BigQuery 支援資料表中的巢狀記錄。巢狀記錄可以是單一記錄,也可以包含重複的值。本頁面將概要說明如何在 Looker 中使用 BigQuery 巢狀資料。
巢狀記錄的優點
掃描分散式資料集時,使用巢狀記錄有幾項優點:
- 巢狀記錄不需要彙整。這表示計算速度可以加快,且掃描的資料量會比每次查詢時必須重新加入額外資料時少得多。
- 巢狀結構本質上是預先彙整的資料表。如果您不參照巢狀資料欄,查詢就不會產生額外費用,因為 BigQuery 資料會儲存在資料欄中。如果您參照巢狀資料欄,邏輯就會與同區彙整相同。
- 巢狀結構可避免重複資料,否則這些資料會在寬廣的去規格化表格中重複。換句話說,如果某人曾居住於五個城市,寬鬆的非正規資料表會在五個資料列中包含所有相關資訊 (每個曾居住的城市一個)。在巢狀結構中,重複的資訊只會佔用一列,因為五個城市的陣列可包含在單一列中,並在需要時解除巢狀結構。
在 LookML 中使用巢狀記錄
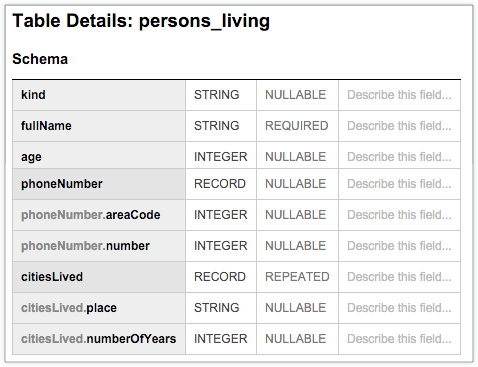
下列 BigQuery 表格 persons_living 會顯示典型的結構定義,用於儲存範例使用者資料,包括 fullName、age、phoneNumber 和 citiesLived,以及每個資料欄的資料類型和模式。這份結構定義顯示「citiesLived」citiesLived欄中的值重複出現,表示部分使用者可能曾居住於多個城市:
以下範例是 LookML,可用於您根據先前顯示的結構定義建立的探索和檢視。有三個檢視畫面:persons、persons_cities_lived 和 persons_phone_number。這項探索與使用非巢狀資料表編寫的探索相同。
注意:雖然下列範例中的所有元件 (檢視畫面和 Explore) 都是以單一程式碼區塊編寫,但建議您將檢視畫面放在個別的檢視畫面檔案中,並將 Explore 和 connection: 規格放在模型檔案中。
-- model file
connection: "bigquery_publicdata_standard_sql"
explore: persons {
# Repeated nested object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived ;;
relationship: one_to_many
}
# Non repeated nested object
join: persons_phone_number {
view_label: "Persons: Phone:"
sql: LEFT JOIN UNNEST([${persons.phoneNumber}]) as persons_phone_number ;;
relationship: one_to_one
}
}
-- view files
view: persons {
sql_table_name: bigquery-samples.nested.persons_living ;;
dimension: id {
primary_key: yes
sql: ${TABLE}.fullName ;;
}
dimension: fullName {label: "Full Name"}
dimension: kind {}
dimension: age {type:number}
dimension: citiesLived {hidden:yes}
dimension: phoneNumber {hidden:yes}
measure: average_age {
type: average
sql: ${age} ;;
drill_fields: [fullName,age]
}
measure: count {
type: count
drill_fields: [fullName, cities_lived.place_count, age]
}
}
view: persons_phone_number {
dimension: areaCode {label: "Area Code"}
dimension: number {}
}
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${place} AS STRING)) ;;
}
dimension: place {}
dimension: numberOfYears {
label: "Number Of Years"
type: number
}
measure: place_count {
type: count
drill_fields: [place, persons.count]
}
measure: total_years {
type: sum
sql: ${numberOfYears} ;;
drill_fields: [persons.fullName, persons.age, place, numberOfYears]
}
}
以下各節將更詳細說明 LookML 中處理巢狀資料的各個元件:
瀏覽次數
每個巢狀記錄都會寫入為檢視畫面。舉例來說,phoneNumber 檢視畫面只會宣告記錄中顯示的維度:
view: persons_phone_number {
dimension: areaCode {label: "Area Code"}
dimension: number {}
}
persons_cities_lived 檢視畫面較為複雜。如 LookML 範例所示,您可以定義記錄中顯示的維度 (numberOfYears 和 place),但也可以定義一些指標。指標和 drill_fields 的定義與一般情況相同,就好像這些資料位於專屬表格中一樣。唯一的差異在於,您會將 id 宣告為 primary_key,以便正確計算匯總資料。
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${place} AS STRING)) ;;
}
dimension: place {}
dimension: numberOfYears {
label: "Number Of Years"
type: number
}
measure: place_count {
type: count
drill_fields: [place, persons.count]
}
measure: total_years {
type: sum
sql: ${numberOfYears} ;;
drill_fields: [persons.fullName, persons.age, place, numberOfYears]
}
}
記錄宣告
在包含子記錄的檢視畫面 (在本例中為 persons) 中,您需要宣告記錄。這些值會在建立彙整時使用。您可以使用 hidden 參數隱藏這些 LookML 欄位,因為您在探索資料時不需要這些欄位。
view: persons {
...
dimension: citiesLived {
hidden:yes
}
dimension: phoneNumber {
hidden:yes
}
...
}
彙整
BigQuery 中的巢狀記錄是 STRUCT 元素的陣列。彙整關係會建構在資料表中,而非透過 sql_on 參數彙整。在這種情況下,您可以使用 sql: 彙整參數,以便使用 UNNEST 運算子。除了這個差異之外,解開 STRUCT 元素的陣列,就跟彙整資料表一樣。
如果是不會重複的記錄,您可以直接使用 STRUCT;只要將其放在方括號內,即可將其轉換為 STRUCT 元素的陣列。雖然這可能看起來很奇怪,但似乎不會影響效能,而且還能讓程式保持簡潔。
explore: persons {
# Repeated nested object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived ;;
relationship: one_to_many
}
# Non repeated nested object
join: persons_phone_number {
view_label: "Persons: Phone:"
sql: LEFT JOIN UNNEST([${persons.phoneNumber}]) as persons_phone_number ;;
relationship: one_to_one
}
}
針對沒有每個資料列專屬鍵的陣列執行彙整
雖然在資料中使用可辨識的自然鍵,或在 ETL 程序中建立的代替鍵,是最佳做法,但這不一定可行。舉例來說,您可能會遇到某些陣列沒有相對的資料列不重複索引鍵。這時 WITH OFFSET 就能在彙整語法中派上用場。
舉例來說,如果某人曾居住於多個城市 (例如芝加哥、丹佛、舊金山),代表該人的資料欄可能會載入多次。如果沒有提供日期或其他可識別的自然鍵來區分該人在各個城市的任期,就很難在未巢狀結構的資料列上建立主鍵。這就是 WITH OFFSET 可為每個未巢狀資料列提供相對資料列編號 (0、1、2、3) 的地方。這種做法可保證未巢狀列上的專屬鍵:
explore: persons {
# Repeated nested Object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived WITH OFFSET as person_cities_lived_offset;;
relationship: one_to_many
}
}
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${offset} AS STRING)) ;;
}
dimension: offset {
type: number
sql: person_cities_lived_offset;;
}
}
簡單重複的值
BigQuery 中的巢狀資料也可以是簡單值,例如整數或字串。如要展開簡單重複值的陣列,您可以使用與先前所示類似的方法,在彙整中使用 UNNEST 運算子。
以下範例會展開指定的整數陣列 `unresolved_skus`:
explore: impressions {
join: impressions_unresolved_sku {
sql: LEFT JOIN UNNEST(unresolved_skus) AS impressions_unresolved_sku ;;
relationship: one_to_many
}
}
view: impressions_unresolved_sku {
dimension: sku {
type: string
sql: ${TABLE} ;;
}
}
整數陣列 unresolved_skus 的 sql 參數會以 ${TABLE} 表示。這會直接參照值表本身,然後在 explore 中取消巢狀結構。