O BigQuery suporta registos aninhados em tabelas. Os registos aninhados podem ser um único registo ou conter valores repetidos. Esta página apresenta uma vista geral do trabalho com dados aninhados do BigQuery no Looker.
As vantagens dos registos aninhados
Existem algumas vantagens na utilização de registos aninhados quando analisa um conjunto de dados distribuído:
- Os registos aninhados não requerem junções. Isto significa que os cálculos podem ser mais rápidos e analisar muito menos dados do que se tivesse de juntar os dados adicionais sempre que os consultasse.
- As estruturas aninhadas são essencialmente tabelas com junção prévia. Não existe qualquer despesa adicional para a consulta se não fizer referência à coluna aninhada, porque os dados do BigQuery são armazenados em colunas. Se fizer referência à coluna aninhada, a lógica é idêntica a uma junção colocada.
- As estruturas aninhadas evitam a repetição de dados que teriam de ser repetidos numa tabela desnormalizada ampla. Por outras palavras, para uma pessoa que viveu em cinco cidades, uma tabela desnormalizada ampla conteria todas as informações em cinco linhas (uma para cada uma das cidades onde viveu). Numa estrutura aninhada, as informações repetidas ocupam apenas uma linha, uma vez que a matriz de cinco cidades pode ser contida numa única linha e desagrupada quando necessário.
Trabalhar com registos aninhados no LookML
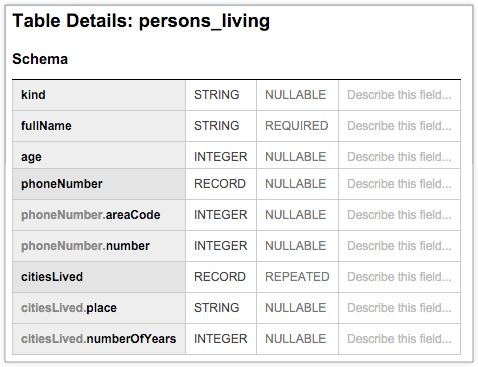
A tabela do BigQuery seguinte, persons_living, apresenta um esquema típico que armazena dados de utilizadores de exemplo, incluindo fullName, age, phoneNumber e citiesLived, juntamente com o tipo de dados e o modo de cada coluna. O esquema mostra que os valores na coluna citiesLived são repetidos, o que indica que alguns utilizadores podem ter vivido em várias cidades:
O exemplo seguinte é o LookML para as análises detalhadas e as vistas que pode criar a partir do esquema anterior apresentado. Existem três vistas: persons, persons_cities_lived e persons_phone_number. A exploração aparece idêntica a uma exploração escrita com tabelas não aninhadas.
Nota: embora todos os componentes (vistas e exploração) estejam escritos num bloco de código no exemplo seguinte, é uma prática recomendada colocar as vistas em ficheiros de vista individuais e colocar a especificação de explorações e connection: no ficheiro de modelo.
-- model file
connection: "bigquery_publicdata_standard_sql"
explore: persons {
# Repeated nested object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived ;;
relationship: one_to_many
}
# Non repeated nested object
join: persons_phone_number {
view_label: "Persons: Phone:"
sql: LEFT JOIN UNNEST([${persons.phoneNumber}]) as persons_phone_number ;;
relationship: one_to_one
}
}
-- view files
view: persons {
sql_table_name: bigquery-samples.nested.persons_living ;;
dimension: id {
primary_key: yes
sql: ${TABLE}.fullName ;;
}
dimension: fullName {label: "Full Name"}
dimension: kind {}
dimension: age {type:number}
dimension: citiesLived {hidden:yes}
dimension: phoneNumber {hidden:yes}
measure: average_age {
type: average
sql: ${age} ;;
drill_fields: [fullName,age]
}
measure: count {
type: count
drill_fields: [fullName, cities_lived.place_count, age]
}
}
view: persons_phone_number {
dimension: areaCode {label: "Area Code"}
dimension: number {}
}
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${place} AS STRING)) ;;
}
dimension: place {}
dimension: numberOfYears {
label: "Number Of Years"
type: number
}
measure: place_count {
type: count
drill_fields: [place, persons.count]
}
measure: total_years {
type: sum
sql: ${numberOfYears} ;;
drill_fields: [persons.fullName, persons.age, place, numberOfYears]
}
}
Cada componente para trabalhar com dados aninhados no LookML é abordado mais detalhadamente nas secções seguintes:
Visualizações
Cada registo aninhado é escrito como uma vista. Por exemplo, a vista phoneNumber declara simplesmente as dimensões que aparecem no registo:
view: persons_phone_number {
dimension: areaCode {label: "Area Code"}
dimension: number {}
}
A vista persons_cities_lived é mais complexa. Conforme mostrado no exemplo do LookML, define as dimensões que aparecem no registo (numberOfYears e place), mas também pode definir algumas medidas. As medidas e as drill_fields são definidas como habitualmente, como se estes dados estivessem na sua própria tabela. A única diferença real é que declara id como primary_key para que os dados agregados sejam calculados corretamente.
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${place} AS STRING)) ;;
}
dimension: place {}
dimension: numberOfYears {
label: "Number Of Years"
type: number
}
measure: place_count {
type: count
drill_fields: [place, persons.count]
}
measure: total_years {
type: sum
sql: ${numberOfYears} ;;
drill_fields: [persons.fullName, persons.age, place, numberOfYears]
}
}
Registe declarações
Na vista que contém os subregistos (neste caso, persons), tem de declarar os registos. Estes são usados quando cria as junções. Pode ocultar estes campos LookML com o parâmetro hidden, uma vez que não vai precisar deles quando explorar os dados.
view: persons {
...
dimension: citiesLived {
hidden:yes
}
dimension: phoneNumber {
hidden:yes
}
...
}
Aderir
Os registos aninhados no BigQuery são matrizes de STRUCTelementos. Em vez de participar com um parâmetro sql_on, a relação de participação é incorporada na tabela. Neste caso, pode usar o sql: parâmetro de junção para poder usar o UNNEST operador. Fora essa diferença, a anulação da aninhagem de um conjunto de elementos STRUCT é exatamente como juntar uma tabela.
No caso de registos não repetidos, pode simplesmente usar STRUCT. Pode transformá-lo num conjunto de elementos STRUCT colocando-o entre parênteses retos. Embora possa parecer estranho, não parece haver penalizações de desempenho, e isto mantém as coisas simples e organizadas.
explore: persons {
# Repeated nested object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived ;;
relationship: one_to_many
}
# Non repeated nested object
join: persons_phone_number {
view_label: "Persons: Phone:"
sql: LEFT JOIN UNNEST([${persons.phoneNumber}]) as persons_phone_number ;;
relationship: one_to_one
}
}
Junções para matrizes sem chaves únicas para cada linha
Embora seja melhor ter chaves naturais identificáveis nos dados ou chaves substitutas criadas no processo de ETL, nem sempre é possível. Por exemplo, pode encontrar uma situação em que algumas matrizes não têm uma chave única relativa para a linha. É aqui que WITH OFFSET pode ser útil na sintaxe de junção.
Por exemplo, uma coluna que representa uma pessoa pode ser carregada várias vezes se a pessoa tiver vivido em várias cidades: Chicago, Denver, São Francisco, etc. Pode ser difícil criar uma chave principal na linha não aninhada se não for fornecida uma data ou outra chave natural identificável para distinguir o período de permanência da pessoa em cada cidade. É aqui que WITH OFFSET pode fornecer um número de linha relativo (0,1,2,3) para cada linha não aninhada. Esta abordagem garante uma chave única na linha sem aninhamento:
explore: persons {
# Repeated nested Object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived WITH OFFSET as person_cities_lived_offset;;
relationship: one_to_many
}
}
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${offset} AS STRING)) ;;
}
dimension: offset {
type: number
sql: person_cities_lived_offset;;
}
}
Valores repetidos simples
Os dados aninhados no BigQuery também podem ser valores simples, como números inteiros ou strings. Para desagrupar matrizes de valores repetidos simples, pode usar uma abordagem semelhante à apresentada anteriormente, usando o operador UNNEST numa união.
O exemplo seguinte anula a aninhagem de uma determinada matriz de números inteiros, `unresolved_skus`:
explore: impressions {
join: impressions_unresolved_sku {
sql: LEFT JOIN UNNEST(unresolved_skus) AS impressions_unresolved_sku ;;
relationship: one_to_many
}
}
view: impressions_unresolved_sku {
dimension: sku {
type: string
sql: ${TABLE} ;;
}
}
O parâmetro sql para a matriz de números inteiros, unresolved_skus, é representado como ${TABLE}. Isto faz referência direta à própria tabela de valores, que é, em seguida, desagrupada em explore.