Weitere Informationen finden Sie auf der Dokumentationsseite Aggregate awareness.
Einführung
Auf dieser Seite finden Sie eine Anleitung zur Implementierung von Aggregatbewusstsein in einem praktischen Szenario. Dazu gehören die Identifizierung von Implementierungsmöglichkeiten, der Wert von Aggregatbewusstsein und ein einfacher Workflow für die Implementierung in einem realen Modell. Auf dieser Seite werden nicht alle Funktionen für die Steigerung der Markenbekanntheit oder Grenzfälle ausführlich erläutert. Sie ist auch kein vollständiger Katalog aller Funktionen.
Was ist die aggregierte Bekanntheit?
In Looker führen Sie Abfragen hauptsächlich für Rohdatentabellen oder Ansichten in Ihrer Datenbank aus. Manchmal handelt es sich dabei um persistente abgeleitete Tabellen (PDTs) in Looker.
Häufig werden sehr große Datasets oder Tabellen verwendet, für die zur Leistungssteigerung Aggregationstabellen oder Roll-ups erforderlich sind.
In der Regel erstellen Sie Aggregationstabellen wie eine orders_daily-Tabelle mit eingeschränkter Dimensionalität. Sie müssen separat behandelt und im Explore-Bereich separat modelliert werden. Sie passen nicht gut in das Modell. Diese Einschränkungen führen zu einer schlechten Nutzererfahrung, wenn der Nutzer für dieselben Daten zwischen mehreren Explores wählen muss.
Mit der Funktion „Aggregate Awareness“ von Looker können Sie jetzt aggregierte Tabellen mit verschiedenen Granularitäts-, Dimensionalitäts- und Aggregationsstufen erstellen und Looker mitteilen, wie sie in vorhandenen Explores verwendet werden sollen. Abfragen nutzen dann diese zusammengefassten Tabellen, wenn Looker dies für angemessen hält, ohne dass Nutzereingaben erforderlich sind. Dadurch wird die Abfragegröße verringert, die Wartezeiten werden verkürzt und die Nutzerfreundlichkeit wird verbessert.
HINWEIS:Die aggregierten Tabellen von Looker sind eine Art persistente abgeleitete Tabelle (PAT). Das bedeutet, dass für Aggregattabellen dieselben Datenbank- und Verbindungsanforderungen gelten wie für PDTs.Ob Ihr Datenbankdialekt und Ihre Looker-Verbindung PDTs unterstützen, erfahren Sie in den Anforderungen auf der Dokumentationsseite Abgeleitete Tabellen in Looker.
Ob Ihr Datenbankdialekt die Funktion „Aggregate awareness“ unterstützt, erfahren Sie auf der Dokumentationsseite Aggregate awareness.
Der Wert von aggregierter Bekanntheit
Es gibt eine Reihe wichtiger Vorteile, die mit der Zusammenfassung von Awareness-Angeboten einhergehen und mit denen Sie zusätzlichen Nutzen aus Ihrem bestehenden Looker-Modell ziehen können:
- Leistungssteigerung:Durch die Implementierung der Aggregatfunktion werden Nutzeranfragen schneller beantwortet. Looker verwendet eine kleinere Tabelle, wenn sie die Daten enthält, die zum Ausführen der Nutzeranfrage erforderlich sind.
- Kosteneinsparungen:Bei bestimmten Dialekten wird die Größe der Abfrage nach einem Verbrauchsmodell berechnet. Wenn Looker kleinere Tabellen abfragt, sinken die Kosten pro Nutzerabfrage.
- Verbesserung der Nutzerfreundlichkeit:Durch die Konsolidierung werden nicht nur Antworten schneller abgerufen, sondern auch redundante Explore-Vorgänge vermieden.
- Geringerer LookML-Aufwand:Wenn Sie vorhandene, auf Liquid basierende Strategien für die Zusammenfassung von Daten durch eine flexible, native Implementierung ersetzen, erhöht sich die Robustheit und es treten weniger Fehler auf.
- Vorhandenes LookML nutzen:Für aggregierte Tabellen wird das
query-Objekt verwendet, in dem vorhandene modellierte Logik wiederverwendet wird, anstatt Logik mit explizitem benutzerdefiniertem SQL zu duplizieren.
Einfaches Beispiel
Hier sehen Sie eine sehr einfache Implementierung in einem Looker-Modell, um zu veranschaulichen, wie einfach die Aggregat-Awareness sein kann. Angenommen, es gibt eine hypothetische Tabelle flights in der Datenbank mit einer Zeile für jeden von der FAA aufgezeichneten Flug. Wir können diese Tabelle in Looker mit einer eigenen Ansicht und einem eigenen Explore modellieren. Hier ist die LookML für eine aggregierte Tabelle, die wir für den Explore definieren können:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
Mit dieser aggregierten Tabelle kann ein Nutzer das Explore flights abfragen. Looker verwendet dann automatisch die in der LookML definierte aggregierte Tabelle, um die Abfragen zu beantworten. Der Nutzer muss Looker nicht über besondere Bedingungen informieren: Wenn die Tabelle für die vom Nutzer ausgewählten Felder geeignet ist, wird sie von Looker verwendet.
Nutzer mit der Berechtigung see_sql können auf dem Tab SQL eines Explores in den Kommentaren sehen, welche aggregierte Tabelle für eine Abfrage verwendet wird. Hier sehen Sie ein Beispiel für den Looker-Tab SQL für eine Abfrage, in der die Aggregationstabelle flights:flights_by_week_and_carrier in teach_scratch verwendet wird:
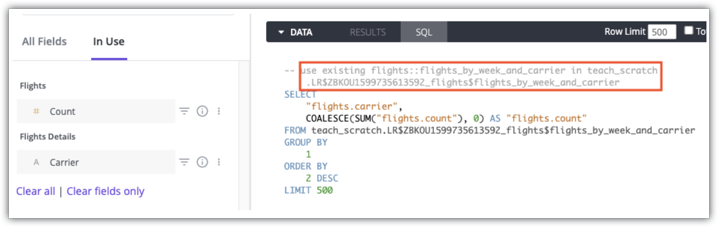
Weitere Informationen dazu, ob Aggregattabellen für eine Abfrage verwendet werden, finden Sie auf der Dokumentationsseite Aggregate awareness.
Chancen erkennen
Um die Vorteile der aggregierten Bekanntheit zu maximieren, sollten Sie herausfinden, wo sie bei der Optimierung oder bei der Steigerung des Werts der aggregierten Bekanntheit eine Rolle spielen kann.
Dashboards mit langer Laufzeit identifizieren
Eine gute Möglichkeit, das Bewusstsein für Aggregate zu schärfen, besteht darin, Aggregattabellen für stark genutzte Dashboards mit sehr langer Laufzeit zu erstellen. Möglicherweise werden Sie von Ihren Nutzern auf langsame Dashboards aufmerksam gemacht. Wenn Sie jedoch see_system_activity haben, können Sie auch das System Activity History Explore von Looker verwenden, um Dashboards mit einer langsameren als der durchschnittlichen Laufzeit zu finden. Als Abkürzung können Sie die folgende URL in einem Browser verwenden und HOSTNAME durch den Namen Ihrer Looker-Instanz ersetzen (z. B. example.cloud.looker.com).
https://HOSTNAME/explore/system__activity/history?fields=dashboard.title,dashboard.link,history.count,history.average_runtime,history.cache_result_query_count,history.database_result_query_count,query.count_of_explores&f[history.created_date]=30+days&f[dashboard.title]=-NULL%2C-Limejump+Dashboard&sorts=history.count+desc&limit=500&query_timezone=America%2FLos_Angeles&vis=%7B%22show_view_names%22%3Afalse%2C%22show_row_numbers%22%3Atrue%2C%22transpose%22%3Afalse%2C%22truncate_text%22%3Atrue%2C%22hide_totals%22%3Afalse%2C%22hide_row_totals%22%3Afalse%2C%22size_to_fit%22%3Atrue%2C%22table_theme%22%3A%22gray%22%2C%22limit_displayed_rows%22%3Afalse%2C%22enable_conditional_formatting%22%3Atrue%2C%22header_text_alignment%22%3A%22left%22%2C%22header_font_size%22%3A%2212%22%2C%22rows_font_size%22%3A%2212%22%2C%22conditional_formatting_include_totals%22%3Afalse%2C%22conditional_formatting_include_nulls%22%3Afalse%2C%22show_sql_query_menu_options%22%3Afalse%2C%22show_totals%22%3Atrue%2C%22show_row_totals%22%3Atrue%2C%22series_column_widths%22%3A%7B%22dashboard.link%22%3A80%2C%22history.average_runtime%22%3A94%2C%22history.count%22%3A96%7D%2C%22series_cell_visualizations%22%3A%7B%22history.count%22%3A%7B%22is_active%22%3Afalse%7D%7D%2C%22conditional_formatting%22%3A%5B%7B%22type%22%3A%22along+a+scale...%22%2C%22value%22%3Anull%2C%22background_color%22%3A%22%232196F3%22%2C%22font_color%22%3Anull%2C%22color_application%22%3A%7B%22collection_id%22%3A%22bdo%22%2C%22palette_id%22%3A%22bdo-diverging-0%22%2C%22options%22%3A%7B%22steps%22%3A5%2C%22constraints%22%3A%7B%22min%22%3A%7B%22type%22%3A%22minimum%22%7D%2C%22mid%22%3A%7B%22type%22%3A%22number%22%2C%22value%22%3A0%7D%2C%22max%22%3A%7B%22type%22%3A%22maximum%22%7D%7D%2C%22mirror%22%3Atrue%2C%22reverse%22%3Atrue%2C%22stepped%22%3Afalse%7D%7D%2C%22bold%22%3Afalse%2C%22italic%22%3Afalse%2C%22strikethrough%22%3Afalse%2C%22fields%22%3A%5B%22history.average_runtime%22%5D%7D%5D%2C%22type%22%3A%22looker_grid%22%2C%22series_types%22%3A%7B%7D%2C%22defaults_version%22%3A1%2C%22hidden_fields%22%3A%5B%22history.cache_result_query_count%22%2C%22history.database_result_query_count%22%2C%22dashboard.link%22%5D%7D&filter_config=%7B%22history.created_date%22%3A%5B%7B%22type%22%3A%22past%22%2C%22values%22%3A%5B%7B%22constant%22%3A%2230%22%2C%22unit%22%3A%22day%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22dashboard.title%22%3A%5B%7B%22type%22%3A%22%21null%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22%22%7D%2C%7B%7D%5D%2C%22id%22%3A2%2C%22error%22%3Afalse%7D%2C%7B%22type%22%3A%22%21%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22Limejump+Dashboard%22%7D%2C%7B%7D%5D%2C%22id%22%3A3%2C%22error%22%3Afalse%7D%5D%7D&dynamic_fields=%5B%7B%22table_calculation%22%3A%22ratio_from_cache_vs_database%22%2C%22label%22%3A%22Ratio+from+Cache+vs+Database%22%2C%22expression%22%3A%22%24%7Bhistory.cache_result_query_count%7D%2F%24%7Bhistory.database_result_query_count%7D%22%2C%22value_format%22%3Anull%2C%22value_format_name%22%3A%22decimal_2%22%2C%22_kind_hint%22%3A%22measure%22%2C%22_type_hint%22%3A%22number%22%7D%2C%7B%22table_calculation%22%3A%22is_performing_worse_than_mean%22%2C%22label%22%3A%22Is+Performing+Worse+Than+Mean%22%2C%22expression%22%3A%22%24%7Bhistory.average_runtime%7D%3Emean%28%24%7Bhistory.average_runtime%7D%29%22%2C%22value_format%22%3Anull%2C%22value_format_name%22%3Anull%2C%22_kind_hint%22%3A%22measure%22%2C%22_type_hint%22%3A%22yesno%22%7D%5D&origin=share-expanded" rel="undefined">this System Activity History Explore link
Es wird eine explorative Datenanalyse mit Daten zu den Dashboards Ihrer Instanz angezeigt, darunter Titel, Verlauf, Anzahl der explorativen Datenanalysen, Verhältnis von Cache zu Datenbank und Leistung schlechter als Durchschnitt:

In diesem Beispiel gibt es eine Reihe von Dashboards mit hoher Auslastung, die schlechter als der Durchschnitt abschneiden, z. B. das Dashboard Beispielvisualisierungen. Im Dashboard Sample Visualizations werden zwei Explores verwendet. Daher wäre es eine gute Strategie, Aggregationstabellen für beide Explores zu erstellen.
Langsame und von Nutzern häufig abgefragte Explores ermitteln
Eine weitere Möglichkeit, die aggregierte Bekanntheit zu steigern, sind Explores, die häufig von Nutzern abgefragt werden und eine unterdurchschnittliche Antwort auf Anfragen aufweisen.
Sie können das System Activity History Explore als Ausgangspunkt verwenden, um Möglichkeiten zur Optimierung von Explores zu ermitteln. Als Abkürzung können Sie die folgende URL in einem Browser verwenden und HOSTNAME durch den Namen Ihrer Looker-Instanz ersetzen (z. B. example.cloud.looker.com).
https://HOSTNAME/explore/system__activity/history?fields=query.view,history.query_run_count,user.count,query.model,history.average_runtime&f[history.created_date]=30+days&f[history.source]=Explore&sorts=history.query_run_count+desc&limit=15&query_timezone=America%2FLos_Angeles&vis=%7B%22show_view_names%22%3Afalse%2C%22show_row_numbers%22%3Atrue%2C%22transpose%22%3Afalse%2C%22truncate_text%22%3Atrue%2C%22hide_totals%22%3Afalse%2C%22hide_row_totals%22%3Afalse%2C%22size_to_fit%22%3Atrue%2C%22table_theme%22%3A%22white%22%2C%22limit_displayed_rows%22%3Afalse%2C%22enable_conditional_formatting%22%3Atrue%2C%22header_text_alignment%22%3A%22left%22%2C%22header_font_size%22%3A%2212%22%2C%22rows_font_size%22%3A%2212%22%2C%22conditional_formatting_include_totals%22%3Afalse%2C%22conditional_formatting_include_nulls%22%3Afalse%2C%22show_sql_query_menu_options%22%3Afalse%2C%22show_totals%22%3Atrue%2C%22show_row_totals%22%3Atrue%2C%22series_labels%22%3A%7B%22user.count%22%3A%22User+Count%22%7D%2C%22series_column_widths%22%3A%7B%22query.model%22%3A179%2C%22query.view%22%3A128%7D%2C%22series_cell_visualizations%22%3A%7B%22history.query_run_count%22%3A%7B%22is_active%22%3Atrue%2C%22__FILE%22%3A%22system__activity%2Fcontent_activity.dashboard.lookml%22%2C%22__LINE_NUM%22%3A106%7D%2C%22user.count%22%3A%7B%22is_active%22%3Atrue%2C%22__FILE%22%3A%22system__activity%2Fcontent_activity.dashboard.lookml%22%2C%22__LINE_NUM%22%3A108%7D%7D%2C%22conditional_formatting%22%3A%5B%7B%22type%22%3A%22along+a+scale...%22%2C%22value%22%3Anull%2C%22background_color%22%3A%22%233EB0D5%22%2C%22font_color%22%3Anull%2C%22color_application%22%3A%7B%22collection_id%22%3A%22bdo%22%2C%22palette_id%22%3A%22bdo-diverging-0%22%2C%22options%22%3A%7B%22steps%22%3A5%2C%22reverse%22%3Atrue%7D%7D%2C%22bold%22%3Afalse%2C%22italic%22%3Afalse%2C%22strikethrough%22%3Afalse%2C%22fields%22%3A%5B%22history.average_runtime%22%5D%7D%5D%2C%22type%22%3A%22looker_grid%22%2C%22truncate_column_names%22%3Afalse%2C%22series_types%22%3A%7B%7D%2C%22defaults_version%22%3A1%7D&filter_config=%7B%22history.created_date%22%3A%5B%7B%22type%22%3A%22past%22%2C%22values%22%3A%5B%7B%22constant%22%3A%2230%22%2C%22unit%22%3A%22day%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22history.source%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22Explore%22%7D%2C%7B%7D%5D%2C%22id%22%3A1%2C%22error%22%3Afalse%7D%5D%7D&origin=share-expanded
Sie sehen eine Explore-Visualisierung mit Daten zu den Explores Ihrer Instanz, einschließlich Explore, Modell, Anzahl der ausgeführten Abfragen, Anzahl der Nutzer und Durchschnittliche Laufzeit in Sekunden:

Im Explore „Verlauf“ können Sie die folgenden Arten von Explores in Ihrer Instanz identifizieren:
- Explores, die von Nutzern abgefragt werden (im Gegensatz zu Abfragen über die API oder Abfragen aus geplanten Zustellungen)
- Häufig abgefragte Explores
- Explores mit schlechter Leistung (im Vergleich zu anderen Explores)
Im vorherigen Beispiel für „System Activity History“ sind die Explores flights und order_items wahrscheinliche Kandidaten für die Implementierung von Aggregate Awareness.
Häufig in Abfragen verwendete Felder identifizieren
Schließlich können Sie weitere Optimierungsmöglichkeiten auf Datenebene ermitteln, indem Sie sich ansehen, welche Felder Nutzer häufig in Abfragen und Filtern verwenden.
Als Abkürzung können Sie die folgende URL in einem Browser verwenden und HOSTNAME durch den Namen Ihrer Looker-Instanz ersetzen (z. B. example.cloud.looker.com).
https://HOSTNAME/explore/system__activity/field_usage?fields=field_usage.model,field_usage.explore,field_usage.field,field_usage.times_used&f[field_usage.model]=faa%2C%22advanced_data_analyst_bootcamp%22&f[field_usage.explore]=flights%2C%22order_items%22&sorts=field_usage.times_used+desc&limit=500&query_timezone=America%2FNew_York&vis=%7B%22x_axis_gridlines%22%3Afalse%2C%22y_axis_gridlines%22%3Atrue%2C%22show_view_names%22%3Afalse%2C%22show_y_axis_labels%22%3Atrue%2C%22show_y_axis_ticks%22%3Atrue%2C%22y_axis_tick_density%22%3A%22default%22%2C%22y_axis_tick_density_custom%22%3A5%2C%22show_x_axis_label%22%3Atrue%2C%22show_x_axis_ticks%22%3Atrue%2C%22y_axis_scale_mode%22%3A%22linear%22%2C%22x_axis_reversed%22%3Afalse%2C%22y_axis_reversed%22%3Afalse%2C%22plot_size_by_field%22%3Afalse%2C%22trellis%22%3A%22%22%2C%22stacking%22%3A%22%22%2C%22limit_displayed_rows%22%3Atrue%2C%22legend_position%22%3A%22center%22%2C%22point_style%22%3A%22none%22%2C%22show_value_labels%22%3Afalse%2C%22label_density%22%3A25%2C%22x_axis_scale%22%3A%22auto%22%2C%22y_axis_combined%22%3Atrue%2C%22ordering%22%3A%22none%22%2C%22show_null_labels%22%3Afalse%2C%22show_totals_labels%22%3Afalse%2C%22show_silhouette%22%3Afalse%2C%22totals_color%22%3A%22%23808080%22%2C%22limit_displayed_rows_values%22%3A%7B%22show_hide%22%3A%22show%22%2C%22first_last%22%3A%22first%22%2C%22num_rows%22%3A%2215%22%7D%2C%22series_types%22%3A%7B%7D%2C%22type%22%3A%22looker_bar%22%2C%22defaults_version%22%3A1%7D&filter_config=%7B%22field_usage.model%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22faa%2Cadvanced_data_analyst_bootcamp%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22field_usage.explore%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22flights%2Corder_items%22%7D%2C%7B%7D%5D%2C%22id%22%3A1%2C%22error%22%3Afalse%7D%5D%7D&origin=share-expanded
Ersetzen Sie die Filter entsprechend. Sie sehen nun eine explorative Datenanalyse mit einem Balkendiagramm, in dem die Anzahl der Verwendungen eines Felds in einer Abfrage angegeben ist:
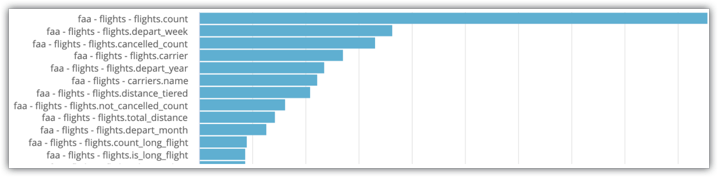
Im Beispiel „System Activity Explore“ im Bild sehen Sie, dass flights.count und flights.depart_week die beiden am häufigsten ausgewählten Felder für den Explore sind. Daher eignen sich diese Felder gut für die Aufnahme in Aggregattabellen.
Konkrete Daten wie diese sind hilfreich, aber es gibt auch subjektive Elemente, die Ihre Auswahlkriterien beeinflussen. Wenn Sie sich beispielsweise die vier vorherigen Felder ansehen, können Sie davon ausgehen, dass Nutzer sich häufig die Anzahl der geplanten Flüge und die Anzahl der Flüge ansehen, die storniert wurden, und dass sie diese Daten sowohl nach Woche als auch nach Fluggesellschaft aufschlüsseln möchten. Dies ist ein Beispiel für eine klare, logische und praxisnahe Kombination von Feldern und Messwerten.
Zusammenfassung
Die Schritte auf dieser Dokumentationsseite sollen als Leitfaden dienen, um Dashboards, Explores und Felder zu finden, die für die Optimierung infrage kommen. Es ist auch wichtig zu wissen, dass sich alle drei gegenseitig ausschließen können: Die problematischen Dashboards werden möglicherweise nicht von den problematischen Explores unterstützt und das Erstellen von Aggregattabellen mit den häufig verwendeten Feldern hilft diesen Dashboards möglicherweise überhaupt nicht. Möglicherweise handelt es sich um drei separate Implementierungen der Aggregatfunktion.
Zusammengefasste Tabellen entwerfen
Nachdem Sie Möglichkeiten für die Steigerung der Markenbekanntheit ermittelt haben, können Sie aggregierte Tabellen entwerfen, die diese Möglichkeiten am besten nutzen. Informationen zu den Feldern, Messwerten und Zeiträumen, die in aggregierten Tabellen unterstützt werden, sowie weitere Richtlinien für das Erstellen aggregierter Tabellen finden Sie auf der Dokumentationsseite Aggregate awareness.
HINWEIS:Aggregierte Tabellen müssen nicht genau mit Ihrer Abfrage übereinstimmen, damit sie verwendet werden können. Wenn Ihre Abfrage auf Wochenbasis erfolgt und Sie eine Tabelle mit täglichen aggregierten Daten haben, verwendet Looker Ihre aggregierte Tabelle anstelle der Rohdatentabelle auf Zeitstempel-Ebene. Wenn Sie beispielsweise eine aggregierte Tabelle haben, die auf der Ebenebrandunddatezusammengefasst ist, und ein Nutzer nur auf der Ebenebrandeine Abfrage ausführt, kann diese Tabelle trotzdem von Looker für die Aggregatberücksichtigung verwendet werden.
Die Aggregat-Awareness wird für die folgenden Messwerte unterstützt:
- Standardmesswerte : Messwerte vom Typ SUMME, ANZAHL, MITTELWERT, MIN und MAX
- Zusammengesetzte Messwerte : Messwerte vom Typ NUMBER, STRING, YESNO und DATE
- Ungefähre Anzahl unterschiedlicher Messwerte : Dialekte, die die HyperLogLog-Funktionalität verwenden können
Die aggregierte Awareness wird für die folgenden Messwerte nicht unterstützt:
- Unterschiedliche Messwerte:Da Unterscheidung nur für atomare, nicht aggregierte Daten berechnet werden kann, werden
*_DISTINCT-Messwerte außerhalb dieser Schätzungen, die HyperLogLog verwenden, nicht unterstützt. - Auf Kardinalität basierende Messwerte:Wie bei Messwerten für eindeutige Werte können Mediane und Perzentile nicht vorab aggregiert werden und werden nicht unterstützt.
HINWEIS:Wenn Sie eine potenzielle Nutzeranfrage mit Messwerttypen kennen, die von der aggregierten Sensibilisierung nicht unterstützt werden, sollten Sie in diesem Fall eine aggregierte Tabelle erstellen, die genau einer Abfrage entspricht. Eine Aggregattabelle, die genau der Abfrage entspricht, kann verwendet werden, um eine Abfrage mit Maßtypen zu beantworten, die andernfalls für die Aggregatberücksichtigung nicht unterstützt würden.
Detaillierungsgrad der zusammengefassten Tabelle
Bevor Sie Tabellen für Kombinationen aus Dimensionen und Messwerten erstellen, sollten Sie gängige Nutzungsmuster und Feldauswahlen ermitteln, um Aggregattabellen zu erstellen, die so oft wie möglich verwendet werden und die größte Wirkung haben. Alle Felder, die in der Abfrage verwendet werden (unabhängig davon, ob sie ausgewählt oder gefiltert werden), müssen in der aggregierten Tabelle enthalten sein, damit die Tabelle für die Abfrage verwendet werden kann. Wie bereits erwähnt, muss die aggregierte Tabelle jedoch nicht genau mit einer Abfrage übereinstimmen, damit sie für die Abfrage verwendet werden kann. Sie können viele potenzielle Nutzeranfragen in einer einzigen aggregierten Tabelle beantworten und trotzdem eine deutliche Leistungssteigerung erzielen.
Im Beispiel zum Ermitteln von Feldern, die häufig in Abfragen verwendet werden, gibt es zwei Dimensionen (flights.depart_week und flights.carrier), die sehr häufig ausgewählt werden, sowie zwei Messwerte (flights.count und flights.cancelled_count). Daher wäre es sinnvoll, eine aggregierte Tabelle zu erstellen, in der alle vier Felder verwendet werden. Außerdem führt das Erstellen einer einzelnen aggregierten Tabelle für flights_by_week_and_carrier zu einer häufigeren Verwendung aggregierter Tabellen als bei zwei verschiedenen aggregierten Tabellen für flights_by_week- und flights_by_carrier-Tabellen.
Hier ist ein Beispiel für eine aggregierte Tabelle, die wir für Anfragen zu den gemeinsamen Feldern erstellen könnten:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
Die Aussagen Ihrer geschäftlichen Nutzer, anekdotische Beweise und Daten aus der Systemaktivität von Looker können Ihnen bei der Entscheidungsfindung helfen.
Anwendbarkeit und Leistung in Einklang bringen
Im folgenden Beispiel sehen Sie eine Explore-Abfrage der Felder „Flights Depart Week“, „Flights Details Carrier“, „Flights Count“ und „Flights Detailed Cancelled Count“ aus der aggregierten Tabelle flights_by_week_and_carrier:
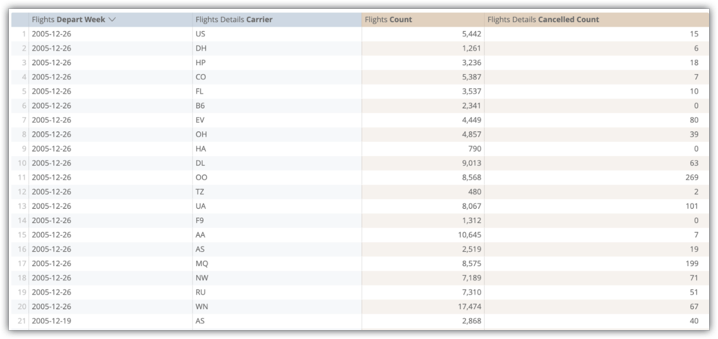
Die Ausführung dieser Abfrage in der ursprünglichen Datenbanktabelle dauerte 15,8 Sekunden und es wurden 38 Millionen Zeilen ohne Joins mit Amazon Redshift gescannt. Das Pivotieren der Abfrage, was ein normaler Nutzervorgang ist, dauerte 29,5 Sekunden.
Nach der Implementierung der aggregierten Tabelle flights_by_week_and_carrier dauerte die nachfolgende Abfrage 7, 2 Sekunden und es wurden 4.592 Zeilen gescannt. Das entspricht einer Reduzierung der Tabellengröße um 99,98 %. Das Pivotieren der Abfrage hat 9,8 Sekunden gedauert.
Im Explore „Systemaktivität – Feldnutzung“ können wir sehen, wie oft unsere Nutzer diese Felder in Abfragen verwenden. In diesem Beispiel wurde flights.count 47.848-mal, flights.depart_week 18.169-mal, flights.cancelled_count 16.570-mal und flights.carrier 13.517-mal verwendet.

Selbst wenn wir sehr bescheiden schätzen, dass bei 25% dieser Anfragen alle vier Felder auf einfachste Weise verwendet wurden (einfache Auswahl, kein Pivot), ergibt sich eine insgesamt eingesparte Wartezeit von 3.379 × 8,6 Sekunden = 8 Stunden und 4 Minuten.
HINWEIS:Das hier verwendete Beispielmodell ist sehr einfach. Diese Ergebnisse sollten nicht als Benchmark oder Referenzrahmen für Ihr Modell verwendet werden.
Wenn wir denselben Ablauf auf unser E-Commerce-Modell order_items – das am häufigsten verwendete Explore in der Instanz – anwenden, erhalten wir die folgenden Ergebnisse:
| Quelle | Abfragezeitpunkt | Gescannte Zeilen |
|---|---|---|
| Basistabelle | 13,1 Sekunden | 285.000 |
| Zusammengefasste Tabelle | 5,1 Sekunden | 138.000 |
| Delta | 8 Sekunden | 147.000 |
Die in der Abfrage und der nachfolgenden aggregierten Tabelle verwendeten Felder waren brand, created_date, orders_count und total_revenue. Dabei wurden zwei Joins verwendet. Die Felder wurden insgesamt 11.000 Mal verwendet. Bei derselben kombinierten Nutzung von etwa 25 % würde die aggregierte Einsparung für Nutzer 6 Stunden und 6 Minuten (8 Sekunden × 2.750 = 22.000 Sekunden) betragen. Das Erstellen der zusammengefassten Tabelle hat 17,9 Sekunden gedauert.
Wenn Sie sich diese Ergebnisse ansehen, sollten Sie einen Moment innehalten und die potenziellen Renditen bewerten, die sich aus Folgendem ergeben:
- Größere, komplexere Modelle/Explores optimieren, die eine „akzeptable“ Leistung haben und durch bessere Modellierungspraktiken eine Leistungssteigerung erfahren können
im Vergleich zu
- Aggregierte Bekanntheit nutzen, um einfachere Modelle zu optimieren, die häufiger verwendet werden und eine schlechte Leistung aufweisen
Wenn Sie versuchen, die letzten Leistungsreserven aus Looker und Ihrer Datenbank herauszuholen, werden Sie feststellen, dass sich Ihre Bemühungen immer weniger auszahlen. Sie sollten sich immer der Erwartungen an die Baseline-Leistung bewusst sein, insbesondere von geschäftlichen Nutzern, und die Einschränkungen Ihrer Datenbank (z. B. Parallelität, Abfrageschwellen, Kosten usw.) berücksichtigen. Sie sollten nicht davon ausgehen, dass diese Einschränkungen durch die aggregierte Bekanntheit aufgehoben werden.
Denken Sie auch daran, dass eine aggregierte Tabelle mit mehr Feldern größer und langsamer ist. Größere Tabellen können mehr Abfragen optimieren und daher in mehr Situationen verwendet werden. Sie sind jedoch nicht so schnell wie kleinere, einfachere Tabellen.
Beispiel:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week,flights.distance, flights.arrival_week,flights.cancelled]
measures: [cancelled_count, count, flights.average_distance, flights.total_distance]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}Die aggregierte Tabelle wird für jede Kombination der angezeigten Dimension und für jede der enthaltenen Messwerte verwendet. Sie kann also zur Beantwortung vieler verschiedener Nutzeranfragen herangezogen werden. Wenn Sie diese Tabelle jedoch für eine einfache SELECT-Abfrage von carrier und count verwenden möchten,ist ein Scan einer Tabelle mit 885.000 Zeilen erforderlich. Wenn die Tabelle hingegen auf zwei Dimensionen basiert, wären für dieselbe Abfrage nur 4.592 Zeilen zu scannen. Die Tabelle mit 885.000 Zeilen ist immer noch eine Reduzierung der Tabellengröße um 97 % (von den vorherigen 38 Millionen Zeilen). Wenn Sie jedoch eine weitere Dimension hinzufügen, erhöht sich die Tabellengröße auf 20 Millionen Zeilen. Wenn Sie mehr Felder in Ihre Aggregattabelle aufnehmen, um sie für mehr Abfragen nutzbar zu machen, sinkt der zusätzliche Nutzen.
Zusammengefasste Tabellen erstellen
Nehmen wir das Beispiel Flüge. Hier haben wir eine Optimierungsmöglichkeit erkannt. Die beste Strategie wäre, drei verschiedene aggregierte Tabellen zu erstellen:
-
flights_by_week_and_carrier -
flights_by_month_and_distance -
flights_by_year
Am einfachsten erstellen Sie diese aggregierten Tabellen, indem Sie die LookML-Datei für die aggregierte Tabelle aus einer Explore-Abfrage oder aus einem Dashboard abrufen und die LookML-Datei Ihren Looker-Projektdateien hinzufügen.
Nachdem Sie die Aggregat-Tabellen Ihrem LookML-Projekt hinzugefügt und die Aktualisierungen in der Produktion bereitgestellt haben, werden die Aggregat-Tabellen für die Abfragen Ihrer Nutzer in Ihren Explores verwendet.
Persistenz
Damit sie für die aggregierte Analyse zugänglich sind, müssen aggregierte Tabellen in Ihrer Datenbank gespeichert werden. Es empfiehlt sich, die automatische Regenerierung dieser aggregierten Tabellen mit Ihrer Caching-Richtlinie abzustimmen, indem Sie Datengruppen verwenden. Sie sollten für eine aggregierte Tabelle, die für den zugehörigen Explore verwendet wird, dieselbe Datengruppe verwenden. Wenn Sie keine Datengruppen verwenden können, ist der Parameter sql_trigger_value eine Alternative. Im Folgenden sehen Sie einen allgemeinen, datumsbasierten Wert für sql_trigger_value:
sql_trigger_value: SELECT CURRENT_DATE() ;;
Dadurch werden Ihre aggregierten Tabellen jeden Tag um Mitternacht automatisch erstellt.
Zeitraumlogik
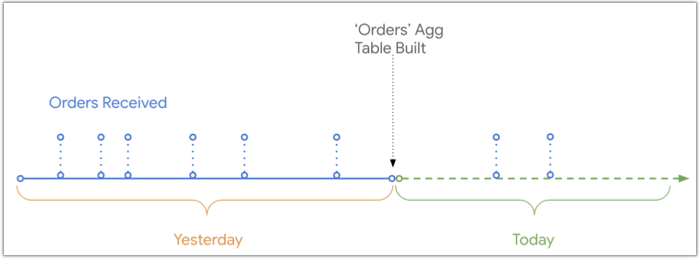
Wenn Looker eine Aggregattabelle erstellt, werden Daten bis zu dem Zeitpunkt berücksichtigt, zu dem die Aggregattabelle erstellt wurde. Alle Daten, die später an die Basistabelle in der Datenbank angehängt wurden, werden normalerweise aus den Ergebnissen einer Abfrage mit dieser Aggregattabelle ausgeschlossen.
Dieses Diagramm zeigt den Zeitablauf, wann Bestellungen eingegangen und in der Datenbank protokolliert wurden, im Vergleich zum Zeitpunkt, zu dem die aggregierte Tabelle Bestellungen erstellt wurde. Heute sind zwei Bestellungen eingegangen, die nicht in der aggregierten Tabelle Bestellungen enthalten sind, da sie nach der Erstellung der Tabelle eingegangen sind:
Looker kann jedoch neue Daten mit der aggregierten Tabelle zusammenführen, wenn ein Nutzer einen Zeitraum abfragt, der sich mit der aggregierten Tabelle überschneidet. Das wird im folgenden Zeitachsendiagramm veranschaulicht:
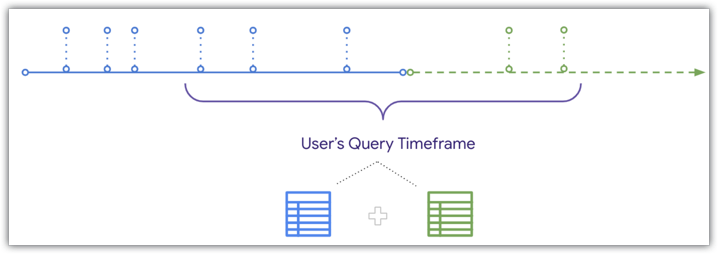
Da in Looker neue Daten mit einer Aggregattabelle zusammengeführt werden können, werden Bestellungen, die nach der Erstellung der Aggregattabelle eingegangen sind, in den Ergebnissen des Nutzers berücksichtigt, wenn er nach einem Zeitraum filtert, der sich mit dem Ende der Aggregat- und der Basistabelle überschneidet. Weitere Informationen und die Bedingungen, die erfüllt sein müssen, um neue Daten mit Abfragen für aggregierte Tabellen zu kombinieren, finden Sie auf der Dokumentationsseite Aggregate awareness.
Zusammenfassung
Zusammenfassend lässt sich sagen, dass es drei grundlegende Schritte gibt, um eine Implementierung für die aggregierte Bekanntheit zu erstellen:
- Möglichkeiten ermitteln, bei denen sich eine Optimierung mit Aggregattabellen anbietet und sich positiv auswirkt.
- Entwerfen Sie Aggregattabellen, die die häufigsten Nutzeranfragen abdecken, aber klein genug sind, um die Größe dieser Anfragen ausreichend zu reduzieren.
- Erstellen Sie die aggregierten Tabellen im Looker-Modell und kombinieren Sie die Persistenz der Tabelle mit der Persistenz des Explore-Cache.