このドキュメントでは、Dataproc クラスタで実行されている Dataproc Jobs サービス、Spark SQL CLI、または Zeppelin ウェブ インターフェースを使用して、メタデータが BigLake metastore に保存された Apache Iceberg テーブルを作成する方法を示します。
始める前に
まだ作成していない場合は、 Google Cloud プロジェクト、Cloud Storage バケット、Dataproc クラスタを作成します。
プロジェクトを設定する
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
外部 ID プロバイダ(IdP)を使用している場合は、まず連携 ID を使用して gcloud CLI にログインする必要があります。
-
gcloud CLI を初期化するには、次のコマンドを実行します。
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
外部 ID プロバイダ(IdP)を使用している場合は、まず連携 ID を使用して gcloud CLI にログインする必要があります。
-
gcloud CLI を初期化するには、次のコマンドを実行します。
gcloud init プロジェクトの Cloud Storage バケットを作成します。
- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
-
In the Get started section, do the following:
- Enter a globally unique name that meets the bucket naming requirements.
- To add a
bucket label,
expand the Labels section (),
click add_box
Add label, and specify a
keyand avaluefor your label.
-
In the Choose where to store your data section, do the following:
- Select a Location type.
- Choose a location where your bucket's data is permanently stored from the Location type drop-down menu.
- If you select the dual-region location type, you can also choose to enable turbo replication by using the relevant checkbox.
- To set up cross-bucket replication, select
Add cross-bucket replication via Storage Transfer Service and
follow these steps:
Set up cross-bucket replication
- In the Bucket menu, select a bucket.
In the Replication settings section, click Configure to configure settings for the replication job.
The Configure cross-bucket replication pane appears.
- To filter objects to replicate by object name prefix, enter a prefix that you want to include or exclude objects from, then click Add a prefix.
- To set a storage class for the replicated objects, select a storage class from the Storage class menu. If you skip this step, the replicated objects will use the destination bucket's storage class by default.
- Click Done.
-
In the Choose how to store your data section, do the following:
- Select a default storage class for the bucket or Autoclass for automatic storage class management of your bucket's data.
- To enable hierarchical namespace, in the Optimize storage for data-intensive workloads section, select Enable hierarchical namespace on this bucket.
- In the Choose how to control access to objects section, select whether or not your bucket enforces public access prevention, and select an access control method for your bucket's objects.
-
In the Choose how to protect object data section, do the
following:
- Select any of the options under Data protection that you
want to set for your bucket.
- To enable soft delete, click the Soft delete policy (For data recovery) checkbox, and specify the number of days you want to retain objects after deletion.
- To set Object Versioning, click the Object versioning (For version control) checkbox, and specify the maximum number of versions per object and the number of days after which the noncurrent versions expire.
- To enable the retention policy on objects and buckets, click the Retention (For compliance) checkbox, and then do the following:
- To enable Object Retention Lock, click the Enable object retention checkbox.
- To enable Bucket Lock, click the Set bucket retention policy checkbox, and choose a unit of time and a length of time for your retention period.
- To choose how your object data will be encrypted, expand the Data encryption section (), and select a Data encryption method.
- Select any of the options under Data protection that you
want to set for your bucket.
-
In the Get started section, do the following:
- Click Create.
Dataproc クラスタを作成します。 リソースと費用を節約するには、このドキュメントで説明する例の実行用に単一ノードの Dataproc クラスタを作成します。
クラスタが作成されるリージョンのサブネットで、プライベート Google アクセス(PGA)を有効にする必要があります。
このガイドの Zeppelin ウェブ インターフェースの例を実行する場合は、Zeppelin オプション コンポーネントが有効になっている Dataproc クラスタを使用または作成する必要があります。
カスタム サービス アカウントにロールを付与します(必要な場合)。デフォルトでは、Dataproc クラスタ VM は Compute Engine のデフォルトのサービス アカウントを使用して Dataproc とやり取りします。クラスタの作成時にカスタム サービス アカウントを指定する場合は、Dataproc ワーカーロール(
roles/dataproc.worker)または必要なワーカーロール権限を持つカスタムロールが必要です。ローカル ターミナル ウィンドウまたは Cloud Shell で、
viやnanoなどのテキスト エディタを使用して、次のコマンドをiceberg-table.sqlファイルにコピーし、ファイルを現在のディレクトリに保存します。USE CATALOG_NAME; CREATE NAMESPACE IF NOT EXISTS example_namespace; USE example_namespace; DROP TABLE IF EXISTS example_table; CREATE TABLE example_table (id int, data string) USING ICEBERG LOCATION 'gs://BUCKET/WAREHOUSE_FOLDER'; INSERT INTO example_table VALUES (1, 'first row'); ALTER TABLE example_table ADD COLUMNS (newDoubleCol double); DESCRIBE TABLE example_table;
次のように置き換えます。
- CATALOG_NAME: Iceberg カタログ名。
- BUCKET と WAREHOUSE_FOLDER: Iceberg ウェアハウスに使用する Cloud Storage バケットとフォルダ。
gcloud CLI を使用して、ローカルの
iceberg-table.sqlを Cloud Storage のバケットにコピーします。gcloud storage cp iceberg-table.sql gs://BUCKET/
ローカル ターミナル ウィンドウまたは Cloud Shell で次の
curlコマンドを実行して、iceberg-spark-runtime-3.5_2.12-1.6.1JAR ファイルを現在のディレクトリにダウンロードします。curl -o iceberg-spark-runtime-3.5_2.12-1.6.1.jar https://storage-download.googleapis.com/maven-central/maven2/org/apache/iceberg/iceberg-spark-runtime-3.5_2.12/1.6.1/iceberg-spark-runtime-3.5_2.12-1.6.1.jar
gcloud CLI を使用して、ローカルの
iceberg-spark-runtime-3.5_2.12-1.6.1JAR ファイルを現在のディレクトリから Cloud Storage のバケットにコピーします。gcloud storage cp iceberg-spark-runtime-3.5_2.12-1.6.1.jar gs://BUCKET/
次の gcloud dataproc jobs submit spark-sql コマンドをローカル ターミナル ウィンドウでローカルに実行するか Cloud Shell で実行して、Iceberg テーブルを作成するための Spark SQL ジョブを送信します。
gcloud dataproc jobs submit spark-sql \ --project=PROJECT_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --jars="gs://BUCKET/1.6.1/iceberg-spark-runtime-3.5_2.12-1.6.1.jar,gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.6.1-1.0.1-beta.jar" \ --properties="spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog,spark.sql.catalog.CATALOG_NAME.catalog-impl=org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog,spark.sql.catalog.CATALOG_NAME.gcp_project=PROJECT_ID,spark.sql.catalog.CATALOG_NAME.gcp_location=LOCATION,spark.sql.catalog.CATALOG_NAME.warehouse=gs://BUCKET/WAREHOUSE_FOLDER" \ -f="gs://BUCKETiceberg-table.sql"
注:
- PROJECT_ID: 実際の Google Cloud プロジェクト ID。 プロジェクト ID は、 Google Cloud コンソールのダッシュボードの [プロジェクト情報] セクションに表示されます。
- CLUSTER_NAME: Dataproc クラスタの名前。
- REGION: クラスタが配置されている Compute Engine リージョン。
- CATALOG_NAME: Iceberg カタログ名。
- BUCKET と WAREHOUSE_FOLDER: Iceberg ウェアハウスに使用する Cloud Storage バケットとフォルダ。
- LOCATION: サポートされている BigQuery のロケーション。デフォルトのロケーションは「US」です。
--jars: BigLake metastore にテーブルのメタデータを作成するために必要な JAR がリストされています。--properties: カタログ プロパティ。-f: Cloud Storage のバケットにコピーしたiceberg-table.sqlジョブファイル。
ジョブが完了したら、ターミナル出力でテーブルの説明を確認します。
Time taken: 2.194 seconds id int data string newDoubleCol double Time taken: 1.479 seconds, Fetched 3 row(s) Job JOB_ID finished successfully.
BigQuery でテーブルのメタデータを確認します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
Iceberg テーブルのメタデータを確認します。
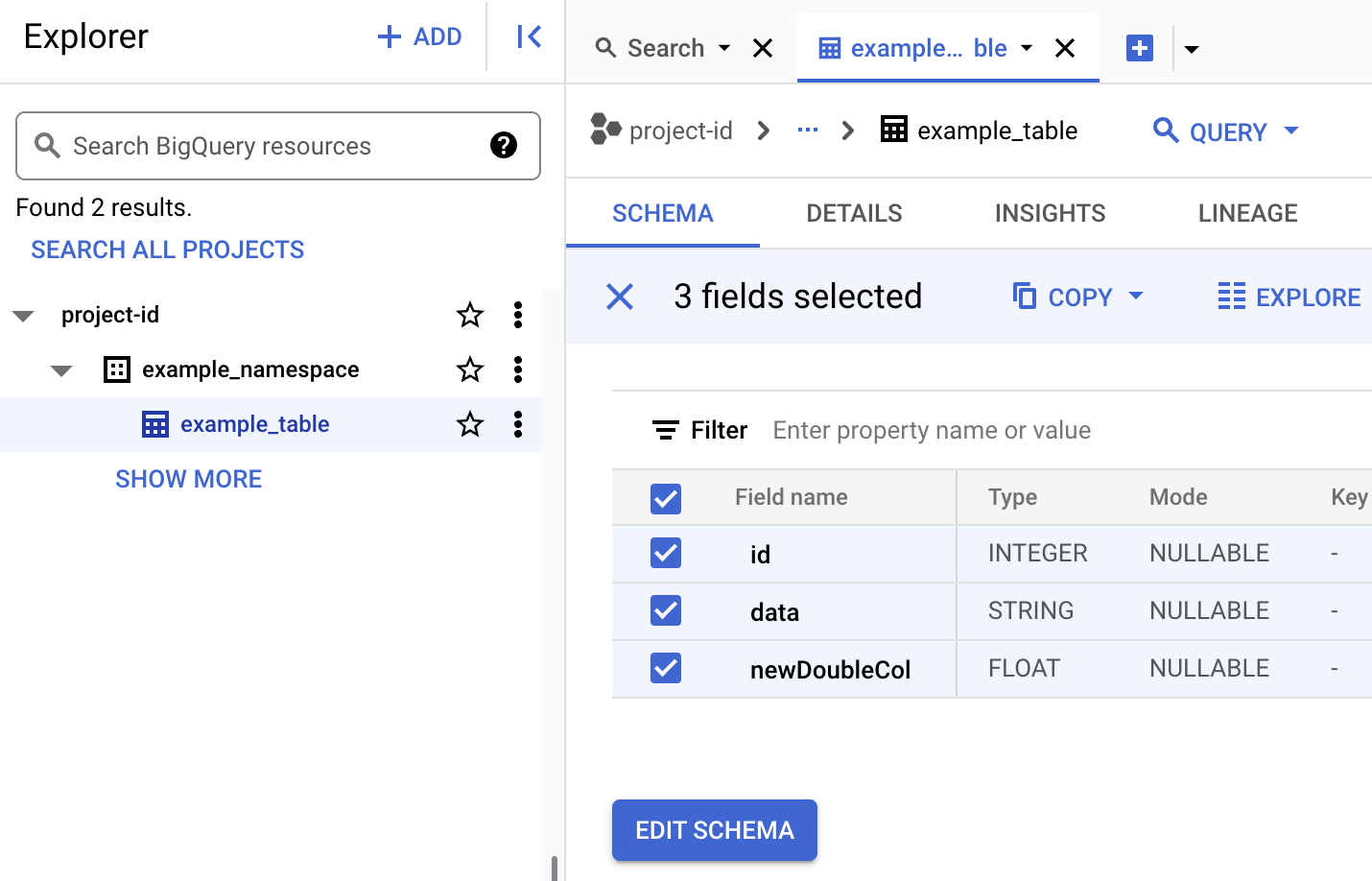
Google Cloud コンソールで、Dataproc の [ジョブの送信] に移動します。
[ジョブを送信] ページに移動し、次のフィールドに入力します。
- ジョブ ID: 提示された ID を使用するか、独自の ID を挿入します。
- リージョン: クラスタが配置されているリージョンを選択します。
- クラスタ: クラスタを選択します。
- ジョブタイプ:
SparkSqlを選択します。 - クエリソースのタイプ:
Query fileを選択します。 - クエリファイル:
gs://BUCKET/iceberg-table.sqlを挿入します。 - JAR ファイル: 以下を挿入します。
gs://BUCKET/iceberg-spark-runtime-3.5_2.12-1.6.1.jar,gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.6.1-1.0.1-beta.jar
- プロパティ: [プロパティを追加] を 5 回クリックして 5 つの
keyvalue入力フィールドのリストを作成し、次のキーと値のペアをコピーして 5 つのプロパティを定義します。# キー 値 1. spark.sql.catalog.CATALOG_NAMEorg.apache.iceberg.spark.SparkCatalog2. spark.sql.catalog.CATALOG_NAME.catalog-implorg.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog3. spark.sql.catalog.CATALOG_NAME.gcp_projectPROJECT_ID4. spark.sql.catalog.CATALOG_NAME.gcp_locationLOCATION5. spark.sql.catalog.CATALOG_NAME.warehousegs://BUCKET/WAREHOUSE_FOLDER
注:
- CATALOG_NAME: Iceberg カタログ名。
- PROJECT_ID: 実際の Google Cloud プロジェクト ID。 プロジェクト ID は、 Google Cloud コンソールのダッシュボードの [プロジェクト情報] セクションに表示されます。 クラスタが配置されているリージョン。
- LOCATION: サポートされている BigQuery のロケーション。デフォルトのロケーションは「US」です。
- BUCKET と WAREHOUSE_FOLDER: Iceberg ウェアハウスに使用する Cloud Storage バケットとフォルダ。
[送信] をクリックします。
ジョブの進行状況をモニタリングしてジョブ出力を確認するには、 Google Cloud コンソールで Dataproc の [ジョブ] ページに移動し、
Job IDをクリックして [ジョブの詳細] ページを開きます。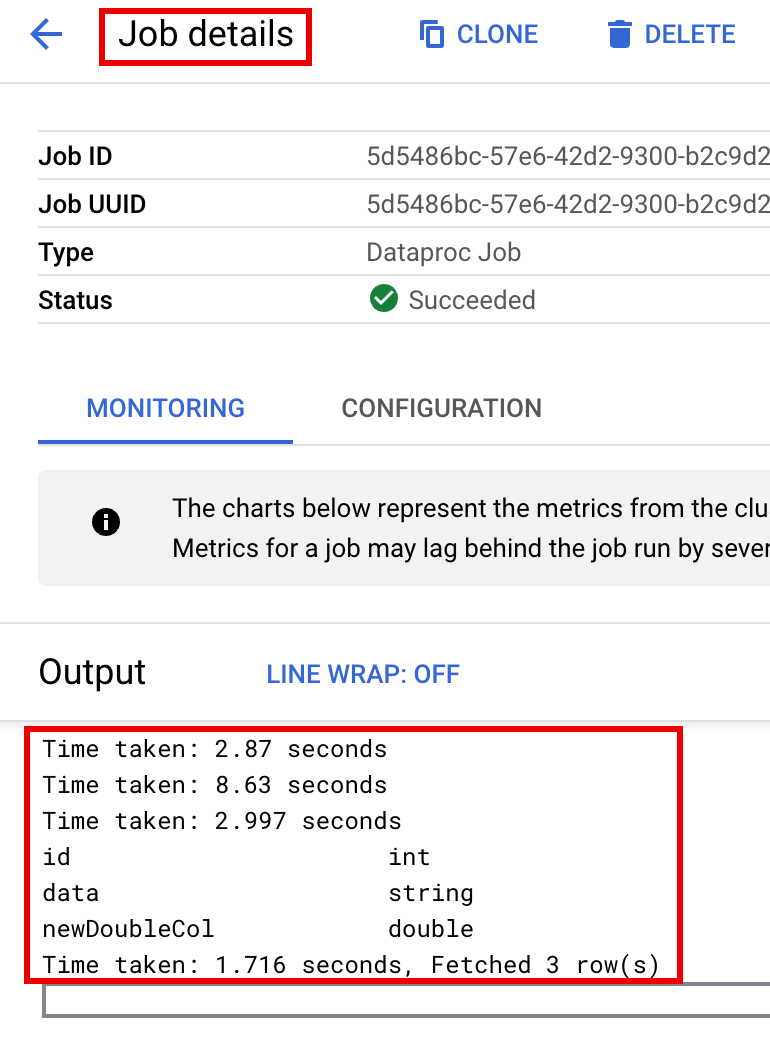
BigQuery でテーブルのメタデータを確認します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
Iceberg テーブルのメタデータを確認します。
- PROJECT_ID: 実際の Google Cloud プロジェクト ID。 プロジェクト ID は、 Google Cloud コンソールのダッシュボードの [プロジェクト情報] セクションに表示されます。
- CLUSTER_NAME: Dataproc クラスタの名前。
- REGION: クラスタが配置されている Compute Engine リージョン。
- CATALOG_NAME: Iceberg カタログ名。
- BUCKET と WAREHOUSE_FOLDER: Iceberg ウェアハウスに使用する Cloud Storage バケットとフォルダ。 LOCATION: サポートされている BigQuery のロケーション。デフォルトのロケーションは「US」です。
jarFileUris: BigQuery metastore にテーブルのメタデータを作成するために必要な JAR がリストされています。properties: カタログのプロパティ。queryFileUri: Cloud Storage のバケットにコピーしたiceberg-table.sqlジョブファイル。Google Cloud コンソールで、[BigQuery] ページに移動します。
Iceberg テーブルのメタデータを確認します。
SSH を使用して、Dataproc クラスタのマスターノードに接続します。
SSH セッション ターミナルで、
viまたはnanoテキスト エディタを使用して、次のコマンドをiceberg-table.sqlファイルにコピーします。SET CATALOG_NAME = `CATALOG_NAME`; SET BUCKET = `BUCKET`; SET WAREHOUSE_FOLDER = `WAREHOUSE_FOLDER`; USE `${CATALOG_NAME}`; CREATE NAMESPACE IF NOT EXISTS `${CATALOG_NAME}`.example_namespace; DROP TABLE IF EXISTS `${CATALOG_NAME}`.example_namespace.example_table; CREATE TABLE `${CATALOG_NAME}`.example_namespace.example_table (id int, data string) USING ICEBERG LOCATION 'gs://${BUCKET}/${WAREHOUSE_FOLDER}'; INSERT INTO `${CATALOG_NAME}`.example_namespace.example_table VALUES (1, 'first row'); ALTER TABLE `${CATALOG_NAME}`.example_namespace.example_table ADD COLUMNS (newDoubleCol double); DESCRIBE TABLE `${CATALOG_NAME}`.example_namespace.example_table;次のように置き換えます。
- CATALOG_NAME: Iceberg カタログ名。
- BUCKET と WAREHOUSE_FOLDER: Iceberg ウェアハウスに使用する Cloud Storage バケットとフォルダ。
SSH セッション ターミナルで、次の
spark-sqlコマンドを実行して Iceberg テーブルを作成します。spark-sql \ --packages org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.6.1 \ --jars https://storage-download.googleapis.com/maven-central/maven2/org/apache/iceberg/iceberg-spark-runtime-3.5_2.12/1.6.1/iceberg-spark-runtime-3.5_2.12-1.6.1.jar,gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.6.1-1.0.1-beta.jar \ --conf spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog \ --conf spark.sql.catalog.CATALOG_NAME.catalog-impl=org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog \ --conf spark.sql.catalog.CATALOG_NAME.gcp_project=PROJECT_ID \ --conf spark.sql.catalog.CATALOG_NAME.gcp_location=LOCATION \ --conf spark.sql.catalog.CATALOG_NAME.warehouse=gs://BUCKET/WAREHOUSE_FOLDER \ -f iceberg-table.sql
次のように置き換えます。
- PROJECT_ID: 実際の Google Cloud プロジェクト ID。 プロジェクト ID は、 Google Cloud コンソールのダッシュボードの [プロジェクト情報] セクションに表示されます。
- LOCATION: サポートされている BigQuery のロケーション。デフォルトのロケーションは「US」です。
BigQuery でテーブルのメタデータを確認します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
Iceberg テーブルのメタデータを確認します。
Google Cloud コンソールで、Dataproc の [クラスタ] ページに移動します。
クラスタ名を選択して [クラスタの詳細] ページを開きます。
[ウェブ インターフェース] タブをクリックすると、クラスタにインストールされているデフォルト コンポーネントとオプション コンポーネントのウェブ インターフェースへのリンクのリストが [コンポーネント ゲートウェイ] に表示されます。
[Zeppelin] リンクをクリックして Zeppelin ウェブ インターフェースを開きます。
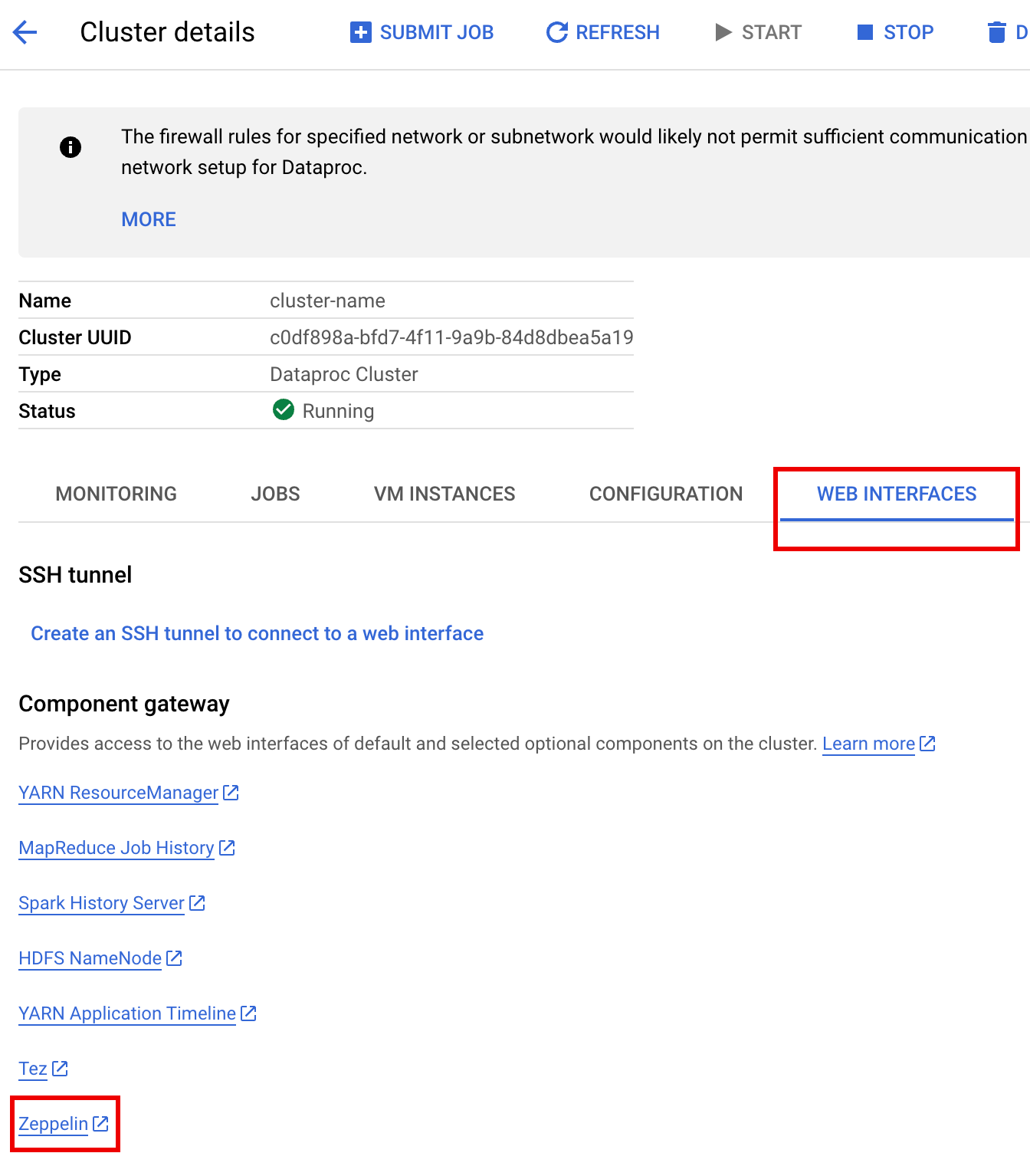
Zeppelin ウェブ インターフェースで [anonymous] メニューをクリックし、[Interpreter] をクリックして [Interpreters] ページを開きます。
次のように、2 つの JAR を Zeppelin Spark インタープリタに追加します。
- [
Search interpreters] ボックスに「Spark」と入力して、Spark インタープリタ セクションまでスクロールします。 - [edit] をクリックします。
[spark.jars] フィールドに次の内容を貼り付けます。
https://storage-download.googleapis.com/maven-central/maven2/org/apache/iceberg/iceberg-spark-runtime-3.5_2.12/1.6.1/iceberg-spark-runtime-3.5_2.12-1.6.1.jar,gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.6.1-1.0.1-beta.jar

Spark インタープリタ セクションの下部にある [Save] をクリックしてから、[OK] をクリックしてインタープリタを更新し、新しい設定で Spark インタープリタを再起動します。
- [
Zeppelin ノートブックのメニューで、[Create new note] をクリックします。
[Create new note] ダイアログでノートブックの名前を入力し、デフォルトの spark インタープリタを受け入れます。[Create] をクリックしてノートブックを開きます。
変数を入力してから、次の PySpark コードを Zeppelin ノートブックにコピーします。
%pyspark
from pyspark.sql import SparkSession
project_id = "PROJECT_ID" catalog = "CATALOG_NAME" namespace = "NAMESPACE" location = "LOCATION" warehouse_dir = "gs://BUCKET/WAREHOUSE_DIRECTORY"
spark = SparkSession.builder \ .appName("BigQuery Metastore Iceberg") \ .config(f"spark.sql.catalog.{catalog}", "org.apache.iceberg.spark.SparkCatalog") \ .config(f"spark.sql.catalog.{catalog}.catalog-impl", "org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog") \ .config(f"spark.sql.catalog.{catalog}.gcp_project", f"{project_id}") \ .config(f"spark.sql.catalog.{catalog}.gcp_location", f"{location}") \ .config(f"spark.sql.catalog.{catalog}.warehouse", f"{warehouse_dir}") \ .getOrCreate()
spark.sql(f"USE `{catalog}`;") spark.sql(f"CREATE NAMESPACE IF NOT EXISTS `{namespace}`;") spark.sql(f"USE `{namespace}`;")
\# Create table and display schema (without LOCATION) spark.sql("DROP TABLE IF EXISTS example_iceberg_table") spark.sql("CREATE TABLE example_iceberg_table (id int, data string) USING ICEBERG") spark.sql("DESCRIBE example_iceberg_table;")
\# Insert table data. spark.sql("INSERT INTO example_iceberg_table VALUES (1, 'first row');")
\# Alter table, then display schema. spark.sql("ALTER TABLE example_iceberg_table ADD COLUMNS (newDoubleCol double);")
\# Select and display the contents of the table. spark.sql("SELECT * FROM example_iceberg_table").show()次のように置き換えます。
- PROJECT_ID: 実際の Google Cloud プロジェクト ID。 プロジェクト ID は、 Google Cloud コンソールのダッシュボードの [プロジェクト情報] セクションに表示されます。
- CATALOG_NAME と NAMESPACE: Iceberg テーブルを識別するための Iceberg カタログ名と名前空間の組み合わせ(
catalog.namespace.table_name)。 - LOCATION: サポートされている BigQuery のロケーション。デフォルトのロケーションは「US」です。
- BUCKET と WAREHOUSE_DIRECTORY: Iceberg ウェアハウスのディレクトリとして使用する Cloud Storage バケットとフォルダ。
実行アイコンをクリックするか、
Shift-Enterキーを押してコードを実行します。ジョブが完了すると、「Spark Job Finished」というステータス メッセージが表示され、出力にテーブルの内容が表示されます。
BigQuery でテーブルのメタデータを確認します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
Iceberg テーブルのメタデータを確認します。
OSS データベースと BigQuery データセットのマッピング
オープンソース データベースと BigQuery データセットの用語のマッピングは次のとおりです。
OSS データベース BigQuery データセット 名前空間、データベース データセット パーティション分割ありまたはパーティション分割なしのテーブル テーブル ビュー ビュー Iceberg テーブルを作成する
このセクションでは、Dataproc クラスタで実行される Dataproc サービス、Spark SQL CLI、Zeppelin コンポーネント ウェブ インターフェースに Spark SQL コードを送信して、メタデータが BigLake metastore に保存された Iceberg テーブルを作成する方を示します。
Dataproc ジョブ
Dataproc サービスにジョブを送信するには、Google Cloud コンソールまたは Google Cloud CLI を使用して Dataproc クラスタにジョブを送信するか、HTTP REST リクエストまたはプログラムによる gRPC Dataproc Cloud クライアント ライブラリで Dataproc Jobs API を呼び出します。
このセクションの例では、gcloud CLI、 Google Cloud コンソール、または Dataproc REST API を使用して、Dataproc Spark SQL ジョブを Dataproc サービスに送信し、メタデータが BigQuery に保存された Iceberg テーブルを作成する方法を示します。
ジョブファイルを準備する
次の手順で Spark SQL ジョブファイルを作成します。このファイルには、Iceberg テーブルの作成と更新を行う Spark SQL コマンドが含まれます。
次に、
iceberg-spark-runtime-3.5_2.12-1.6.1JAR ファイルをダウンロードして Cloud Storage にコピーします。Spark SQL ジョブを送信する
対応するタブの手順に従って、gcloud CLI、Google Cloud コンソール、または Dataproc REST API を使用して Spark SQL ジョブを Dataproc サービスに送信します。
gcloud
コンソール
次の手順で、 Google Cloud コンソールを使用して Spark SQL ジョブを Dataproc サービスに送信し、メタデータが BigLake metastore に保存された Iceberg テーブルを作成します。
REST
Dataproc jobs.submit API を使用して Spark SQL ジョブを Dataproc サービスに送信し、メタデータが BigLake metastore に保存された Iceberg テーブルを作成できます。
リクエストのデータを使用する前に、次のように置き換えます。
HTTP メソッドと URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
リクエストの本文(JSON):
{ "projectId": "PROJECT_ID", "job": { "placement": { "clusterName": "CLUSTER_NAME" }, "statusHistory": [], "reference": { "jobId": "", "projectId": "PROJECT_ID" }, "sparkSqlJob": { "properties": { "spark.sql.catalog."CATALOG_NAME": "org.apache.iceberg.spark.SparkCatalog", "spark.sql.catalog."CATALOG_NAME".catalog-impl": "org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog", "spark.sql.catalog."CATALOG_NAME".gcp_project": "PROJECT_ID", "spark.sql.catalog."CATALOG_NAME".gcp_location": "LOCATION", "spark.sql.catalog."CATALOG_NAME".warehouse": "gs://BUCKET/WAREHOUSE_FOLDER" }, "jarFileUris": [ "gs://BUCKET/iceberg-spark-runtime-3.5_2.12-1.5.2.jar,gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.5.2-1.0.1-beta.jar" ], "scriptVariables": {}, "queryFileUri": "gs://BUCKET/iceberg-table.sql" } } }リクエストを送信するには、次のいずれかのオプションを展開します。
次のような JSON レスポンスが返されます。
{ "reference": { "projectId": "PROJECT_ID", "jobId": "..." }, "placement": { "clusterName": "CLUSTER_NAME", "clusterUuid": "..." }, "status": { "state": "PENDING", "stateStartTime": "..." }, "submittedBy": "USER", "sparkSqlJob": { "queryFileUri": "gs://BUCKET/iceberg-table.sql", "properties": { "spark.sql.catalog.USER_catalog": "org.apache.iceberg.spark.SparkCatalog", "spark.sql.catalog.USER_catalog.catalog-impl": "org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog", "spark.sql.catalog.USER_catalog.gcp_project": "PROJECT_ID", "spark.sql.catalog.USER_catalog.gcp_location": "LOCATION", "spark.sql.catalog.USER_catalog.warehouse": "gs://BUCKET/WAREHOUSE_FOLDER" }, "jarFileUris": [ "gs://BUCKET/iceberg-spark-runtime-3.5_2.12-1.5.2.jar", "gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.5.2-1.0.1-beta.jar" ] }, "driverControlFilesUri": "gs://dataproc-...", "driverOutputResourceUri": "gs://dataproc-.../driveroutput", "jobUuid": "...", "region": "REGION" }ジョブの進行状況をモニタリングしてジョブ出力を確認するには、 Google Cloud コンソールで Dataproc の [ジョブ] ページに移動し、
Job IDをクリックして [ジョブの詳細] ページを開きます。
BigQuery でテーブルのメタデータを確認します。
Spark SQL CLI
次の手順では、Dataproc クラスタのマスターノードで実行されている Spark SQL CLI を使用して、テーブル メタデータが BigLake metastore に保存された Iceberg テーブルを作成する方法を示します。
Zeppelin ウェブ インターフェース
次の手順では、Dataproc クラスタのマスターノードで実行されている Zeppelin ウェブ インターフェースを使用して、テーブル メタデータが BigLake metastore に保存された Iceberg テーブルを作成する方法を示します。