Le tabelle derivate aprono un mondo di possibilità analitiche avanzate, ma possono essere difficili da affrontare, implementare e risolvere i problemi. Questo ricettario contiene i casi d'uso più comuni delle tabelle derivate in Looker.
Questa pagina contiene i seguenti esempi:
- Creazione di una tabella alle 3:00 ogni giorno
- Aggiungere nuovi dati a una tabella di grandi dimensioni
- Utilizzare le funzioni finestra SQL
- Creazione di colonne derivate per i valori calcolati
- Strategie di ottimizzazione
- Utilizzare le PDT per testare le ottimizzazioni
UNIONdue tabelle- Calcolo della somma di una somma (dimensionalizzazione di una misura)
- Tabelle di riepilogo con riconoscimento degli aggregati
Risorse della tabella derivata
Questi cookbook presuppongono una conoscenza introduttiva di LookML e delle tabelle derivate. Devi avere familiarità con la creazione di visualizzazioni e la modifica del file del modello. Se vuoi ripassare uno di questi argomenti, consulta le seguenti risorse:
- Tabelle derivate
- Termini e concetti di LookML
- Creare tabelle derivate native
- Riferimento al parametro
derived_table - Memorizzazione nella cache delle query e ricreazione delle PDT con i gruppi di dati
Creazione di una tabella alle 3:00 ogni giorno
I dati in questo esempio vengono inseriti alle 2 del mattino ogni giorno. I risultati di una query su questi dati saranno gli stessi, indipendentemente dall'ora in cui viene eseguita, ovvero alle 3:00 o alle 21:00. Pertanto, è consigliabile creare la tabella una volta al giorno e consentire agli utenti di estrarre i risultati da una cache.
L'inclusione del datagroup nel file del modello consente di riutilizzarlo con più tabelle ed esplorazioni. Questo gruppo di dati contiene un parametro sql_trigger_value che indica al gruppo di dati quando attivare e ricreare la tabella derivata.
Per altri esempi di espressioni di trigger, consulta la documentazione di sql_trigger_value.
## in the model file
datagroup: standard_data_load {
sql_trigger_value: SELECT FLOOR(((TIMESTAMP_DIFF(CURRENT_TIMESTAMP(),'1970-01-01 00:00:00',SECOND)) - 60*60*3)/(60*60*24)) ;;
max_cache_age: "24 hours"
}
explore: orders {
…
Aggiungi il parametro datagroup_trigger alla definizione di derived_table nel file della vista e specifica il nome del datagruppo che vuoi utilizzare. In questo esempio, il gruppo di dati è standard_data_load.
view: orders {
derived_table: {
indexes: ["id"]
datagroup_trigger: standard_data_load
sql:
SELECT
user_id,
id,
created_at,
status
FROM
demo_db.orders
GROUP BY
user_id ;;
}
…
}
Aggiunta di nuovi dati a una tabella di grandi dimensioni
Una PDT incrementale è una tabella derivata persistente che Looker crea aggiungendo nuovi dati alla tabella, anziché ricostruirla interamente.
L'esempio successivo si basa sulla tabella orders per mostrare come viene creata in modo incrementale. I nuovi dati sugli ordini vengono inseriti ogni giorno e possono essere aggiunti alla tabella esistente quando aggiungi un parametro increment_key e un parametro increment_offset.
view: orders {
derived_table: {
indexes: ["id"]
increment_key: "created_at"
increment_offset: 3
datagroup_trigger: standard_data_load
distribution_style: all
sql:
SELECT
user_id,
id,
created_at,
status
FROM
demo_db.orders
GROUP BY
user_id ;;
}
dimension: id {
primary_key: yes
type: number
sql: ${TABLE}.id ;; }
…
}
Il valore increment_key è impostato su created_at, ovvero l'incremento di tempo per cui devono essere eseguiti query e aggiunti alla PDT in questo esempio.
Il valore increment_offset è impostato su 3 per specificare il numero di periodi di tempo precedenti (alla granularità della chiave di incremento) che vengono ricostruiti per tenere conto dei dati in arrivo in ritardo.
Utilizzo delle funzioni finestra SQL
Alcuni dialetti di database supportano le funzioni finestra, in particolare per creare numeri di sequenza, chiavi primarie, totali parziali e cumulativi e altri utili calcoli su più righe. Dopo l'esecuzione della query principale, tutte le dichiarazioni derived_column vengono eseguite in un passaggio separato.
Se il dialetto del database supporta le funzioni finestra, puoi utilizzarle nella tabella derivata nativa. Crea un parametro derived_column con un parametro sql che contenga la funzione finestra. Quando fai riferimento ai valori, devi utilizzare il nome della colonna definito nella tabella derivata nativa.
Il seguente esempio mostra come creare una tabella derivata nativa che includa le colonne user_id, order_id e created_time. A questo punto, utilizzeresti una colonna derivata con una funzione finestra SQL ROW_NUMBER() per calcolare una colonna che contiene il numero di sequenza dell'ordine di un cliente.
view: user_order_sequences {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: order_id {
field: order_items.order_id
}
column: created_time {
field: order_items.created_time
}
derived_column: user_sequence {
sql: ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY created_time) ;;
}
}
}
dimension: order_id {
hidden: yes
}
dimension: user_sequence {
type: number
}
}
Creare colonne derivate per i valori calcolati
Puoi aggiungere derived_column parametri per specificare colonne che non esistono nell'esplorazione del parametro explore_source. Ogni parametro derived_column ha un parametro sql che specifica come costruire il valore.
Il calcolo di sql può utilizzare qualsiasi colonna specificata utilizzando i parametri column. Le colonne derivate non possono includere funzioni di aggregazione, ma possono includere calcoli che possono essere eseguiti su una singola riga della tabella.
Questo esempio crea una colonna average_customer_order, che viene calcolata dalle colonne lifetime_customer_value e lifetime_number_of_orders nella tabella derivata nativa.
view: user_order_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: users.id
}
column: lifetime_number_of_orders {
field: order_items.count
}
column: lifetime_customer_value {
field: order_items.total_profit
}
derived_column: average_customer_order {
sql: lifetime_customer_value / lifetime_number_of_orders ;;
}
}
}
dimension: user_id {
hidden: yes
}
dimension: lifetime_number_of_orders {
type: number
}
dimension: lifetime_customer_value {
type: number
}
dimension: average_customer_order {
type: number
}
}
Strategie di ottimizzazione
Poiché le PDT sono archiviate nel database, devi ottimizzarle utilizzando le seguenti strategie, supportate dal dialetto:
Ad esempio, per aggiungere la persistenza, puoi impostare la PDT in modo che venga ricreata quando viene attivato il gruppo di dati orders_datagroup, quindi puoi aggiungere indici sia a customer_id che a first_order, come mostrato di seguito:
view: customer_order_summary {
derived_table: {
explore_source: orders {
...
}
datagroup_trigger: orders_datagroup
indexes: ["customer_id", "first_order"]
}
}
Se non aggiungi un indice (o un equivalente per il tuo dialetto), Looker ti avviserà che devi farlo per migliorare le prestazioni delle query.
Utilizzare i test PDT per testare le ottimizzazioni
Puoi utilizzare le PDT per testare diverse opzioni di indicizzazione, distribuzione e altre opzioni di ottimizzazione senza richiedere un grande supporto da parte degli sviluppatori DBA o ETL.
Considera un caso in cui hai una tabella, ma vuoi testare indici diversi. Il codice LookML iniziale per la vista potrebbe essere simile al seguente:
view: customer {
sql_table_name: warehouse.customer ;;
}
Per testare le strategie di ottimizzazione, puoi utilizzare il parametro indexes per aggiungere indici al codice LookML, come mostrato di seguito:
view: customer {
# sql_table_name: warehouse.customer
derived_table: {
sql: SELECT * FROM warehouse.customer ;;
persist_for: "8 hours"
indexes: [customer_id, customer_name, salesperson_id]
}
}
Esegui una query sulla vista una volta per generare il PDT. Poi esegui le query di test e confronta i risultati. Se i risultati sono favorevoli, puoi chiedere al team DBA o ETL di aggiungere gli indici alla tabella originale.
UNION due tabelle
Puoi eseguire un operatore SQL UNION o UNION ALL in entrambe le tabelle derivate se il dialetto SQL lo supporta. Gli operatori UNION e UNION ALL combinano i set di risultati di due query.
Questo esempio mostra l'aspetto di una tabella derivata basata su SQL con un UNION:
view: first_and_second_quarter_sales {
derived_table: {
sql:
SELECT * AS sales_records
FROM sales_records_first_quarter
UNION
SELECT * AS sales_records
FROM sales_records_second_quarter ;;
}
}
L'istruzione UNION nel parametro sql produce una tabella derivata che combina i risultati di entrambe le query.
La differenza tra UNION e UNION ALL è che UNION ALL non rimuove le righe duplicate. Quando utilizzi UNION anziché UNION ALL, devi tenere presente alcune considerazioni sul rendimento, in quanto il server di database deve eseguire un lavoro aggiuntivo per rimuovere le righe duplicate.
Calcolo della somma di una somma (dimensionalizzazione di una misura)
Come regola generale in SQL e, di conseguenza, in Looker, non puoi raggruppare una query in base ai risultati di una funzione di aggregazione (rappresentata in Looker come misure). Puoi raggruppare solo per campi non aggregati (rappresentati in Looker come dimensioni).
Per raggruppare in base a un'aggregazione (ad esempio per calcolare la somma di una somma), devi "dimensionalizzare" una misura. Un modo per farlo è utilizzare una tabella derivata, che crea in modo efficace una sottoquery dell'aggregazione.
A partire da un'esplorazione, Looker può generare LookML per tutta o la maggior parte della tabella derivata. Ti basta creare un'esplorazione e selezionare tutti i campi che vuoi includere nella tabella derivata. Poi, per generare il codice LookML della tabella derivata nativa (o basata su SQL):
Fai clic sul menu a forma di ingranaggio dell'esplorazione e seleziona Ottieni LookML.
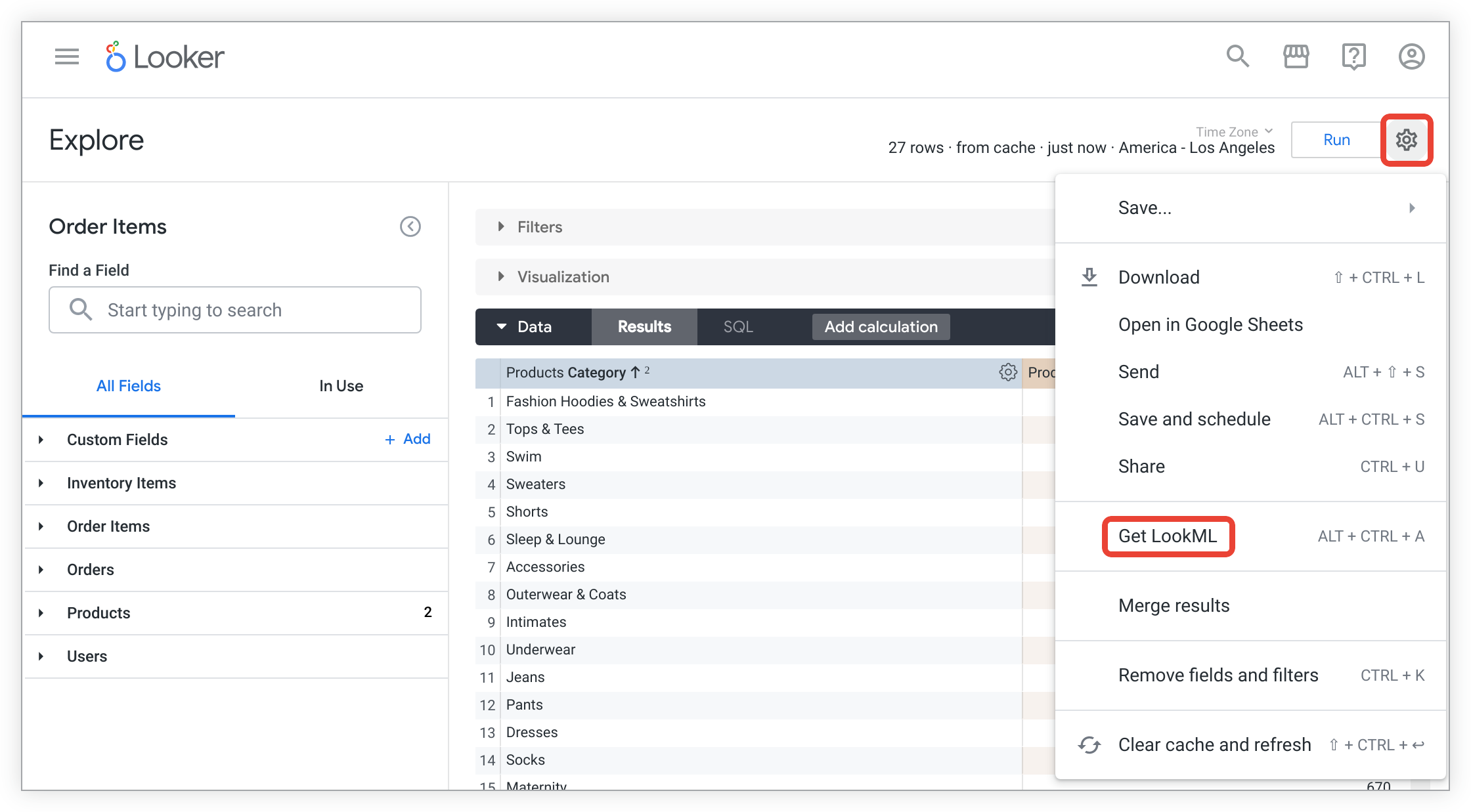
Per visualizzare il codice LookML per la creazione di una tabella derivata nativa per l'Esplorazione, fai clic sulla scheda Tabella derivata.

Copia il LookML.
Ora che hai copiato il codice LookML generato, incollalo in un file di visualizzazione seguendo questi passaggi:
In modalità di sviluppo, vai ai file di progetto.
Fai clic su + nella parte superiore dell'elenco dei file di progetto nell'IDE di Looker e seleziona Crea vista. In alternativa, per creare il file all'interno della cartella, fai clic sul menu di una cartella e seleziona Crea visualizzazione.
Imposta un nome significativo per la visualizzazione.
Se vuoi, puoi modificare i nomi delle colonne, specificare le colonne derivate e aggiungere filtri.
Tabelle di rollup con consapevolezza aggregata
In Looker, spesso potresti incontrare set di dati o tabelle molto grandi che, per essere efficienti, richiedono tabelle di aggregazione o rollup.
Con la consapevolezza aggregata di Looker, puoi pre-costruire tabelle aggregate a vari livelli di granularità, dimensionalità e aggregazione e puoi comunicare a Looker come utilizzarle all'interno delle esplorazioni esistenti. Le query utilizzeranno quindi queste tabelle di rollup quando Looker lo riterrà opportuno, senza alcun input utente. In questo modo, la dimensione delle query verrà ridotta, i tempi di attesa diminuiranno e l'esperienza utente migliorerà.
Di seguito è riportata un'implementazione molto semplice in un modello Looker per dimostrare quanto possa essere semplice la consapevolezza degli aggregati. Data una tabella ipotetica dei voli nel database con una riga per ogni volo registrato tramite la FAA, puoi modellare questa tabella in Looker con una propria visualizzazione ed esplorazione. Di seguito è riportato il codice LookML per una tabella aggregata che puoi definire per l'esplorazione:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
Con questa tabella aggregata, un utente può eseguire query in flights Esplora e Looker utilizzerà automaticamente la tabella aggregata per rispondere alle query. Per una procedura dettagliata più approfondita della consapevolezza aggregata, consulta il tutorial sulla consapevolezza aggregata.