BigQuery admite registros anidados en tablas. Los registros anidados pueden ser un solo registro o contener valores repetidos. En esta página se ofrece una descripción general de cómo trabajar con datos anidados de BigQuery en Looker.
Ventajas de los registros anidados
Usar registros anidados al analizar un conjunto de datos distribuido ofrece varias ventajas:
- Los registros anidados no requieren combinaciones. Esto significa que los cálculos pueden ser más rápidos y escanear muchos menos datos que si tuvieras que volver a combinar los datos adicionales cada vez que los consultaras.
- Las estructuras anidadas son básicamente tablas unidas previamente. No hay ningún coste adicional por la consulta si no haces referencia a la columna anidada, ya que los datos de BigQuery se almacenan en columnas. Si haces referencia a la columna anidada, la lógica es idéntica a la de una combinación colocada.
- Las estructuras anidadas evitan que se repitan datos que tendrían que repetirse en una tabla desnormalizada amplia. En otras palabras, en el caso de una persona que haya vivido en cinco ciudades, una tabla desnormalizada amplia contendría toda su información en cinco filas (una por cada ciudad en la que haya vivido). En una estructura anidada, la información repetida solo ocupa una fila, ya que la matriz de cinco ciudades se puede incluir en una sola fila y desanidar cuando sea necesario.
Trabajar con registros anidados en LookML
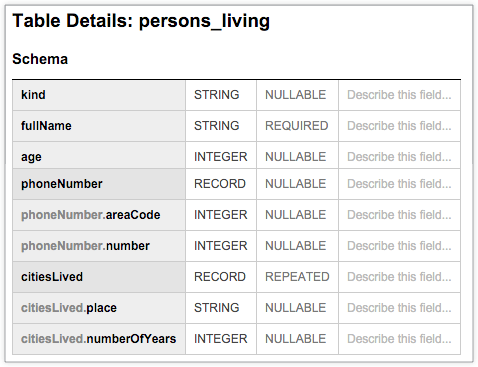
La siguiente tabla de BigQuery, persons_living, muestra un esquema típico que almacena datos de usuario de ejemplo, como fullName, age, phoneNumber y citiesLived, junto con el tipo de datos y el modo de cada columna. El esquema muestra que los valores de la columna citiesLived se repiten, lo que indica que algunos usuarios pueden haber vivido en varias ciudades:
En el siguiente ejemplo se muestra el LookML de los Exploraciones y las vistas que puedes crear a partir del esquema anterior. Hay tres vistas: persons, persons_cities_lived y persons_phone_number. La Exploración parece idéntica a una Exploración escrita con tablas no anidadas.
Nota: Aunque todos los componentes (vistas y Exploraciones) se escriben en un bloque de código en el siguiente ejemplo, es recomendable colocar las vistas en archivos de vista individuales y las Exploraciones y la especificación de connection: en el archivo de modelo.
-- model file
connection: "bigquery_publicdata_standard_sql"
explore: persons {
# Repeated nested object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived ;;
relationship: one_to_many
}
# Non repeated nested object
join: persons_phone_number {
view_label: "Persons: Phone:"
sql: LEFT JOIN UNNEST([${persons.phoneNumber}]) as persons_phone_number ;;
relationship: one_to_one
}
}
-- view files
view: persons {
sql_table_name: bigquery-samples.nested.persons_living ;;
dimension: id {
primary_key: yes
sql: ${TABLE}.fullName ;;
}
dimension: fullName {label: "Full Name"}
dimension: kind {}
dimension: age {type:number}
dimension: citiesLived {hidden:yes}
dimension: phoneNumber {hidden:yes}
measure: average_age {
type: average
sql: ${age} ;;
drill_fields: [fullName,age]
}
measure: count {
type: count
drill_fields: [fullName, cities_lived.place_count, age]
}
}
view: persons_phone_number {
dimension: areaCode {label: "Area Code"}
dimension: number {}
}
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${place} AS STRING)) ;;
}
dimension: place {}
dimension: numberOfYears {
label: "Number Of Years"
type: number
}
measure: place_count {
type: count
drill_fields: [place, persons.count]
}
measure: total_years {
type: sum
sql: ${numberOfYears} ;;
drill_fields: [persons.fullName, persons.age, place, numberOfYears]
}
}
En las siguientes secciones se explica con más detalle cada componente para trabajar con datos anidados en LookML:
Vistas
Cada registro anidado se escribe como una vista. Por ejemplo, la vista phoneNumber solo declara las dimensiones que aparecen en el registro:
view: persons_phone_number {
dimension: areaCode {label: "Area Code"}
dimension: number {}
}
La vista persons_cities_lived es más compleja. Como se muestra en el ejemplo de LookML, se definen las dimensiones que aparecen en el registro (numberOfYears y place), pero también se pueden definir algunas medidas. Las medidas y los drill_fields se definen de la forma habitual, como si estos datos estuvieran en su propia tabla. La única diferencia real es que declaras id como primary_key para que los agregados se calculen correctamente.
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${place} AS STRING)) ;;
}
dimension: place {}
dimension: numberOfYears {
label: "Number Of Years"
type: number
}
measure: place_count {
type: count
drill_fields: [place, persons.count]
}
measure: total_years {
type: sum
sql: ${numberOfYears} ;;
drill_fields: [persons.fullName, persons.age, place, numberOfYears]
}
}
Registrar declaraciones
En la vista que contiene los subregistros (en este caso, persons), debes declarar los registros. Se usarán cuando crees las uniones. Puedes ocultar estos campos de LookML con el parámetro hidden, ya que no los necesitarás al explorar los datos.
view: persons {
...
dimension: citiesLived {
hidden:yes
}
dimension: phoneNumber {
hidden:yes
}
...
}
Uniones
Los registros anidados de BigQuery son arrays de elementos STRUCT. En lugar de unirse con un parámetro sql_on, la relación de unión se crea en la tabla. En este caso, puede usar el parámetro de unión sql: para poder usar el operador UNNEST. Aparte de esa diferencia, desanidar una matriz de elementos STRUCT es exactamente igual que combinar una tabla.
En el caso de los registros no repetidos, puedes usar STRUCT. Para convertirlo en una matriz de elementos STRUCT, colócalo entre corchetes. Aunque pueda parecer extraño, no parece que haya ninguna penalización en el rendimiento, lo que hace que todo sea más sencillo.
explore: persons {
# Repeated nested object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived ;;
relationship: one_to_many
}
# Non repeated nested object
join: persons_phone_number {
view_label: "Persons: Phone:"
sql: LEFT JOIN UNNEST([${persons.phoneNumber}]) as persons_phone_number ;;
relationship: one_to_one
}
}
Uniones de arrays sin claves únicas para cada fila
Aunque lo ideal es que los datos tengan claves naturales identificables o claves subrogadas creadas en el proceso de ETL, no siempre es posible. Por ejemplo, puede que te encuentres en una situación en la que algunas matrices no tengan una clave única relativa para la fila. Aquí es donde WITH OFFSET puede ser útil en la sintaxis de unión.
Por ejemplo, una columna que representa a una persona puede cargarse varias veces si la persona ha vivido en varias ciudades (Chicago, Denver, San Francisco, etc.). Puede ser difícil crear una clave principal en la fila sin anidar si no se proporciona una fecha u otra clave natural identificable para distinguir la permanencia de la persona en cada ciudad. Aquí es donde WITH OFFSET puede proporcionar un número de fila relativo (0,1,2,3) para cada fila no anidada. De esta forma, se garantiza que la fila sin anidar tenga una clave única:
explore: persons {
# Repeated nested Object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived WITH OFFSET as person_cities_lived_offset;;
relationship: one_to_many
}
}
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${offset} AS STRING)) ;;
}
dimension: offset {
type: number
sql: person_cities_lived_offset;;
}
}
Valores repetidos sencillos
Los datos anidados de BigQuery también pueden ser valores simples, como números enteros o cadenas. Para desanidar matrices de valores repetidos simples, puedes usar un enfoque similar al que se ha mostrado anteriormente, usando el operador UNNEST en una unión.
En el siguiente ejemplo se desanida una matriz de números enteros determinada, `unresolved_skus`:
explore: impressions {
join: impressions_unresolved_sku {
sql: LEFT JOIN UNNEST(unresolved_skus) AS impressions_unresolved_sku ;;
relationship: one_to_many
}
}
view: impressions_unresolved_sku {
dimension: sku {
type: string
sql: ${TABLE} ;;
}
}
El parámetro sql de la matriz de números enteros unresolved_skus se representa como ${TABLE}. Hace referencia directamente a la tabla de valores, que se desanida en explore.