BigQuery mendukung data bertingkat dalam tabel. Data bertingkat dapat berupa satu data atau berisi nilai berulang. Halaman ini memberikan ringkasan tentang cara menggunakan data bertingkat BigQuery di Looker.
Keuntungan data bertingkat
Ada beberapa keuntungan menggunakan data bertingkat saat Anda memindai set data terdistribusi:
- Data bertingkat tidak memerlukan join. Artinya, komputasi dapat lebih cepat dan memindai lebih sedikit data daripada jika Anda harus menggabungkan kembali data tambahan setiap kali membuat kueri.
- Struktur bertingkat pada dasarnya adalah tabel yang telah digabungkan sebelumnya. Tidak ada biaya tambahan untuk kueri jika Anda tidak mereferensikan kolom bertingkat, karena data BigQuery disimpan dalam kolom. Jika Anda mereferensikan kolom bertingkat, logikanya sama dengan join yang ditempatkan berdekatan.
- Struktur bertingkat menghindari data berulang yang harus diulang dalam tabel denormalisasi yang luas. Dengan kata lain, untuk seseorang yang telah tinggal di lima kota, tabel denormalisasi lebar akan berisi semua informasinya dalam lima baris (satu untuk setiap kota tempat ia tinggal). Dalam struktur bertingkat, informasi berulang hanya memerlukan satu baris karena array lima kota dapat ditampung dalam satu baris dan tidak bertingkat saat diperlukan.
Bekerja dengan data bertingkat di LookML
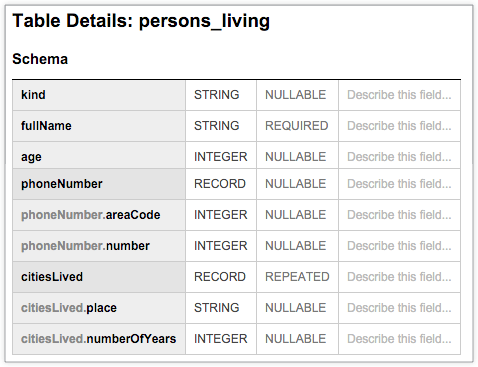
Tabel BigQuery berikut, persons_living, menampilkan skema standar yang menyimpan contoh data pengguna, termasuk fullName, age, phoneNumber, dan citiesLived beserta jenis data dan mode setiap kolom. Skema menunjukkan bahwa nilai di kolom citiesLived diulang, yang menunjukkan bahwa beberapa pengguna mungkin pernah tinggal di beberapa kota:
Contoh berikut adalah LookML untuk Jelajah dan tampilan yang dapat Anda buat dari skema sebelumnya yang ditampilkan. Ada tiga tampilan: persons, persons_cities_lived, dan persons_phone_number. Penjelajahan ini terlihat identik dengan Penjelajahan yang ditulis dengan tabel yang tidak bertingkat.
Catatan: Meskipun semua komponen (tampilan dan Jelajahi) ditulis dalam satu blok kode dalam contoh berikut, praktik terbaiknya adalah menempatkan tampilan di setiap file tampilan dan menempatkan Jelajahi dan spesifikasi connection: di file model.
-- model file
connection: "bigquery_publicdata_standard_sql"
explore: persons {
# Repeated nested object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived ;;
relationship: one_to_many
}
# Non repeated nested object
join: persons_phone_number {
view_label: "Persons: Phone:"
sql: LEFT JOIN UNNEST([${persons.phoneNumber}]) as persons_phone_number ;;
relationship: one_to_one
}
}
-- view files
view: persons {
sql_table_name: bigquery-samples.nested.persons_living ;;
dimension: id {
primary_key: yes
sql: ${TABLE}.fullName ;;
}
dimension: fullName {label: "Full Name"}
dimension: kind {}
dimension: age {type:number}
dimension: citiesLived {hidden:yes}
dimension: phoneNumber {hidden:yes}
measure: average_age {
type: average
sql: ${age} ;;
drill_fields: [fullName,age]
}
measure: count {
type: count
drill_fields: [fullName, cities_lived.place_count, age]
}
}
view: persons_phone_number {
dimension: areaCode {label: "Area Code"}
dimension: number {}
}
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${place} AS STRING)) ;;
}
dimension: place {}
dimension: numberOfYears {
label: "Number Of Years"
type: number
}
measure: place_count {
type: count
drill_fields: [place, persons.count]
}
measure: total_years {
type: sum
sql: ${numberOfYears} ;;
drill_fields: [persons.fullName, persons.age, place, numberOfYears]
}
}
Setiap komponen untuk menangani data bertingkat di LookML dibahas secara lebih mendetail di bagian berikut:
Dilihat
Setiap kumpulan data bertingkat ditulis sebagai tampilan. Misalnya, tampilan phoneNumber hanya mendeklarasikan dimensi yang muncul dalam data:
view: persons_phone_number {
dimension: areaCode {label: "Area Code"}
dimension: number {}
}
Tampilan persons_cities_lived lebih kompleks. Seperti yang ditunjukkan dalam contoh LookML, Anda menentukan dimensi yang muncul dalam kumpulan data (numberOfYears dan place), tetapi Anda juga dapat menentukan beberapa ukuran. Ukuran dan drill_fields ditentukan seperti biasa, seolah-olah data ini berada dalam tabelnya sendiri. Satu-satunya perbedaan nyata adalah Anda mendeklarasikan id sebagai primary_key sehingga agregat dihitung dengan benar.
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${place} AS STRING)) ;;
}
dimension: place {}
dimension: numberOfYears {
label: "Number Of Years"
type: number
}
measure: place_count {
type: count
drill_fields: [place, persons.count]
}
measure: total_years {
type: sum
sql: ${numberOfYears} ;;
drill_fields: [persons.fullName, persons.age, place, numberOfYears]
}
}
Mencatat deklarasi
Dalam tampilan yang berisi subdata (dalam hal ini persons), Anda perlu mendeklarasikan data. Ini akan digunakan saat Anda membuat join. Anda dapat menyembunyikan kolom LookML ini dengan parameter hidden karena Anda tidak akan membutuhkannya saat menjelajahi data.
view: persons {
...
dimension: citiesLived {
hidden:yes
}
dimension: phoneNumber {
hidden:yes
}
...
}
Gabungan
Kumpulan data bertingkat di BigQuery adalah array elemen STRUCT. Alih-alih bergabung dengan parameter sql_on, hubungan join dibuat ke dalam tabel. Dalam hal ini, Anda dapat menggunakan parameter join sql: sehingga dapat menggunakan operator UNNEST. Selain perbedaan tersebut, membatalkan penyusunan bertingkat array elemen STRUCT sama persis dengan menggabungkan tabel.
Untuk data yang tidak berulang, Anda cukup menggunakan STRUCT; Anda dapat mengubahnya menjadi array elemen STRUCT dengan menempatkannya dalam tanda kurung siku. Meskipun hal ini mungkin tampak aneh, tampaknya tidak ada penalti performa — dan hal ini membuat semuanya tetap bersih dan sederhana.
explore: persons {
# Repeated nested object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived ;;
relationship: one_to_many
}
# Non repeated nested object
join: persons_phone_number {
view_label: "Persons: Phone:"
sql: LEFT JOIN UNNEST([${persons.phoneNumber}]) as persons_phone_number ;;
relationship: one_to_one
}
}
Gabungan untuk array tanpa kunci unik untuk setiap baris
Meskipun sebaiknya memiliki kunci alami yang dapat diidentifikasi dalam data, atau kunci pengganti yang dibuat dalam proses ETL, hal ini tidak selalu memungkinkan. Misalnya, Anda dapat mengalami situasi saat beberapa array tidak memiliki kunci unik relatif untuk baris. Di sinilah WITH OFFSET dapat berguna dalam sintaksis join.
Misalnya, kolom yang mewakili seseorang mungkin dimuat beberapa kali jika orang tersebut telah tinggal di beberapa kota — Chicago, Denver, San Francisco, dll. Sulit untuk membuat kunci utama pada baris yang tidak bertingkat jika tanggal atau kunci alami yang dapat diidentifikasi lainnya tidak diberikan untuk membedakan masa jabatan orang tersebut di setiap kota. Di sinilah WITH OFFSET dapat memberikan nomor baris relatif (0,1,2,3) untuk setiap baris yang tidak disusun bertingkat. Pendekatan ini menjamin kunci unik pada baris yang tidak bertingkat:
explore: persons {
# Repeated nested Object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived WITH OFFSET as person_cities_lived_offset;;
relationship: one_to_many
}
}
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${offset} AS STRING)) ;;
}
dimension: offset {
type: number
sql: person_cities_lived_offset;;
}
}
Nilai berulang sederhana
Data bertingkat di BigQuery juga dapat berupa nilai sederhana, seperti bilangan bulat atau string. Untuk membatalkan penyusunan bertingkat array nilai berulang sederhana, Anda dapat menggunakan pendekatan serupa seperti yang ditunjukkan sebelumnya, menggunakan operator UNNEST dalam join.
Contoh berikut membatalkan penyusunan bertingkat array bilangan bulat tertentu, `unresolved_skus`:
explore: impressions {
join: impressions_unresolved_sku {
sql: LEFT JOIN UNNEST(unresolved_skus) AS impressions_unresolved_sku ;;
relationship: one_to_many
}
}
view: impressions_unresolved_sku {
dimension: sku {
type: string
sql: ${TABLE} ;;
}
}
Parameter sql untuk array bilangan bulat, unresolved_skus, direpresentasikan sebagai ${TABLE}. Ini langsung mereferensikan tabel nilai itu sendiri, yang kemudian dihapus bertingkat di explore.