BigQuery는 테이블에서 중첩 레코드를 지원합니다. 중첩 레코드는 단일 레코드이거나 반복 값을 포함할 수 있습니다. 이 페이지에서는 Looker에서 BigQuery 중첩 데이터를 사용하는 방법을 간략히 설명합니다.
중첩 레코드 장점
분산 데이터 세트를 스캔할 때 중첩 레코드를 사용하면 몇 가지 이점이 있습니다.
- 중첩 레코드는 조인이 필요하지 않습니다. 즉, 쿼리할 때마다 추가 데이터를 다시 조인해야 하는 것보다 계산이 빠르고 데이터를 훨씬 적게 스캔할 수 있습니다.
- 중첩 구조는 기본적으로 사전 조인된 테이블입니다. BigQuery 데이터는 열에 저장되므로 중첩된 열을 참조하지 않으면 쿼리에 대한 추가 비용이 발생하지 않습니다. 중첩된 열을 참조하는 경우 논리는 배치된 조인과 동일합니다.
- 중첩 구조는 광범위한 비정규화 테이블에서 반복되어야 하는 데이터를 반복하지 않습니다. 즉, 5개 도시에 거주한 사람의 경우 광범위한 비정규화 테이블에는 모든 정보가 5개 행에 포함되어 있습니다(각 도시에 하나씩). 중첩 구조에서는 5개 도시 배열을 단일 행에 포함할 수 있고 필요할 때 중첩을 해제할 수 있으므로 반복되는 정보가 1개 행만 사용합니다.
LookML에서 중첩 레코드 사용
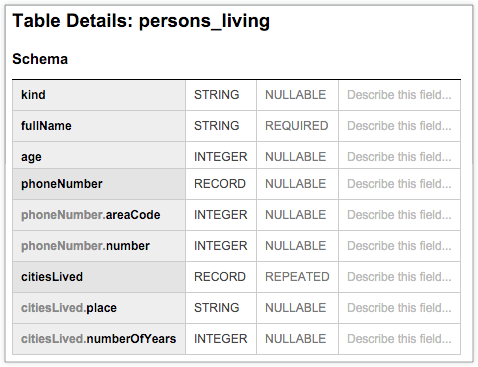
다음 BigQuery 테이블인 persons_living은 fullName, age, phoneNumber, citiesLived를 포함한 예시 사용자 데이터를 각 열의 datatype 및 mode와 함께 저장하는 일반적인 스키마를 표시합니다. 스키마에는 citiesLived 열의 값이 반복되어 일부 사용자가 여러 도시에 거주했을 수 있음을 보여줍니다.
다음 예시는 표시된 이전 스키마에서 만들 수 있는 Explore 및 뷰의 LookML입니다. 세 가지 뷰, 즉 persons, persons_cities_lived, persons_phone_number가 있습니다. Explore는 중첩되지 않은 테이블로 작성된 Explore와 동일하게 표시됩니다.
참고: 다음 예에서 모든 구성요소(뷰 및 Explore)는 하나의 코드 블록으로 작성되지만 개별 뷰 파일에 뷰를 배치하고 모델 파일에 Explore 및 connection: 사양을 배치하는 것이 좋습니다.
-- model file
connection: "bigquery_publicdata_standard_sql"
explore: persons {
# Repeated nested object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived ;;
relationship: one_to_many
}
# Non repeated nested object
join: persons_phone_number {
view_label: "Persons: Phone:"
sql: LEFT JOIN UNNEST([${persons.phoneNumber}]) as persons_phone_number ;;
relationship: one_to_one
}
}
-- view files
view: persons {
sql_table_name: bigquery-samples.nested.persons_living ;;
dimension: id {
primary_key: yes
sql: ${TABLE}.fullName ;;
}
dimension: fullName {label: "Full Name"}
dimension: kind {}
dimension: age {type:number}
dimension: citiesLived {hidden:yes}
dimension: phoneNumber {hidden:yes}
measure: average_age {
type: average
sql: ${age} ;;
drill_fields: [fullName,age]
}
measure: count {
type: count
drill_fields: [fullName, cities_lived.place_count, age]
}
}
view: persons_phone_number {
dimension: areaCode {label: "Area Code"}
dimension: number {}
}
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${place} AS STRING)) ;;
}
dimension: place {}
dimension: numberOfYears {
label: "Number Of Years"
type: number
}
measure: place_count {
type: count
drill_fields: [place, persons.count]
}
measure: total_years {
type: sum
sql: ${numberOfYears} ;;
drill_fields: [persons.fullName, persons.age, place, numberOfYears]
}
}
LookML에서 중첩된 데이터를 사용하는 각 구성요소는 다음 섹션에서 더 자세히 설명합니다.
뷰
각 중첩 레코드는 뷰로 작성됩니다. 예를 들어 phoneNumber 뷰는 레코드에 표시되는 측정기준을 간단히 선언합니다.
view: persons_phone_number {
dimension: areaCode {label: "Area Code"}
dimension: number {}
}
persons_cities_lived 뷰는 더 복잡합니다. LookML 예시와 같이 레코드에 표시되는 측정기준(numberOfYears 및 place)을 정의하지만 일부 측정값을 정의할 수도 있습니다. 이 데이터는 자체 테이블에 있는 것처럼 평소와 같이 drill_fields로 정의됩니다. 유일한 차이점은 집계가 제대로 계산되도록 id를 primary_key로 선언하는 것입니다.
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${place} AS STRING)) ;;
}
dimension: place {}
dimension: numberOfYears {
label: "Number Of Years"
type: number
}
measure: place_count {
type: count
drill_fields: [place, persons.count]
}
measure: total_years {
type: sum
sql: ${numberOfYears} ;;
drill_fields: [persons.fullName, persons.age, place, numberOfYears]
}
}
레코드 선언
하위 레코드가 포함된 뷰(이 경우 persons)에서 레코드를 선언해야 합니다. 이러한 레코드는 조인을 만들 때 사용됩니다. 데이터를 탐색할 때는 이러한 LookML 필드가 필요하지 않으므로 hidden 매개변수를 사용하여 이러한 필드를 숨길 수 있습니다.
view: persons {
...
dimension: citiesLived {
hidden:yes
}
dimension: phoneNumber {
hidden:yes
}
...
}
조인
BigQuery의 중첩 레코드는 STRUCT 요소 배열입니다. sql_on 매개변수와 조인하는 대신 조인 관계가 테이블에 빌드됩니다. 이 경우 sql: 조인 매개변수를 사용하여 UNNEST 연산자를 사용할 수 있습니다. 그 차이를 제외하면 STRUCT 요소 배열을 중첩 해제하는 것은 테이블 조인과 정확히 같습니다.
반복되지 않는 레코드의 경우 STRUCT을 사용하면 됩니다. 대괄호 안에 배치하여 STRUCT 요소의 배열로 변환할 수 있습니다. 이상하게 보일 수도 있지만 성능 저하가 없기 때문에 깔끔하고 단순하게 유지됩니다.
explore: persons {
# Repeated nested object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived ;;
relationship: one_to_many
}
# Non repeated nested object
join: persons_phone_number {
view_label: "Persons: Phone:"
sql: LEFT JOIN UNNEST([${persons.phoneNumber}]) as persons_phone_number ;;
relationship: one_to_one
}
}
각 행에서 고유한 키 없이 배열 조인
데이터에 식별 가능한 자연 키를 사용하거나 ETL 프로세스에서 서로게이트 키를 생성하는 것이 가장 좋지만 이것이 항상 가능한 것은 아닙니다. 예를 들어 일부 배열에 행에 대한 상대 고유 키가 없는 경우가 발생할 수 있습니다. 이때 WITH OFFSET를 조인 구문으로 유용하게 사용할 수 있습니다.
예를 들어 한 사람이 시카고, 덴버, 샌프란시스코 등 여러 도시에 거주한 경우, 한 사람을 나타내는 열이 여러 번 로드될 수 있습니다. 각 도시에서 사용자의 근속 기간을 구분하기 위해 날짜나 기타 식별 가능한 자연 키가 제공되지 않으면 중첩되지 않은 행에 기본 키를 만들기가 어려울 수 있습니다. 여기서 WITH OFFSET는 중첩되지 않은 각 행의 상대 행 번호(0,1,2,3)를 제공할 수 있습니다. 이 방식은 중첩되지 않은 행에서 고유 키를 보장합니다.
explore: persons {
# Repeated nested Object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived WITH OFFSET as person_cities_lived_offset;;
relationship: one_to_many
}
}
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${offset} AS STRING)) ;;
}
dimension: offset {
type: number
sql: person_cities_lived_offset;;
}
}
단순한 반복 값
BigQuery의 중첩 데이터는 정수나 문자열과 같은 간단한 값이 될 수도 있습니다. 간단한 반복 값의 배열을 중첩 해제하려면 조인에서 UNNEST 연산자를 사용하여 앞서 설명한 것과 유사한 접근 방식을 사용하면 됩니다.
다음 예시에서는 지정된 정수 배열 `unresolved_skus`를 중첩 해제합니다.
explore: impressions {
join: impressions_unresolved_sku {
sql: LEFT JOIN UNNEST(unresolved_skus) AS impressions_unresolved_sku ;;
relationship: one_to_many
}
}
view: impressions_unresolved_sku {
dimension: sku {
type: string
sql: ${TABLE} ;;
}
}
정수 배열 unresolved_skus의 sql 매개변수는 ${TABLE}로 표시됩니다. 이렇게 하면 값 테이블 자체가 직접 참조되고, 이후에 explore에서 중첩 해제됩니다.