
Bigtable
Escalone seus aplicativos sensíveis à latência com o pioneiro NoSQL
Serviço de banco de dados NoSQL de baixa latência, compatível com Cassandra e HBase, para machine learning, análise operacional e aplicativos voltados ao usuário.
Faça um teste sem custo financeiro.
Características do produto
Ofereça suporte a cargas de trabalho operacionais e analíticas em um único banco de dados com facilidade
Leituras e gravações de alto desempenho mesmo em implantações distribuídas globalmente
Migre facilmente cargas de trabalho NoSQL com APIs e ferramentas de migração compatíveis

Recursos
Baixa latência e capacidade alta
O Bigtable é um armazenamento de chave-valor e famílias de colunas, ideal para o acesso rápido a dados estruturados, semiestruturados ou não estruturados. Isso faz com que cargas de trabalho sensíveis à latência, como a personalização, sejam perfeitas para o Bigtable.
Os contadores distribuídos e a alta capacidade de processamento de leitura e gravação por dólar também o tornam ideal para casos de uso de sequência de cliques e IoT, e até mesmo análise em lote para aplicativos de computação de alto desempenho (HPC), incluindo treinamento de modelos de ML.
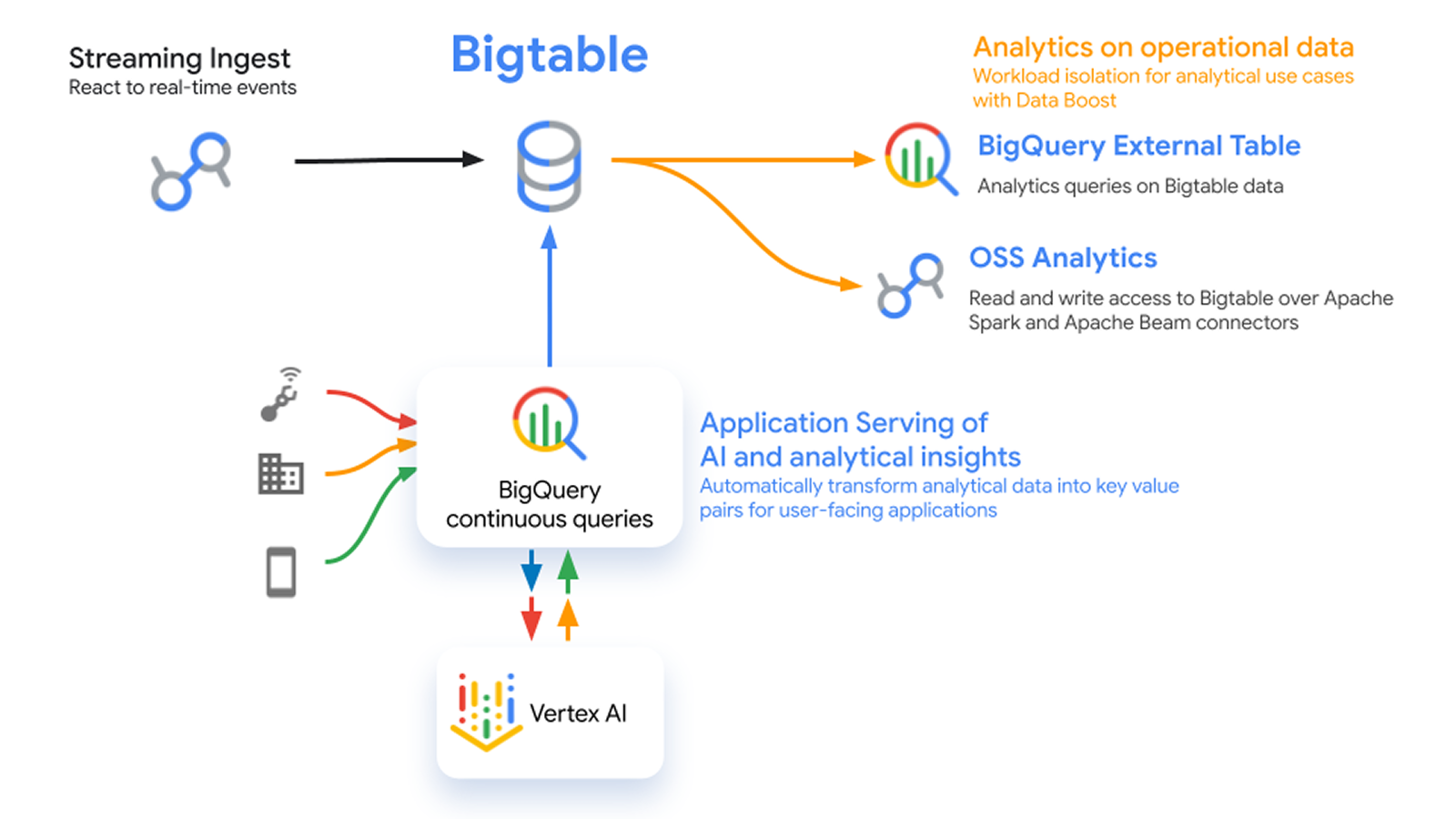
Arquitetura de armazenamento híbrido
O Bigtable oferece camadas de dados automáticas e integradas entre RAM, SSD e HDD, o que ajuda a oferecer alto desempenho com economia. Ofereça latências ultrabaixas com RAM e elimine problemas de uso excessivo do ponto de acesso sem precisar de uma camada de cache. Faça o escalonamento dos dados acessados com pouca frequência para HDD e tenha economias significativas sem gerenciar pipelines de dados e sem se preocupar em manter os dados sincronizados entre vários sistemas.
SQL e visualizações materializadas contínuas
O BigQuery SQL permite que os usuários criem aplicativos em tempo real e totalmente gerenciados usando a sintaxe SQL já conhecida, com recursos especializados que preservam o esquema flexível do BigQuery. Também é possível usar a interface SQL para criar visualizações materializadas incrementais que simplificam a criação de métricas em tempo real. Uma visualização materializada do Bigtable mantém os dados atualizados automaticamente ao processar as alterações conforme elas chegam, sem afetar o desempenho de gravação e leitura, e escalona automaticamente em resposta ao tráfego.
Flexibilidade do modelo de dados
O Bigtable permite que o modelo de dados evolua organicamente. Armazene tudo, desde escalares, JSON, buffers de protocolo, Avro, Arrow até embeddings e imagens, além de adicionar/remover dinamicamente novas colunas conforme necessário. Forneça disponibilização de baixa latência ou análises em lote de alto desempenho em dados brutos e não estruturados em um único banco de dados.
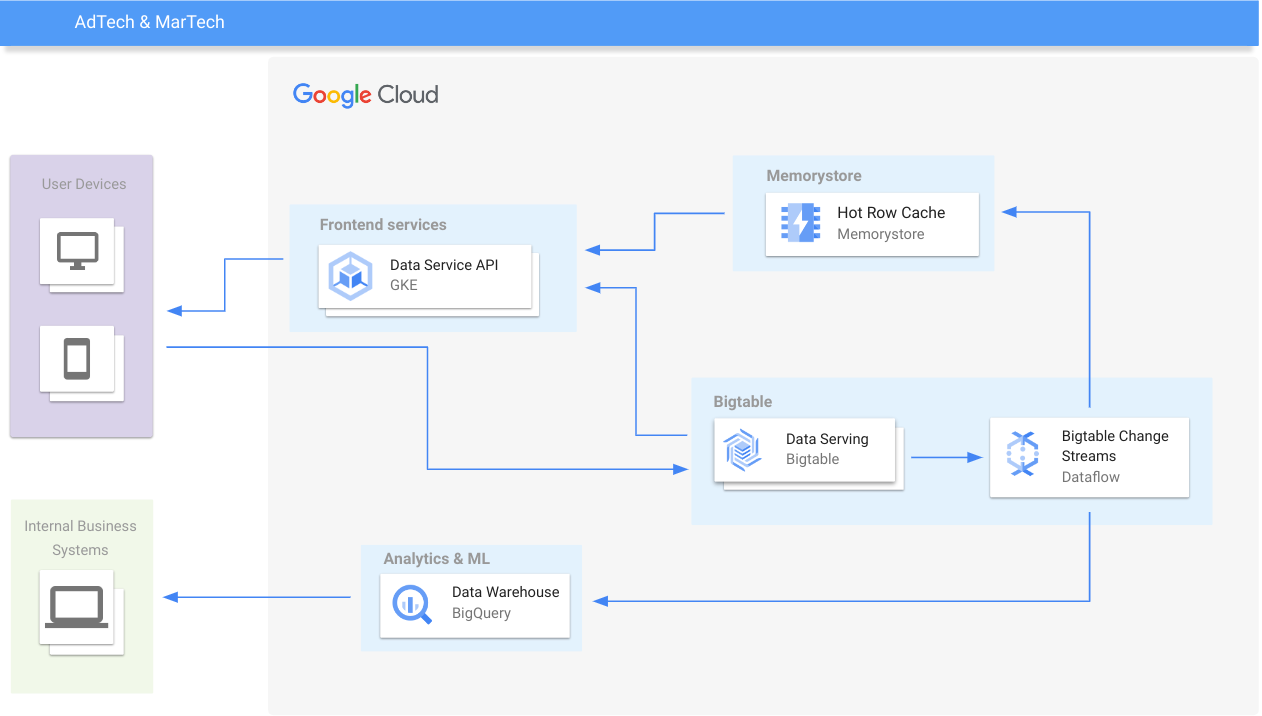
Migração fácil de bancos de dados NoSQL
O Bigtable oferece APIs do Apache Cassandra e do HBase e ferramentas de migração que permitem uma integração mais rápida e simples, garantindo uma migração de dados precisa com menos esforço. A biblioteca de replicação do HBase do Bigtable e o Cassandra Proxy permitem migrações em tempo real sem inatividade, enquanto o Data Bridge do Bigtable e a Ferramenta de migração do Aerospike simplificam as migrações do Amazon DynamoDB e do Aerospike, respectivamente.

De uma única zona até oito regiões de uma só vez
Os aplicativos com suporte do Bigtable podem entregar leituras e gravações de baixa latência com configurações multiprimárias distribuídas globalmente, não importa onde seus usuários estejam. As instâncias zonais são ótimas para economizar custos e podem ser escalonadas perfeitamente para implantações multirregionais com replicação automática. Além disso, ao executar uma instância multirregional, seu banco de dados é protegido contra uma falha regional e oferece disponibilidade líder do setor de 99,999%.
Escalonabilidade de leitura e gravação sem limites
O Bigtable separa os recursos de computação do repositório de dados, o que possibilita o ajuste transparente dos recursos de processamento. Cada nó adicional pode processar leituras e gravações igualmente bem, proporcionando escalabilidade horizontal sem esforço. O Bigtable otimiza o desempenho escalonando automaticamente os recursos para se adaptarem ao tráfego do servidor, lidando com fragmentação, replicação e processamento de consultas.
Processamento de dados de alto desempenho isolado de cargas de trabalho
O Data Boost do Bigtable permite que os usuários executem consultas analíticas, realizem processos de ETL em lote, treinem modelos de ML ou exportem dados com mais rapidez sem afetar as cargas de trabalho transacionais. O Data Boost não requer planejamento nem gerenciamento de capacidade. Ele permite consultar diretamente os dados armazenados no sistema de armazenamento distribuído do Google, o Colossus, usando capacidade sob demanda. Assim, os usuários conseguem facilmente processar cargas de trabalho mistas e compartilhar dados sem preocupações.
Suporte a aplicativos e ferramentas avançados
Conecte-se facilmente ao ecossistema de código aberto com a API Apache HBase. Crie aplicativos baseados em dados mais rapidamente com integrações totais com o Apache Spark, Hadoop, GKE, Dataflow, Dataproc, Vertex AI Vector Search e BigQuery. Conheça as equipes de desenvolvimento onde elas estiverem com bibliotecas de cliente e de SQL para Java, Go, Python, C#, Node.js, PHP, Ruby, C++, HBase e integração com o LangChain.
Desenvolvimento agêntico
Com o suporte a MCP, o Kit de Desenvolvimento de Agente (ADK) e a integração do LangChain, você cria aplicativos de agentes para oferecer suporte à automação de processos ou experiências de usuário conversacionais com facilidade. Usando as habilidades do agente do Bigtable com o Antigravity, o IDE de sua preferência ou a CLI, você aumenta sua produtividade como desenvolvedor, cria mais e mais rápido com o Bigtable.
Sem custos ocultos
Sem cobranças de IOPS, sem custo para fazer ou restaurar backups, nenhum preço de leitura/gravação desproporcional para afetar seu orçamento conforme suas cargas de trabalho evoluem.
Captura e eventos de dados alterados em tempo real
Use os fluxos de alterações do Bigtable para capturar dados alterados dos bancos do Bigtable e integrá-los a outros sistemas para análise, acionamento de eventos e conformidade.
Segurança e controles de nível empresarial
Chaves de criptografia gerenciadas pelo cliente (CMEK, na sigla em inglês) com suporte ao Cloud External Key Manager, integração do IAM para acesso e controles, suporte para VPC-SC, transparência no acesso, aprovação de acesso e registros de auditoria abrangentes ajudam a garantir que seus dados estejam protegidos e em conformidade com as regulamentações. Com o controle de acesso detalhado, você autoriza o acesso no nível da tabela, da coluna ou da linha.

Observabilidade
Monitore o desempenho dos bancos de dados do Bigtable com métricas do lado do servidor. Analise os padrões de uso com a ferramenta de monitoramento interativo Key Visualizer. Use as estatísticas de consulta, as estatísticas da tabela e a ferramenta dos tablets mais usados para solucionar problemas de desempenho de consulta e diagnosticar rapidamente problemas de latência com o monitoramento do lado do cliente.
Recuperação de desastres
Faça backups incrementais do seu banco de dados de forma econômica e restaure sob demanda. Armazene backups em diferentes regiões para ter mais resiliência e fazer restaurações com facilidade entre instâncias ou projetos em cenários de teste e produção.
Como funciona
As instâncias do Bigtable fornecem computação e armazenamento em uma ou mais regiões. Cada cluster do Bigtable pode receber leituras e gravações. Os dados são "divididos" automaticamente para fins de escalonabilidade e replicados entre clusters de maneira assíncrona. Um relógio distribuído chamado TrueTime garante que as transações sejam ordenadas corretamente.
As instâncias do Bigtable fornecem computação e armazenamento em uma ou mais regiões. Cada cluster do Bigtable pode receber leituras e gravações. Os dados são "divididos" automaticamente para fins de escalonabilidade e replicados entre clusters de maneira assíncrona. Um relógio distribuído chamado TrueTime garante que as transações sejam ordenadas corretamente.

Análise em tempo real
Aumente a atualidade dos dados e reduza a latência das consultas
Recursos de aprendizagem
Aumente a atualidade dos dados e reduza a latência das consultas
AdTech e varejo
Personalize experiências em tempo real
Recursos de aprendizagem
Personalize experiências em tempo real
Malha de dados e análise operacional
Consolide silos de dados e faça o escalonamento horizontal de sistemas legados
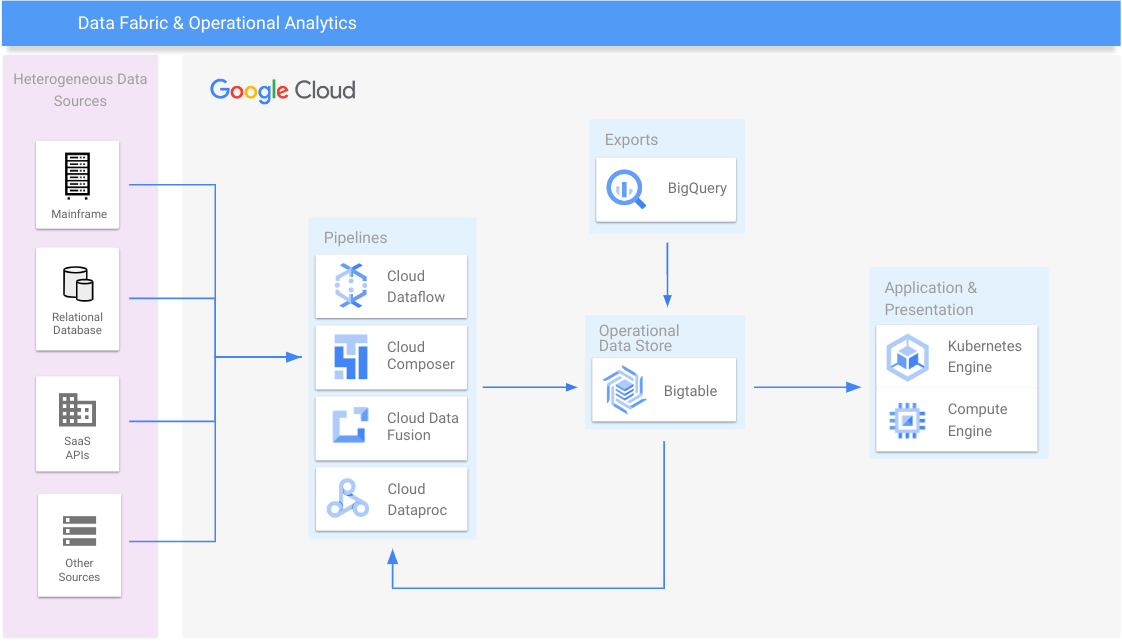
Recursos de aprendizagem
Consolide silos de dados e faça o escalonamento horizontal de sistemas legados
Segurança cibernética
Detecte malware, fraude de pagamento, bloqueio de spam e golpes
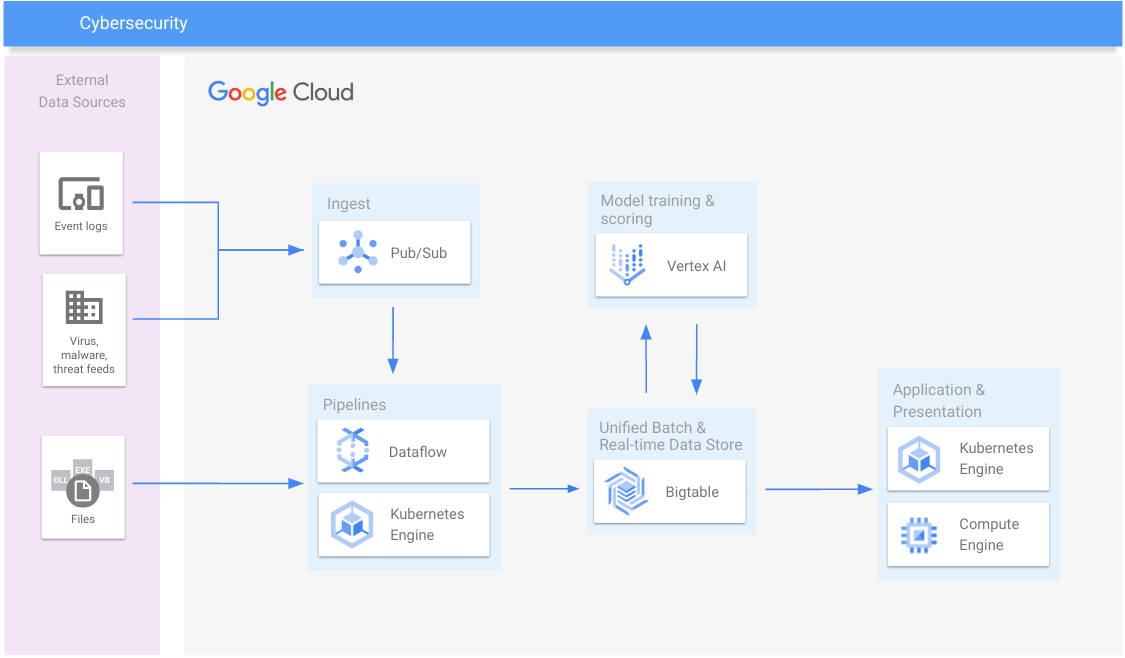
Recursos de aprendizagem
Detecte malware, fraude de pagamento, bloqueio de spam e golpes
Mídia
Ofereça análises de engajamento e conteúdo de mídia
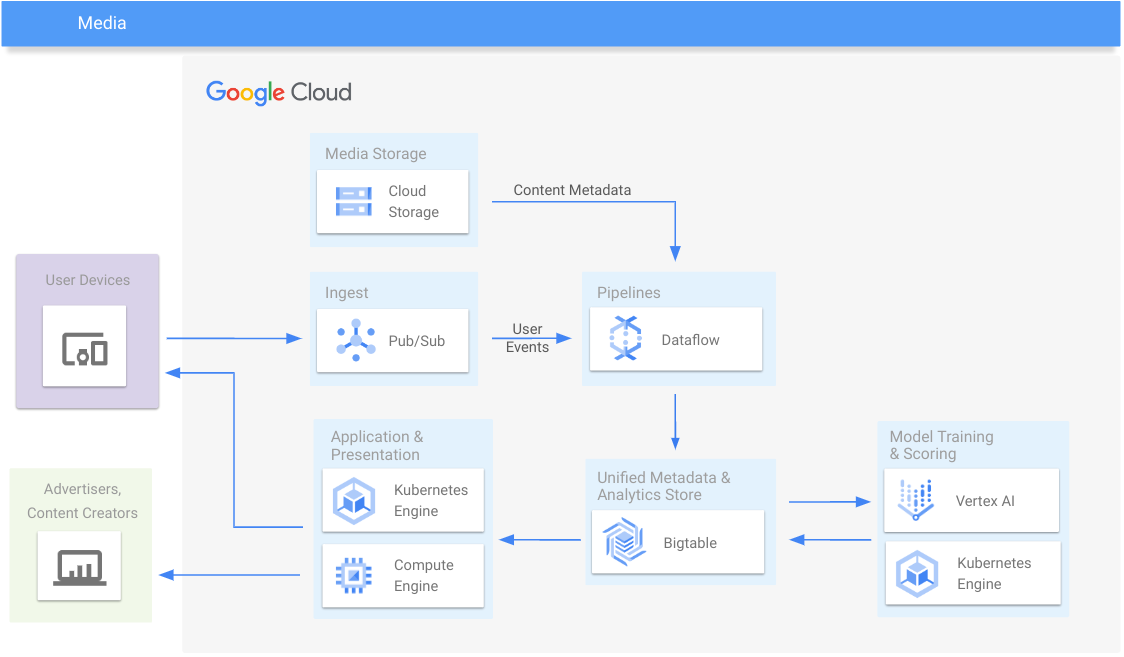
Recursos de aprendizagem
Ofereça análises de engajamento e conteúdo de mídia
Séries temporais e IoT
Gerenciar dados de séries temporais em qualquer escala
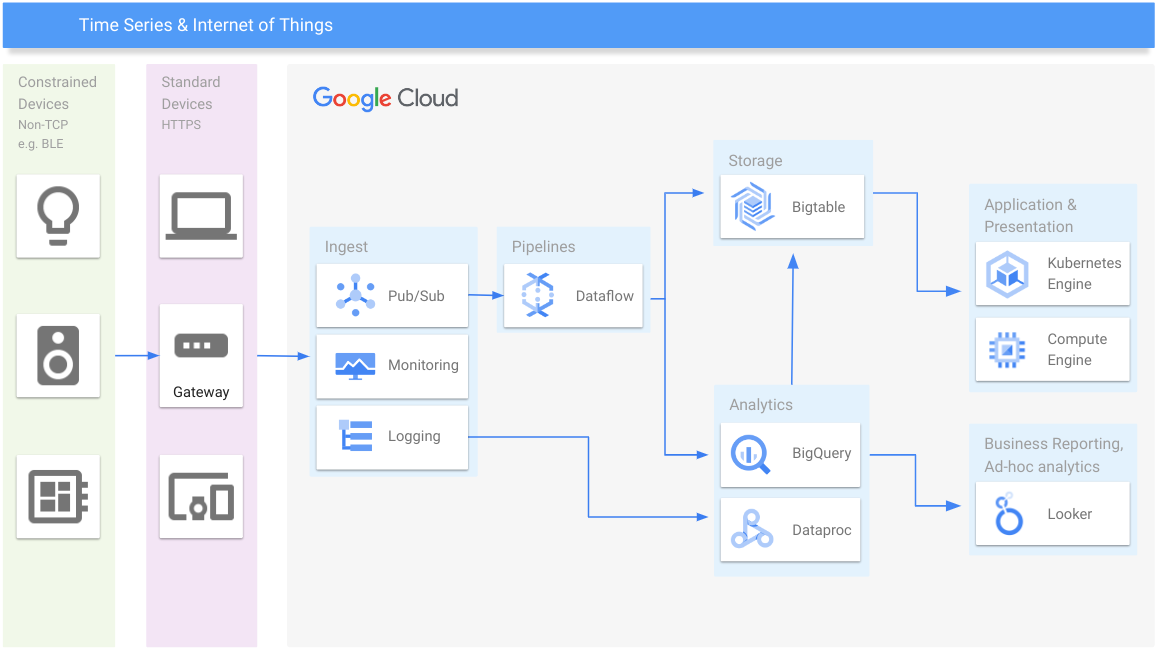
Recursos de aprendizagem
Gerenciar dados de séries temporais em qualquer escala
Infraestrutura de machine learning
Treinamento de modelo em escala e disponibilização.
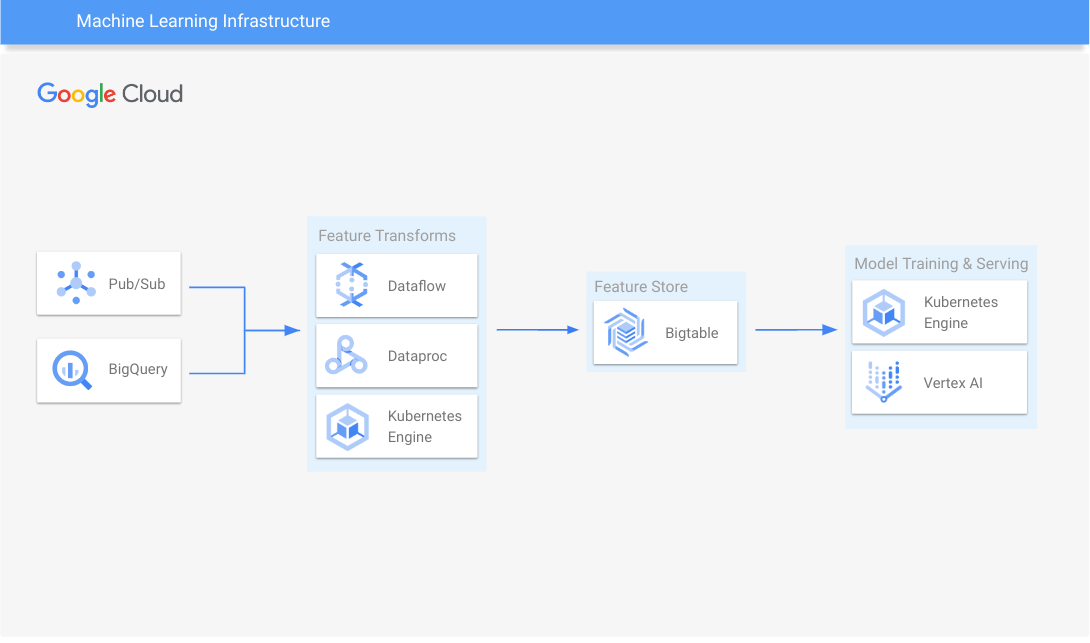
Saiba como usar o Bigtable com armazenamentos de recursos de código aberto conhecidos
Recursos de aprendizagem
Treinamento de modelo em escala e disponibilização.
Saiba como usar o Bigtable com armazenamentos de recursos de código aberto conhecidos
Preços
| Como funcionam os preços do Bigtable | Os preços do Bigtable são baseados na capacidade de computação, no armazenamento do banco de dados, no armazenamento de backup e no uso da rede. Os descontos por uso contínuo reduzem ainda mais o preço. | |
|---|---|---|
| Serviço | Descrição | Preço |
Capacidade de computação | Enterprise edition Ele vem com recursos importantes para machine learning, séries temporais, análise operacional e aplicativos voltados ao usuário em escala com baixa latência de um dígito em milissegundos. A capacidade de computação é provisionada como nós. | A partir de US$ 0,65 por nó/hora |
Enterprise Plus edition Suporte às cargas de trabalho mais exigentes com os níveis mais altos de configurabilidade, desempenho, observabilidade e governança. Inclui todos os recursos da edição Enterprise e pode oferecer latência abaixo de milissegundos. A capacidade de computação é provisionada como nós. | A partir de US$ 0,85 por nó/hora | |
Camada na memória Capacidade de processamento de leitura na memória para leituras de latência ultrabaixa com alta resistência a pontos de acesso. Disponível apenas na edição Enterprise Plus. A capacidade de processamento de leitura é provisionada em incrementos de 40.000 linhas (1 kB) por segundo, até 120.000 linhas por segundo por nó. | A partir de US$ 0,20 por 40.000 linhas por segundo de capacidade | |
Data Boost | Recursos de computação isolados e sob demanda para processamento em lote | A partir de US$ 0,000845 por unidade de processamento sem servidor por hora |
Armazenamento de dados | SSD Os preços são baseados no tamanho físico das tabelas. Cada réplica é faturada separadamente. Recomendado para veiculação de baixa latência. | A partir de US$ 0,17 por GB/mês |
HDD Os preços são baseados no tamanho físico das tabelas. Cada réplica é faturada separadamente. O acesso infrequente (IA) usa HDD e é cobrado com a mesma taxa. | A partir de US$ 0,026 por GB/mês | |
Backups | Backups padrão O preço é baseado no tamanho físico dos backups. Os backups do Bigtable são incrementais. | A partir de US$ 0,026 por GB/mês |
Backups dinâmicos Otimizado para reduzir significativamente o tempo de restauração. O preço é baseado no tamanho físico dos backups. | A partir de US$ 0,12 por GB/mês | |
Rede | Entrada | Sem custo financeiro |
Saída dentro da mesma região | Sem custo financeiro | |
Saída entre regiões | A partir de US$ 0,10 por GB | |
Replicação | Dentro da mesma região | Sem custo financeiro |
Entre as regiões | A partir de US$ 0,01 por GB | |
Saiba mais sobre os preços do Bigtable e osdescontos por compromisso de uso.
Como funcionam os preços do Bigtable
Os preços do Bigtable são baseados na capacidade de computação, no armazenamento do banco de dados, no armazenamento de backup e no uso da rede. Os descontos por uso contínuo reduzem ainda mais o preço.
Capacidade de computação
Enterprise edition
Ele vem com recursos importantes para machine learning, séries temporais, análise operacional e aplicativos voltados ao usuário em escala com baixa latência de um dígito em milissegundos.
A capacidade de computação é provisionada como nós.
Starting at
US$ 0,65
por nó/hora
Enterprise Plus edition
Suporte às cargas de trabalho mais exigentes com os níveis mais altos de configurabilidade, desempenho, observabilidade e governança. Inclui todos os recursos da edição Enterprise e pode oferecer latência abaixo de milissegundos.
A capacidade de computação é provisionada como nós.
Starting at
US$ 0,85
por nó/hora
Camada na memória
Capacidade de processamento de leitura na memória para leituras de latência ultrabaixa com alta resistência a pontos de acesso. Disponível apenas na edição Enterprise Plus.
A capacidade de processamento de leitura é provisionada em incrementos de 40.000 linhas (1 kB) por segundo, até 120.000 linhas por segundo por nó.
Starting at
US$ 0,20
por 40.000 linhas por segundo de capacidade
Data Boost
Recursos de computação isolados e sob demanda para processamento em lote
Starting at
US$ 0,000845
por unidade de processamento sem servidor por hora
Armazenamento de dados
SSD
Os preços são baseados no tamanho físico das tabelas. Cada réplica é faturada separadamente. Recomendado para veiculação de baixa latência.
Starting at
US$ 0,17
por GB/mês
HDD
Os preços são baseados no tamanho físico das tabelas. Cada réplica é faturada separadamente. O acesso infrequente (IA) usa HDD e é cobrado com a mesma taxa.
Starting at
US$ 0,026
por GB/mês
Backups
Backups padrão
O preço é baseado no tamanho físico dos backups. Os backups do Bigtable são incrementais.
Starting at
US$ 0,026
por GB/mês
Backups dinâmicos
Otimizado para reduzir significativamente o tempo de restauração. O preço é baseado no tamanho físico dos backups.
Starting at
US$ 0,12
por GB/mês
Rede
Entrada
Sem custo financeiro
Saída dentro da mesma região
Sem custo financeiro
Saída entre regiões
Starting at
US$ 0,10
por GB
Replicação
Dentro da mesma região
Sem custo financeiro
Entre as regiões
Starting at
US$ 0,01
por GB
Saiba mais sobre os preços do Bigtable e osdescontos por compromisso de uso.
Caso de negócios
Veja como outras empresas criaram apps inovadores para entregar ótimas experiências aos clientes, reduzir custos e aumentar o ROI com o Bigtable
Confira como a Box modernizou os bancos de dados NoSQL com o Bigtable
A Box melhora a escalonabilidade e a disponibilidade, além de reduzir o custo de gerenciamento por meio de uma migração perfeita.
Conteúdo relacionado



Benefícios e clientes
Expanda seus negócios com aplicativos inovadores que são escalonados sem limites para atender a qualquer demanda.
Tenha o melhor custo-benefício da categoria e pague pelo que usar.
Migre facilmente de outros bancos de dados NoSQL e execute implantações híbridas ou de várias nuvens com APIs de código aberto e ferramentas de migração.















Parceiros e integração
Aproveite nossos parceiros especializados em Bigtable para ajudar você em todas as etapas da jornada, desde avaliações e casos de negócios até migrações e criação de novos aplicativos no Bigtable.

































Integradores de sistemas
Quer saber mais detalhes sobre qual integração de parceiro ou terceiros é melhor para sua empresa? Acesse o diretório de parceiros.
Saiba mais
Perguntas frequentes
Que tipo de banco de dados é o Bigtable?
O Bigtable é um serviço de banco de dados NoSQL, mais especificamente um armazenamento de chave-valor que permite tabelas muito amplas com dezenas de milhares de colunas. Portanto, também é chamado de banco de dados de famílias de colunas ou mapa multidimensional distribuído O Bigtable é um banco de dados NoSQL em "Não apenas SQL" em vez de "Zero SQL". Ele oferece suporte a muitos recursos além de pesquisas de chave-valor, incluindo agregações e índices secundários globais.
O Bigtable é mais semelhante aos projetos de código aberto populares que ele inspirou, como Apache HBase e Cassandra, e, por isso, ele é o destino mais comum para clientes que lidam com grandes volumes de dados e que estão buscando uma solução de banco de dados NoSQL de alto desempenho, econômica e totalmente gerenciada no Google Cloud.
O Bigtable aceita SQL?
Além das APIs de chave-valor, o Bigtable também oferece suporte a consultas SQL de três maneiras diferentes:
- Para o desenvolvimento de aplicativos de baixa latência, o Bigtable oferece uma API de consulta SQL baseada no GoogleSQL com extensões para o modelo de dados de colunas largas semelhantes ao Cassandra Query Language (CQL). Ele oferece suporte a mais de 200 funções, incluindo agregações (GROUP BY), janelas, funções de processamento geoespacial e JSON e pesquisa vetorial (kNN). O Bigtable aceita a sintaxe de consulta padrão e encadeada.
- Para casos de uso de ciência de dados ou outros tipos de processamento em lote e ETL, o Bigtable oferece suporte ao SparkSQL usando o cliente Spark.
- Para usuários que querem fazer análises exploratórias post-hoc ou combinar dados de várias fontes para análises em lote, os dados do Bigtable também podem ser acessados pelo BigQuery. Basta registrar suas tabelas do Bigtable no BigQuery e fazer consultas como qualquer outra tabela do BigQuery, sem qualquer ETL ou duplicação de dados.
Como faço para migrar bancos de dados para o Bigtable?
O Bigtable oferece APIs do Apache Cassandra e do HBase e ferramentas de migração que permitem uma integração mais rápida e simples, garantindo uma migração de dados precisa com menos esforço. A biblioteca de replicação do HBase do Bigtable e as ferramentas de migração do Cassandra permitem migrações em tempo real sem inatividade. O Bigtable também oferece utilitários para simplificar as migrações do DynamoDB e do Aerospike.
O Bigtable funciona sem servidor?
O armazenamento do Bigtable é cobrado por GB usado de maneira semelhante a um modelo sem servidor. O Bigtable também oferece escalonamento horizontal linear e pode aumentar e diminuir automaticamente os recursos de computação em resposta a flutuações na demanda. Por isso, não exige um compromisso de capacidade de longo prazo para armazenamento ou computação. No entanto, o preço da computação de baixa latência é baseado em capacidade e cobrado por nó, não por solicitação, em que cada nó pode atender até 17 mil solicitações por segundo. Isso torna o preço do Bigtable mais favorável para cargas de trabalho maiores, mas menos ideal para aplicativos pequenos que podem ser mais adequados para bancos de dados do Google Cloud, como o Firestore.
Para processamento de dados em lote, o Bigtable oferece o Data Boost, que é faturado em unidades de processamento sem servidor (SPU, na sigla em inglês).
O Bigtable é um cache persistente?
O Bigtable é um banco de dados com desempenho semelhante ao de um cache, não um cache com persistência. Ele oferece recursos avançados de processamento no banco de dados, uma API SQL, visualizações materializadas contínuas e índices secundários assíncronos, usando a tecnologia RDMA para fornecer acesso direto à RAM para alto rendimento e desempenho não vinculados à capacidade da CPU do servidor de banco de dados. Embora seja possível usar o Bigtable como substituto para soluções de cache duráveis como o MemoryDB, o contrário nem sempre é verdadeiro, já que soluções como o Redis foram projetadas como um cache, não como um banco de dados.


















