BigQuery 支持在表中使用嵌套记录。嵌套记录可以是单个记录,也可以包含重复值。本页面简要介绍了如何在 Looker 中处理 BigQuery 嵌套数据。
嵌套记录的优势
在扫描分布式数据集时,使用嵌套记录有以下几点优势:
- 嵌套记录不需要联接。这意味着,与每次查询时都必须重新联接额外数据相比,计算速度可以更快,并且扫描的数据量要少得多。
- 嵌套结构本质上是预联接的表。如果您不引用嵌套列,则查询不会产生额外费用,因为 BigQuery 数据存储在列中。如果您引用嵌套列,则逻辑与共置联接相同。
- 嵌套结构可避免重复数据,而这些数据在宽度较大的非规范化表中必须重复。换句话说,对于一个曾居住过五个城市的用户,宽的非规范化表会在五行中(每行对应一个城市)包含该用户的所有信息。在嵌套结构中,重复的信息只占用一行,因为五个城市的数组可以包含在一行中,并在需要时取消嵌套。
在 LookML 中处理嵌套记录
以下 BigQuery 表 persons_living 显示了一个典型的架构,用于存储示例用户数据,包括 fullName、age、phoneNumber 和 citiesLived,以及每列的数据类型和模式。架构显示 citiesLived 列中的值重复,这表明部分用户可能居住过多个城市:
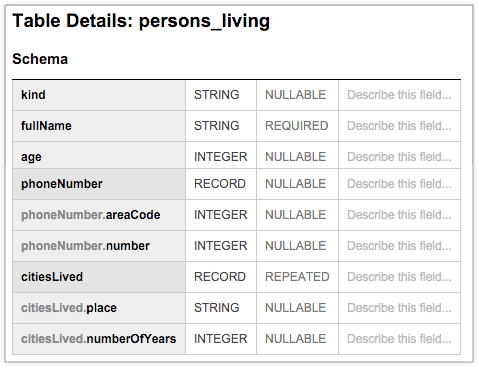
以下示例是您可以根据上方显示的架构创建的探索和视图的 LookML。有三个视图:persons、persons_cities_lived 和 persons_phone_number。该探索与使用非嵌套表编写的探索完全相同。
注意:虽然以下示例中的所有组件(视图和探索)都编写在一个代码块中,但最佳实践是将视图放置在单独的视图文件中,并将探索和 connection: 规范放置在模型文件中。
-- model file
connection: "bigquery_publicdata_standard_sql"
explore: persons {
# Repeated nested object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived ;;
relationship: one_to_many
}
# Non repeated nested object
join: persons_phone_number {
view_label: "Persons: Phone:"
sql: LEFT JOIN UNNEST([${persons.phoneNumber}]) as persons_phone_number ;;
relationship: one_to_one
}
}
-- view files
view: persons {
sql_table_name: bigquery-samples.nested.persons_living ;;
dimension: id {
primary_key: yes
sql: ${TABLE}.fullName ;;
}
dimension: fullName {label: "Full Name"}
dimension: kind {}
dimension: age {type:number}
dimension: citiesLived {hidden:yes}
dimension: phoneNumber {hidden:yes}
measure: average_age {
type: average
sql: ${age} ;;
drill_fields: [fullName,age]
}
measure: count {
type: count
drill_fields: [fullName, cities_lived.place_count, age]
}
}
view: persons_phone_number {
dimension: areaCode {label: "Area Code"}
dimension: number {}
}
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${place} AS STRING)) ;;
}
dimension: place {}
dimension: numberOfYears {
label: "Number Of Years"
type: number
}
measure: place_count {
type: count
drill_fields: [place, persons.count]
}
measure: total_years {
type: sum
sql: ${numberOfYears} ;;
drill_fields: [persons.fullName, persons.age, place, numberOfYears]
}
}
以下各部分详细介绍了在 LookML 中处理嵌套数据的每个组件:
视图
每个嵌套记录都会写入为视图。例如,phoneNumber 视图只声明记录中显示的维度:
view: persons_phone_number {
dimension: areaCode {label: "Area Code"}
dimension: number {}
}
persons_cities_lived 视图更复杂。如 LookML 示例所示,您可以定义记录中显示的维度(numberOfYears 和 place),但也可以定义一些测量。测量和 drill_fields 的定义与往常一样,就像这些数据位于自己的表中一样。唯一的实际区别在于,您将 id 声明为 primary_key,以便正确计算汇总值。
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${place} AS STRING)) ;;
}
dimension: place {}
dimension: numberOfYears {
label: "Number Of Years"
type: number
}
measure: place_count {
type: count
drill_fields: [place, persons.count]
}
measure: total_years {
type: sum
sql: ${numberOfYears} ;;
drill_fields: [persons.fullName, persons.age, place, numberOfYears]
}
}
记录声明
在包含子记录的视图(在本例中为 persons)中,您需要声明记录。您在创建联接时会用到这些值。您可以使用 hidden 参数隐藏这些 LookML 字段,因为您在探索数据时不需要它们。
view: persons {
...
dimension: citiesLived {
hidden:yes
}
dimension: phoneNumber {
hidden:yes
}
...
}
联接
BigQuery 中的嵌套记录是 STRUCT 元素的数组。联接关系内置于表中,而不是使用 sql_on 参数进行联接。在这种情况下,您可以使用 sql: 联接参数,以便使用 UNNEST 运算符。除此差异外,展开 STRUCT 元素数组与联接表完全相同。
对于非重复记录,您只需使用 STRUCT;您可以将其放入方括号中,将其转换为 STRUCT 元素的数组。虽然这可能看起来很奇怪,但似乎不会影响性能,而且这样做可以保持代码的简洁性。
explore: persons {
# Repeated nested object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived ;;
relationship: one_to_many
}
# Non repeated nested object
join: persons_phone_number {
view_label: "Persons: Phone:"
sql: LEFT JOIN UNNEST([${persons.phoneNumber}]) as persons_phone_number ;;
relationship: one_to_one
}
}
对没有为每行提供唯一键的数组进行联接
虽然最好在数据中使用可识别的自然键,或在 ETL 流程中创建代理键,但这并不总是可行的。例如,您可能会遇到某些数组没有行相对唯一键的情况。在这种情况下,WITH OFFSET 在联接语法中非常有用。
例如,如果某个人曾居住在芝加哥、丹佛、旧金山等多个城市,那么代表该人的列可能会多次加载。如果未提供日期或其他可识别的自然键来区分该人在每个城市的居住时长,则很难在非嵌套行上创建主键。在这里,WITH OFFSET 可以为每个非嵌套行提供相对行号 (0,1,2,3)。这种方法可保证非嵌套行具有唯一键:
explore: persons {
# Repeated nested Object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived WITH OFFSET as person_cities_lived_offset;;
relationship: one_to_many
}
}
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${offset} AS STRING)) ;;
}
dimension: offset {
type: number
sql: person_cities_lived_offset;;
}
}
简单的重复值
BigQuery 中的嵌套数据还可以是简单值,例如整数或字符串。如需展开由简单重复值组成的数组,您可以使用与上文中所示类似的方法,即在联接中使用 UNNEST 运算符。
以下示例会展开给定的整数数组“unresolved_skus”:
explore: impressions {
join: impressions_unresolved_sku {
sql: LEFT JOIN UNNEST(unresolved_skus) AS impressions_unresolved_sku ;;
relationship: one_to_many
}
}
view: impressions_unresolved_sku {
dimension: sku {
type: string
sql: ${TABLE} ;;
}
}
整数数组 unresolved_skus 的 sql 参数表示为 ${TABLE}。这会直接引用值表本身,然后在 explore 中取消嵌套。