Questa pagina descrive le metriche e i dashboard disponibili per monitorare la latenza di avvio dei carichi di lavoro Google Kubernetes Engine (GKE) e dei nodi del cluster sottostanti. Puoi utilizzare le metriche per monitorare, risolvere i problemi e ridurre la latenza di avvio.
Questa pagina è destinata agli amministratori e agli operatori della piattaforma che devono monitorare e ottimizzare la latenza di avvio dei carichi di lavoro. Per scoprire di più sui ruoli comuni a cui facciamo riferimento nei contenuti di Google Cloud , consulta la pagina Ruoli utente e attività comuni di GKE.
Panoramica
La latenza di avvio influisce in modo significativo sulla risposta dell'applicazione ai picchi di traffico, sulla velocità di ripristino delle repliche in seguito a interruzioni e sull'efficienza dei costi operativi dei cluster e dei carichi di lavoro. Il monitoraggio della latenza di avvio dei tuoi workload può aiutarti a rilevare i peggioramenti della latenza e a monitorare l'impatto degli aggiornamenti del workload e dell'infrastruttura sulla latenza di avvio.
L'ottimizzazione della latenza di avvio del workload offre i seguenti vantaggi:
- Riduce la latenza di risposta del servizio agli utenti durante i picchi di traffico.
- Riduce la capacità di gestione in eccesso necessaria per assorbire i picchi di domanda durante la creazione di nuove repliche.
- Riduce il tempo di inattività delle risorse già implementate e in attesa che le risorse rimanenti vengano avviate durante i calcoli batch.
Prima di iniziare
Prima di iniziare, assicurati di aver eseguito le seguenti operazioni:
- Attiva l'API Google Kubernetes Engine. Attiva l'API Google Kubernetes Engine
- Se vuoi utilizzare Google Cloud CLI per questa attività,
installala e poi
inizializza
gcloud CLI. Se hai già installato gcloud CLI, scarica l'ultima
versione eseguendo il comando
gcloud components update. Le versioni precedenti di gcloud CLI potrebbero non supportare l'esecuzione dei comandi in questo documento.
Abilita le API Cloud Logging e Cloud Monitoring.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Requisiti
Per visualizzare le metriche e i dashboard per la latenza di avvio dei carichi di lavoro, il cluster GKE deve soddisfare i seguenti requisiti:
- Devi avere GKE versione 1.31.1-gke.1678000 o successive.
- Devi configurare la raccolta delle metriche di sistema.
- Devi configurare la raccolta dei log di sistema.
- Abilita le metriche di stato Kube con il componente
PODsui tuoi cluster per visualizzare le metriche di pod e container.
Ruoli e autorizzazioni richiesti
Per ottenere le autorizzazioni necessarie per abilitare la generazione di log e per accedere ai log ed elaborarli, chiedi all'amministratore di concederti i seguenti ruoli IAM:
-
Visualizza cluster, nodi e workload GKE:
Visualizzatore Kubernetes Engine (
roles/container.viewer) sul tuo progetto -
Accedi alle metriche di latenza di avvio e visualizza le dashboard:
Monitoring Viewer (
roles/monitoring.viewer) sul tuo progetto -
Accedi ai log con informazioni sulla latenza, ad esempio gli eventi di pull delle immagini di Kubelet, e visualizzali in Esplora log e Log Analytics:
Logs Viewer (
roles/logging.viewer) sul tuo progetto
Per ulteriori informazioni sulla concessione dei ruoli, consulta Gestisci l'accesso a progetti, cartelle e organizzazioni.
Potresti anche riuscire a ottenere le autorizzazioni richieste tramite i ruoli personalizzati o altri ruoli predefiniti.
Metriche di latenza di avvio
Le metriche di latenza di avvio sono incluse nelle metriche di sistema di GKE e vengono esportate in Cloud Monitoring nello stesso progetto del cluster GKE.
I nomi delle metriche di Cloud Monitoring in questa tabella devono essere preceduti dal prefisso
kubernetes.io/. Questo prefisso è stato omesso dalle voci della tabella.
| Tipo di metrica (livelli della gerarchia delle risorse) Nome visualizzato |
|
|---|---|
|
Tipo, Tipo, Unità
Risorse monitorate |
Descrizione Etichette |
pod/latencies/pod_first_ready
(project)
Latenza prima disponibilità pod |
|
GAUGE, Double, s
k8s_pod |
Latenza di avvio end-to-end del pod (dal pod Created a Ready), inclusi i pull delle immagini. Campionamento eseguito ogni 60 secondi. |
node/latencies/startup
(progetto)
Latenza di avvio dei nodi |
|
GAUGE, INT64, s
k8s_node |
La latenza totale di avvio del nodo, dall'CreationTimestamp dell'istanza GCE a Kubernetes node ready per la prima volta. Campionamento eseguito ogni 60 secondi.accelerator_family: una classificazione dei nodi in base agli acceleratori hardware: gpu, tpu, cpu.
kube_control_plane_available: indica se la richiesta di creazione del nodo è stata ricevuta quando KCP (kube control plane) era disponibile.
|
autoscaler/latencies/per_hpa_recommendation_scale_latency_seconds
(progetto)
Per la latenza di scalabilità dei suggerimenti HPA |
|
GAUGE, DOUBLE, s
k8s_scale |
Latenza dei suggerimenti di scalabilità di Horizontal Pod Autoscaler (HPA) (tempo tra la creazione delle metriche e l'applicazione del suggerimento di scalabilità corrispondente all'apiserver) per il target HPA. Campionamento eseguito ogni 60 secondi. Dopo il campionamento, i dati non sono visibili per un massimo di 20 secondi.metric_type: il tipo di origine della metrica. Deve essere uno tra "ContainerResource", "External", "Object", "Pods" o "Resource".
|
Visualizza la dashboard Latenza di avvio per i workload
La dashboard Latenza di avvio per i carichi di lavoro è disponibile solo per i deployment. Per visualizzare le metriche di latenza di avvio per i deployment, segui questi passaggi nella console Google Cloud :
Vai alla pagina Workload.
Per aprire la visualizzazione Dettagli deployment, fai clic sul nome del workload che vuoi esaminare.
Fai clic sulla scheda Osservabilità.
Seleziona Latenza di avvio dal menu a sinistra.
Visualizza la distribuzione della latenza di avvio dei pod
La latenza di avvio dei pod si riferisce alla latenza di avvio totale, inclusi i pull delle immagini, che misura il tempo che intercorre tra lo stato Created del pod e lo stato Ready. Puoi valutare la latenza di avvio dei pod utilizzando i
due grafici seguenti:
Grafico Distribuzione della latenza di avvio dei pod: questo grafico mostra i percentili di latenza di avvio dei pod (50°, 95° e 99° percentile) calcolati in base alle osservazioni degli eventi di avvio dei pod in intervalli di tempo fissi di tre ore, ad esempio dalle 00:00 alle 03:00 e dalle 03:00 alle 06:00. Puoi utilizzare questo grafico per i seguenti scopi:
- Comprendi la latenza di avvio del pod di base.
- Identifica le modifiche della latenza di avvio dei pod nel tempo.
- Correlare le modifiche alla latenza di avvio dei pod con eventi recenti, come i deployment dei workload o gli eventi del gestore della scalabilità automatica dei cluster. Puoi selezionare gli eventi nell'elenco Annotazioni nella parte superiore della dashboard.
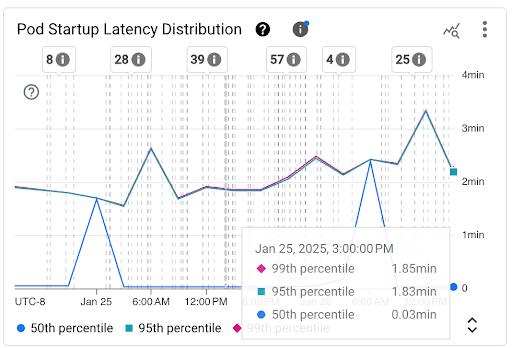
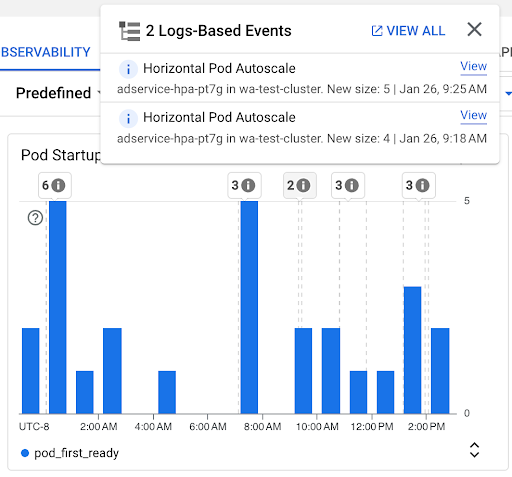
Grafico Conteggio avvii pod: questo grafico mostra il conteggio dei pod avviati durante gli intervalli di tempo selezionati. Puoi utilizzare questo grafico per i seguenti scopi:
- Comprendere le dimensioni dei campioni di pod utilizzati per calcolare i percentili della distribuzione della latenza di avvio dei pod per un determinato intervallo di tempo.
- Comprendere le cause degli avvii dei pod, come i deployment dei workload o gli eventi di Horizontal Pod Autoscaler. Puoi selezionare gli eventi nell'elenco Annotazioni nella parte superiore della dashboard.
Visualizzare la latenza di avvio dei singoli pod
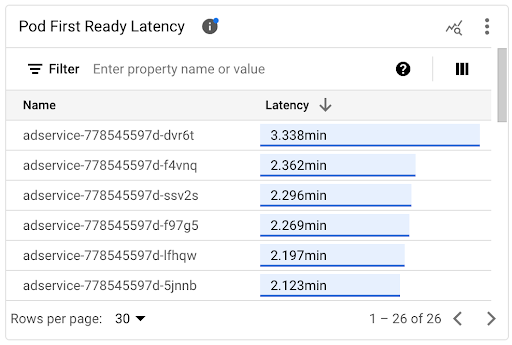
Puoi visualizzare la latenza di avvio dei singoli pod nel grafico della cronologia Latenza di Pod First Ready e nell'elenco associato.
- Utilizza il grafico a cronologia della latenza prima disponibilità pod per correlare gli avvii dei singoli pod con eventi recenti, come gli eventi di Horizontal Pod Autoscaler o Cluster Autoscaler. Puoi selezionare questi eventi nell'elenco Annotazioni nella parte superiore della dashboard. Questo grafico ti aiuta a determinare le potenziali cause di eventuali modifiche della latenza di avvio rispetto ad altri pod.
- Utilizza l'elenco Latenza del primo pod pronto per identificare i singoli pod il cui avvio ha richiesto più o meno tempo. Puoi ordinare l'elenco in base alla colonna Latenza. Quando identifichi i pod con la latenza di avvio più elevata, puoi risolvere i problemi di riduzione della latenza mettendo in correlazione gli eventi di avvio dei pod con altri eventi recenti.
Puoi scoprire quando è stato creato un singolo pod esaminando il valore nel campo timestamp in un evento di creazione del pod corrispondente. Per visualizzare il campo
timestamp, esegui la seguente query in
Esplora log:
log_id("cloudaudit.googleapis.com/activity") AND
protoPayload.methodName="io.k8s.core.v1.pods.create" AND
resource.labels.project_id=PROJECT_ID AND
resource.labels.cluster_name=CLUSTER_NAME AND
resource.labels.location=CLUSTER_LOCATION AND
protoPayload.response.metadata.namespace=NAMESPACE AND
protoPayload.response.metadata.name=POD_NAME
Per elencare tutti gli eventi di creazione dei pod per il tuo workload, utilizza il seguente filtro
nella query precedente:
protoPayload.response.metadata.name=~"POD_NAME_PREFIX-[a-f0-9]{7,10}-[a-z0-9]{5}"
Quando confronti le latenze dei singoli pod, puoi testare l'impatto di varie configurazioni sulla latenza di avvio dei pod e identificare una configurazione ottimale in base ai tuoi requisiti.
Determinare la latenza di pianificazione dei pod
La latenza di pianificazione del pod è il tempo che intercorre tra la creazione di un pod e la sua pianificazione su un nodo. La latenza di pianificazione dei pod contribuisce al tempo di avvio end-to-end di un pod e viene calcolata sottraendo i timestamp di un evento di pianificazione dei pod e di una richiesta di creazione dei pod.
Puoi trovare un timestamp di un singolo evento di pianificazione dei pod dal campo
jsonPayload.eventTime in un evento di pianificazione dei pod corrispondente. Per visualizzare
il campo jsonPayload.eventTime, esegui la seguente query in
Esplora log:
log_id("events")
jsonPayload.reason="Scheduled"
resource.type="k8s_pod"
resource.labels.project_id=PROJECT_ID
resource.labels.location=CLUSTER_LOCATION
resource.labels.cluster_name=CLUSTER_NAME
resource.labels.namespace_name=NAMESPACE
resource.labels.pod_name=POD_NAME
Per elencare tutti gli eventi di pianificazione dei pod per il tuo carico di lavoro, utilizza il seguente filtro
nella query precedente:
resource.labels.pod_name=~"POD_NAME_PREFIX-[a-f0-9]{7,10}-[a-z0-9]{5}"
Visualizzare la latenza di pull delle immagini
La latenza di pull delle immagini container contribuisce alla latenza di avvio del pod negli scenari in cui l'immagine non è ancora disponibile sul nodo o deve essere aggiornata. Quando ottimizzi la latenza di pull delle immagini, riduci la latenza di avvio del workload durante gli eventi di scalabilità orizzontale del cluster.
Puoi visualizzare la tabella Eventi di pull delle immagini di Kubelet per vedere quando sono state estratte le immagini container del workload e quanto tempo ha richiesto il processo.
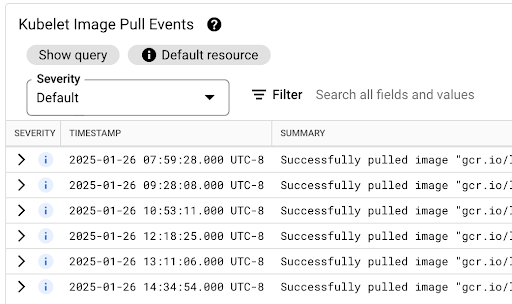
La latenza di pull dell'immagine è disponibile nel campo jsonPayload.message, che
contiene un messaggio simile al seguente:
"Successfully pulled image "gcr.io/example-project/image-name" in 17.093s (33.051s including waiting). Image size: 206980012 bytes."
Visualizza la distribuzione della latenza dei suggerimenti di scalabilità HPA
La latenza dei suggerimenti di scalabilità di Horizontal Pod Autoscaler (HPA) per il target HPA è il tempo che intercorre tra la creazione delle metriche e l'applicazione del suggerimento di scalabilità corrispondente all'API server. Quando ottimizzi la latenza dei suggerimenti di scalabilità HPA, riduci la latenza di avvio del carico di lavoro durante gli eventi di scalabilità orizzontale.
Lo scaling HPA può essere visualizzato nei seguenti due grafici:
Grafico Distribuzione della latenza dei suggerimenti sulla scalabilità HPA: questo grafico mostra i percentili della latenza dei suggerimenti sulla scalabilità HPA (50°, 95° e 99° percentile) calcolati in base alle osservazioni dei suggerimenti sulla scalabilità HPA in intervalli di tempo di 3 ore. Puoi utilizzare questo grafico per i seguenti scopi:
- Comprendi la latenza di base dei suggerimenti di scalabilità HPA.
- Identifica le modifiche apportate alla latenza dei suggerimenti di scalabilità HPA nel tempo.
- Correlare le modifiche alla latenza dei suggerimenti di scalabilità HPA con gli eventi recenti. Puoi selezionare gli eventi nell'elenco Annotazioni nella parte superiore della dashboard.
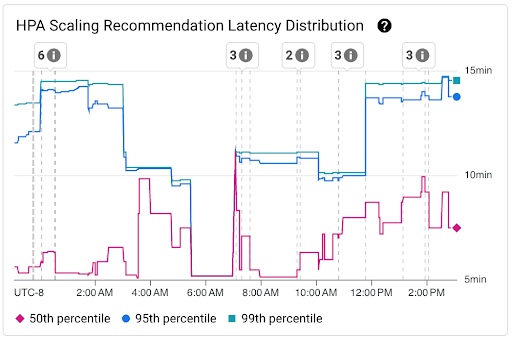
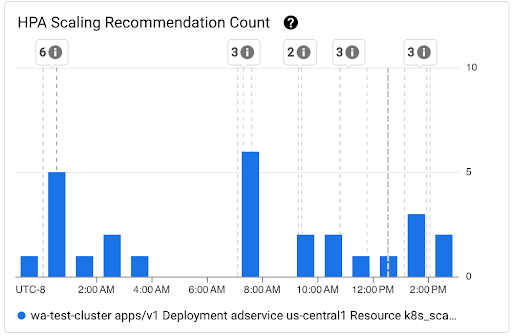
Grafico Numero di suggerimenti sulla scalabilità HPA: questo grafico mostra il conteggio dei suggerimenti di scalabilità HPA osservati durante l'intervallo di tempo selezionato. Utilizza il grafico per le seguenti attività:
- Comprendi le dimensioni del campione dei suggerimenti di scalabilità HPA. I campioni vengono utilizzati per calcolare i percentili nella distribuzione della latenza per i suggerimenti di scalabilità HPA per un determinato intervallo di tempo.
- Correlare i suggerimenti di scalabilità HPA con i nuovi eventi di avvio dei pod e con gli eventi di Horizontal Pod Autoscaler. Puoi selezionare gli eventi nell'elenco Annotazioni nella parte superiore della dashboard.
Visualizza i problemi di pianificazione per i pod
I problemi di pianificazione dei pod potrebbero influire sulla latenza di avvio end-to-end del tuo carico di lavoro. Per ridurre la latenza di avvio end-to-end del workload, risolvi i problemi e riduci il loro numero.
Di seguito sono riportati i due grafici disponibili per monitorare questi problemi:
- Il grafico Pod non pianificabili/in attesa/non riusciti mostra i conteggi di pod non pianificabili, in attesa e non riusciti nel tempo.
- Il grafico Container con backoff/in attesa/non idonei mostra i conteggi dei container in questi stati nel tempo.
Visualizza la dashboard della latenza di avvio per i nodi
Per visualizzare le metriche di latenza di avvio per i nodi, segui questi passaggi nella consoleGoogle Cloud :
Vai alla pagina Cluster Kubernetes.
Per aprire la visualizzazione Dettagli cluster, fai clic sul nome del cluster che vuoi esaminare.
Fai clic sulla scheda Osservabilità.
Nel menu a sinistra, seleziona Latenza di avvio.
Visualizza la distribuzione della latenza di avvio dei nodi
La latenza di avvio di un nodo si riferisce alla latenza di avvio totale, che
misura il tempo che intercorre dall'CreationTimestamp del nodo fino allo
stato Kubernetes node ready. La latenza di avvio dei nodi può essere visualizzata nei
due grafici seguenti:
Grafico Distribuzione della latenza di avvio dei nodi: questo grafico mostra i percentili della latenza di avvio dei nodi (50°, 95° e 99° percentile) calcolati in base alle osservazioni degli eventi di avvio dei nodi in intervalli di tempo fissi di 3 ore, ad esempio 00:00-03:00 e 03:00-06:00. Puoi utilizzare questo grafico per i seguenti scopi:
- Comprendi la latenza di avvio del nodo di base.
- Identifica le modifiche della latenza di avvio dei nodi nel tempo.
- Correlare le modifiche alla latenza di avvio dei nodi con eventi recenti, ad esempio aggiornamenti del cluster o aggiornamenti del node pool. Puoi selezionare gli eventi nell'elenco Annotazioni nella parte superiore della dashboard.
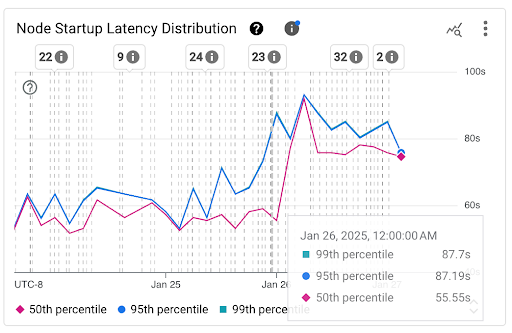
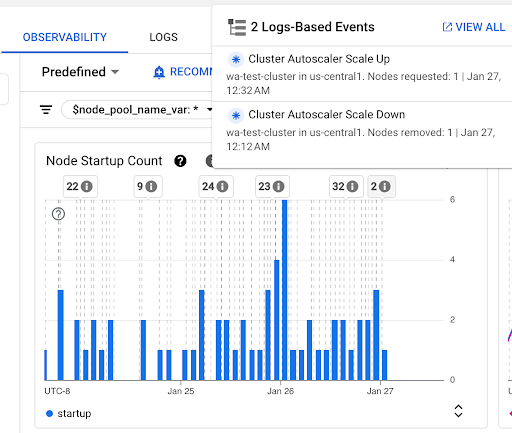
Grafico Conteggio avvii nodi: questo grafico mostra il conteggio dei nodi avviati durante gli intervalli di tempo selezionati. Puoi utilizzare il grafico per i seguenti scopi:
- Comprendere le dimensioni del campione dei nodi, utilizzate per calcolare i percentili della distribuzione della latenza di avvio dei nodi per un determinato intervallo di tempo.
- Comprendere le cause degli avvii dei nodi, ad esempio gli aggiornamenti del pool di nodi o gli eventi del gestore della scalabilità automatica del cluster. Puoi selezionare gli eventi nell'elenco Annotazioni nella parte superiore della dashboard.
Visualizza la latenza di avvio dei singoli nodi
Quando confronti le latenze dei singoli nodi, puoi testare l'impatto di varie configurazioni dei nodi sulla latenza di avvio dei nodi e identificare una configurazione ottimale in base ai tuoi requisiti. Puoi visualizzare la latenza di avvio dei singoli nodi nel grafico a cronologia Latenza di avvio dei nodi e nell'elenco associato.
Utilizza il grafico della cronologia della Latenza di avvio dei nodi per correlare gli avvii dei singoli nodi con eventi recenti, come gli aggiornamenti del cluster o del pool di nodi. Puoi determinare le potenziali cause delle variazioni della latenza di avvio rispetto ad altri nodi. Puoi selezionare gli eventi nell'elenco Annotazioni nella parte superiore della dashboard.
Utilizza l'elenco Latenza di avvio dei nodi per identificare i singoli nodi il cui avvio ha richiesto più o meno tempo. Puoi ordinare l'elenco in base alla colonna Latenza. Quando identifichi i nodi con la latenza di avvio più elevata, puoi risolvere i problemi di riduzione della latenza mettendo in correlazione gli eventi di avvio dei nodi con altri eventi recenti.
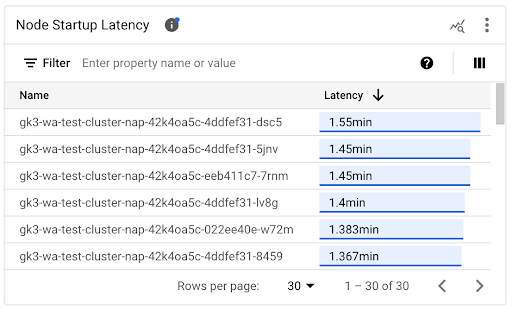
Puoi scoprire quando è stato creato un singolo nodo esaminando il valore del campo protoPayload.metadata.creationTimestamp in un evento di creazione del nodo corrispondente. Per visualizzare il campo protoPayload.metadata.creationTimestamp, esegui la
seguente query in Esplora log:
log_id("cloudaudit.googleapis.com/activity") AND
protoPayload.methodName="io.k8s.core.v1.nodes.create" AND
resource.labels.project_id=PROJECT_ID AND
resource.labels.cluster_name=CLUSTER_NAME AND
resource.labels.location=CLUSTER_LOCATION AND
protoPayload.response.metadata.name=NODE_NAME
Visualizza la latenza di avvio in un pool di nodi
Se i pool di nodi hanno configurazioni diverse, ad esempio per eseguire workload diversi, potrebbe essere necessario monitorare la latenza di avvio dei nodi separatamente per pool di nodi. Quando confronti le latenze di avvio dei nodi nei tuoi pool di nodi, puoi ottenere informazioni su come la configurazione dei nodi influisce sulla latenza di avvio dei nodi e di conseguenza ottimizzare la latenza.
Per impostazione predefinita, il dashboard Latenza di avvio dei nodi mostra la distribuzione della latenza di avvio aggregata e le latenze di avvio dei singoli nodi in tutti i pool di nodi di un cluster. Per visualizzare la latenza di avvio dei nodi per un pool di nodi specifico, seleziona il nome del pool di nodi utilizzando il filtro $node_pool_name_var nella parte superiore della dashboard.
Passaggi successivi
- Scopri come ottimizzare la scalabilità automatica dei pod in base alle metriche.
- Scopri di più sui modi per ridurre la latenza di avvio a freddo su GKE.
- Scopri come ridurre la latenza di pull delle immagini con lo streaming delle immagini.
- Scopri di più sull'economia sorprendente della regolazione della scalabilità automatica orizzontale dei pod.
- Monitora i tuoi carichi di lavoro con il monitoraggio automatico delle applicazioni.