SQL クエリを使用してデータを検索する際に、Spanner では、データ取得の効率向上する可能性のあるセカンダリ インデックスがある場合、それが自動的に使用されます。ただし、Spanner によって、クエリの処理速度が低下するインデックスが選択されることがあります。その結果、クエリの実行速度が以前よりも低下したと気付くことがあります。
このページでは、クエリの実行速度の変化を検出する方法と、それらのクエリのクエリ実行プランを検査する方法、必要に応じて将来のクエリのために別のインデックスを指定する方法について説明します。
クエリ実行速度の変化を検出する
次のいずれかの変更を加えた後に、クエリの実行速度が変化する可能性が最も高くなります。
- セカンダリ インデックスを持つ大量の既存データに対する大幅な変更。
- セカンダリ インデックスの追加、変更、削除。
Spanner による実行が通常よりも遅い特定のクエリを識別するために、いくつかのツールを使用できます。
- Query Insights とクエリ統計。
Cloud Monitoring で取得して分析するアプリケーション固有の指標。たとえば、クエリの数の指標をモニタリングすると、インスタンスでのクエリ数の推移を確認し、クエリの実行に使用されたクエリ オプティマイザーのバージョンを確認することができます。
アプリケーションのパフォーマンスを測定するクライアント側のモニタリング ツール。
新しいデータベースに関する注意事項
新しく挿入されたデータまたはインポートされたデータを使用して、新しく作成されたデータベースにクエリを実行する場合、Spanner は、最適なインデックスを選択しない場合があります。クエリ オプティマイザーがオプティマイザーの統計情報を自動的に収集するのに最大 3 日かかるためです。これよりも早く、新しい Spanner データベースのインデックスの使用を最適化するには、新しい統計パッケージを手動で作成します。
スキーマを確認する
速度が低下したクエリを見つけた後、そのクエリの SQL ステートメントを参照し、ステートメントで使用されているテーブルと、それらのテーブルから取得される列を特定します。
次に、これらのテーブルのために存在するセカンダリ インデックスを見つけます。それらのインデックスに、クエリ対象の列が含まれている、つまり、Spanner がクエリを処理するためにそのインデックスのいずれかを使用するかどうかを判断します。
- 該当するインデックスがある場合は、次のステップとして、Spanner がクエリに使用したインデックスを見つけます。
該当するインデックスがない場合、
gcloud spanner operations listコマンドを使用して、該当するインデックスを最近削除したかどうかを確認します。gcloud spanner operations list \ --instance=INSTANCE \ --database=DATABASE \ --filter="@TYPE:UpdateDatabaseDdlMetadata"該当するインデックスを削除した場合、その変更がクエリのパフォーマンスに影響している可能性があります。セカンダリ インデックスをテーブルに追加し直します。インデックスが追加されたら、再度クエリを実行して、パフォーマンスを確認します。パフォーマンスが改善されない場合は、次のステップとして、Spanner によってクエリに使用されたインデックスを見つけます。
該当するインデックスを削除しなかった場合、索引の選択はクエリのパフォーマンスの低下の原因ではありません。パフォーマンスに影響する可能性のある、データや使用パターンに対するその他の変更を探します。
クエリに使用されているインデックスを見つける
Spanner によってクエリの処理に使用されているインデックスを見つけるには、 Google Cloud コンソールのクエリ実行プランを参照します。
Google Cloud コンソールの [Spanner インスタンス] ページに移動します。
クエリの対象とするインスタンスの名前をクリックします。
左側のペインで、クエリするデータベースをクリックして、[ Spanner Studio] をクリックします。
テストするクエリを入力します。
[クエリを実行] プルダウン リストで、[説明のみ] を選択します。Spanner にクエリプランが表示されます。
クエリプランで次の演算子を少なくとも 1 つ探します。
- テーブル スキャン
- インデックス スキャン
- クロス適用または分散クロス適用
以降のセクションでは、各演算子の意味について説明します。
テーブル スキャン演算子
テーブル スキャン演算子は、Spanner がセカンダリ インデックスを使用しなかったことを示します。
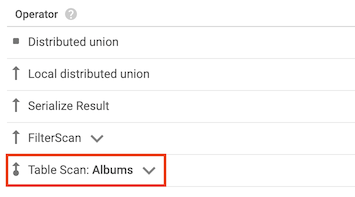
たとえば、Albums テーブルにセカンダリ インデックスがなく、次のクエリを実行するとします。
SELECT AlbumTitle FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
使用するインデックスがないため、クエリプランにはテーブル スキャン演算子が含まれます。
インデックス スキャン演算子
インデックス スキャン演算子は、Spanner がクエリを処理したとき、セカンダリ インデックスを使用したことを示します。
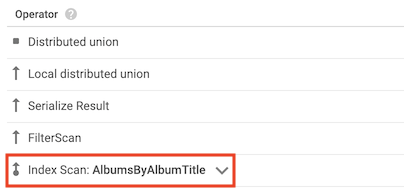
たとえば、インデックスを Albums テーブルに追加するとします。
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
その後、次のクエリを実行します。
SELECT AlbumTitle FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
AlbumsByAlbumTitle インデックスに含まれる AlbumTitle は、クエリによって選択される唯一の列です。その結果、クエリプランにはインデックス スキャン演算子が含まれます。
クロス適用演算子
場合によっては、クエリで選択される列の一部のみを含むインデックスが Spanner によって使用されます。そのため、Spanner では、インデックスをベーステーブルと結合することが必要となります。
このタイプの結合が発生すると、クエリプランには、次の入力を持つクロス適用か分散クロス適用演算子が含まれます。
- テーブルのインデックスのインデックス スキャン演算子
- インデックスを所有するテーブルのテーブル スキャン演算子
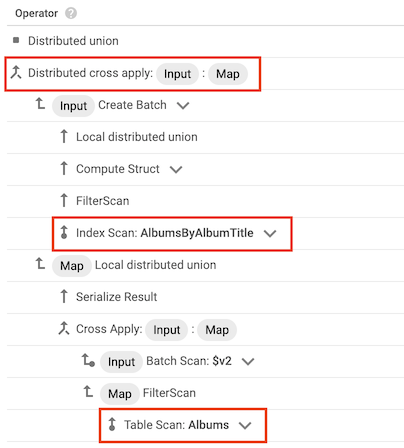
たとえば、インデックスを Albums テーブルに追加するとします。
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
その後、次のクエリを実行します。
SELECT * FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
AlbumsByAlbumTitle インデックスには AlbumTitle が含まれますが、クエリでは、AlbumTitle だけでなく、テーブルのすべての列を選択します。そのため、クエリプランには、AlbumsByAlbumTitle のインデックス スキャンと Albums のテーブル スキャンを入力とする、分散クロス適用演算子が含まれます。
別のインデックスを選択する
Spanner で使用した索引を見つけた後、別の索引を使用するか、索引を使用せずにベーステーブルをスキャンして、クエリを実行してみます。インデックスを指定するには、クエリに FORCE_INDEX ディレクティブを追加します。
より速いバージョンのクエリが見つかった場合は、より速いバージョンを使用するようにアプリケーションを更新します。
インデックスの選択に関するガイドライン
クエリでテストするインデックスを決定する場合は、次のガイドラインを使用します。
クエリが次のいずれかの条件を満たしている場合は、セカンダリ インデックスではなく、ベーステーブルを使用してみます。
- クエリで、ベーステーブルの主キーのプレフィックスと等しいかどうかを確認します(たとえば、
SELECT * FROM Albums WHERE SingerId = 1)。 - クエリの述語を満たす行が多数あります(たとえば、
SELECT * FROM Albums WHERE AlbumTitle != "There Is No Album With This Title")。 - クエリで、数百行のみが含まれるベーステーブルを使用します。
- クエリで、ベーステーブルの主キーのプレフィックスと等しいかどうかを確認します(たとえば、
クエリに非常に選択的な述語(
REGEXP_CONTAINS、STARTS_WITH、<、<=、>、>=、!=など)が含まれている場合、述語で使用されているものと同じ列を含むインデックスを使用してみてください。
更新されたクエリをテストする
Google Cloud コンソールを使用して、更新されたクエリをテストし、クエリの処理にかかる時間を確認します。
クエリにクエリ パラメータが含まれ、あるクエリ パラメータが一部の値に対して他の値よりも頻繁にバインドされている場合は、そのいずれかの値をクエリ パラメータにバインドしてテストします。たとえば、クエリに WHERE country = @countryId のような述語が含まれ、ほとんどすべてのクエリで @countryId が値 US にバインドされている場合は、@countryId を US にバインドしてパフォーマンスをテストします。このアプローチは、最も頻繁に実行するクエリの最適化に役立ちます。
Google Cloud コンソールで更新されたクエリをテストするには、次の操作を行います。
Google Cloud コンソールの [Spanner インスタンス] ページに移動します。
クエリの対象とするインスタンスの名前をクリックします。
左側のペインで、クエリするデータベースをクリックして、[ Spanner Studio] をクリックします。
テストするクエリに
FORCE_INDEXディレクティブを含めて入力し、[クエリを実行] をクリックします。Google Cloud コンソールで [結果表] タブが開き、Spanner サービスでクエリを処理するためにかかった時間などのクエリ結果が表示されます。
この指標には、 Google Cloud コンソールがクエリ結果を解釈して表示するのにかかった時間など、他のレイテンシのソースは含まれません。
REST API を使用して JSON 形式でクエリの詳細なプロファイルを取得する
デフォルトでは、クエリを実行すると、ステートメントの結果のみが返されます。これは、QueryMode が NORMAL に設定されているためです。詳細な実行統計をクエリ結果に含めるには、QueryMode を PROFILE に設定します。
セッションを作成する
クエリモードを更新する前に、Spanner データベース サービスとの通信チャネルを表すセッションを作成してください。
projects.instances.databases.sessions.createをクリックします。プロジェクト、インスタンス、データベース ID を次の形式で指定します。
projects/[\PROJECT_ID\]/instances/[\INSTANCE_ID\]/databases/[\DATABASE_ID\][実行] をクリックします。レスポンスには、作成したセッションが以下の形式で示されます。
projects/[\PROJECT_ID\]/instances/[\INSTANCE_ID\]/databases/[\DATABASE_ID\]/sessions/[\SESSION\]次のステップで、これを使用してクエリ プロファイルを実行します。作成されたセッションは、次に使用されるまで最大 1 時間維持され、その後、データベースによって削除されます。
クエリのプロファイル
クエリの PROFILE モードを有効にします。
projects.instances.databases.sessions.executeSqlをクリックします。[session] には前のステップで作成したセッション ID を入力します。
projects/[PROJECT_ID]/instances/[INSTANCE_ID]/databases/[DATABASE_ID]/sessions/[SESSION][リクエストの本文] で以下のように入力します。
{ "sql": "[YOUR_SQL_QUERY]", "queryMode": "PROFILE" }[実行] をクリックします。返されるレスポンスには、クエリ結果、クエリプラン、クエリの実行統計が含まれます。