Wie in Abfrageausführungspläne beschrieben, transformiert der SQL-Compiler eine SQL-Anweisung in einen Abfrageausführungsplan, der verwendet wird, um die Ergebnisse der Abfrage zu erhalten. Auf dieser Seite werden Best Practices zum Erstellen von SQL-Anweisungen beschrieben. Sie helfen Spanner dabei, effiziente Ausführungspläne zu finden.
Die Beispiel-SQL-Anweisungen auf dieser Seite verwenden das folgende Beispielschema:
GoogleSQL
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY (SingerId);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
ReleaseDate DATE
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
Die vollständige SQL-Referenz finden Sie unter Anweisungssyntax, Funktionen und Operatoren und Lexikalische Struktur und Syntax.
PostgreSQL
CREATE TABLE Singers (
SingerId BIGINT PRIMARY KEY,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
SingerInfo BYTEA,
BirthDate TIMESTAMPTZ
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY(SingerId, AlbumId),
FOREIGN KEY (SingerId) REFERENCES Singers(SingerId)
) INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
Weitere Informationen finden Sie unter PostgreSQL-Sprache in Spanner.
Abfrageparameter verwenden
Spanner unterstützt Abfrageparameter, um die Leistung zu steigern und SQL-Injection zu verhindern, wenn Abfragen über Nutzereingaben erstellt werden. Sie können Abfrageparameter als Ersatz für beliebige Ausdrücke verwenden, aber nicht als Ersatz für Kennzeichnungen, Spaltennamen, Tabellennamen oder andere Teile der Abfrage.
Parameter können überall dort vorkommen, wo ein Literalwert erwartet wird. Derselbe Parametername kann mehrmals in einer einzelnen SQL-Anweisung verwendet werden.
Zusammenfassend haben Abfrageparameter folgende Vorteile für die Abfrageausführung:
- Voroptimierte Pläne: Abfragen, die Parameter verwenden, können bei jedem Aufruf schneller ausgeführt werden, da Spanner durch die Parametrisierung den Ausführungsplan besser zwischenspeichern kann.
- Vereinfachte Abfragezusammensetzung: Sie müssen Stringwerte nicht ausschließen, wenn Sie sie in Abfrageparametern bereitstellen. Abfrageparameter verringern auch das Risiko von Syntaxfehlern.
- Sicherheit: Abfrageparameter machen Abfragen sicherer, da sie Sie vor verschiedenen SQL-Injection-Angriffen schützen. Dieser Schutz ist besonders wichtig für Abfragen, die Sie aus Nutzereingaben erstellen.
So werden Abfragen von Spanner ausgeführt
Mit Spanner können Sie Datenbanken mithilfe deklarativer SQL-Anweisungen abfragen, die angeben, welche Daten abgerufen werden sollen. Wenn Sie wissen möchten, wie Spanner die Ergebnisse erhält, sehen Sie sich den Ausführungsplan für die Abfrage an. Ein Abfrageausführungsplan zeigt die mit jedem Schritt der Abfrage verbundenen Berechnungskosten an. Mit diesen Kosten können Sie Leistungsprobleme bei Abfragen beheben und Ihre Abfrage optimieren. Weitere Informationen finden Sie unter Abfrage-Ausführungspläne.
Sie können Abfrageausführungspläne über die Google Cloud Console oder die Clientbibliotheken abrufen.
So rufen Sie einen Abfrageausführungsplan für eine bestimmte Abfrage mit der Google Cloud Console ab:
Öffnen Sie die Seite „Spanner-Instanzen“.
Wählen Sie die Namen der Spanner-Instanz und der Datenbank aus, die Sie abfragen möchten.
Klicken Sie im linken Navigationsbereich auf Spanner Studio.
Geben Sie die Abfrage in das Textfeld ein und klicken Sie auf Abfrage ausführen.
Klicken Sie auf Erläuterung
. Die Google Cloud Console zeigt einen visuellen Ausführungsplan für die Abfrage an.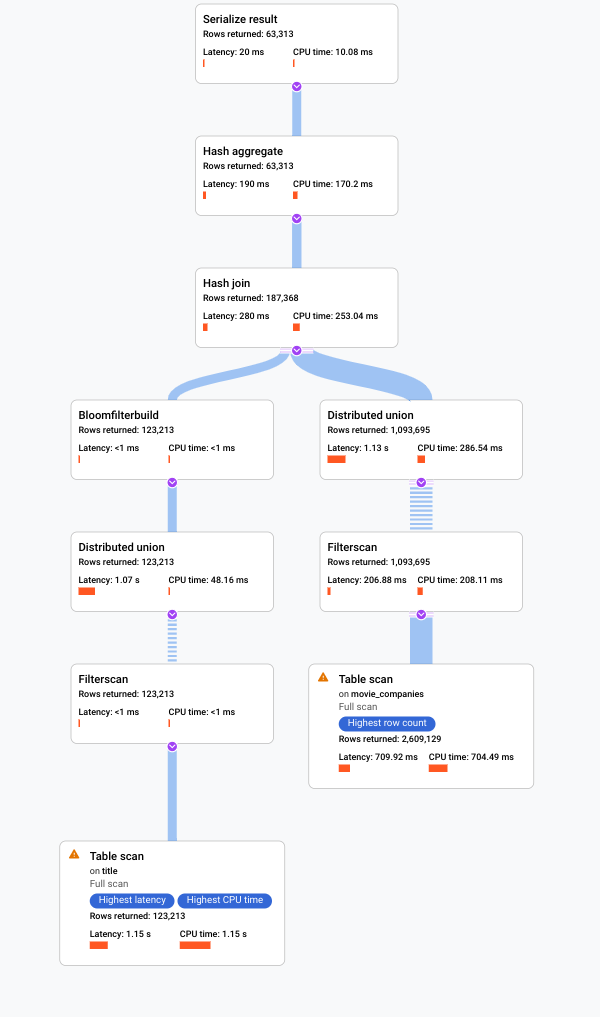
Weitere Informationen zu visuellen Plänen und zur Fehlerbehebung mithilfe dieser Pläne finden Sie unter Abfrage mit dem Abfrageplanervisualisierer abstimmen.
Sie können sich auch Beispiele für Verlaufsabfragepläne ansehen und die Leistung einer Abfrage im Zeitverlauf für bestimmte Abfragen vergleichen. Weitere Informationen finden Sie unter Abgetastete Abfragepläne.
Sekundäre Indexe verwenden
Wie andere relationale Datenbanken bietet Spanner sekundäre Indexe, mit denen Sie Daten entweder mithilfe einer SQL-Anweisung oder mithilfe der Leseoberfläche von Spanner abrufen können. Die gängigere Methode zum Abrufen von Daten aus einem Index ist die Verwendung von Spanner Studio. Mit einem sekundären Index in einer SQL-Abfrage können Sie angeben, wie Spanner die Ergebnisse erhalten soll. Das Angeben eines sekundären Index kann die Ausführung von Abfragen beschleunigen.
Angenommen, Sie möchten die IDs aller Sänger mit einem bestimmten Nachnamen abrufen. Hier ist eine Möglichkeit, eine solche SQL-Abfrage zu schreiben:
SELECT s.SingerId
FROM Singers AS s
WHERE s.LastName = 'Smith';
Diese Abfrage würde die erwarteten Ergebnisse zurückgeben. Es kann jedoch lange dauern. Die Dauer hängt von der Anzahl der Zeilen in der Tabelle Singers ab und davon, wie viele das Prädikat WHERE s.LastName = 'Smith' erfüllen. Wenn es keinen sekundären Index gibt, der die Spalte LastName enthält, aus der gelesen werden soll, liest der Abfrageplan die gesamte Tabelle Singers, um Zeilen zu finden, die mit dem Prädikat übereinstimmen. Das Lesen der gesamten Tabelle wird als vollständiger Tabellenscan bezeichnet. Das ist eine teure Methode, um die Ergebnisse zu erhalten, wenn die Tabelle nur einen kleinen Anteil von Singers mit diesem Nachnamen enthält.
Sie können die Leistung dieser Abfrage verbessern, wenn Sie einen sekundären Index für die Nachname-Spalte definieren:
CREATE INDEX SingersByLastName ON Singers (LastName);
Da der sekundäre Index SingersByLastName die indexierte Tabellenspalte LastName und die Primärschlüsselspalte SingerId enthält, kann Spanner alle Daten aus der wesentlich kleineren Indextabelle abrufen, ohne die gesamte Tabelle Singers scannen zu müssen.
In diesem Szenario verwendet Spanner automatisch den sekundären Index SingersByLastName während der Ausführung der Abfrage (sofern drei Tage seit der Datenbankerstellung vergangen sind; siehe Hinweis zu neuen Datenbanken). Als Best Practice hat es sich jedoch bewährt, Spanner diesen Index explizit anzugeben. Legen Sie dazu in der Klausel FROM eine Indexanweisung fest:
GoogleSQL
SELECT s.SingerId
FROM Singers@{FORCE_INDEX=SingersByLastName} AS s
WHERE s.LastName = 'Smith';
PostgreSQL
SELECT s.SingerId
FROM Singers /*@ FORCE_INDEX=SingersByLastName */ AS s
WHERE s.LastName = 'Smith';
Beispiel: Sie wollten neben der ID auch den Vornamen des Sängers abrufen. Auch wenn die Spalte FirstName nicht im Index enthalten ist, sollten Sie die Indexanweisung wie zuvor angeben:
GoogleSQL
SELECT s.SingerId, s.FirstName
FROM Singers@{FORCE_INDEX=SingersByLastName} AS s
WHERE s.LastName = 'Smith';
PostgreSQL
SELECT s.SingerId, s.FirstName
FROM Singers /*@ FORCE_INDEX=SingersByLastName */ AS s
WHERE s.LastName = 'Smith';
Sie erhalten immer noch einen Leistungsvorteil bei der Verwendung des Index, da Spanner beim Ausführen des Abfrageplans keinen vollständigen Tabellenscan machen muss. Stattdessen wählt es die Teilmenge der Zeilen aus, die die Bedingung aus dem Index SingersByLastName erfüllen, und führt dann einen Suchvorgang aus der Basistabelle Singers aus, um den ersten Namen nur für diese Teilmenge von Zeilen abzurufen.
Wenn Sie vermeiden möchten, dass Spanner überhaupt Zeilen aus der Basistabelle abrufen muss, können Sie eine Kopie der FirstName-Spalte im Index selbst speichern:
GoogleSQL
CREATE INDEX SingersByLastName ON Singers (LastName) STORING (FirstName);
PostgreSQL
CREATE INDEX SingersByLastName ON Singers (LastName) INCLUDE (FirstName);
Die Verwendung einer STORING-Klausel (für den GoogleSQL-Dialekt) oder einer INCLUDE-Klausel (für den PostgreSQL-Dialekt) kostet zwar zusätzlichen Speicher, bietet jedoch die folgenden Vorteile:
- SQL-Abfragen, die den Index verwenden und in der Klausel
STORINGoderINCLUDEgespeicherte Spalten auswählen, benötigen keine zusätzliche Verknüpfung mit der Basistabelle. - Leseaufrufe, die den Index verwenden, können in der Klausel
STORINGoderINCLUDEgespeicherte Spalten lesen.
Die Beispiele oben zeigen, wie sekundäre Indexe Abfragen beschleunigen können, wenn die von der WHERE-Klausel einer Abfrage ausgewählten Zeilen mit dem sekundären Index schnell identifiziert werden können.
Ein weiteres Szenario, in dem sekundäre Indexe Leistungsvorteile bieten können, sind bestimmte Abfragen, die geordnete Ergebnisse zurückgeben. Angenommen, Sie möchten alle Albumtitel und ihre Veröffentlichungsdaten aufsteigend nach Veröffentlichungsdatum und absteigend nach Albumtitel abrufen. So könnten Sie eine SQL-Abfrage schreiben:
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums AS a
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
Ohne einen sekundären Index erfordert diese Abfrage möglicherweise einen teuren Sortierschritt im Ausführungsplan. Sie können die Abfrageausführung beschleunigen, wenn Sie diesen sekundären Index definieren:
CREATE INDEX AlbumsByReleaseDateTitleDesc on Albums (ReleaseDate, AlbumTitle DESC);
Schreiben Sie die Abfrage dann neu, um den sekundären Index zu verwenden:
GoogleSQL
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums@{FORCE_INDEX=AlbumsByReleaseDateTitleDesc} AS a
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
PostgreSQL
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums /*@ FORCE_INDEX=AlbumsByReleaseDateTitleDesc */ AS s
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
Diese Abfrage und diese Indexdefinition erfüllen die folgenden zwei Kriterien:
- Wenn Sie den Sortierschritt entfernen möchten, muss die Spaltenliste in der
ORDER BY-Klausel ein Präfix der Indexschlüsselliste sein. - Damit nicht noch einmal von der Basistabelle aus verknüpft werden muss, um fehlende Spalten abzurufen, muss der Index alle Spalten in der Tabelle abdecken, die in der Abfrage verwendet werden.
Sekundäre Indizes können häufige Abfragen beschleunigen. Das Hinzufügen von sekundären Indizes kann jedoch zu Verzögerungen bei den Commit-Vorgängen führen, da für jeden sekundären Index in der Regel ein zusätzlicher Knoten bei jedem Commit erforderlich ist. Bei den meisten Arbeitslasten ist es ausreichend, einige wenige sekundäre Indizes zu haben. Sie sollten jedoch überlegen, ob Ihnen Leselatenz oder Schreiblatenz wichtiger ist und welche Vorgänge für Ihre Arbeitslast am wichtigsten sind. Sie sollten auch die Arbeitslast messen, damit sie tatsächlich erwartungsgemäß funktioniert.
Die vollständige Referenz zu sekundären Indexen finden Sie unter Sekundäre Indexe.
Scans optimieren
Bei bestimmten Spanner-Abfragen kann es vorteilhaft sein, beim Scannen von Daten eine batchorientierte Verarbeitungsmethode anstelle der gängigen zeilenorientierten Verarbeitungsmethode zu verwenden. Die Verarbeitung von Scans in Batches ist eine effizientere Methode, um große Datenmengen gleichzeitig zu verarbeiten. Außerdem können so die CPU-Auslastung und die Latenz bei Abfragen gesenkt werden.
Der Spanner-Scanvorgang beginnt die Ausführung immer mit der zeilenorientierten Methode. Während dieser Zeit erfasst Spanner mehrere Laufzeitmesswerte. Anschließend wendet Spanner eine Reihe von Heuristiken an, die auf dem Ergebnis dieser Messwerte basieren, um die optimale Suchmethode zu ermitteln. Gegebenenfalls wechselt Spanner zu einer batchorientierten Verarbeitungsmethode, um den Scandurchsatz und die Leistung zu verbessern.
Gängige Anwendungsfälle
Bei Abfragen mit den folgenden Merkmalen ist die batchorientierte Verarbeitung im Allgemeinen vorteilhaft:
- Große Scans über selten aktualisierte Daten.
- Scans mit Prädikaten in Spalten mit fester Breite.
- Scans mit einer großen Anzahl von Suchvorgängen. Bei einer Suche wird ein Index verwendet, um Einträge abzurufen.
Anwendungsfälle ohne Leistungssteigerung
Nicht alle Abfragen profitieren von der batchorientierten Verarbeitung. Bei den folgenden Abfragetypen ist die Leistung bei der zeilenorientierten Scanverarbeitung höher:
- Punktabfrage: Abfragen, bei denen nur eine Zeile abgerufen wird.
- Kleine Scanabfragen: Tabellenscans, bei denen nur wenige Zeilen gescannt werden, es sei denn, die Anzahl der Suchvorgänge ist hoch.
- Abfragen, bei denen
LIMITverwendet wird. - Abfragen mit vielen Daten zum Kundenabbruch: Bei diesen Abfragen werden mehr als 10% der gelesenen Daten häufig aktualisiert.
- Abfragen mit Zeilen mit großen Werten: Zeilen mit großen Werten enthalten Werte,die größer als 32.000 Byte (vor der Komprimierung) in einer einzelnen Spalte sind.
Scanmethode einer Abfrage prüfen
So prüfen Sie, ob für Ihre Abfrage die batchorientierte Verarbeitung, die zeilenorientierte Verarbeitung oder der automatische Wechsel zwischen den beiden Scanmethoden verwendet wird:
Rufen Sie in derGoogle Cloud Console die Seite Spanner-Instanzen auf.
Klicken Sie auf den Namen der Instanz mit der Abfrage, die Sie untersuchen möchten.
Klicken Sie in der Tabelle „Datenbanken“ auf die Datenbank mit der Abfrage, die Sie untersuchen möchten.
Klicken Sie im Navigationsmenü auf Spanner Studio.
Öffnen Sie einen neuen Tab, indem Sie auf Neuer SQL-Editor-Tab oder Neuer Tab klicken.
Schreiben Sie Ihre Abfrage, sobald der Abfrageeditor angezeigt wird.
Klicken Sie auf Ausführen.
Spanner führt die Abfrage aus und zeigt die Ergebnisse an.
Klicken Sie unter dem Abfrageeditor auf den Tab Erläuterung.
Spanner bietet eine Visualisierung des Abfrageausführungsplans. Jede Karte im Diagramm stellt einen Iterator dar.
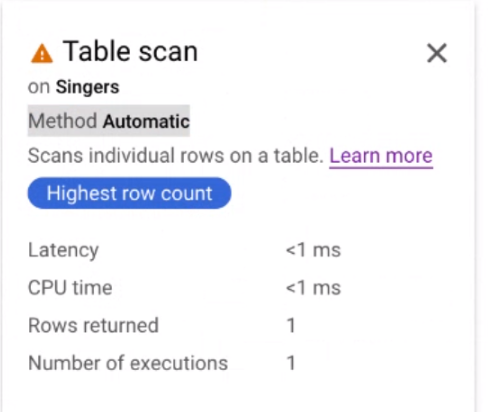
Klicken Sie auf die Karte „Tabellenscan“, um ein Infofeld zu öffnen.
Der Infobereich enthält Kontextinformationen zum ausgewählten Scan. Die Scanmethode wird auf dieser Karte angezeigt. Automatisch gibt an, dass Spanner die Scanmethode bestimmt. Weitere mögliche Werte sind Batch für die batchorientierte Verarbeitung und Zeile für die zeilenorientierte Verarbeitung.
Von einer Abfrage verwendete Scanmethode erzwingen
Um die Abfrageleistung zu optimieren, wählt Spanner die optimale Suchmethode für Ihre Abfrage aus. Wir empfehlen, diese Standard-Scanmethode zu verwenden. Es kann jedoch Fälle geben, in denen Sie eine bestimmte Art der Scanmethode erzwingen möchten.
Batchorientiertes Scannen erzwingen
Sie können das batchorientierte Scannen auf Tabellen- und Anweisungsebene erzwingen.
Wenn Sie die batchorientierte Scanmethode auf Tabellenebene erzwingen möchten, verwenden Sie in Ihrer Abfrage einen Tabellenhinweis:
GoogleSQL
SELECT ...
FROM (t1@{SCAN_METHOD=BATCH} JOIN t2 ON ...)
WHERE ...
PostgreSQL
SELECT ...
FROM (t1/*@ scan_method=batch */ JOIN t2 on ...)
WHERE ...
Wenn Sie die batchorientierte Scanmethode auf Anweisungsebene erzwingen möchten, verwenden Sie in Ihrer Abfrage einen Anweisungshinweis:
GoogleSQL
@{SCAN_METHOD=BATCH}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ scan_method=batch */
SELECT ...
FROM ...
WHERE ...
Automatisches Scannen deaktivieren und zeilenorientiertes Scannen erzwingen
Wir empfehlen zwar nicht, die von Spanner festgelegte automatische Scanmethode zu deaktivieren, Sie können sie aber deaktivieren und die zeilenorientierte Scanmethode zur Fehlerbehebung verwenden, z. B. zur Diagnose von Latenz.
Wenn Sie die automatische Scanmethode deaktivieren und die Zeilenverarbeitung auf Tabellenebene erzwingen möchten, verwenden Sie in Ihrer Abfrage einen Tabellenhinweis:
GoogleSQL
SELECT ...
FROM (t1@{SCAN_METHOD=ROW} JOIN t2 ON ...)
WHERE ...
PostgreSQL
SELECT ...
FROM (t1/*@ scan_method=row */ JOIN t2 on ...)
WHERE ...
Wenn Sie die automatische Scanmethode deaktivieren und die Zeilenverarbeitung auf Anweisungsebene erzwingen möchten, verwenden Sie einen Anweisungshinweis in Ihrer Abfrage:
GoogleSQL
@{SCAN_METHOD=ROW}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ scan_method=row */
SELECT ...
FROM ...
WHERE ...
Abfrageausführung optimieren
Sie können nicht nur Scans optimieren, sondern auch die Abfrageausführung, indem Sie die Ausführungsmethode auf Anweisungsebene erzwingen. Dies funktioniert nur für einige Operatoren und ist unabhängig von der Scanmethode, die nur vom Scanoperator verwendet wird.
Standardmäßig werden die meisten Operatoren mit der zeilenorientierten Methode ausgeführt, bei der die Daten zeilenweise verarbeitet werden. Vektorisierte Operatoren werden mit der batchorientierten Methode ausgeführt, um den Durchsatz und die Leistung der Ausführung zu verbessern. Diese Operatoren verarbeiten Daten jeweils blockweise. Wenn ein Operator viele Zeilen verarbeiten muss, ist die batchorientierte Ausführungsmethode in der Regel effizienter.
Ausführungsmethode und Scanmethode
Die Abfrageausführungsmethode ist unabhängig von der Abfrage-Scanmethode. Sie können eine, beide oder keine dieser Methoden in Ihrem Abfragehinweis festlegen.
Die Abfrageausführungsmethode bezieht sich darauf, wie Abfrageoperatoren Zwischenergebnisse verarbeiten und wie die Operatoren miteinander interagieren. Die Scanmethode bezieht sich darauf, wie der Scanoperator mit der Speicherschicht von Spanner interagiert.
Ausführungsmethode der Abfrage erzwingen
Zur Optimierung der Abfrageleistung wählt Spanner anhand verschiedener Heuristiken die optimale Ausführungsmethode für Ihre Abfrage aus. Wir empfehlen, diese Standardausführungsmethode zu verwenden. Es kann jedoch Fälle geben, in denen Sie eine bestimmte Ausführungsmethode erzwingen möchten.
Sie können die Ausführungsmethode auf Anweisungsebene erzwingen. EXECUTION_METHOD ist kein Befehl, sondern ein Abfragehinweis. Letztendlich entscheidet der Abfrageoptimierer, welche Methode für jeden einzelnen Operator verwendet werden soll.
Wenn Sie die batchorientierte Ausführungsmethode auf Anweisungsebene erzwingen möchten, verwenden Sie in Ihrer Abfrage einen Anweisungshinweis:
GoogleSQL
@{EXECUTION_METHOD=BATCH}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ execution_method=batch */
SELECT ...
FROM ...
WHERE ...
Wir empfehlen zwar nicht, die von Spanner festgelegte automatische Ausführungsmethode zu deaktivieren, Sie können sie aber deaktivieren und die zeilenorientierte Ausführungsmethode für die Fehlerbehebung verwenden, z. B. zur Diagnose von Latenz.
Wenn Sie die automatische Ausführungsmethode deaktivieren und die zeilenorientierte Ausführungsmethode auf Anweisungsebene erzwingen möchten, verwenden Sie einen Anweisungshinweis in Ihrer Abfrage:
GoogleSQL
@{EXECUTION_METHOD=ROW}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ execution_method=row */
SELECT ...
FROM ...
WHERE ...
Prüfen, welche Ausführungsmethode aktiviert ist
Nicht alle Spanner-Operatoren unterstützen sowohl batchorientierte als auch zeilenorientierte Ausführungsmethoden. Im Visualisierungstool für Abfrageausführungspläne wird für jeden Operator die Ausführungsmethode auf der Iteratorkarte angezeigt. Wenn die Ausführungsmethode batchorientiert ist, wird Batch angezeigt. Bei zeilenorientierter Ausrichtung wird Zeile angezeigt.
Wenn die Operatoren in Ihrer Abfrage mit unterschiedlichen Ausführungsmethoden ausgeführt werden, werden die Adapter für die Ausführungsmethode DataBlockToRowAdapter und RowToDataBlockAdapter zwischen den Operatoren angezeigt, um die Änderung der Ausführungsmethode zu verdeutlichen.
Suchanfragen für Bereichsschlüssel optimieren
Die SQL-Abfrage wird häufig dafür verwendet, basierend auf einer Liste bekannter Schlüssel mehrere Zeilen aus Spanner zu lesen.
Die folgenden Best Practices helfen Ihnen, effiziente Abfragen zu schreiben, wenn Sie Daten nach einer Reihe von Schlüsseln abrufen:
Wenn die Liste der Schlüssel kurz ist und keine benachbarten Schlüssel enthält, verwenden Sie Abfrageparameter und
UNNESTzur Erstellung der Abfrage.Wenn die Schlüsselliste beispielsweise
{1, 5, 1000}lautet, schreiben Sie die Abfrage so:GoogleSQL
SELECT * FROM Table AS t WHERE t.Key IN UNNEST (@KeyList)
PostgreSQL
SELECT * FROM Table AS t WHERE t.Key IN UNNEST ($1)
Hinweise:
Der Operator Array UNNEST vereinfacht ein Eingabe-Array so, dass es in Zeilen von Elementen vorliegt.
Der Abfrageparameter,
@KeyListfür GoogleSQL und$1für PostgreSQL, kann die Abfrage beschleunigen, wie in der vorangehenden Best Practice beschrieben.
Wenn die Liste der Schlüssel benachbarte Schlüssel enthält und innerhalb eines Bereichs liegt, geben Sie die untere und obere Grenze des Schlüsselbereichs in der Klausel
WHEREan.Wenn die Schlüsselliste beispielsweise
{1,2,3,4,5}lautet, erstellen Sie die Abfrage so:GoogleSQL
SELECT * FROM Table AS t WHERE t.Key BETWEEN @min AND @max
PostgreSQL
SELECT * FROM Table AS t WHERE t.Key BETWEEN $1 AND $2
Diese Abfrage ist nur effizienter, wenn die Schlüssel im Schlüsselbereich benachbart sind. Mit anderen Worten, wenn Ihre Schlüsselliste
{1, 5, 1000}ist, sollten Sie die unteren und oberen Grenzen nicht wie in der obigen Abfrage angeben, da die resultierende Abfrage jeden Wert zwischen 1 und 1.000 durchsuchen würde.
Joins optimieren
Join-Vorgänge können teuer sein, da sie die Anzahl der Zeilen, die Ihre Abfrage scannen muss, erheblich erhöhen können. Dies führt zu langsameren Abfragen. Zusätzlich zu den Methoden, die Sie in anderen relationalen Datenbanken zum Optimieren von Join-Abfragen verwenden, finden Sie hier einige Best Practices für einen effizienteren JOIN bei der Verwendung von Spanner SQL:
Verbinden Sie nach Möglichkeit Daten in verschränkten Tabellen mit dem Primärschlüssel. Beispiel:
SELECT s.FirstName, a.ReleaseDate FROM Singers AS s JOIN Albums AS a ON s.SingerId = a.SingerId;
Die Zeilen in der verschränkten Tabelle
Albumswerden in denselben Splits wie die übergeordnete Zeile inSingersgespeichert, wie in Schema und Datenmodell erläutert. Daher können Joins lokal abgeschlossen werden, ohne viele Daten über das Netzwerk zu senden.Verwenden Sie die Join-Anweisung, wenn Sie die Reihenfolge des Joins erzwingen möchten. Beispiel:
GoogleSQL
SELECT * FROM Singers AS s JOIN@{FORCE_JOIN_ORDER=TRUE} Albums AS a ON s.SingerId = a.Singerid WHERE s.LastName LIKE '%x%' AND a.AlbumTitle LIKE '%love%';
PostgreSQL
SELECT * FROM Singers AS s JOIN/*@ FORCE_JOIN_ORDER=TRUE */ Albums AS a ON s.SingerId = a.Singerid WHERE s.LastName LIKE '%x%' AND a.AlbumTitle LIKE '%love%';
Die Join-Anweisung
FORCE_JOIN_ORDERweist Spanner an, die in der Abfrage angegebene Join-Reihenfolge zu verwenden (d. h.Singers JOIN Albums, nichtAlbums JOIN Singers). Die zurückgegebenen Ergebnisse sind unabhängig von der Reihenfolge, die Spanner auswählt, identisch. Sie sollten diese Join-Anweisung allerdings verwenden, wenn Sie im Abfrageplan bemerken, dass Spanner die Join-Reihenfolge geändert und unerwünschte Konsequenzen verursacht hat, z. B. dass größere Zwischenergebnisse erzielt oder dass Gelegenheiten zum Suchen von Zeilen verpasst wurden.Wählen Sie mit einer Join-Anweisung eine Join-Implementierung aus. Wenn Sie mit SQL mehrere Tabellen abfragen, verwendet Spanner automatisch eine Join-Methode, durch die die Abfrage wahrscheinlich effizienter wird. Google empfiehlt jedoch, mit verschiedenen Join-Algorithmen zu testen. Wenn Sie den richtigen Join-Algorithmus auswählen, können Latenz, Speicherverbrauch oder beides verbessert werden. Diese Abfrage zeigt die Syntax für die Verwendung einer JOIN-Anweisung mit dem Hinweis
JOIN_METHODzum Auswählen einesHASH JOIN:GoogleSQL
SELECT * FROM Singers s JOIN@{JOIN_METHOD=HASH_JOIN} Albums AS a ON a.SingerId = a.SingerId
PostgreSQL
SELECT * FROM Singers s JOIN/*@ JOIN_METHOD=HASH_JOIN */ Albums AS a ON a.SingerId = a.SingerId
Wenn Sie einen
HASH JOINoderAPPLY JOINverwenden und eineWHERE-Klausel haben, die auf einer Seite IhresJOINsehr selektiv ist, legen Sie die Tabelle mit der geringsten Anzahl von Zeilen als erste Tabelle in derFROM-Klausel des Joins fest. Diese Struktur ist hilfreich, da Spanner inHASH JOINimmer die linke Tabelle als Build und die rechte Tabelle als Probe auswählt. Auf ähnliche Weise wählt Spanner fürAPPLY JOINdie linke Tabelle als Outer Join und die rechte Tabelle als Inner Join aus. Weitere Informationen zu diesen Join-Typen finden Sie unter Hash Join und Apply Join.Geben Sie für Abfragen, die für Ihre Arbeitslast wichtig sind, die leistungsstärkste Join-Methode und Join-Reihenfolge in Ihren SQL-Anweisungen an, um eine konsistente Leistung zu erzielen.
Abfragen mit Pushdown von Zeitstempelprädikaten optimieren
Die Pushdown-Optimierung von Zeitstempelprädikaten ist eine Abfrageoptimierungstechnik, die in Spanner verwendet wird, um die Effizienz von Abfragen zu verbessern, bei denen Zeitstempel und Daten mit einer altersbasierten Speicherebenen-Richtlinie verwendet werden. Wenn Sie diese Optimierung aktivieren, werden die Filtervorgänge für Zeitstempelspalten so früh wie möglich im Abfrageausführungsplan ausgeführt. Dadurch kann die Menge der verarbeiteten Daten erheblich reduziert und die Abfrageleistung insgesamt verbessert werden.
Bei der Pushdown-Behandlung von Zeitstempelprädikaten analysiert die Datenbank-Engine die Abfrage und identifiziert den Zeitstempelfilter. Dieser Filter wird dann an die Speicherebene „weitergeschoben“, sodass nur die relevanten Daten anhand der Zeitstempelkriterien vom SSD gelesen werden. Dadurch wird die Menge der verarbeiteten und übertragenen Daten minimiert, was zu einer schnelleren Abfrageausführung führt.
Damit Abfragen so optimiert werden, dass nur auf auf der SSD gespeicherte Daten zugegriffen wird, müssen folgende Voraussetzungen erfüllt sein:
- Für die Abfrage muss die Pushdown-Funktion für Zeitstempelprädikate aktiviert sein. Weitere Informationen finden Sie unter Hinweise zu GoogleSQL-Anweisungen und Hinweise zu PostgreSQL-Anweisungen.
- Die Abfrage muss eine altersbasierte Einschränkung verwenden, die dem in der Datenfreigaberichtlinie angegebenen Alter entspricht oder niedriger ist (mit der Option
ssd_to_hdd_spill_timespanin der DDL-AnweisungCREATE LOCALITY GROUPoderALTER LOCALITY GROUPfestgelegt). Weitere Informationen finden Sie unter GoogleSQL-LOCALITY GROUP-Anweisungen und PostgreSQL-LOCALITY GROUP-Anweisungen. Die in der Abfrage gefilterte Spalte muss eine Zeitstempelspalte sein, die den Commit-Zeitstempel enthält. Weitere Informationen zum Erstellen einer Commit-Zeitstempelspalte finden Sie unter Commit-Zeitstempel in GoogleSQL und Commit-Zeitstempel in PostgreSQL. Diese Spalten müssen zusammen mit der Zeitstempelspalte aktualisiert werden und sich in derselben Lokalitätsgruppe befinden, für die eine altersbasierte Speicherhierarchie gilt.
Wenn sich für eine bestimmte Zeile einige der abgefragten Spalten auf der SSD und einige auf der HDD befinden, weil Spalten zu unterschiedlichen Zeiten aktualisiert und zu unterschiedlichen Zeiten auf die HDD verschoben werden, ist die Leistung der Abfrage bei Verwendung des Hinweises möglicherweise geringer. Das liegt daran, dass die Abfrage Daten aus den verschiedenen Speicherebenen einfügen muss. Wenn Sie den Hinweis verwenden, altert Spanner die Daten auf Zellebene (Zeilen- und Spaltenebene) basierend auf dem Commit-Zeitstempel jeder Zelle, was die Abfrage verlangsamt. Um dieses Problem zu vermeiden, sollten Sie alle Spalten, die mit dieser Optimierungstechnik abgefragt werden, regelmäßig in derselben Transaktion aktualisieren, damit alle Spalten denselben Commit-Zeitstempel haben und von der Optimierung profitieren.
Wenn Sie die Pushdown-Optimierung von Zeitstempelprädikaten auf Anweisungsebene aktivieren möchten, verwenden Sie in Ihrer Abfrage einen Anweisungshinweis. Beispiel:
GoogleSQL
@{allow_timestamp_predicate_pushdown=TRUE}
SELECT s.SingerInfo
FROM Singers s
WHERE s.ModificationTime > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 12 HOUR);
PostgreSQL
/*@allow_timestamp_predicate_pushdown=TRUE*/
SELECT s.SingerInfo
FROM Singers s
WHERE s.ModificationTime > CURRENT_TIMESTAMP - INTERVAL '12 hours';
Große Lesevorgänge in Lese-Schreib-Transaktionen vermeiden
Lese-Schreib-Transaktionen ermöglichen eine Sequenz von null oder mehr Lesevorgängen oder SQL-Abfragen und können eine Reihe von Mutationen vor einem Aufruf zum Commit enthalten. Um die Konsistenz Ihrer Daten zu gewährleisten, erhält Spanner Sperren beim Lesen und Schreiben von Zeilen in Ihren Tabellen und Indexen. Weitere Informationen zu Sperrungen finden Sie unter Lebensdauer von Lese- und Schreibvorgängen.
Aufgrund der Funktionsweise von Sperren in Spanner führt das Ausführen einer Lese- oder SQL-Abfrage mit einer großen Anzahl von Zeilen (z. B. SELECT * FROM Singers) dazu, dass keine anderen Transaktionen in die gelesenen Zeilen schreiben können, bis Ihre Transaktion in einem Commit-Vorgang ausgeführt oder abgebrochen wird.
Da Ihre Transaktion eine große Anzahl von Zeilen verarbeitet, dauert sie wahrscheinlich länger als eine Transaktion, die einen kleinen Zeilenbereich liest (z. B.SELECT LastName FROM Singers WHERE SingerId = 7). Dadurch wird das Problem weiter verschärft und der Systemdurchsatz reduziert.
Daher sollten Sie große Lesevorgänge (z. B. vollständige Tabellenscans oder massive Verknüpfungsvorgänge) in Ihren Transaktionen vermeiden, es sei denn, Sie sind bereit, einen niedrigeren Schreibdurchsatz zu akzeptieren.
In einigen Fällen kann das folgende Muster bessere Ergebnisse liefern:
- Führen Sie die großen Lesevorgänge in einer schreibgeschützten Transaktion aus. Schreibgeschützte Transaktionen ermöglichen einen höheren Gesamtdurchsatz, da sie keine Sperren verwenden.
- Optional: Führen Sie alle erforderlichen Verarbeitungen für die gerade gelesenen Daten durch.
- Starten Sie eine Lese-Schreib-Transaktion.
- Prüfen Sie, ob sich die Werte der wichtigen Zeilen nicht geändert haben, seit Sie die schreibgeschützte Transaktion in Schritt 1 ausgeführt haben.
- Wenn sich die Zeilen geändert haben, führen Sie einen Rollback der Transaktion durch und beginnen Sie noch einmal bei Schritt 1.
- Wenn alles in Ordnung ist, können Sie einen Commit Ihrer Mutationen durchführen.
Sie können große Lesevorgänge in Lese-Schreib-Transaktionen vermeiden, wenn Sie sich die Ausführungspläne ansehen, die von Ihren Abfragen generiert werden.
Verwenden Sie ORDER BY, um die Reihenfolge Ihrer SQL-Ergebnisse sicherzustellen
Wenn Sie eine bestimmte Reihenfolge für die Ergebnisse einer SELECT-Abfrage erwarten, sollten Sie die ORDER BY-Klausel explizit einschließen. Beispiel: Wenn Sie alle Sänger in Primärschlüsselreihenfolge auflisten möchten, verwenden Sie diese Abfrage:
SELECT * FROM Singers
ORDER BY SingerId;
Spanner garantiert nur die Ergebnisreihenfolge, wenn die ORDER BY-Klausel in der Abfrage vorhanden ist. Mit anderen Worten, betrachten Sie diese Abfrage ohne ORDER
BY:
SELECT * FROM Singers;
Die Ergebnisse dieser Abfrage kommen in Spanner nicht garantiert in der Primärschlüsselreihenfolge vor. Außerdem kann sich die Reihenfolge der Ergebnisse jederzeit ändern und es ist nicht sicher, dass sie in mehreren Aufrufen konsistent ist. Wenn eine Abfrage eine ORDER BY-Klausel enthält und Spanner einen Index verwendet, der die erforderliche Reihenfolge bereitstellt, werden die Daten nicht explizit sortiert. Sie müssen sich also keine Gedanken über die Auswirkungen auf die Leistung machen. Im Abfrageplan sehen Sie, ob ein expliziter Sortiervorgang in der Ausführung enthalten ist.
STARTS_WITH anstelle von LIKE verwenden
Da parametrisierte LIKE-Muster von Spanner erst bei der Ausführung ausgewertet werden, ist es notwendig, dass alle Zeilen gelesen und mit dem Ausdruck LIKE zur Ausfilterung nicht übereinstimmender Zeilen verglichen werden.
Wenn ein LIKE-Muster das Format foo% hat (z. B. mit einem festen String beginnt und mit einem einzelnen Platzhalterprozentzeichen endet) und die Spalte indexiert ist, verwenden Sie STARTS_WITH anstelle von LIKE. Mit dieser Option kann Spanner den Abfrageausführungsplan noch effektiver optimieren.
Nicht empfohlen:
GoogleSQL
SELECT a.AlbumTitle FROM Albums a WHERE a.AlbumTitle LIKE @like_clause;
PostgreSQL
SELECT a.AlbumTitle FROM Albums a WHERE a.AlbumTitle LIKE $1;
Empfohlen:
GoogleSQL
SELECT a.AlbumTitle FROM Albums a WHERE STARTS_WITH(a.AlbumTitle, @prefix);
PostgreSQL
SELECT a.AlbumTitle FROM Albums a WHERE STARTS_WITH(a.AlbumTitle, $2);
Commit-Zeitstempel verwenden
Wenn Ihre Anwendung Daten abfragen muss, die nach einem bestimmten Zeitpunkt geschrieben wurden, fügen Sie den entsprechenden Tabellen Spalten mit Commit-Zeitstempeln hinzu. Commit-Zeitstempel ermöglichen eine Spanner-Optimierung, mit der die I/O-Aktivitäten von Abfragen reduziert werden können, deren WHERE-Klauseln die Ergebnisse auf Zeilen beschränken, die vor einer bestimmten Zeit geschrieben wurden.
Weitere Informationen zu dieser Optimierung mit GoogleSQL-Datenbanken oder mit PostgreSQL-Datenbanken