Quando você tem permissão para criar campos personalizados, é possível criar grupos personalizados ad hoc para dimensões sem usar funções lógicas em expressões do Looker ou desenvolver a lógicaCASE WHENem parâmetrossqlou campostype: case.
Também é possível criar agrupamentos personalizados específicos para dimensões de tipo numérico sem precisar usar funções lógicas em expressões do Looker ou desenvolver campos do LookML type: tier quando você tem permissão para criar campos personalizados.
A divisão em grupos pode ser muito útil para criar dimensões de agrupamento personalizadas no Looker.
Há três maneiras de criar buckets no Looker:
- Como usar o tipo
dimensiontier - Como usar o parâmetro
case - Usar uma instrução SQL
CASE WHENno parâmetroSQLde um campo do LookML
Como usar tier para agrupar
Para criar classes de números inteiros, basta definir o tipo dimension como tier:
dimension: users_lifetime_orders_tier {
type: tier
tiers: [0,1,2,5,10]
sql: ${users_lifetime_orders} ;;
}
Você pode usar o parâmetro style para personalizar a aparência das camadas na pesquisa. As quatro opções para style são as seguintes:
Exemplo:
dimension: age_tier {
type: tier
tiers: [0,10,20,30,40,50,60,70,80]
style: integer
sql: ${age} ;;
}
O parâmetro style classic é o padrão e usa o formato Tx[x,x] com Tx indicando o número de camadas e [x,x] indicando o intervalo. A imagem a seguir é uma tabela de dados da Análise detalhada com a contagem de usuários agrupada por idade dos usuários:
![A categoria "Idade dos usuários" mais alta disponível na tabela de dados é T02[10,20], indicando uma contagem de 808 usuários com idades entre 10 e 20 anos.](https://cloud.google.com/static/looker/docs/images/bucketing-in-looker-1-2210.png?hl=pt-br)
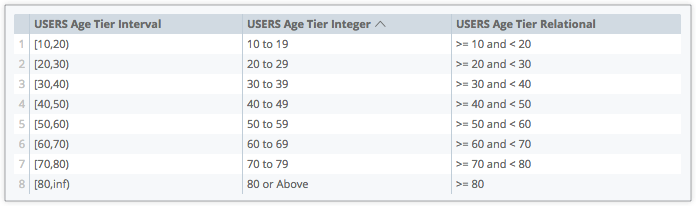
A próxima imagem mostra exemplos das outras opções de parâmetro style:
-
interval: com o formato[x,x], que indica o valor mais baixo e o mais alto de um nível. -
integer: com o formatox to x, que indica o valor mais baixo e o mais alto de um nível. -
relational: com o formato>= x and <x, que indica que um valor é maior ou igual ao valor do nível mais baixo e menor que o valor do nível mais alto.
Considerações
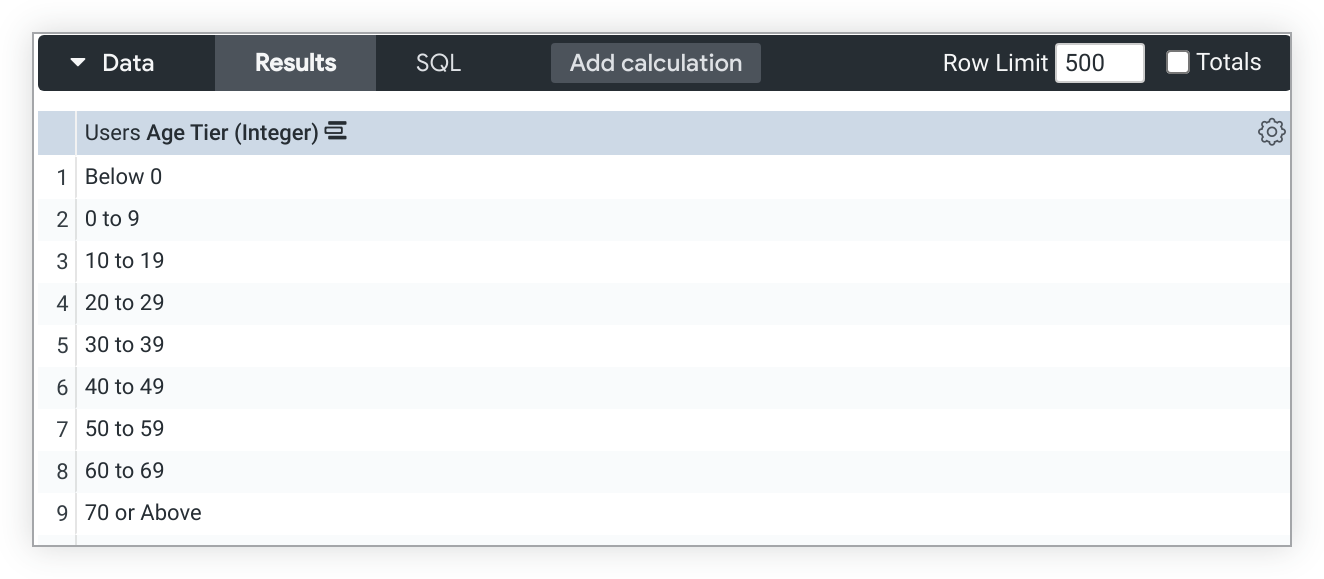
O uso de tier com preenchimento de dimensão pode resultar em buckets de nível inesperados.
Por exemplo, uma dimensão type: tier, Nível de idade, vai mostrar os intervalos de nível para Abaixo de 0 e 0 a 9 quando o preenchimento de dimensão estiver ativado, mesmo que os dados não incluam valores de idade para esses intervalos:
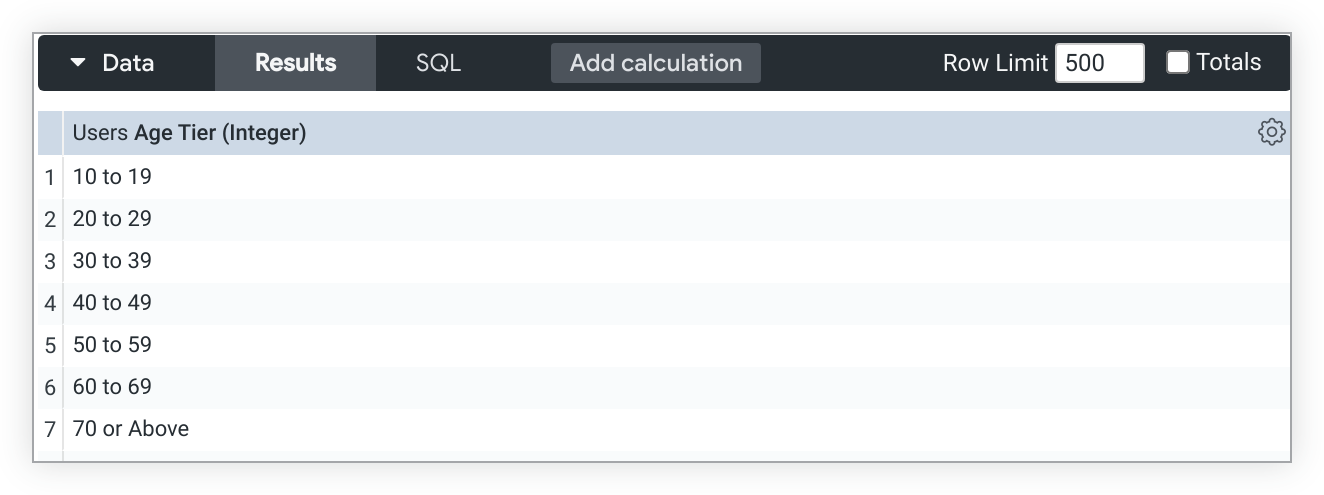
Quando o preenchimento de dimensão está desativado para Nível de idade, os buckets refletem com mais precisão os valores de idade disponíveis nos dados, começando com o bucket 10 a 19:
Para ativar ou desativar o preenchimento de dimensão, passe o cursor sobre o nome da dimensão na Análise, clique no ícone de engrenagem no nível do campo e selecione Remover valores de nível preenchidos para desativar ou Preencher valores de nível ausentes para ativar.
Saiba mais sobre o tiers do Looker na página de documentação Dimensões, filtros e tipos de parâmetros.
Como usar case para agrupar
É possível usar o parâmetro case para criar buckets com nome personalizado e classificação personalizada. O parâmetro case é recomendado para um conjunto fixo de buckets, porque pode ajudar a controlar a forma como os valores são apresentados, ordenados e usados em filtros e visualizações da interface. Por exemplo, com case, um usuário pode selecionar apenas os valores de grupo definidos em um filtro.
Para criar buckets com case, defina uma dimensão, como um bucket para valores de pedidos:
dimension: order_amount_bucket {
case: {
when: {
sql: ${order_amount} <= 50;;
label: "Small"
}
when: {
sql: ${order_amount} > 50 AND ${order_amount} <= 150;;
label: "Medium"
}
when: {
sql: ${order_amount} > 150;;
label: "Large"
}
else:"Unknown"
}
}
O parâmetro case geralmente classifica os valores na ordem em que os buckets são listados. Para a dimensão order_amount_bucket, a ordem dos buckets é Pequeno, Médio e Grande:

Se você quiser classificar de forma alfanumérica, adicione o parâmetro alpha_sort
à dimensão, como esta:
dimension: order_amount_bucket {
alpha_sort: yes
case: {
when: {
sql: ${order_amount} <= 50;;
label: "Small"
}
when: {
sql: ${order_amount} > 50 AND ${order_amount} <= 150;;
label: "Medium"
}
when: {
sql: ${order_amount} > 150;;
label: "Large"
}
else:"Unknown"
}
}
Para dimensões em que muitos valores distintos são desejados na saída (isso exigiria que você definisse cada saída com uma instrução WHEN ou ELSE) ou quando você quiser implementar uma instrução ELSE mais complexa, recomendamos o uso de um CASE WHEN SQL, discutido na próxima seção.
Leia mais sobre o parâmetro case na página de documentação Parâmetros de campo.
Como usar o SQL CASE WHEN para agrupar
Uma instrução CASE WHEN do SQL é recomendada para agrupamentos mais complexos ou para a implementação de uma instrução ELSE mais detalhada.
Por exemplo, você pode usar métodos de agrupamento diferentes, dependendo do destino de um pedido. Uma instrução CASE WHEN SQL pode ser usada para criar uma dimensão de bucket composta, em que a instrução THEN retorna dimensões em vez de strings:
dimension: compound_buckets {
sql:
CASE
WHEN ${orders.destination} = 'US' THEN ${us_buckets}
WHEN ${orders.destination} = 'CA' THEN ${canada_buckets}
ELSE ${intl_buckets}
END ;;
}