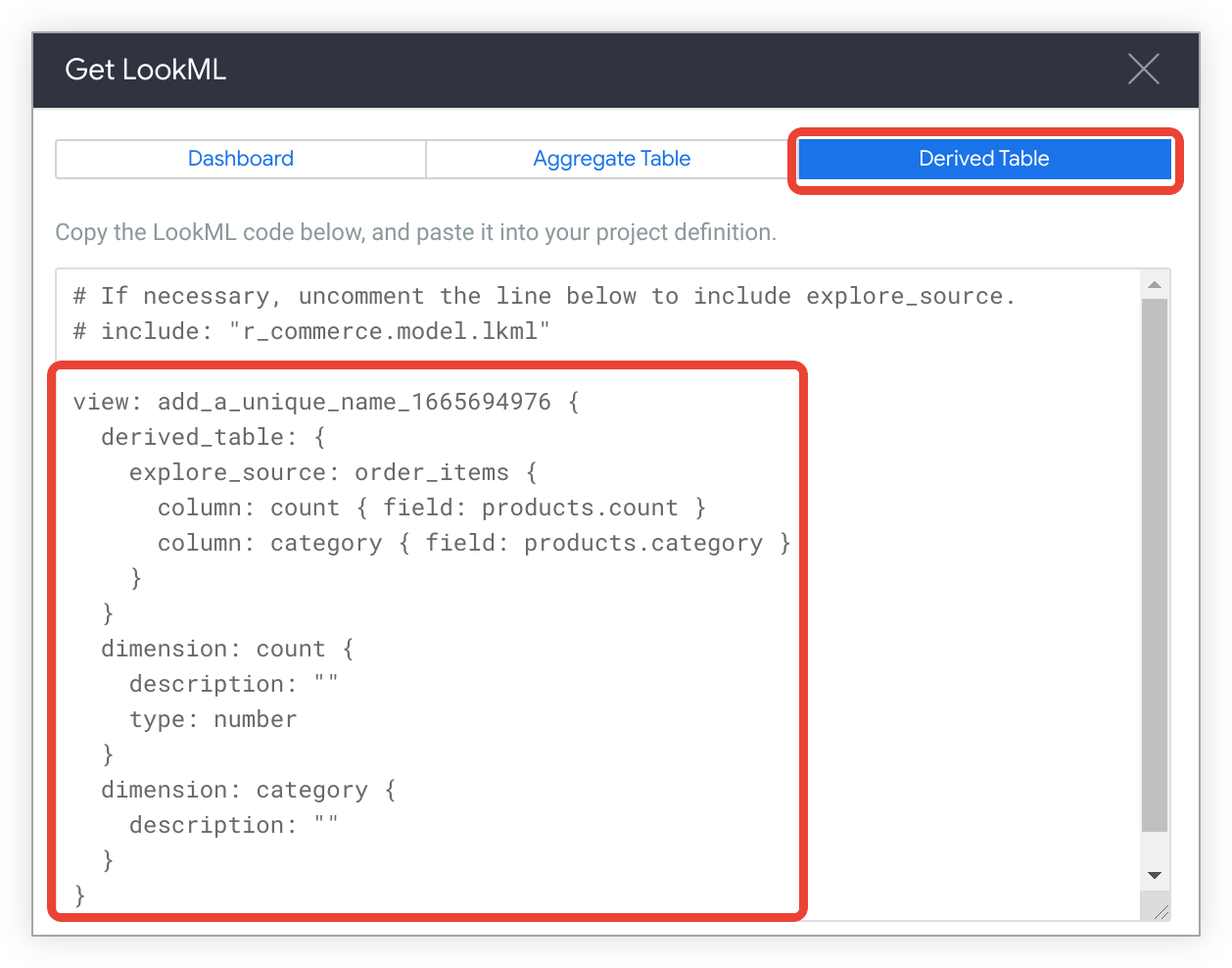
Salin LookML.
Setelah menyalin LookML yang dihasilkan, tempelkan ke file tampilan dengan mengikuti langkah-langkah berikut:
Dalam Mode Pengembangan, buka file project Anda.
Klik + di bagian atas daftar file project di Looker IDE, lalu pilih Create View. Atau, untuk membuat file di dalam folder, klik menu folder, lalu pilih Buat Tampilan.
Tetapkan nama tampilan ke sesuatu yang bermakna.
Secara opsional, ubah nama kolom, tentukan kolom turunan, dan tambahkan filter.
Tabel ringkasan dengan kesadaran agregat
Di Looker, Anda mungkin sering menemukan set data atau tabel yang sangat besar yang, agar berperforma baik, memerlukan tabel agregasi atau ringkasan.
Dengan kemampuan Looker untuk mengenali agregasi, Anda dapat membuat tabel agregasi terlebih dahulu ke berbagai tingkat perincian, dimensi, dan agregasi; dan Anda dapat memberi tahu Looker cara menggunakannya dalam Eksplorasi yang ada. Kueri kemudian akan menggunakan tabel gabungan ini jika Looker menganggapnya sesuai, tanpa input pengguna. Hal ini akan mengurangi ukuran kueri, mengurangi waktu tunggu, dan meningkatkan pengalaman pengguna.
Berikut ini menunjukkan implementasi yang sangat sederhana dalam model Looker untuk menunjukkan betapa ringannya kesadaran agregat. Dengan tabel penerbangan hipotetis di database yang memiliki baris untuk setiap penerbangan yang dicatat melalui FAA, Anda dapat memodelkan tabel ini di Looker dengan tampilan dan Eksplorasi sendiri. Berikut adalah LookML untuk tabel gabungan yang dapat Anda tentukan untuk Eksplorasi:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
Dengan tabel gabungan ini, pengguna dapat membuat kueri flights Eksplorasi, dan Looker akan otomatis menggunakan tabel gabungan untuk menjawab kueri. Untuk penelusuran yang lebih mendetail tentang kesadaran agregat, buka Tutorial kesadaran agregat.