持续查询简介
本文档介绍了 BigQuery 持续查询。
BigQuery 持续查询是持续运行的 SQL 语句。借助持续查询,您可以实时分析 BigQuery 中的传入数据。您可以将持续查询生成的输出行插入 BigQuery 表中,也可以将其导出到 Pub/Sub、Bigtable 或 Spanner。持续查询可以使用以下方法之一处理已写入标准 BigQuery 表的数据:
您可以使用持续查询执行对时间敏感的任务,例如创建数据洞见并立即采取行动、应用实时机器学习 (ML) 推理,以及将数据复制到其他平台。这样,您就可以将 BigQuery 用作应用决策逻辑的事件驱动型数据处理引擎。
下图显示了常见的持续查询工作流:
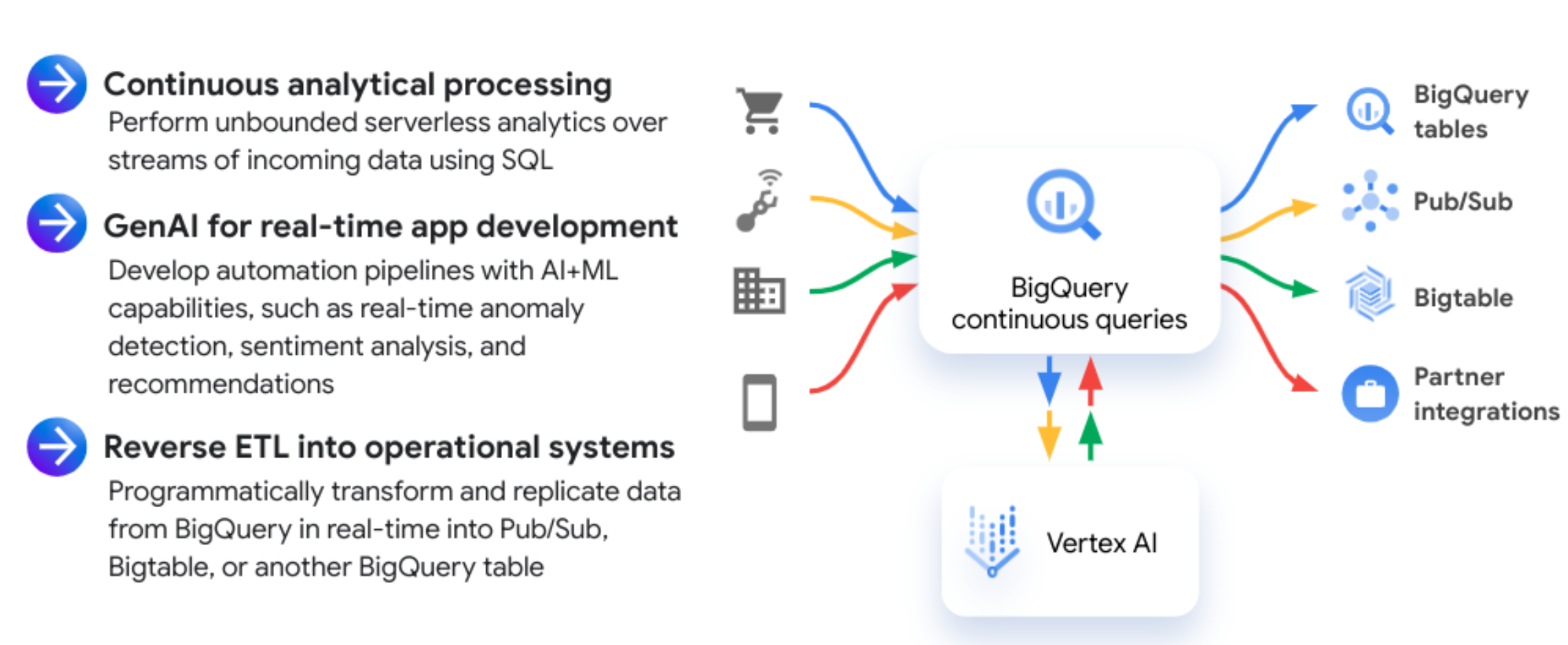
使用场景
您可能需要使用持续查询的常见使用场景如下:
- 个性化的客户互动服务:使用生成式 AI 为每一次客户互动创建量身定制的个性化消息。
- 异常值检测:构建可让您实时对复杂数据执行异常值和威胁检测的解决方案,以便您更快地对问题做出响应。
- 可自定义的事件驱动型流水线:使用与 Pub/Sub 的持续查询集成,根据传入的数据触发下游应用。
- 数据丰富化和实体提取:使用持续查询,通过 SQL 函数和机器学习模型执行实时数据丰富化和转换。
- 反向提取、转换和加载(反向 ETL):对更适合低延迟应用服务的其他存储系统执行实时反向 ETL。例如,分析或增强写入 BigQuery 的事件数据,然后将其流式传输到 Bigtable 或 Spanner 以供应用使用。
支持的操作
持续查询支持以下操作:
- 运行
INSERT语句以将持续查询中的数据写入 BigQuery 表中。 运行
EXPORT DATA语句以将持续查询输出发布到 Pub/Sub 主题。如需了解详情,请参阅将数据导出到 Pub/Sub。您可以将 Pub/Sub 主题中的数据与其他服务结合使用,例如使用 Dataflow 执行流式数据分析,或在应用集成工作流中使用数据。
运行
EXPORT DATA语句,将数据从 BigQuery 导出到 Bigtable 表。如需了解详情,请参阅将数据导出到 Bigtable。运行
EXPORT DATA语句,将数据从 BigQuery 导出到 Spanner 表。如需了解详情,请参阅将数据导出到 Spanner(反向 ETL)。调用以下生成式 AI 函数:
此函数需要您具有基于 Vertex AI 模型的 BigQuery ML 远程模型。
调用以下 AI 函数:
这些函数需要您通过 Cloud AI API 建立 BigQuery ML 远程模型。
使用
ML.NORMALIZER函数对数值数据进行归一化处理。使用无状态 GoogleSQL 函数,例如转换函数。在无状态函数中,每行都会与表格中的其他行分开处理。
使用
APPENDS更改历史记录函数以从特定时间点开始持续查询处理。
授权
运行持续查询作业时使用的 Google Cloud 访问令牌由用户账号生成后,存留时间 (TTL) 为两天。因此,此类作业会在两天后停止运行。服务账号生成的访问令牌可以运行更长时间,但仍必须遵守查询运行时上限。如需了解详情,请参阅使用服务账号运行持续查询。
位置
以下位置支持持续查询:
| 区域说明 | 区域名称 | 详细信息 | |
|---|---|---|---|
| 美洲 | |||
| 美国多区域 | us |
||
| 达拉斯 | us-south1 |
|
|
| 艾奥瓦 | us-central1 |
|
|
| 洛杉矶 | us-west2 |
||
| 墨西哥 | northamerica-south1 |
||
| 蒙特利尔 | northamerica-northeast1 |
|
|
| 北弗吉尼亚 | us-east4 |
||
| 俄勒冈 | us-west1 |
|
|
| 盐湖城 | us-west3 |
||
| 圣地亚哥 | southamerica-west1 |
|
|
| 圣保罗 | southamerica-east1 |
|
|
| 南卡罗来纳 | us-east1 |
||
| 多伦多 | northamerica-northeast2 |
|
|
| 亚太地区 | |||
| 德里 | asia-south2 |
||
| 香港 | asia-east2 |
||
| 雅加达 | asia-southeast2 |
||
| 墨尔本 | australia-southeast2 |
||
| 孟买 | asia-south1 |
||
| 大阪 | asia-northeast2 |
||
| 首尔 | asia-northeast3 |
||
| 新加坡 | asia-southeast1 |
||
| 悉尼 | australia-southeast1 |
||
| 台湾 | asia-east1 |
||
| 东京 | asia-northeast1 |
||
| 欧洲 | |||
| 欧盟多区域 | eu |
||
| 比利时 | europe-west1 |
|
|
| 柏林 | europe-west10 |
||
| 芬兰 | europe-north1 |
|
|
| 法兰克福 | europe-west3 |
||
| 伦敦 | europe-west2 |
|
|
| 马德里 | europe-southwest1 |
|
|
| 米兰 | europe-west8 |
||
| 荷兰 | europe-west4 |
|
|
| 巴黎 | europe-west9 |
|
|
| 斯德哥尔摩 | europe-north2 |
|
|
| 都灵 | europe-west12 |
||
| 华沙 | europe-central2 |
||
| 苏黎世 | europe-west6 |
|
|
| 中东 | |||
| 多哈 | me-central1 |
||
| Dammam | me-central2 |
||
| 特拉维夫 | me-west1 |
||
| 非洲 | |||
| 约翰内斯堡 | africa-south1 |
||
限制
持续查询存在以下限制:
- BigQuery 持续查询不会维护已注入的数据的状态。不支持依赖于状态的常见操作,例如
JOIN、聚合函数或窗口函数。 您不能在持续查询中使用以下 SQL 功能:
持续查询不支持处理变更数据捕获 (CDC) 更新/插入数据。
持续查询不支持将通配符表用作数据源。
持续查询不支持将外部表用作数据源。
持续查询不支持将 INFORMATION_SCHEMA 视图用作数据源。
持续查询不支持以下 BigQuery 安全功能:
将数据导出到 Bigtable 时,您只能定位与包含您正在查询的表的 BigQuery 数据集位于同一Google Cloud 区域边界内的 Bigtable 实例。如需了解详情,请参阅位置注意事项。此限制不适用于将数据导出到 Pub/Sub,因为 Pub/Sub 是一个全球性资源。
将数据导出到 Bigtable、Spanner 或 Pub/Sub 位置端点时,您只能定位与包含您正在查询的表的 BigQuery 数据集位于同一 Google Cloud区域边界内的 Bigtable、Spanner 或 Pub/Sub 资源。将数据导出到 Pub/Sub 全球端点时,此限制不适用。
您无法从数据画布运行持续查询。
在持续查询作业运行期间,您无法修改持续查询中使用的 SQL。如需了解详情,请参阅修改持续查询的 SQL。
如果持续查询作业在处理传入数据方面落后,并且输出水印滞后时间超过 48 小时,则该作业会失败。您可以再次运行查询并使用
APPENDS更改历史记录功能从停止上一个持续查询作业的时间点恢复处理。如需了解详情,请参阅从特定时间点开始持续查询。使用用户账号配置的持续查询最多可运行两天。使用服务账号配置的持续查询最多可运行 150 天。达到查询运行时上限后,查询会失败并停止处理传入数据。
虽然持续查询是使用 BigQuery 可靠性功能构建的,但偶尔也会出现临时性问题。问题可能会导致系统自动对您的持续查询进行一定程度的重复处理,从而导致持续查询输出中出现重复数据。请设计下游系统以处理此类情况。
预留限制
- 您必须创建企业版或企业 Plus 版预留,才能运行持续查询。持续查询不支持按需计算结算模式。
- 创建
CONTINUOUS预留分配时,关联的预留最多只能有 500 个槽。您可以通过联系 bq-continuous-queries-feedback@google.com 申请提高此上限。 - 您无法创建在同一预留中使用与持续查询预留分配不同的作业类型的预留分配。
- 您无法配置持续查询并发。BigQuery 会根据使用
CONTINUOUS作业类型的可用预留分配,自动确定可以并发运行的持续查询的数量。 - 使用同一预留运行多个持续查询时,单个作业可能无法公平地拆分可用资源(由 BigQuery 公平性定义)。
槽自动扩缩
连续查询可以使用槽自动扩缩来动态扩缩分配的容量,以满足您的工作负载需求。随着持续查询工作负载的增加或减少,BigQuery 会动态地调整槽。
连续查询开始运行后,它会主动监听传入的数据,这会消耗槽资源。虽然包含正在运行的持续查询的预留不会缩减到零个槽,但主要监听传入数据的空闲持续查询预计会占用最少数量的槽,通常约为 1 个槽。
空闲槽共享
持续查询可以使用空闲槽共享与其他预留和作业类型共享未使用的槽资源。
- 运行持续查询仍需要
CONTINUOUS预留分配,而不能仅依赖于其他预留中的空闲槽。因此,CONTINUOUS预留分配需要非零槽基准或非零槽自动扩缩配置。 - 只有
CONTINUOUS预留分配中的空闲基准槽或承诺槽可共享。自动扩缩槽不能作为其他预留的空闲槽进行共享。
价格
持续查询使用 BigQuery 容量计算价格,以槽为单位。如需运行持续查询,您必须拥有使用企业版或企业 Plus 版的预留以及使用 CONTINUOUS 作业类型的预留分配。
其他 BigQuery 资源(例如数据注入和存储)的使用费用按 BigQuery 价格中显示的费率收取。
接收持续查询结果或在持续查询处理期间被调用的其他服务的使用,将按照针对这些服务发布的费率收费。如需了解持续查询使用的其他 Google Cloud 服务的价格,请参阅以下主题:
后续步骤
尝试创建持续查询。