- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- Mit der Funktion Jetzt testen!, die in der Referenzdokumentation zur Spanner API erläutert wird. In den auf dieser Seite gezeigten Beispielen wird die Funktion Jetzt testen! verwendet.
- Mit Google APIs Explorer, der die Cloud Spanner API und andere Google APIs enthält.
- Mit anderen Tools oder Frameworks, die HTTP-REST-Aufrufe unterstützen.
In den Beispielen wird
[PROJECT_ID]als Google Cloud Projekt-ID verwendet. Ersetzen Sie[PROJECT_ID]durch IhreGoogle Cloud Projekt-ID. Umgeben Sie die Projekt-ID nicht mit[und].In den Beispielen wird eine Instanz-ID von
test-instanceerstellt und verwendet. Ersetzen Sie diese Angabe durch Ihre Instanz-ID, wenn Sietest-instancenicht verwenden.In den Beispielen wird eine Datenbank-ID von
example-dberstellt und verwendet. Ersetzen Sie diese Angabe, wenn Sieexample-dbnicht verwenden.Die Beispiele enthalten
[SESSION]als Teil eines Sitzungsnamens. Ersetzen Sie[SESSION]durch den Wert, den Sie erhalten, wenn Sie eine Sitzung erstellen. Umgeben Sie den Sitzungsnamen nicht mit[und].In den Beispielen wird als Transaktions-ID
[TRANSACTION_ID]verwendet. Ersetzen Sie[TRANSACTION_ID]durch den Wert, den Sie erhalten, wenn Sie eine Transaktion erstellen. Umgeben Sie die Transaktions-ID nicht mit[und].Mit der Funktion Jetzt testen! können einzelne HTTP-Request-Felder interaktiv hinzugefügt werden. In den meisten Beispielen in diesem Thema wird der gesamte Request angegeben und nicht beschrieben, wie dem Request einzelne Felder interaktiv hinzugefügt werden.
- Klicken Sie auf
projects.instanceConfigs.list. Geben Sie für parent (übergeordnet) Folgendes ein:
projects/[PROJECT_ID]Klicken Sie auf Execute (Ausführen). Die verfügbaren Instanzkonfigurationen werden in der Antwort angezeigt. Hier wird eine Beispielantwort dargestellt (Ihr Projekt kann andere Instanzkonfigurationen umfassen):
{ "instanceConfigs": [ { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-asia-south1", "displayName": "asia-south1" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-asia-east1", "displayName": "asia-east1" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-asia-northeast1", "displayName": "asia-northeast1" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-europe-west1", "displayName": "europe-west1" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-us-east4", "displayName": "us-east4" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-us-central1", "displayName": "us-central1" } ] }- Klicken Sie auf
projects.instances.create. Geben Sie für parent (übergeordnet) Folgendes ein:
projects/[PROJECT_ID]Klicken Sie auf Add request body parameters (Anfragetextparameter hinzufügen) und wählen Sie
instanceaus.Klicken Sie auf eines der Infofelder für instance (Instanz), um mögliche Felder anzuzeigen. Fügen Sie Werte für die folgenden Felder hinzu:
nodeCount: Geben Sie1ein.config: Geben Sie den Wertnamevon einer der regionalen Instanzkonfigurationen ein, die zurückgegeben werden, wenn Sie Instanzkonfigurationen auflisten.displayName: Geben SieTest Instanceein.
Klicken Sie auf das Infofeld, das nach der schließenden Klammer für instance (Instanz) angezeigt wird, und wählen Sie instanceId aus.
Geben Sie für
instanceIdden Werttest-instanceein.
Die Instanzerstellungsseite der Funktion Jetzt testen! sollte nun etwa so aussehen: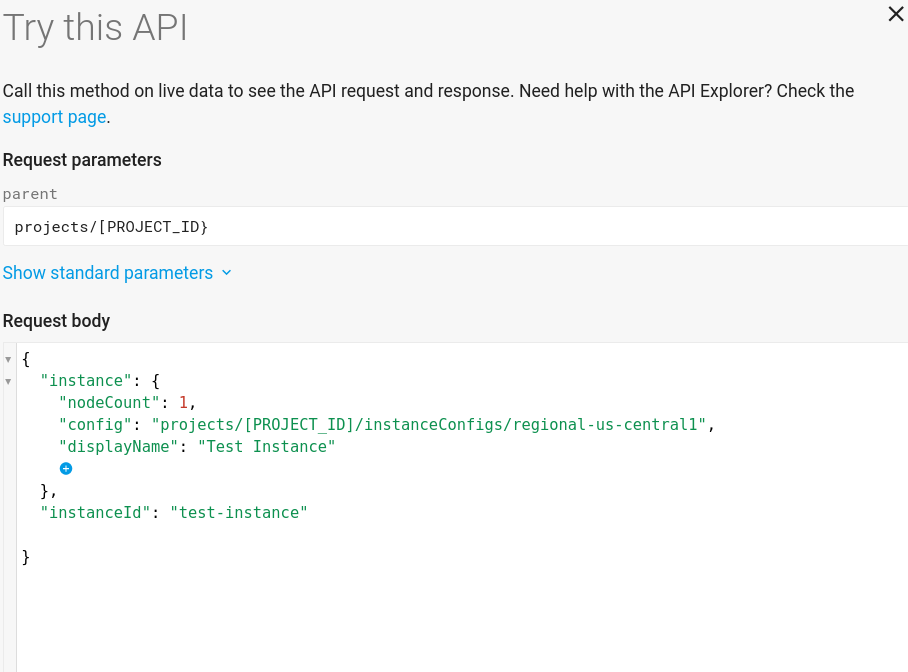
Klicken Sie auf Ausführen. Als Antwort wird ein lange laufender Vorgang zurückgegeben, den Sie abfragen können, um seinen Status zu überprüfen.
- Klicken Sie auf
projects.instances.databases.create. Geben Sie für parent (übergeordnet) Folgendes ein:
projects/[PROJECT_ID]/instances/test-instanceKlicken Sie auf Add request body parameters (Anfragetextparameter hinzufügen) und wählen Sie
createStatementaus.Geben Sie unter
createStatementFolgendes ein:CREATE DATABASE `example-db`Der Datenbankname
example-dbenthält einen Bindestrich, deshalb muss er in Graviszeichen (`) stehen.Klicken Sie auf Ausführen. Als Antwort wird ein lange laufender Vorgang zurückgegeben, den Sie abfragen können, um seinen Status zu überprüfen.
- Klicken Sie auf
projects.instances.databases.updateDdl. Geben Sie für database (Datenbank) Folgendes ein:
projects/[PROJECT_ID]/instances/test-instance/databases/example-dbVerwenden Sie Folgendes für Request body (Anfragetext):
{ "statements": [ "CREATE TABLE Singers ( SingerId INT64 NOT NULL, FirstName STRING(1024), LastName STRING(1024), SingerInfo BYTES(MAX) ) PRIMARY KEY (SingerId)", "CREATE TABLE Albums ( SingerId INT64 NOT NULL, AlbumId INT64 NOT NULL, AlbumTitle STRING(MAX)) PRIMARY KEY (SingerId, AlbumId), INTERLEAVE IN PARENT Singers ON DELETE CASCADE" ] }Das Array
statementsenthält die DDL-Anweisungen für die Schemadefinition.Klicken Sie auf Ausführen. Als Antwort wird ein lange laufender Vorgang zurückgegeben, den Sie abfragen können, um seinen Status zu überprüfen.
- Klicken Sie auf
projects.instances.databases.sessions.create. Geben Sie für database (Datenbank) Folgendes ein:
projects/[PROJECT_ID]/instances/test-instance/databases/example-dbKlicken Sie auf Execute (Ausführen).
Die Antwort enthält die erstellte Sitzung in der folgenden Form:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Sie verwenden diese Sitzung, wenn Sie Daten aus der Datenbank lesen oder in sie schreiben.
- Klicken Sie auf
projects.instances.databases.sessions.commit. Geben Sie für session (Sitzung) Folgendes ein:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](Sie erhalten diesen Wert, wenn Sie eine Sitzung erstellen.)
Verwenden Sie Folgendes für Request body (Anfragetext):
{ "singleUseTransaction": { "readWrite": {} }, "mutations": [ { "insertOrUpdate": { "table": "Singers", "columns": [ "SingerId", "FirstName", "LastName" ], "values": [ [ "1", "Marc", "Richards" ], [ "2", "Catalina", "Smith" ], [ "3", "Alice", "Trentor" ], [ "4", "Lea", "Martin" ], [ "5", "David", "Lomond" ] ] } }, { "insertOrUpdate": { "table": "Albums", "columns": [ "SingerId", "AlbumId", "AlbumTitle" ], "values": [ [ "1", "1", "Total Junk" ], [ "1", "2", "Go, Go, Go" ], [ "2", "1", "Green" ], [ "2", "2", "Forever Hold Your Peace" ], [ "2", "3", "Terrified" ] ] } } ] }Klicken Sie auf Execute (Ausführen). In der Antwort wird der Commit-Zeitstempel angegeben.
- Klicken Sie auf
projects.instances.databases.sessions.executeSql. Geben Sie für session (Sitzung) Folgendes ein:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](Sie erhalten diesen Wert, wenn Sie eine Sitzung erstellen.)
Verwenden Sie Folgendes für Request body (Anfragetext):
{ "sql": "SELECT SingerId, AlbumId, AlbumTitle FROM Albums" }Klicken Sie auf Execute (Ausführen). In der Antwort werden die Abfrageergebnisse angegeben.
- Klicken Sie auf
projects.instances.databases.sessions.read. Geben Sie für session (Sitzung) Folgendes ein:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](Sie erhalten diesen Wert, wenn Sie eine Sitzung erstellen.)
Verwenden Sie Folgendes für Request body (Anfragetext):
{ "table": "Albums", "columns": [ "SingerId", "AlbumId", "AlbumTitle" ], "keySet": { "all": true } }Klicken Sie auf Execute (Ausführen). In der Antwort werden die gelesenen Ergebnisse dargestellt.
- Klicken Sie auf
projects.instances.databases.updateDdl. Geben Sie für database (Datenbank) Folgendes ein:
projects/[PROJECT_ID]/instances/test-instance/databases/example-dbVerwenden Sie Folgendes für Request body (Anfragetext):
{ "statements": [ "ALTER TABLE Albums ADD COLUMN MarketingBudget INT64" ] }Das Array
statementsenthält die DDL-Anweisungen für die Schemadefinition.Klicken Sie auf Ausführen. Dieser Vorgang kann einige Minuten dauern, selbst wenn der REST-Aufruf eine Antwort zurückgibt. Als Antwort wird ein lange laufender Vorgang zurückgegeben, den Sie abfragen können, um seinen Status zu überprüfen.
- Klicken Sie auf
projects.instances.databases.sessions.commit. Geben Sie für session (Sitzung) Folgendes ein:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](Sie erhalten diesen Wert, wenn Sie eine Sitzung erstellen.)
Verwenden Sie Folgendes für Request body (Anfragetext):
{ "singleUseTransaction": { "readWrite": {} }, "mutations": [ { "update": { "table": "Albums", "columns": [ "SingerId", "AlbumId", "MarketingBudget" ], "values": [ [ "1", "1", "100000" ], [ "2", "2", "500000" ] ] } } ] }Klicken Sie auf Execute (Ausführen). In der Antwort wird der Commit-Zeitstempel angegeben.
- Klicken Sie auf
projects.instances.databases.sessions.executeSql. Geben Sie für session (Sitzung) Folgendes ein:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](Sie erhalten diesen Wert, wenn Sie eine Sitzung erstellen.)
Verwenden Sie Folgendes für Request body (Anfragetext):
{ "sql": "SELECT SingerId, AlbumId, MarketingBudget FROM Albums" }Klicken Sie auf Ausführen. In einem Teil der Antwort sind zwei Zeilen mit den aktualisierten Werten für
MarketingBudgetenthalten:"rows": [ [ "1", "1", "100000" ], [ "1", "2", null ], [ "2", "1", null ], [ "2", "2", "500000" ], [ "2", "3", null ] ]- Klicken Sie auf
projects.instances.databases.updateDdl. Geben Sie für database (Datenbank) Folgendes ein:
projects/[PROJECT_ID]/instances/test-instance/databases/example-dbVerwenden Sie Folgendes für Request body (Requesttext):
{ "statements": [ "CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle)" ] }Klicken Sie auf Execute (Ausführen). Dieser Vorgang kann einige Minuten dauern, selbst wenn der REST-Aufruf eine Antwort zurückgibt. Als Antwort wird ein lange laufender Vorgang zurückgegeben, den Sie abfragen können, um seinen Status zu überprüfen.
- Klicken Sie auf
projects.instances.databases.sessions.executeSql. Geben Sie für session (Sitzung) Folgendes ein:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](Sie erhalten diesen Wert, wenn Sie eine Sitzung erstellen.)
Verwenden Sie Folgendes für Request body (Anfragetext):
{ "sql": "SELECT AlbumId, AlbumTitle, MarketingBudget FROM Albums WHERE AlbumTitle >= 'Aardvark' AND AlbumTitle < 'Goo'" }Klicken Sie auf Execute (Ausführen). In einem Teil der Antwort sind die folgenden Zeilen enthalten:
"rows": [ [ "2", "Go, Go, Go", null ], [ "2", "Forever Hold Your Peace", "500000" ] ]- Klicken Sie auf
projects.instances.databases.sessions.read. Geben Sie für session (Sitzung) Folgendes ein:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](Sie erhalten diesen Wert, wenn Sie eine Sitzung erstellen.)
Verwenden Sie Folgendes für Request body (Anfragetext):
{ "table": "Albums", "columns": [ "AlbumId", "AlbumTitle" ], "keySet": { "all": true }, "index": "AlbumsByAlbumTitle" }Klicken Sie auf Execute (Ausführen). In einem Teil der Antwort sind die folgenden Zeilen enthalten:
"rows": [ [ "2", "Forever Hold Your Peace" ], [ "2", "Go, Go, Go" ], [ "1", "Green" ], [ "3", "Terrified" ], [ "1", "Total Junk" ] ]- Klicken Sie auf
projects.instances.databases.updateDdl. Geben Sie für database (Datenbank) Folgendes ein:
projects/[PROJECT_ID]/instances/test-instance/databases/example-dbVerwenden Sie Folgendes für Request body (Requesttext):
{ "statements": [ "CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget)" ] }Klicken Sie auf Execute (Ausführen). Dieser Vorgang kann einige Minuten dauern, selbst wenn der REST-Aufruf eine Antwort zurückgibt. Als Antwort wird ein lange laufender Vorgang zurückgegeben, den Sie abfragen können, um seinen Status zu überprüfen.
- Klicken Sie auf
projects.instances.databases.sessions.read. Geben Sie für session (Sitzung) Folgendes ein:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](Sie erhalten diesen Wert, wenn Sie eine Sitzung erstellen.)
Verwenden Sie Folgendes für Request body (Anfragetext):
{ "table": "Albums", "columns": [ "AlbumId", "AlbumTitle", "MarketingBudget" ], "keySet": { "all": true }, "index": "AlbumsByAlbumTitle2" }Klicken Sie auf Execute (Ausführen). In einem Teil der Antwort sind die folgenden Zeilen enthalten:
"rows": [ [ "2", "Forever Hold Your Peace", "500000" ], [ "2", "Go, Go, Go", null ], [ "1", "Green", null ], [ "3", "Terrified", null ], [ "1", "Total Junk", "100000" ] ]- Klicken Sie auf
projects.instances.databases.sessions.beginTransaction. Geben Sie für session (Sitzung) Folgendes ein:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Verwenden Sie Folgendes für Request body (Requesttext):
{ "options": { "readOnly": {} } }Klicken Sie auf Execute (Ausführen).
Die Antwort enthält die ID der erstellten Transaktion.
- Klicken Sie auf
projects.instances.databases.sessions.executeSql. Geben Sie für session (Sitzung) Folgendes ein:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](Sie erhalten diesen Wert, wenn Sie eine Sitzung erstellen.)
Verwenden Sie Folgendes für Request body (Anfragetext):
{ "sql": "SELECT SingerId, AlbumId, AlbumTitle FROM Albums", "transaction": { "id": "[TRANSACTION_ID]" } }Klicken Sie auf Execute (Ausführen). Die Antwort sollte Zeilen ähnlich den folgenden enthalten:
"rows": [ [ "2", "2", "Forever Hold Your Peace" ], [ "1", "2", "Go, Go, Go" ], [ "2", "1", "Green" ], [ "2", "3", "Terrified" ], [ "1", "1", "Total Junk" ] ]- Klicken Sie auf
projects.instances.databases.sessions.read. Geben Sie für session (Sitzung) Folgendes ein:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](Sie erhalten diesen Wert, wenn Sie eine Sitzung erstellen.)
Verwenden Sie Folgendes für Request body (Anfragetext):
{ "table": "Albums", "columns": [ "SingerId", "AlbumId", "AlbumTitle" ], "keySet": { "all": true }, "transaction": { "id": "[TRANSACTION_ID]" } }Klicken Sie auf Execute (Ausführen). Die Antwort sollte Zeilen ähnlich den folgenden enthalten:
"rows": [ [ "1", "1", "Total Junk" ], [ "1", "2", "Go, Go, Go" ], [ "2", "1", "Green" ], [ "2", "2", "Forever Hold Your Peace" ], [ "2", "3", "Terrified" ] ]- Klicken Sie auf
projects.instances.databases.dropDatabase. Geben Sie unter Name Folgendes ein:
projects/[PROJECT_ID]/instances/test-instance/databases/example-dbKlicken Sie auf Execute (Ausführen).
- Klicken Sie auf
projects.instances.delete. Geben Sie unter Name Folgendes ein:
projects/[PROJECT_ID]/instances/test-instanceKlicken Sie auf Ausführen.
Methoden zum Durchführen von REST-Aufrufen
Sie haben folgende Möglichkeiten, Spanner-REST-Aufrufe durchzuführen:
Auf dieser Seite verwendete Konventionen
Instanzen
Wenn Sie Spanner zum ersten Mal verwenden, müssen Sie eine Instanz erstellen. Dabei handelt es sich um eine Zuordnung von Ressourcen, die von Spanner-Datenbanken verwendet werden. Wenn Sie eine Instanz erstellen, legen Sie fest, wo die Daten gespeichert und wie viel Rechenkapazität die Instanz hat.
Instanzkonfigurationen auflisten
Wenn Sie eine Instanz erstellen, geben Sie eine Instanzkonfiguration an, mit der die geografische Platzierung und Replikation der Datenbanken in der Instanz definiert wird. Sie können eine regionale Konfiguration wählen, die Daten in einer Region speichert, oder eine multiregionale Konfiguration, die Daten über mehrere Regionen verteilt. Weitere Informationen dazu finden Sie unter Instanzen.
Ermitteln Sie anhand von projects.instanceConfigs.list, welche Konfigurationen für Ihr Google Cloud -Projekt verfügbar sind.
Sie verwenden den Wert name für eine der Instanzkonfigurationen, wenn Sie die Instanz erstellen.
Instanz erstellen
Sie können Ihre Instanzen mit projects.instances.list auflisten.
Datenbank erstellen
Erstellen Sie eine Datenbank mit dem Namen example-db.
Sie können Ihre Datenbanken mit projects.instances.databases.list auflisten.
Schema erstellen
Verwenden Sie die Datendefinitionssprache (DDL) von Spanner, um Tabellen zu erstellen, zu ändern oder zu verwerfen und Indexe zu erstellen oder zu verwerfen.
Mit dem Schema werden außerdem die beiden Tabellen Singers und Albums für eine einfache Musikanwendung definiert. Die Tabellen werden im weiteren Verlauf dieser Seite verwendet. Sehen Sie sich das Beispielschema an, falls Sie es noch nicht getan haben.
Sie können Ihr Schema mit projects.instances.databases.getDdl abrufen.
Sitzung erstellen
Bevor Sie Daten hinzufügen, aktualisieren, löschen oder abfragen können, müssen Sie eine Sitzung erstellen. Dabei handelt es sich um einen Kommunikationskanal mit dem Spanner-Datenbankdienst. Sie verwenden eine Sitzung nicht direkt, wenn Sie die Spanner-Clientbibliothek einsetzen, da die Sitzungen von der Clientbibliothek in Ihrem Namen verwaltet werden.
Sitzungen sollen langlebig sein. Der Spanner-Datenbankdienst kann eine Sitzung löschen, wenn die Sitzung länger als eine Stunde inaktiv ist. Beim Versuch, eine gelöschte Sitzung zu verwenden, wird NOT_FOUND zurückgegeben. Wenn dieser Fehler auftritt, erstellen und verwenden Sie eine neue Sitzung. Mit projects.instances.databases.sessions.get können Sie feststellen, ob eine Sitzung noch aktiv ist.
Weitere Informationen finden Sie unter Eine inaktive Sitzung offen halten.
Im nächsten Schritt werden Daten in die Datenbank geschrieben.
Daten schreiben
Daten werden mit dem Typ Mutation geschrieben. Eine Mutation ist ein Container für Mutationsvorgänge. Eine Mutation stellt eine Folge von Einfügungs-, Aktualisierungs-, Lösch- und anderen Vorgängen dar, die in kleinstmöglichen Schritten auf verschiedene Zeilen und Tabellen in einer Spanner-Datenbank angewendet werden können.
In diesem Beispiel wurde insertOrUpdate verwendet. Weitere Vorgänge für Mutations sind insert, update, replace und delete.
Weitere Informationen zum Codieren von Datentypen finden Sie unter "TypeCode".
Daten mit SQL abfragen
Daten mit der Lese-API auslesen
Datenbankschema aktualisieren
Beispiel: Sie möchten der Tabelle Albums eine neue Spalte mit dem Namen MarketingBudget hinzufügen. Dazu muss das Datenbankschema aktualisiert werden. Spanner unterstützt Schemaaktualisierungen für Datenbanken, ohne dass die Traffic-Bereitstellung unterbrochen werden muss. Bei einer Schemaaktualisierung muss die Datenbank nicht offline geschaltet und es müssen keine ganzen Tabellen oder Spalten gesperrt werden. Sie können während des Vorgangs weiter Daten in die Datenbank schreiben.
Spalte hinzufügen
Daten in die neue Spalte schreiben
Mit dem folgenden Code werden Daten in die neue Spalte geschrieben. Er legt für MarketingBudget den Wert 100000 für den Zeilenschlüssel fest, der durch Albums(1, 1) angegeben wird, und 500000 für den Zeilenschlüssel, der durch Albums(2, 2) angegeben wird.
Sie können auch eine SQL-Abfrage oder einen Leseaufruf ausführen, um die Werte abzurufen, die Sie gerade geschrieben haben.
So führen Sie die Abfrage aus:
Sekundären Index verwenden
Beispiel: Sie möchten alle Zeilen aus Albums abrufen, deren Wert für AlbumTitle in einem bestimmten Bereich liegen. Sie könnten dazu alle Werte aus der Spalte AlbumTitle mit einer SQL-Anweisung oder einem Leseaufruf lesen und dann die Zeilen verwerfen, die die Kriterien nicht erfüllen. Dieser vollständige Tabellenscan wäre jedoch sehr kostspielig, insbesondere bei Tabellen mit vielen Zeilen. Stattdessen können Sie einen sekundären Index für die Tabelle erstellen und damit das Abrufen von Zeilen beim Suchen über Spalten mit nicht primärem Schlüssel beschleunigen.
Damit ein sekundärer Index einer vorhandenen Tabelle hinzugefügt werden kann, muss das Schema aktualisiert werden. Wie bei anderen Schemaaktualisierungen kann mit Spanner ein Index hinzugefügt werden, ohne dass die Traffic-Bereitstellung unterbrochen werden muss. Spanner verwendet dann automatisch die vorhandenen Daten, um einen Backfill für den Index auszuführen. Backfills können einige Minuten dauern. Sie müssen aber die Datenbank nicht offline schalten und können während des Vorgangs weiter in alle Tabellen oder Spalten schreiben. Weitere Informationen finden Sie unter Index-Backfill.
Nachdem Sie einen sekundären Index hinzugefügt haben, verwendet Spanner diesen automatisch für SQL-Abfragen, die mit dem Index sehr wahrscheinlich schneller ausgeführt werden. Wenn Sie die Leseschnittstelle verwenden, müssen Sie den Index angeben, den Sie nutzen möchten.
Sekundären Index hinzufügen
Sie können einen Index mit updateDdl hinzufügen.
Abfrage mit dem Index
Mit dem Index auslesen
Index mit einer STORING-Klausel hinzufügen
Vielleicht haben Sie bemerkt, dass im obigen Beispiel die Spalte MarketingBudget nicht gelesen wird. Die Leseschnittstelle von Spanner unterstützt nicht die Möglichkeit, einen Index mit einer Datentabelle zu verbinden, um Werte zu suchen, die nicht im Index gespeichert sind.
Erstellen Sie eine alternative Definition von AlbumsByAlbumTitle, die eine Kopie von MarketingBudget im Index speichert.
Sie können einen STORING-Index mit updateDdl hinzufügen.
Sie können jetzt einen Lesevorgang ausführen, der die Spalten AlbumId, AlbumTitle und MarketingBudget aus dem Index AlbumsByAlbumTitle2 abruft:
Daten mit schreibgeschützten Transaktionen abrufen
Angenommen, Sie möchten mehr als einen Lesevorgang mit demselben Zeitstempel ausführen. Bei schreibgeschützten Transaktionen wird ein gleichbleibendes Präfix des Commit-Verlaufs der Transaktionen beibehalten, damit die Anwendung immer konsistente Daten erhält.
Schreibgeschützte Transaktion erstellen
Sie können nun mit einer schreibgeschützten Transaktion Daten mit einem konsistenten Zeitstempel abrufen, selbst wenn sich die Daten seit der Erstellung der schreibgeschützten Transaktion geändert haben.
Abfrage mit der schreibgeschützten Transaktion ausführen
Mit der schreibgeschützten Transaktion auslesen
Spanner unterstützt auch Lese-/Schreibtransaktionen, bei denen eine Reihe von Lese- und Schreibvorgängen in kleinstmöglichen Schritten zu einem einzigen logischen Zeitpunkt ausgeführt werden. Weitere Informationen finden Sie unter Lese-Schreib-Transaktionen. Die Funktion Jetzt testen! eignet sich nicht für die Demonstration einer Lese-Schreib-Transaktion.
Bereinigen
Löschen Sie die Datenbank und die erstellte Instanz, um zu vermeiden, dass Ihrem Google Cloud Konto die in dieser Anleitung verwendeten Ressourcen in Rechnung gestellt werden.