Nesta página, exploramos os padrões de arquitetura mais comuns para uma implantação hospedada pelo cliente e descrevemos as práticas recomendadas para implementá-los. Para usar esta página de maneira eficaz, você precisa conhecer os conceitos e práticas de arquitetura de sistemas.
Estratégia de fluxo de trabalho
Depois de identificar a auto-hospedagem como uma opção viável para sua implementação do Looker, a próxima etapa é elaborar a estratégia que será usada pela implantação.
- Faça uma avaliação. Identifique uma lista de fluxos de trabalho planejados e atuais.
- Liste os padrões de arquitetura aplicáveis. Começando pelos fluxos de trabalho indicados, identifique os padrões de arquitetura aplicáveis.
- Priorize e selecione o padrão de arquitetura ideal. Alinhe o padrão de arquitetura com as tarefas e os resultados mais importantes.
- Configure os componentes arquitetônicos e implante o aplicativo Looker. Implemente o host, as dependências de terceiros e a topologia de rede necessários para estabelecer conexões seguras de clientes.
Opções de arquitetura
Máquina virtual dedicada
Uma opção é executar o Looker como uma única instância em uma máquina virtual (VM) dedicada. Uma única instância pode atender a cargas de trabalho exigentes ao escalonar verticalmente o host e aumentar os pools de linhas de execução padrão. No entanto, a sobrecarga de processamento de gerenciar um heap Java grande sujeita o escalonamento vertical à lei dos retornos decrescentes. Geralmente, é aceitável para cargas de trabalho pequenas e médias. O diagrama a seguir mostra as configurações padrão e opcionais entre uma instância do Looker em execução em uma VM dedicada, os repositórios locais e remotos, os servidores SMTP e as fontes de dados destacadas nas seções Vantagens e Práticas recomendadas para essa opção.
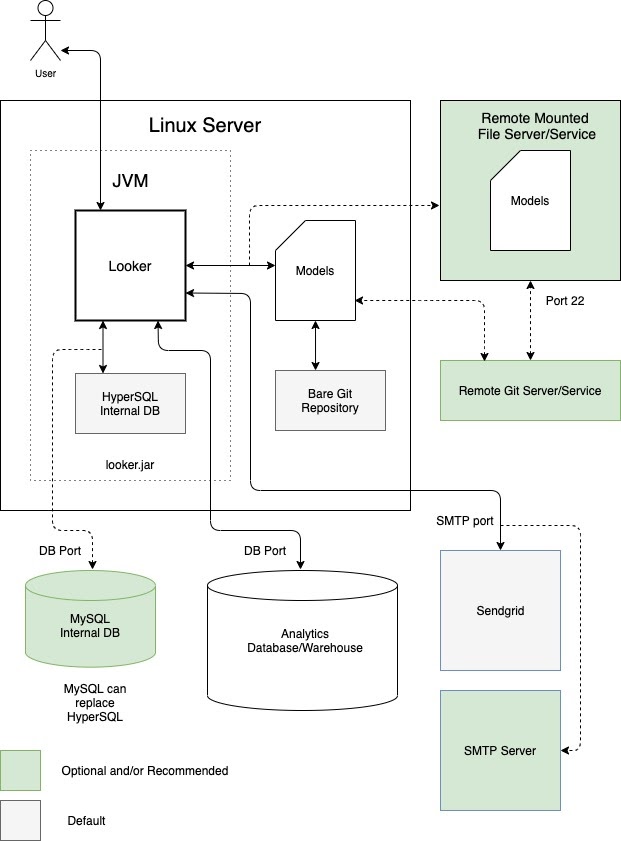
Vantagens
- É fácil implantar e manter uma VM dedicada.
- O banco de dados interno é hospedado no aplicativo Looker.
- Os modelos do Looker, o repositório Git, o servidor SMTP e os componentes do banco de dados de back-end podem ser configurados local ou remotamente.
- Você pode substituir o servidor SMTP padrão do Looker pelo seu para notificações por e-mail e tarefas programadas.
Práticas recomendadas
- Por padrão, o Looker pode gerar repositórios Git simples para um projeto. Recomendamos configurar um repositório Git remoto para redundância.
-
Por padrão, o Looker começa com um banco de dados HyperSQL na memória. Esse banco de dados é conveniente e leve, mas pode ter problemas de desempenho com uso intenso. Recomendamos o uso de um banco de dados MySQL para implantações maiores. Recomendamos a migração para um banco de dados MySQL remoto quando o arquivo
~/looker/.db/looker.scriptatingir 600 MB. - Sua implantação do Looker precisará ser validada pelo serviço de licenciamento do Looker. O tráfego de saída na porta 443 é obrigatório.
- Uma implantação de VM dedicada pode ser escalonada verticalmente aumentando os recursos disponíveis e os pools de linhas de execução do Looker. No entanto, aumentar a RAM está sujeito à lei de retornos decrescentes quando ela atinge 64 GB, já que os eventos de coleta de lixo são de uma única linha de execução e interrompem todas as outras para serem executados. Os nós com 16 CPUs e 64 GB de RAM oferecem um bom equilíbrio entre preço e desempenho.
- Recomendamos que sua implantação tenha armazenamento com duas operações por segundo (IOPS) por GB.
Cluster de VMs
Executar o Looker como um cluster de instâncias em várias VMs é um padrão flexível que se beneficia do failover e da redundância de serviços. A escalonabilidade horizontal aumenta a capacidade de processamento sem causar estouro de heap e custos excessivos de coleta de lixo. Os nós têm a opção de dedicação de carga de trabalho, o que permite adaptar várias opções de implantação a diferentes requisitos de negócios. As implantações de cluster exigem pelo menos um administrador de sistema com experiência em sistemas Linux e capacidade de gerenciar as partes componentes.
Cluster padrão
Para a maioria das implantações padrão, um cluster de nós de serviço idênticos é suficiente. Todos os nós do cluster são configurados da mesma forma e estão no mesmo pool de balanceadores de carga. Nenhum dos nós nessa configuração teria mais ou menos probabilidade de atender a solicitações de usuários do Looker, uma tarefa de renderização, uma tarefa programada, uma solicitação de API etc.
Esse tipo de configuração é adequado quando a maioria das solicitações vem diretamente de um usuário do Looker que está executando consultas e interagindo com o Looker. Ele começa a falhar quando um grande número de solicitações vem de um programador, um renderizador ou outra origem. Nesse caso, é benéfico designar determinados nós de serviço para lidar com tarefas como programação e renderização.
Por exemplo, os usuários costumam programar a execução das entregas de dados na manhã de segunda-feira. Um usuário que tenta executar consultas do Looker na manhã de segunda-feira pode ter problemas de desempenho enquanto o Looker trabalha no backlog de solicitações programadas. Ao aumentar o número de nós de serviço, o cluster oferece um aumento proporcional na capacidade de processamento em todos os recursos do Looker.
O diagrama a seguir mostra como as solicitações ao Looker feitas pelo usuário, apps e scripts são equilibradas em uma instância do Looker em cluster.
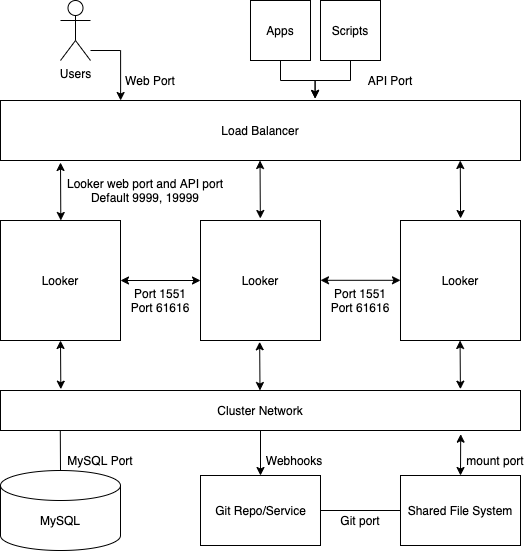
Vantagens
- Um cluster padrão maximiza o throughput geral com configuração mínima da topologia do cluster.
- A VM Java sofre degradação de performance no limite de memória alocada de 64 GB. Por isso, o escalonamento horizontal tem retornos maiores do que o vertical.
- Uma configuração de cluster garante redundância e failover de serviço.
Práticas recomendadas
- Cada nó do Looker precisa ser hospedado em uma VM dedicada.
- O balanceador de carga, que é o ponto de entrada do cluster, precisa ser um balanceador de carga da camada 4. Ele precisa ter um tempo limite longo (3.600 segundos), estar equipado com um certificado SSL assinado e ser configurado para encaminhar da porta 443 (https) para 9999 (porta em que o servidor do Looker detecta).
- Recomendamos que sua implantação tenha armazenamento com 2 IOPS por GB.
Dev/Staging/Prod
Para casos de uso que priorizam o tempo máximo de atividade do conteúdo para os usuários finais, recomendamos ambientes separados do Looker para compartimentar o trabalho de desenvolvimento e de análise. Ao restringir as mudanças no ambiente de produção por trás de ambientes isolados de desenvolvimento e teste, essa arquitetura mantém um ambiente de produção o mais estável possível.
Esses benefícios exigem a configuração dos ambientes interconectados e a adoção de um ciclo de lançamento robusto. Uma implantação de desenvolvimento/teste/produção também exige uma equipe de desenvolvedores familiarizados com a API do Looker e o Git para administração de fluxo de trabalho.
O diagrama a seguir mostra o fluxo de conteúdo entre desenvolvedores de LookML que criam conteúdo na instância de desenvolvimento, testadores de controle de qualidade que testam o conteúdo na instância de controle de qualidade e usuários, apps e scripts que consomem o conteúdo na instância de Production.
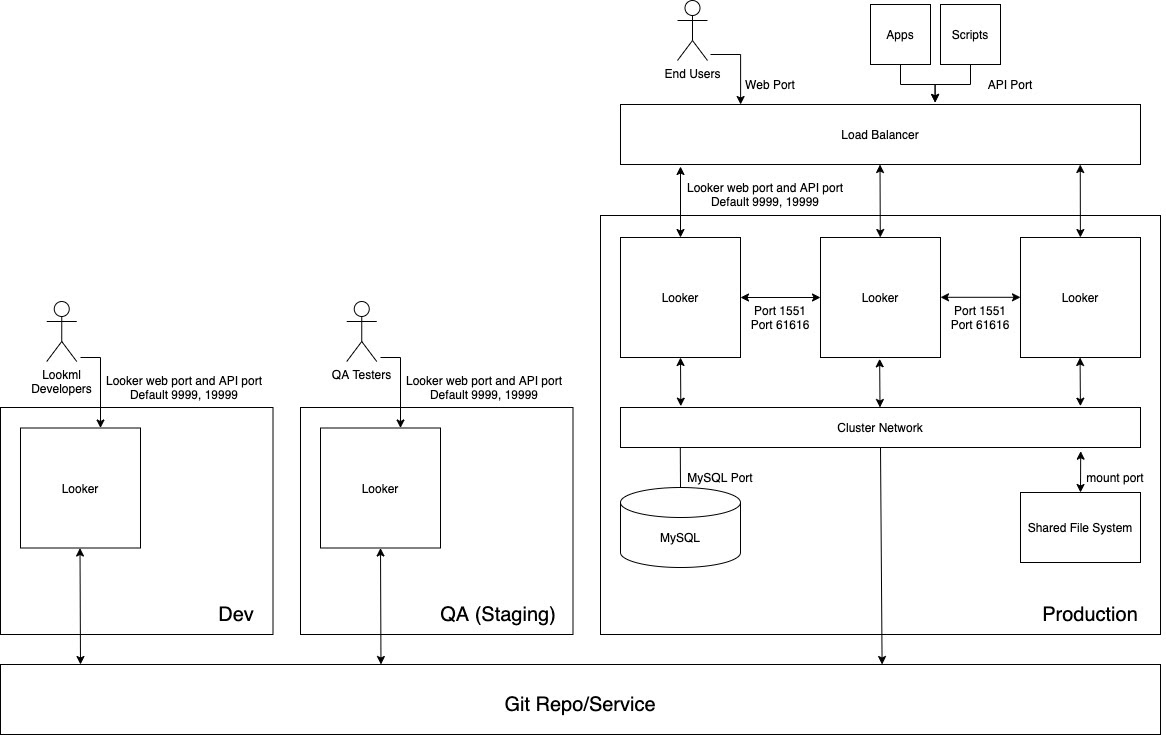
Vantagens
- A validação de conteúdo e LookML ocorre em um ambiente de não produção, garantindo que todas as modificações na lógica do modelo possam ser totalmente verificadas antes de chegar aos usuários de produção.
- Recursos em toda a instância, como recursos do Labs ou protocolos de autenticação, podem ser testados isoladamente antes de serem ativados no ambiente de produção.
- É possível testar políticas de grupo de dados e de cache em um ambiente que não seja de produção.
- O teste do modo de produção do Looker é independente dos ambientes de produção responsáveis por atender os usuários finais.
- As versões do Looker podem ser testadas em um ambiente de não produção, tempo suficiente para testar novos recursos, mudanças no fluxo de trabalho e problemas antes de atualizar o ambiente de produção.
Práticas recomendadas
- Isole as várias atividades que ocorrem simultaneamente em pelo menos três instâncias separadas:
- Instância de desenvolvimento: os desenvolvedores usam o ambiente de desenvolvimento para confirmar código, realizar experimentos, corrigir bugs e cometer erros com segurança.
- Instância de controle de qualidade: também chamada de ambiente de teste ou preparo, é onde os desenvolvedores executam testes manuais e automatizados. O ambiente de QA é complexo e pode consumir muitos recursos.
- Instância Production: é onde o valor é criado para os clientes e/ou a empresa. Production é um ambiente de alta visibilidade e precisa estar livre de erros.
- Mantenha um fluxo de trabalho de ciclo de lançamento documentado e repetível.
- Se for necessário atender a grandes volumes de desenvolvedores e testadores de QA, as instâncias de desenvolvimento e/ou QA poderão ser agrupadas. Sejam deixadas como uma VM independente ou um cluster de VMs, as instâncias de desenvolvimento e QA estão sujeitas às mesmas considerações arquitetônicas mostradas anteriormente nas respectivas seções.
Alta capacidade de processamento de programação
Para casos de uso que exigem alta capacidade de entrega de dados programada e entregas confiáveis e pontuais, recomendamos que a configuração inclua um cluster com um pool de nós dedicados exclusivamente ao agendamento. Essa configuração ajuda a manter os aplicativos da Web e incorporados rápidos e responsivos. Para aproveitar esses benefícios, é necessário configurar nós com opções de inicialização personalizadas e regras de balanceamento de carga adequadas, conforme mostrado no diagrama a seguir e descrito nas seções Vantagens e Práticas recomendadas dessa opção.
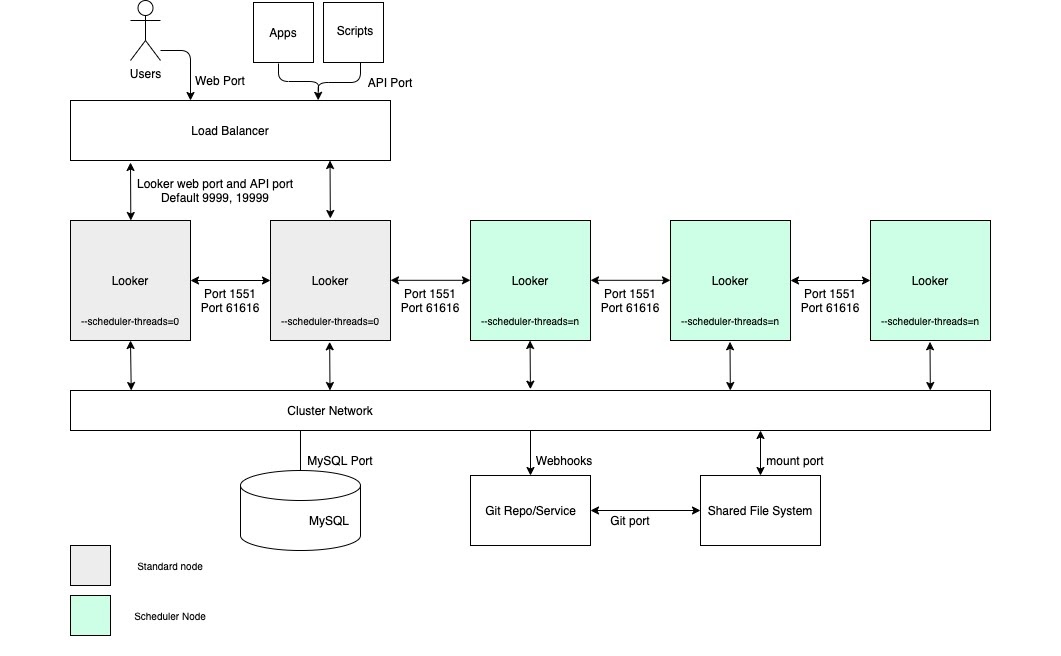
Vantagens
- A dedicação de nós a uma função específica compartimenta recursos para programação de funções de desenvolvimento e de análise ad hoc.
- Os usuários podem desenvolver LookML e explorar conteúdo sem usar ciclos de nós responsáveis por atender às entregas de dados programadas.
- O alto tráfego de usuários direcionado aos nós regulares não impede as cargas de trabalho programadas atendidas pelos nós de programação.
Práticas recomendadas
- Cada nó do Looker precisa ser hospedado em uma VM dedicada.
- O balanceador de carga, que é o ponto de entrada do cluster, precisa ser um balanceador de carga da camada 4. Ele precisa ter um tempo limite longo (3.600 segundos), estar equipado com um certificado SSL assinado e ser configurado para encaminhar da porta 443 (https) para 9999 (porta em que o servidor do Looker detecta).
- Omita os nós do programador das regras de balanceamento de carga para que eles não atendam ao tráfego do usuário final e às solicitações de API internas.
- Recomendamos que sua implantação tenha armazenamento com 2 IOPS por GB.
Alta capacidade de renderização
Para casos de uso que exigem alta taxa de transferência de relatórios de renderização, recomendamos configurar um cluster com um pool de nós dedicados exclusivamente à renderização. Renderizar um arquivo PDF ou uma imagem PNG/JPEG é uma operação relativamente cara em termos de recursos no Looker. A renderização pode exigir muita memória e CPU, e quando o Linux está sob pressão de memória, ele pode encerrar um processo em execução. Como o uso de memória de um job de renderização não pode ser determinado com antecedência, iniciar um job de renderização pode resultar no encerramento do processo do Looker. A configuração de nós de renderização dedicados permite o ajuste ideal dos jobs de renderização, preservando a capacidade de resposta do aplicativo interativo e incorporado.
Para aproveitar esses benefícios, é necessário configurar nós com opções de inicialização personalizadas e regras de balanceamento de carga adequadas, conforme mostrado no diagrama a seguir e explicado nas seções Vantagens e Práticas recomendadas para essa opção. Além disso, os nós de renderização podem exigir mais recursos de host do que os nós padrão, já que o serviço de renderização do Looker depende de processos do Chromium de terceiros que compartilham tempo de CPU e memória.
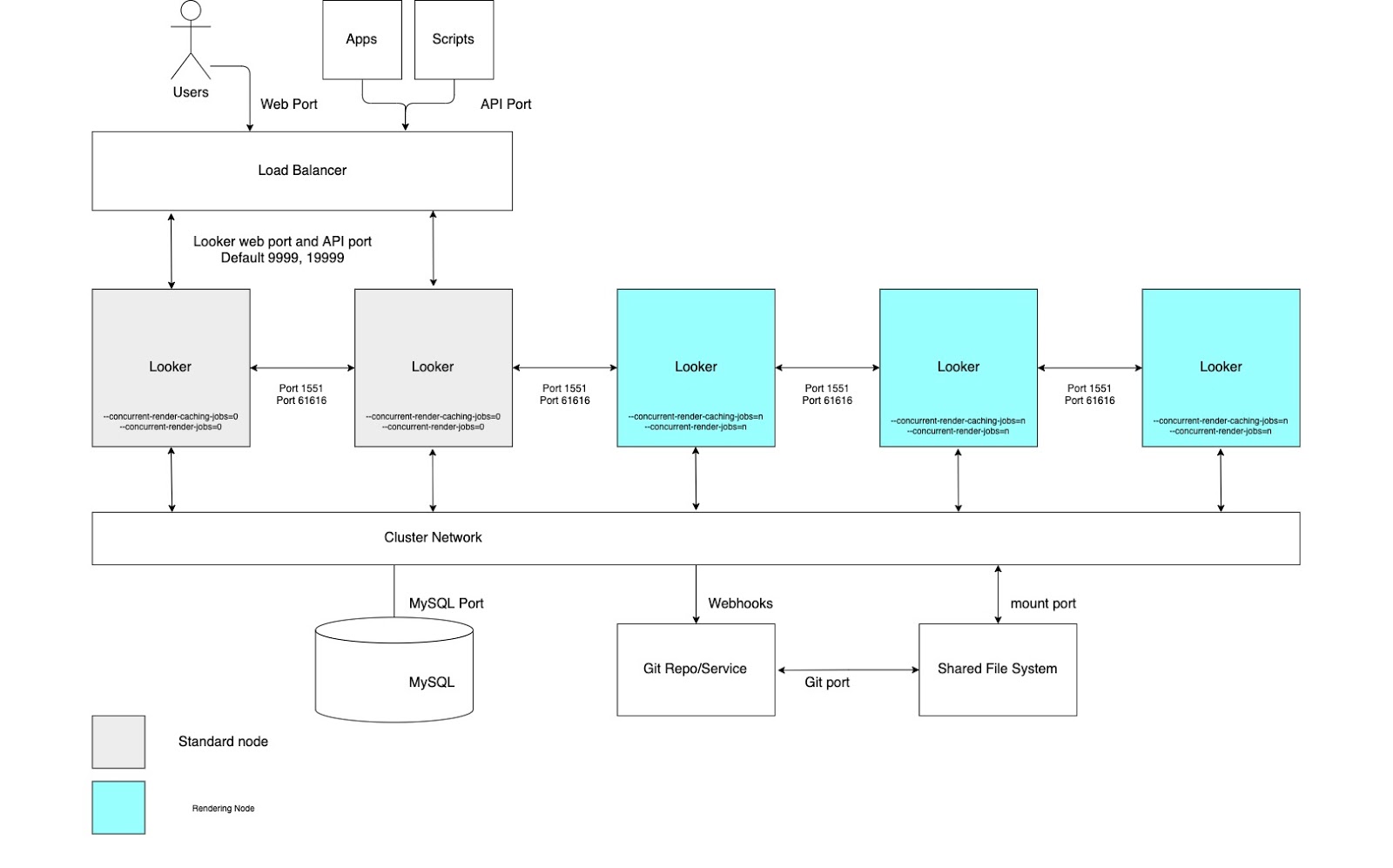
Vantagens
- A dedicação de nós a uma função específica compartimentaliza os recursos para renderização de funções de desenvolvimento e de análise ad hoc.
- Os usuários podem desenvolver LookML e analisar conteúdo sem usar ciclos dos nós responsáveis por renderizar PNGs e PDFs.
- O alto tráfego de usuários direcionado aos nós regulares não impede as cargas de trabalho de renderização atendidas pelos nós de renderização.
Práticas recomendadas
- Cada nó do Looker precisa ser hospedado em uma VM dedicada.
- O balanceador de carga, que é o ponto de entrada do cluster, precisa ser um balanceador de carga da camada 4. Ele precisa ter um tempo limite longo (3.600 segundos), estar equipado com um certificado SSL assinado e ser configurado para encaminhar da porta 443 (https) para 9999 (porta em que o servidor do Looker detecta).
- Omita a renderização de nós das regras de balanceamento de carga para que eles não atendam ao tráfego do usuário final e às solicitações internas de API.
- Alocar relativamente menos memória para o Java nos nós de renderização para dar aos processos do Chromium um buffer de memória maior. Em vez de alocar 60% da memória para Java, aloque de 40 a 50%.
- O risco de pressão de memória foi reduzido nos nós não renderizados, então a quantidade de memória dedicada ao Looker pode ser aumentada. Em vez dos 60% padrão, considere um número maior, como 80%.
- Recomendamos que sua implantação tenha armazenamento com 2 IOPS por GB.