파생 테이블은 고급 분석 가능성의 세계를 열어주지만 접근, 구현, 문제 해결이 어려울 수 있습니다. 이 설명서에는 Looker에서 파생 테이블의 가장 일반적인 사용 사례가 포함되어 있습니다.
이 페이지에는 다음 예시가 포함되어 있습니다.
- 매일 오전 3시에 테이블 빌드
- 대형 테이블에 새 데이터 추가
- SQL 윈도우 함수 사용
- 계산된 값의 파생 열 만들기
- 최적화 전략
- PDT를 사용하여 최적화 테스트
- 두
UNION테이블 - 합계 계산(측정값 측정기준화)
- 집계 인식이 포함된 롤업 테이블
파생 테이블 리소스
이 설명서에서는 사용자가 LookML 및 파생 테이블에 대해 기본적으로 이해하고 있다고 가정합니다. 뷰를 만들고 모델 파일을 수정하는 방법을 숙지해야 합니다. 이러한 주제에 대해 복습하려면 다음 리소스를 확인하세요.
매일 오전 3시에 테이블 빌드
이 예시의 데이터는 매일 오전 2시에 제공됩니다. 이 데이터에 대한 쿼리의 결과는 오전 3시에 실행되든 오후 9시에 실행되든 동일합니다. 따라서 하루에 한 번 테이블을 빌드하고 사용자가 캐시에서 결과를 가져올 수 있도록 하는 것이 좋습니다.
모델 파일에 데이터 그룹을 포함하면 여러 테이블 및 Explore에서 데이터 그룹을 재사용할 수 있습니다. 이 데이터 그룹에는 파생 테이블을 트리거하고 다시 빌드할 시기를 데이터 그룹에 알려주는 sql_trigger_value 매개변수가 포함되어 있습니다.
트리거 표현식의 더 많은 예시는 sql_trigger_value 문서를 참조하세요.
## in the model file
datagroup: standard_data_load {
sql_trigger_value: SELECT FLOOR(((TIMESTAMP_DIFF(CURRENT_TIMESTAMP(),'1970-01-01 00:00:00',SECOND)) - 60*60*3)/(60*60*24)) ;;
max_cache_age: "24 hours"
}
explore: orders {
…
datagroup_trigger 매개변수를 뷰 파일의 derived_table 정의에 추가하고 사용할 데이터 그룹의 이름을 지정합니다. 이 예시에서 데이터 그룹은 standard_data_load입니다.
view: orders {
derived_table: {
indexes: ["id"]
datagroup_trigger: standard_data_load
sql:
SELECT
user_id,
id,
created_at,
status
FROM
demo_db.orders
GROUP BY
user_id ;;
}
…
}
대형 테이블에 새 데이터 추가
증분 PDT는 테이블 전체를 다시 빌드하는 대신 Looker가 테이블에 새 데이터를 추가하여 빌드하는 영구 파생 테이블입니다.
다음 예시에서는 orders 테이블 예시를 바탕으로 빌드하여 테이블이 증분식으로 빌드되는 방식을 보여줍니다. 새로운 주문 데이터가 매일 제공되고 increment_key 매개변수 및 increment_offset 매개변수를 추가하면 기존 테이블에 추가할 수 있습니다.
view: orders {
derived_table: {
indexes: ["id"]
increment_key: "created_at"
increment_offset: 3
datagroup_trigger: standard_data_load
distribution_style: all
sql:
SELECT
user_id,
id,
created_at,
status
FROM
demo_db.orders
GROUP BY
user_id ;;
}
dimension: id {
primary_key: yes
type: number
sql: ${TABLE}.id ;; }
…
}
이 예시에서 increment_key 값은 새 데이터를 쿼리하여 PDT에 추가해야 하는 시간 증분값인 created_at으로 설정됩니다.
increment_offset 값은 3으로 설정되어 늦게 도착하는 데이터를 고려하여 다시 빌드되는 이전 기간 수(증분 키의 세분성 적용)를 지정합니다.
SQL 윈도우 함수 사용
일부 데이터베이스 언어는 특히 시퀀스 넘버, 기본 키, 누적 합계, 기타 유용한 다중 행 계산을 만들기 위한 윈도우 함수를 지원합니다. 기본 쿼리가 실행된 후에는 모든 derived_column 선언이 별도의 패스로 실행됩니다.
데이터베이스 언어가 윈도우 함수를 지원하는 경우 기본 파생 테이블에서 사용할 수 있습니다. 윈도우 함수가 포함된 sql 매개변수를 사용하여 derived_column 매개변수를 만듭니다. 값을 참조할 때는 기본 파생 테이블에 정의된 열 이름을 사용해야 합니다.
다음 예시에서는 user_id, order_id, created_time 열이 포함된 기본 파생 테이블을 만드는 방법을 보여줍니다. 그런 다음 SQL ROW_NUMBER() 윈도우 함수가 있는 파생 열을 사용하여 고객 주문의 시퀀스 넘버가 포함된 열을 계산합니다.
view: user_order_sequences {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: order_id {
field: order_items.order_id
}
column: created_time {
field: order_items.created_time
}
derived_column: user_sequence {
sql: ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY created_time) ;;
}
}
}
dimension: order_id {
hidden: yes
}
dimension: user_sequence {
type: number
}
}
계산된 값의 파생 열 만들기
derived_column 매개변수를 추가하여 explore_source 매개변수의 Explore에 없는 열을 지정할 수 있습니다. 각 derived_column 매개변수에는 값 구성 방법을 지정하는 sql 매개변수가 있습니다.
sql 계산에서 column 매개변수를 사용하여 지정된 모든 열을 사용할 수 있습니다. 파생 열은 집계 함수를 포함할 수 없지만 테이블의 단일 행에서 수행할 수 있는 계산은 포함할 수 있습니다.
이 예시에서는 기본 파생 테이블의 lifetime_customer_value 및 lifetime_number_of_orders 열에서 계산된 average_customer_order 열을 만듭니다.
view: user_order_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: users.id
}
column: lifetime_number_of_orders {
field: order_items.count
}
column: lifetime_customer_value {
field: order_items.total_profit
}
derived_column: average_customer_order {
sql: lifetime_customer_value / lifetime_number_of_orders ;;
}
}
}
dimension: user_id {
hidden: yes
}
dimension: lifetime_number_of_orders {
type: number
}
dimension: lifetime_customer_value {
type: number
}
dimension: average_customer_order {
type: number
}
}
최적화 전략
PDT가 데이터베이스에 저장되므로 언어에서 지원되는 대로 다음 전략을 사용하여 PDT를 최적화해야 합니다.
예를 들어 지속성을 추가하려면 데이터 그룹 orders_datagroup이 트리거될 때 다시 빌드하도록 PDT를 설정한 후 다음과 같이 customer_id 및 first_order 모두에 색인을 추가할 수 있습니다.
view: customer_order_summary {
derived_table: {
explore_source: orders {
...
}
datagroup_trigger: orders_datagroup
indexes: ["customer_id", "first_order"]
}
}
색인(또는 언어의 해당 항목)을 추가하지 않으면 Looker에서 쿼리 성능 향상을 위해 이 작업을 수행해야 한다는 경고 메시지를 표시합니다.
PDT를 사용하여 최적화 테스트
PDT를 사용하면 DBA나 ETL 개발자의 많은 지원 없이도 다양한 색인 생성, 배포, 기타 최적화 옵션을 테스트할 수 있습니다.
테이블이 있지만 여러 색인을 테스트하려는 경우를 가정해 보겠습니다. 뷰의 초기 LookML은 다음과 같을 수 있습니다.
view: customer {
sql_table_name: warehouse.customer ;;
}
최적화 전략을 테스트하려면 다음과 같이 indexes 매개변수를 사용하여 LookML에 색인을 추가하면 됩니다.
view: customer {
# sql_table_name: warehouse.customer
derived_table: {
sql: SELECT * FROM warehouse.customer ;;
persist_for: "8 hours"
indexes: [customer_id, customer_name, salesperson_id]
}
}
뷰를 한 번 쿼리하여 PDT를 생성합니다. 그런 다음 테스트 쿼리를 실행하고 결과를 비교합니다. 결과가 유리하면 DBA 또는 ETL팀에게 원본 테이블에 색인을 추가하도록 요청할 수 있습니다.
두 UNION 테이블
SQL 언어에서 지원되는 경우 두 파생 테이블 모두에서 SQL UNION 또는 UNION ALL 연산자를 실행할 수 있습니다. UNION 및 UNION ALL 연산자는 두 쿼리의 결과 집합을 결합합니다.
이 예시에서는 UNION을 사용하는 SQL 기반 파생 테이블이 어떻게 표시되는지 보여줍니다.
view: first_and_second_quarter_sales {
derived_table: {
sql:
SELECT * AS sales_records
FROM sales_records_first_quarter
UNION
SELECT * AS sales_records
FROM sales_records_second_quarter ;;
}
}
sql 매개변수의 UNION 문은 두 쿼리의 결과를 결합하는 파생 테이블을 생성합니다.
UNION과 UNION ALL의 차이점은 UNION ALL은 중복 행을 삭제하지 않는다는 것입니다. 데이터베이스 서버가 중복 행을 삭제하기 위해 추가 작업을 수행해야 하므로 UNION과 UNION ALL을 사용할 때 염두에 두어야 할 성능에 대한 고려사항이 있습니다.
합계 계산(측정값 측정기준화)
SQL 및 Looker의 일반 규칙에 따라 집계 함수의 결과를 기준으로 쿼리를 그룹화할 수 없습니다(Looker에서 측정값으로 표시됨). 집계되지 않은 필드를 기준으로만 그룹화할 수 있습니다(Looker에서 측정기준으로 표시됨).
집계별로 그룹화하려면(예를 들어 합계를 계산하기 위해) 측정값을 '측정기준화'해야 합니다. 이를 위한 한 가지 방법은 집계의 서브 쿼리를 효과적으로 만드는 파생 테이블을 사용하는 것입니다.
Explore부터 시작하여 Looker는 파생 테이블의 전체 또는 대부분에 대해 LookML을 생성할 수 있습니다. Explore를 만들고 파생 테이블에 포함할 모든 필드를 선택하면 됩니다. 그런 다음 기본(또는 SQL 기반) 파생 테이블 LookML을 생성하려면 다음 단계를 따르세요.
Explore의 톱니바퀴 메뉴를 클릭하고 LookML 가져오기를 선택합니다.
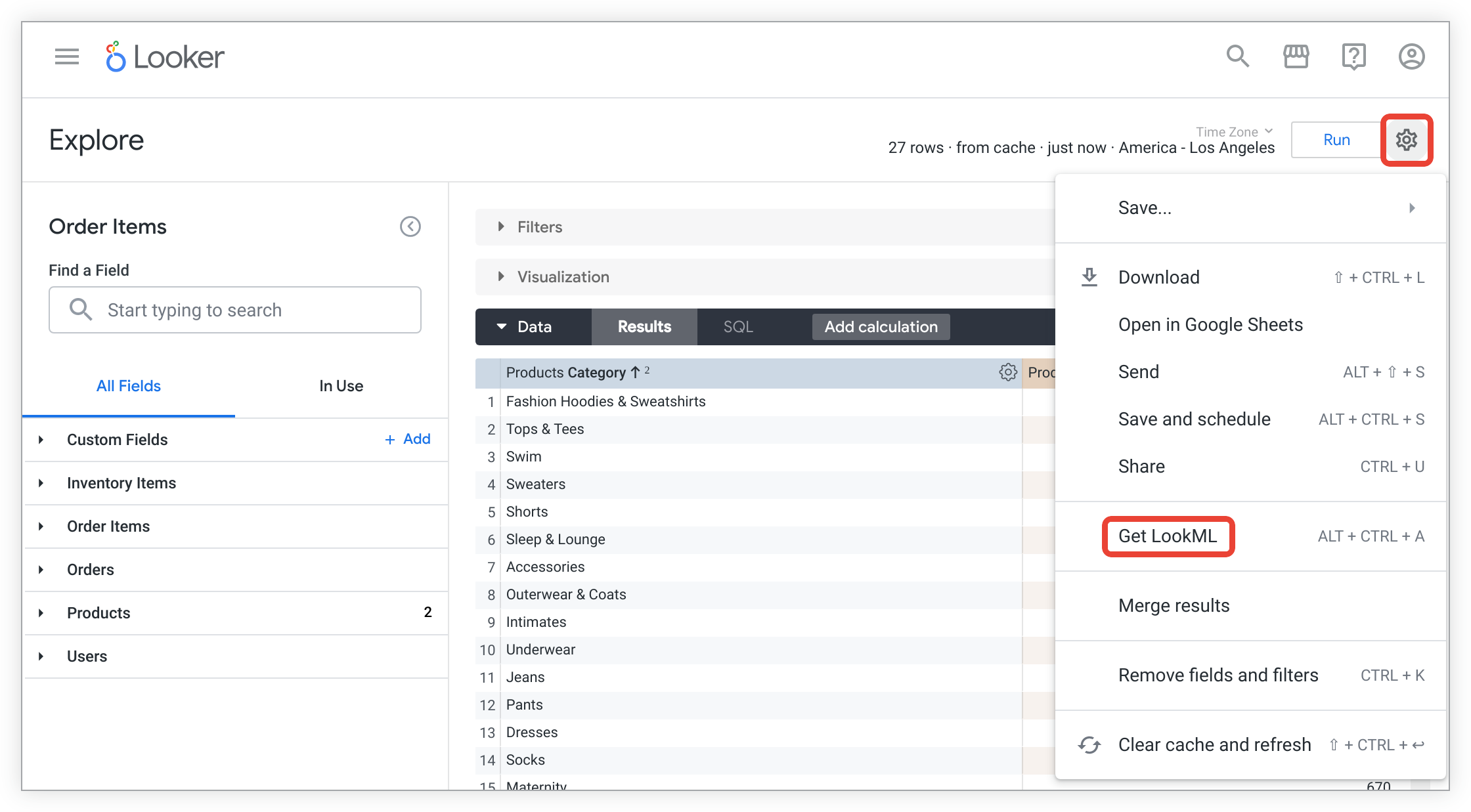
Explore의 기본 파생 테이블을 만드는 LookML을 확인하려면 파생 테이블 탭을 클릭합니다.
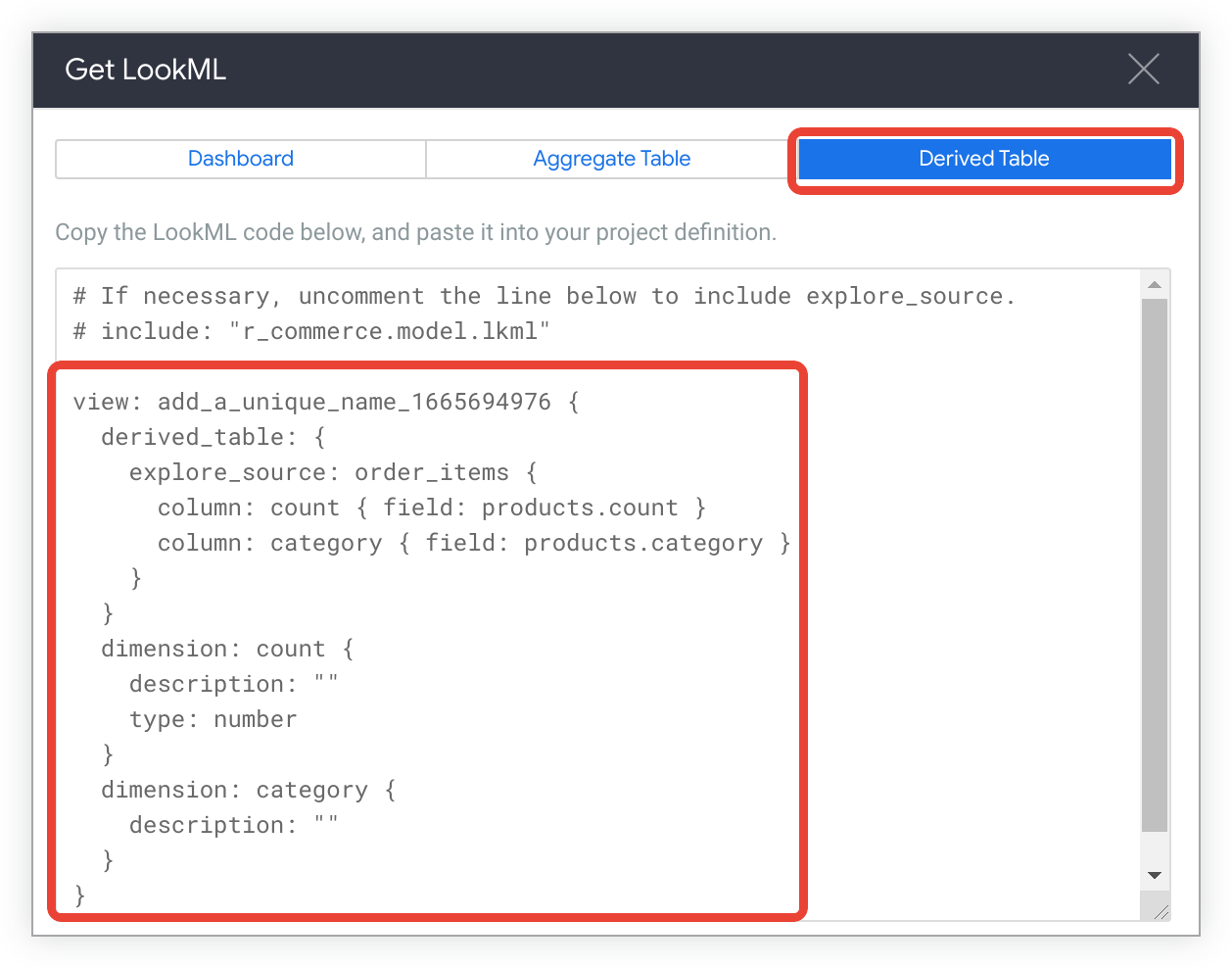
LookML을 복사합니다.
이제 생성된 LookML을 복사했으므로 다음 단계에 따라 뷰 파일에 붙여넣습니다.
Looker IDE에서 프로젝트 파일 목록 상단에 있는 +를 클릭하고 뷰 만들기를 선택합니다. 또는 폴더 내에 파일을 만들려면 폴더 메뉴를 클릭하고 뷰 만들기를 선택합니다.
뷰 이름을 의미 있는 이름으로 설정합니다.
원하는 경우 열 이름을 변경하고, 파생 열을 지정하고, 필터를 추가합니다.
집계 인식이 포함된 롤업 테이블
Looker에서는 성능을 높이기 위해 집계 테이블이나 롤업이 필요한 대규모 데이터 세트 또는 테이블이 있는 경우가 많습니다.
이제 Looker의 집계 인식을 사용하여 다양한 수준의 세부사항, 차원, 집계에 대해 집계 테이블을 사전 구성할 수 있으며, 기존 Explore 내에서 이를 사용하는 방법을 Looker에 알릴 수 있습니다. 그러면 쿼리는 사용자 입력 없이 Looker가 적절하다고 간주하는 롤업 테이블을 사용합니다. 이렇게 하면 쿼리 크기가 줄어들고 대기 시간이 단축되며 사용자 환경이 향상됩니다.
다음은 Looker 모델에서 아주 간단한 구현 방식으로 가볍게 집계된 인식의 정도를 보여줍니다. FAA를 통해 기록된 모든 항공편에 대한 행이 있는 데이터베이스의 가상의 항공편 테이블이 있다면 Looker에서 이 테이블을 자체 뷰 및 Explore로 모델링할 수 있습니다. 다음은 Explore에 정의할 수 있는 집계 테이블의 LookML입니다.
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
이 집계 테이블을 사용하면 사용자가 flights Explore를 쿼리할 수 있으며 Looker에서 집계 테이블을 자동으로 사용하여 쿼리에 답변합니다. 집계 인식에 대한 자세한 둘러보기는 집계 인식 튜토리얼을 참조하세요.