Wenn Sie SQL-Abfragen zum Ermitteln von Daten verwenden, nutzt Spanner automatisch alle sekundären Indexe, die die Daten sehr wahrscheinlich effizienter abrufen. In manchen Fällen kann es aber vorkommen, dass Spanner einen Index auswählt, der Abfragen verlangsamt. Dies führt dann möglicherweise dazu, dass einige Abfragen langsamer als in der Vergangenheit ausgeführt werden.
Auf dieser Seite wird erläutert, wie Sie Änderungen der Ausführungsgeschwindigkeit von Abfragen ermitteln, den Plan zur Ausführung für diese Abfragen prüfen und bei Bedarf einen anderen Index für zukünftige Abfragen festlegen.
Änderungen der Ausführungsgeschwindigkeit der Abfrage erkennen
Wenn Sie eine der folgenden Änderungen vornehmen, führt dies vermutlich zu einer Änderung der Ausführungsgeschwindigkeit der Abfrage:
- Eine große Anzahl vorhandener Daten mit einem sekundären Index wird erheblich verändert.
- Ein sekundärer Index wird hinzugefügt, geändert oder gelöscht.
Sie können mit unterschiedlichen Messwerten und Tools die Abfragen ermitteln, die von Spanner langsamer als gewöhnlich ausgeführt werden:
- Query Insights und Abfragestatistiken
Anwendungsspezifische Messwerte, die mit Cloud Monitoring erfasst und analysiert werden Sie können beispielsweise den Messwert Anzahl der Abfragen überwachen, um die Anzahl der Abfragen in einer Instanz im Verlauf der Zeit zu ermitteln und herauszufinden, welche Version der Abfrageoptimierung verwendet wurde.
Clientseitige Monitoring-Tools zur Messung der Anwendungsleistung
Hinweis zu neuen Datenbanken
Wenn Sie neu erstellte Datenbanken mit gerade eingefügten oder importierten Daten abfragen, wählt Spanner möglicherweise nicht die am besten geeigneten Indexe aus, da der Abfrageoptimierer bis zu drei Tage benötigt, um Optimierungsstatistiken automatisch zu erfassen. Wenn Sie die Indexnutzung einer neuen Spanner-Datenbank früher optimieren möchten, können Sie manuell ein neues Statistikpaket erstellen.
Schema prüfen
Nachdem Sie die Abfrage ermittelt haben, die langsamer ausgeführt wird, sehen Sie sich die SQL-Anweisung für die Abfrage an und identifizieren Sie die Tabellen, die die Anweisung verwendet, sowie die Spalten, die sie aus diesen Tabellen abruft.
Suchen Sie als Nächstes die sekundären Indexe für diese Tabellen. Prüfen Sie, ob einer der Indexe die von Ihnen abgefragten Spalten enthält. Wenn ja, bedeutet dies, dass Spanner möglicherweise einen der Indexe zur Verarbeitung der Abfrage verwendet.
- Sind anwendbare Indexe vorhanden, müssen Sie als Nächstes den Index ermitteln, den Spanner für die Abfrage verwendet hat.
Sind keine anwendbaren Indexe vorhanden, prüfen Sie mit dem Befehl
gcloud spanner operations list, ob Sie vor Kurzem einen entsprechenden Index gelöscht haben:gcloud spanner operations list \ --instance=INSTANCE \ --database=DATABASE \ --filter="@TYPE:UpdateDatabaseDdlMetadata"Wenn Sie einen anwendbaren Index gelöscht haben, hat dies möglicherweise die Abfrageleistung negativ beeinflusst. Fügen Sie den sekundären Index dann wieder zur Tabelle hinzu. Nachdem Spanner den Index hinzugefügt hat, führen Sie die Abfrage noch einmal aus und prüfen deren Leistung. Wenn sich die Leistung nicht verbessert, suchen Sie im nächsten Schritt nach dem Index, den Spanner für die Abfrage verwendet hat.
Wenn Sie keinen anwendbaren Index gelöscht haben, war die Indexauswahl nicht für den Rückgang der Abfrageleistung verantwortlich. Prüfen Sie dann eventuelle andere Änderungen an Ihren Daten oder Nutzungsmustern, die sich möglicherweise auf die Leistung ausgewirkt haben.
Für eine Abfrage verwendeten Index ermitteln
Rufen Sie den Plan zur Abfrageausführung in der Google Cloud Console auf, um festzustellen, welchen Index Spanner zur Verarbeitung einer Abfrage verwendet:
Rufen Sie in der Google Cloud Console die Seite Spanner-Instanzen auf.
Klicken Sie auf den Namen der Instanz, die Sie abfragen möchten.
Klicken Sie im linken Bereich auf die Datenbank, die Sie abfragen möchten, und dann auf Spanner Studio.
Geben Sie die Abfrage ein, die geprüft werden soll.
Wählen Sie aus der Drop-down-Liste Abfrage ausführen die Option Nur Erklärung aus. Spanner zeigt den Abfrageplan an.
Suchen Sie im Abfrageplan nach mindestens einem der folgenden Operatoren:
- Table Scan
- Index Scan
- Cross Apply oder Distributed Cross Apply
Die Bedeutung der einzelnen Operatoren wird in den folgenden Abschnitten erläutert.
Operator "Table Scan"
Der Operator Table Scan gibt an, dass Spanner keinen sekundären Index verwendet hat:
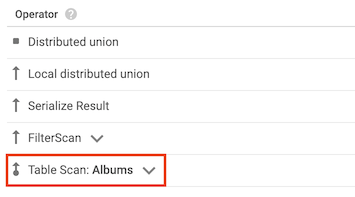
Angenommen, die Tabelle Albums enthält keine sekundären Indexe und Sie führen die folgende Abfrage aus:
SELECT AlbumTitle FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
Da keine verwendbaren Indexe vorhanden sind, enthält der Abfrageplan einen Operator "Table Scan".
Operator "Index Scan"
Der Operator Index Scan gibt an, dass Spanner bei der Verarbeitung der Abfrage einen sekundären Index verwendet hat:
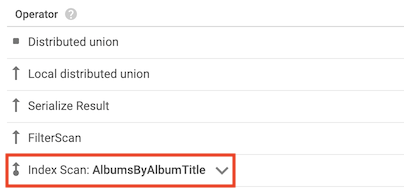
Angenommen, Sie fügen der Tabelle Albums einen Index hinzu:
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
Anschließend führen Sie die folgende Abfrage aus:
SELECT AlbumTitle FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
Der Index AlbumsByAlbumTitle enthält AlbumTitle. Dies ist die einzige Spalte, die von der Abfrage ausgewählt wird. Daher enthält der Abfrageplan einen Operator "Index Scan".
Operator "Cross Apply"
In manchen Fällen verwendet Spanner einen Index, der nur einige der Spalten enthält, die von der Abfrage ausgewählt werden. Dann muss Spanner den Index mit der Basistabelle verknüpfen.
Wenn dieser Join-Typ auftritt, enthält der Abfrageplan den Operator Cross Apply oder Distributed Cross Apply mit den folgende Eingaben:
- Operator "Index Scan" für den Index einer Tabelle
- Operator "Table Scan" für die Tabelle, zu der der Index gehört
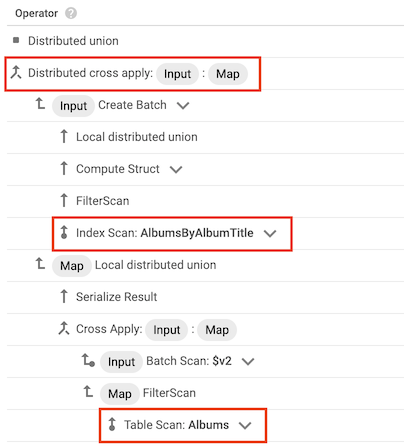
Angenommen, Sie fügen der Tabelle Albums einen Index hinzu:
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
Anschließend führen Sie die folgende Abfrage aus:
SELECT * FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
Der Index AlbumsByAlbumTitle enthält AlbumTitle, die Abfrage wählt aber alle Spalten in der Tabelle aus, nicht nur AlbumTitle. Daher enthält der Abfrageplan den Operator "Distributed Cross Apply" mit einem "Index Scan" von AlbumsByAlbumTitle und einem "Table Scan" von Albums als Eingaben.
Anderen Index auswählen
Wenn Sie den Index ermittelt haben, den Spanner für Ihre Abfrage verwendet hat, versuchen Sie, die Abfrage mit einem anderen Index auszuführen oder in der Basistabelle zu suchen, anstatt einen Index zu verwenden. Wenn Sie den Index angeben möchten, fügen Sie eine FORCE_INDEX-Anweisung zur Abfrage hinzu.
Wenn Sie eine schnellere Version der Abfrage finden, aktualisieren Sie Ihre Anwendung, um die schnellere Version zu verwenden.
Leitlinien für die Auswahl eines Index
Mithilfe der folgenden Leitlinien können Sie festlegen, welcher Index für die Abfrage getestet werden soll:
Wenn Ihre Abfrage eines der angegebenen Kriterien erfüllt, verwenden Sie die Basistabelle anstelle eines sekundären Index:
- Die Abfrage prüft auf Übereinstimmung mit einem Präfix des Primärschlüssels der Basistabelle (z. B.
SELECT * FROM Albums WHERE SingerId = 1). - Eine große Anzahl von Zeilen erfüllt die Abfrageprädikate (z. B.
SELECT * FROM Albums WHERE AlbumTitle != "There Is No Album With This Title"). - Die Abfrage verwendet eine Basistabelle, die nur einige hundert Zeilen enthält.
- Die Abfrage prüft auf Übereinstimmung mit einem Präfix des Primärschlüssels der Basistabelle (z. B.
Wenn die Abfrage ein sehr selektives Prädikat enthält (z. B.
REGEXP_CONTAINS,STARTS_WITH,<,<=,>,>=oder!=), versuchen Sie es mit einem Index, der die gleichen Spalten enthält wie das Prädikat.
Aktualisierte Abfrage testen
Verwenden Sie die Google Cloud Console, um die aktualisierte Abfrage zu testen und um festzustellen, wie lange es dauert, die Abfrage zu verarbeiten.
Wenn Ihre Abfrage Abfrageparameter enthält und ein Abfrageparameter sehr viel häufiger an einige Werte gebunden ist als andere, binden Sie den Abfrageparameter mit einem dieser Werte in Ihre Tests ein. Beispiel: Wenn die Abfrage ein Prädikat wie z. B. WHERE country = @countryId enthält und fast alle Ihre Abfragen @countryId an den Wert US binden, dann binden Sie für Ihre Leistungstests @countryId an US. Ein solches Vorgehen hilft Ihnen bei der Optimierung der Abfragen, die Sie am häufigsten ausführen.
So testen Sie die aktualisierte Abfrage in der Google Cloud Console:
Rufen Sie in der Google Cloud Console die Seite Spanner-Instanzen auf.
Klicken Sie auf den Namen der Instanz, die Sie abfragen möchten.
Klicken Sie im linken Bereich auf die Datenbank, die Sie abfragen möchten, und dann auf Spanner Studio.
Geben Sie die Abfrage ein, die getestet werden soll, einschließlich der Anweisung
FORCE_INDEXund klicken Sie auf Abfrage ausführen.In der Google Cloud Console wird der Tab Ergebnistabelle geöffnet. Darin werden die Abfrageergebnisse angezeigt, einschließlich der Dauer der Verarbeitung der Abfrage durch den Spanner-Dienst.
Dieser Messwert enthält keine anderen Latenzquellen wie etwa die Zeit für die Interpretation und für die Anzeige der Ergebnisse durch die Google Cloud Console.
Mit der REST API das detaillierte Profil einer Abfrage im JSON-Format abrufen
Standardmäßig werden bei einer Abfrage nur Anweisungsergebnisse zurückgegeben.
Dies liegt daran, dass QueryMode auf NORMAL gesetzt ist.
Wenn Sie detaillierte Ausführungsstatistiken in die Abfrageergebnisse aufnehmen möchten, legen Sie für QueryMode den Wert PROFILE fest.
Sitzung erstellen
Erstellen Sie vor dem Aktualisieren des Abfragemodus eine Sitzung als Kommunikationskanal mit dem Spanner-Datenbankdienst.
- Klicken Sie auf
projects.instances.databases.sessions.create. Geben Sie die Projekt-ID, die Instanz-ID und die Datenbank-ID im folgenden Format an:
projects/[\PROJECT_ID\]/instances/[\INSTANCE_ID\]/databases/[\DATABASE_ID\]Klicken Sie auf Ausführen. Die Antwort enthält die erstellte Sitzung in der folgenden Form:
projects/[\PROJECT_ID\]/instances/[\INSTANCE_ID\]/databases/[\DATABASE_ID\]/sessions/[\SESSION\]Damit führen Sie das Abfrageprofil im nächsten Schritt aus. Die erstellte Sitzung bleibt nach einer Nutzung bis zur nächsten Verwendung für höchstens eine Stunde aktiv. Dann wird sie von der Datenbank gelöscht.
Abfrage profilieren
Aktivieren Sie den Modus PROFILE für die Abfrage.
- Klicken Sie auf
projects.instances.databases.sessions.executeSql. Geben Sie unter Sitzung die ID der Sitzung ein, die Sie im vorherigen Schritt erstellt haben:
projects/[PROJECT_ID]/instances/[INSTANCE_ID]/databases/[DATABASE_ID]/sessions/[SESSION]Verwenden Sie Folgendes für Request body (Requesttext):
{ "sql": "[YOUR_SQL_QUERY]", "queryMode": "PROFILE" }Klicken Sie auf Ausführen. Die zurückgegebene Antwort enthält die Abfrageergebnisse, den Abfrageplan und die Ausführungsstatistiken für die Abfrage.